1.本技术涉及计算机领域,特别是涉及一种数据均衡方法和装置。
背景技术:
2.随着当前金融科技领域快速发展,银行业数字化转型的战略背景下,各项银行业务量日益增长,所产生的金融类数据随之剧烈膨胀。银行业务数据基本呈几何级别增长,有较长的生命周期,日增数据条数过亿,历史数据存量达到千亿条,数据的读写访问有较高要求。传统关系型数据库已无法满足当前数据存储需求,伴随着大数据技术兴起,基于服务器集群的数据存储技术得到广泛运用。但是,由于业务数据增长的不确定性和可变性,服务器集群的数据存在分布不均,热点数据集中于某台或某几台主机,导致相关主机负载过重,严重影响服务器集群的整体性能和稳定。
3.因此,目前亟需一种数据均衡方法,以解决服务器集群热点数据分布不均的问题。
技术实现要素:
4.有鉴于此,本技术提供了一种数据均衡方法和装置,用于解决服务器集群热点数据分布不均的问题,其技术方案如下:
5.一种数据均衡方法,包括:
6.采集服务器集群中每个服务器的运行状态指标数据,其中,服务器集群中每个服务器包含至少一个分区,每个分区内包含至少一个数据存储文件,运行状态指标数据能够反映对应服务器的负载情况;
7.根据服务器集群中每个服务器的运行状态指标数据,确定服务器集群中的热点服务器和空闲服务器;
8.获取热点服务器和空闲服务器分别包含的每个数据存储文件的相关信息,并根据热点服务器包含的每个数据存储文件的相关信息,从热点服务器包含的每个热点分区中确定待迁移子分区,其中,相关信息能够反映对应数据存储文件包含的数据是否为热点数据;
9.将热点服务器包含的每个热点分区中的待迁移子分区迁移到空闲服务器中。
10.可选的,采集服务器集群中每个服务器的运行状态指标数据,包括:
11.采集服务器集群中每个服务器的性能指标数据、堆内存指标数据和业务系统指标数据。
12.可选的,根据服务器集群中每个服务器的运行状态指标数据,确定服务器集群中的热点服务器和空闲服务器,包括:
13.将服务器集群中每个服务器的运行状态指标数据映射为向量,得到的向量作为服务器集群中每个服务器的运行状态向量;
14.根据服务器集群中每个服务器的运行状态向量,确定服务器集群中每个服务器对应的负载相关值;
15.根据预设的相关值阈值和筛选个数,以及,服务器集群中每个服务器对应的负载
相关值,确定服务器集群中的热点服务器和空闲服务器。
16.可选的,根据服务器集群中每个服务器的运行状态向量,确定服务器集群中每个服务器对应的负载相关值,包括:
17.将服务器集群中每个服务器的运行状态向量输入到预先训练的神经网络模型中,得到服务器集群中每个服务器对应的负载相关值,其中,神经网络模型采用训练运行状态向量和训练运行状态向量对应的标注负载相关值进行训练。
18.可选的,根据预设的相关值阈值和筛选个数,以及,服务器集群中每个服务器对应的负载相关值,确定服务器集群中的热点服务器和空闲服务器,包括:
19.将服务器集群中每个服务器对应的负载相关值分别与预设的热点相关值阈值和空闲相关值阈值进行比较,得到负载相关值大于热点相关值阈值的服务器,作为待筛选热点服务器,以及,负载相关值小于空闲相关值阈值的服务器,作为待筛选空闲服务器;
20.根据热点筛选个数,从待筛选热点服务器中确定热点服务器,并根据空闲筛选个数,从待筛选空闲服务器中确定空闲服务器。
21.可选的,根据热点服务器包含的每个数据存储文件的相关信息,从热点服务器包含的每个热点分区中确定待迁移子分区,包括:
22.根据热点服务器包含的每个数据存储文件的相关信息,从热点服务器包含的分区中确定预设数目个热点分区;
23.根据热点服务器包含的每个热点分区所包含的数据存储文件的相关信息,从热点服务器包含的每个热点分区中确定待迁移子分区。
24.可选的,根据热点服务器包含的每个数据存储文件的相关信息,从热点服务器包含的分区中确定预设数目个热点分区,包括:
25.根据热点服务器包含的每个数据存储文件的相关信息,计算热点服务器包含的每个数据存储文件对应的热点分数;
26.根据热点服务器包含的每个数据存储文件对应的热点分数,确定热点服务器包含的每个分区对应的热点分数;
27.根据热点服务器包含的每个分区对应的热点分数,从热点服务器包含的分区中确定预设数目个热点分区。
28.可选的,根据热点服务器包含的每个热点分区所包含的数据存储文件的相关信息,从热点服务器包含的每个热点分区中确定待迁移子分区,包括:
29.对于热点服务器包含的每个热点分区,从该热点分区中确定热点分数最高的数据存储文件,在热点分数最高的数据存储文件中设置切分点,作为该热点分区对应的切分点;
30.基于热点服务器包含的每个热点分区对应的切分点,将热点服务器包含的每个热点分区切分为两个子分区,以得到热点服务器包含的每个热点分区所包含的两个子分区;
31.对于热点服务器包含的每个热点分区,根据该热点分区包含的两个子分区分别包含的数据存储文件的相关信息,计算该热点分区包含的两个子分区分别对应的热点分数,并将该热点分区包含的两个子分区中,对应热点分数高的子分区作为该热点分区中的待迁移子分区。
32.可选的,将热点服务器包含的每个热点分区中的待迁移子分区迁移到空闲服务器中,包括:
33.按照热点服务器包含的每个分区对应的热点分数,遍历热点服务器包含的每个热点分区:
34.对于当前遍历到的热点分区,从空闲服务器中确定目标服务器;
35.将当前遍历到的热点分区中的待迁移子分区迁移到目标服务器。
36.一种数据均衡装置,包括:指标数据采集模块、热点空闲服务器确定模块、待迁移子分区确定模块和待迁移子分区迁移模块;
37.指标数据采集模块,用于采集服务器集群中每个服务器的运行状态指标数据,其中,服务器集群中每个服务器包含至少一个分区,每个分区内包含至少一个数据存储文件,运行状态指标数据能够反映对应服务器的负载情况;
38.热点空闲服务器确定模块,用于根据服务器集群中每个服务器的运行状态指标数据,确定服务器集群中的热点服务器和空闲服务器;
39.待迁移子分区确定模块,用于获取热点服务器和空闲服务器分别包含的每个数据存储文件的相关信息,并根据热点服务器包含的每个数据存储文件的相关信息,从热点服务器包含的每个热点分区中确定待迁移子分区,其中,相关信息能够反映对应数据存储文件包含的数据是否为热点数据;
40.待迁移子分区迁移模块,用于将热点服务器包含的每个热点分区中的待迁移子分区迁移到空闲服务器中。
41.经由上述的技术方案可知,本技术提供的数据均衡方法,首先采集服务器集群中每个服务器的运行状态指标数据,然后根据服务器集群中每个服务器的运行状态指标数据,确定服务器集群中的热点服务器和空闲服务器,接着获取热点服务器和空闲服务器分别包含的每个数据存储文件的相关信息,并根据热点服务器包含的每个数据存储文件的相关信息,从热点服务器包含的每个热点分区中确定待迁移子分区,最后将热点服务器包含的每个热点分区中的待迁移子分区迁移到空闲服务器中。本技术能够根据采集的运行状态指标数据确定出热点服务器和空闲服务器,然后再将热点服务器包含的热点分区中的待迁移子分区迁移到空闲服务器,提高了服务器集群热点数据的均衡效果。
附图说明
42.为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
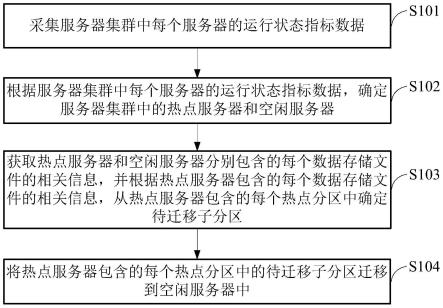
43.图1为本技术实施例提供的数据均衡方法的流程示意图;
44.图2a为regionserver的内部结构示意图;
45.图2b为region的内部结构示意图;
46.图3为三个指标采集器与指标格式转换器的交互示意图;
47.图4为本技术实施例提供的运行状态向量的示意图;
48.图5为神经网络模型、regionserver分类处理器和服务器信息存储器的交互示意图;
49.图6为storefile信息获取器、storefile信息处理器和region均衡计划生成器的
交互示意图;
50.图7为region切分计划执行器和region迁移计划执行器的示意图;
51.图8为本技术实施例提供的数据均衡装置的结构示意图;
52.图9为本技术实施例提供的数据均衡设备的硬件结构框图。
具体实施方式
53.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
54.本技术提供了一种数据均衡方法,该数据均衡方法的大体思路是:使用神经网络找到服务器集群中热点和空闲的服务器,而后对热点服务器中的热点区域进行切分且迁移到空闲的服务器上,以提高服务器集群整体的性能和稳定。接下来通过下述实施例对本技术提供的数据均衡方法进行详细介绍。
55.请参阅图1,示出了本技术实施例提供的数据均衡方法的流程示意图,该数据均衡方法可以包括:
56.步骤s101、采集服务器集群中每个服务器的运行状态指标数据。
57.其中,服务器集群中每个服务器包含至少一个分区,每个分区内包含至少一个数据存储文件。
58.可选的,服务器集群可以为hbase集群中的多个regionserver(分区服务器)组成的集群。
59.参见图2a,示出了一个regionserver的内部结构示意图,每个regionserver上有一个或多个region(分区),读写的数据都存储在region上,一个region相当于关系型数据库中分区表的一个分区,每一个region都有起始rowkey(行键)和结束rowkey,代表了它所存储的数据范围。
60.参见图2b,示出了一个region的内部结构示意图,每一个region内部都包含有多个store实例,store内部有memstore和storeflie(hfile)两个组成部分。其中,memstore存放于内存中,保存当前正在修改的数据,当memstore的大小达到阈值,memstore的内容将会被写到数据存储文件中,形成的数据存储文件即为hfile。storefile是hfile的抽象类,即hfile为物理定义,storeflie为逻辑定义。
61.上述运行状态指标数据能够反映对应服务器的负载情况。在本步骤中,可以由用户设置都需要采集哪些运行状态指标,然后本步骤再根据用户设置的运行状态指标,采集服务器集群中每个服务器的运行状态指标数据。
62.在一可选实施例中,上述运行状态指标可以为性能指标、堆内存指标和业务系统指标,则本步骤可以采集服务器集群中每个服务器的性能指标数据、堆内存指标数据和业务系统指标数据。
63.可选的,上述性能指标包括但不限于cpu使用率、内存使用率等,上述堆内存指标包括但不限于堆内存使用率、eden区使用率、survivor区使用率等,上述业务系统指标包括但不限于服务器单位时间的请求数(并发数)、查询响应时间等。
64.可选的,在本步骤中,性能指标数据可以通过性能指标采集器进行采集,堆内存指标数据可以通过堆内存指标采集器进行采集,业务系统指标可以通过业务系统指标采集器进行采集。
65.步骤s102、根据服务器集群中每个服务器的运行状态指标数据,确定服务器集群中的热点服务器和空闲服务器。
66.前述已经说明了,运行状态指标数据能够反映对应服务器的负载情况,针对服务器集群中的每个服务器,若该服务器的负载较重,说明该服务器为热点服务器,如果该服务器的负载较轻,说明该服务器为空闲服务器。
67.需要说明的是,本步骤确定的热点服务器和空闲服务器的数量可以由用户预先设置,也就是说,用户先设置好筛选个数(包括热点筛选个数和空闲筛选个数),然后再根据用户设置的筛选个数,从服务器集群中筛选热点服务器和空闲服务器。
68.步骤s103、获取热点服务器和空闲服务器分别包含的每个数据存储文件的相关信息,并根据热点服务器包含的每个数据存储文件的相关信息,从热点服务器包含的每个热点分区中确定待迁移子分区。
69.可选的,存储数据文件的相关信息包括但不限于存储数据文件中包含的数据量和请求量,该请求量包括针对存储数据文件的写请求量和读请求量,例如,以hbase集群中的分区服务器为例,请求量包括针对storefile的写请求量和读请求量。
70.在本步骤中,相关信息能够反映对应数据存储文件包含的数据是否为热点数据,因此,基于该相关信息就能够从热点服务器包含的各分区中确定出热点分区,同时也能从每个热点分区中确定出待迁移子分区。这里,待迁移子分区中包含的热点数据的数据量较大,需要将其迁移到空闲服务器,以降低热点服务器的负载,提高服务器集群的整体性能和稳定性。
71.即,本步骤可以在每个热点服务器中确定多个热点分区,并从每个热点分区中确定一个待迁移子分区。
72.步骤s104、将热点服务器包含的每个热点分区中的待迁移子分区迁移到空闲服务器中。
73.本技术提供的数据均衡方法,首先采集服务器集群中每个服务器的运行状态指标数据,然后根据服务器集群中每个服务器的运行状态指标数据,确定服务器集群中的热点服务器和空闲服务器,接着获取热点服务器和空闲服务器分别包含的每个数据存储文件的相关信息,并根据热点服务器包含的每个数据存储文件的相关信息,从热点服务器包含的每个热点分区中确定待迁移子分区,最后将热点服务器包含的每个热点分区中的待迁移子分区迁移到空闲服务器中。本技术能够根据采集的运行状态指标数据确定出热点服务器和空闲服务器,然后再将热点服务器包含的热点分区中的待迁移子分区迁移到空闲服务器,提高了服务器集群热点数据的均衡效果。
74.本技术的一个实施例,对上述“步骤s102、根据服务器集群中每个服务器的运行状态指标数据,确定服务器集群中的热点服务器和空闲服务器”的过程进行说明。
75.可选的,“根据服务器集群中每个服务器的运行状态指标数据,确定服务器集群中的热点服务器和空闲服务器”的过程可以包括:
76.步骤a1、将服务器集群中每个服务器的运行状态指标数据映射为向量,得到的向
量作为服务器集群中每个服务器的运行状态向量。
77.这里,运行状态向量为一个多维向量,每个维度代表一个指标数据,整个运行状态向量一定程度上表示了服务器(例如regionserver)的某段时间内的负载情况。
78.可选的,本步骤可以通过指标格式转换器实现,例如,参见图3所示的三个指标采集器与指标格式转换器的交互示意图,性能指标采集器采集的每个服务器的性能指标数据、堆内存指标采集器采集的每个服务器的堆内存指标数据,以及,业务系统指标采集器采集的每个服务器的业务系统指标均可以输入到指标格式转换器,以得到服务器集群中每个服务器的运行状态向量,本步骤得到的运行状态向量例如可以参见图4所示。
79.步骤a2、根据服务器集群中每个服务器的运行状态向量,确定服务器集群中每个服务器对应的负载相关值。
80.可以理解的是,若要从服务器集群中确定出热点服务器和空闲服务器,就需要将服务器集群中各服务器的负载情况进行比较,而由于向量既有大小又有方向,不便于直接比较大小,因此需要通过本步骤将每个服务器的运行状态向量转换为能够进行大小比较的负载相关值。
81.在一可选实施例中,本步骤可以通过神经网络模型实现,具体来说,本步骤可以将服务器集群中每个服务器的运行状态向量输入到预先训练的神经网络模型中,得到服务器集群中每个服务器对应的负载相关值,其中,神经网络模型采用训练运行状态向量和训练运行状态向量对应的标注负载相关值进行训练。
82.其中,训练运行状态向量的确定过程与前述步骤确定运行状态向量的过程相似,详细可参照前述步骤中的介绍,在此不再赘述。
83.在本步骤中,神经网络模型可以对服务器负载情况进行预测,其输出的负载相关值为(0,1)范围内的值,其中,负载相关值越趋近于1,则表示对应的服务器负载越重,反之,负载相关值越趋近于0,表示对应的服务器负载越轻。
84.步骤a3、根据预设的相关值阈值和筛选个数,以及,服务器集群中每个服务器对应的负载相关值,确定服务器集群中的热点服务器和空闲服务器。
85.在本步骤中,可以由用户设置筛选个数(包括热点筛选个数和空闲筛选个数)和相关值阈值(包括热点相关值阈值和空闲相关值阈值),然后再基于相关值阈值和筛选个数,以及,服务器集群中每个服务器对应的负载相关值,从服务器集群中筛选出负载最重的热点服务器,以及,负载最轻的空闲服务器,以供后续生成均衡计划使用。
86.可选的,本步骤可以通过分类处理器实现,以hbase集群中的分区服务器为例,参见图5所示,分类处理器可以为regionserver分类处理器,该regionserver分类处理器可以接收神经网络模型输出的各服务器的负载相关值,并基于相关值阈值和筛选个数进行比较,以得到热点服务器和空闲服务器。
87.可选的,本步骤还可以将热点服务器信息存储在热点服务器信息存储器中,并将空闲服务器信息存储在空闲服务器信息存储器中,例如,将热点服务器信息存储在图5所示的热点regionserver信息存储器中,并将空闲服务器信息存储在图5所示的空闲regionserver信息存储器中。
88.这里,热点服务器信息中至少包括:热点服务器包含的每个数据存储文件的相关信息,以及对应的服务器标识、分区标识和数据存储文件标识;相应的,空闲服务器信息中
至少包括:空闲服务器包含的每个数据存储文件的相关信息,以及对应的服务器标识、分区标识和数据存储文件标识。
89.在一可选实施例中,“步骤a3、根据预设的相关值阈值和筛选个数,以及,服务器集群中每个服务器对应的负载相关值,确定服务器集群中的热点服务器和空闲服务器”的过程可以包括:
90.步骤a31、将服务器集群中每个服务器对应的负载相关值分别与预设的热点相关值阈值和空闲相关值阈值进行比较,得到负载相关值大于热点相关值阈值的服务器,作为待筛选热点服务器,以及,负载相关值小于空闲相关值阈值的服务器,作为待筛选空闲服务器。
91.具体的,假设热点相关值阈值为x,空闲相关值阈值为y,则对于服务器集群中的每个服务器,若该服务器对应的负载相关值大于x,则将该服务器作为待筛选热点服务器,若该服务器对应的负载相关值小于y,则将该服务器作为待筛选空闲服务器。
92.步骤a32、根据热点筛选个数,从待筛选热点服务器中确定热点服务器,并根据空闲筛选个数,从待筛选空闲服务器中确定空闲服务器。
93.前述步骤确定出的待筛选热点服务器的个数可能大于热点筛选个数,如果对所有的待筛选热点服务器均进行热点数据迁移,可能会导致服务器集群不稳定,因此需要根据热点筛选个数,从待筛选热点服务器中确定热点相关度最高的热点筛选个数个热点服务器,而如果待筛选热点服务器的个数小于或等于热点筛选个数,则无需再进行本步骤的筛选;同理,本步骤可根据空闲筛选个数,从待筛选空闲服务器中确定空闲服务器。
94.可选的,本步骤“根据热点筛选个数,从待筛选热点服务器中确定热点服务器,并根据空闲筛选个数,从待筛选空闲服务器中确定空闲服务器”的过程可以包括:将待筛选热点服务器按照负载相关值由高到低进行排序,从排序结果中筛选位置靠前的热点筛选个数个服务器,这些服务器即为热点服务器;将待筛选空闲服务器按照负载相关值由低到高进行排序,从排序结果中筛选位置靠前的空闲筛选个数个服务器,这些服务器即为空闲服务器。
95.综上,本步骤通过神经网络模型将服务器的运行状态数据对应的运行状态向量转换为负载相关值,并根据负载相关值,结合相关值阈值和筛选个数,从服务器集群中准确地筛选出热点服务器和空闲服务器,筛选效率更高。
96.以下对步骤s103中“根据热点服务器包含的每个数据存储文件的相关信息,从热点服务器包含的每个热点分区中确定待迁移子分区”的过程进行介绍。
97.可选的,“根据热点服务器包含的每个数据存储文件的相关信息,从热点服务器包含的每个热点分区中确定待迁移子分区”的过程包括:
98.步骤b1、根据热点服务器包含的每个数据存储文件的相关信息,从热点服务器包含的分区中确定预设数目个热点分区。
99.具体的,可以由用户预先设置好每个热点服务器包含的热点分区的数目,为便于后续描述,将该数目定义为预设数目,并将该预设数目记为topn。则对于每个热点服务器,本步骤可以根据该热点服务器包含的每个数据存储文件的相关信息,从热点服务器包含的分区中确定预设数目个热点分区。
100.即,每个热点服务器均包括预设数目个热点分区。这里,对于不同的热点服务器来
说,预设数目可以相同,也可以不同,具体需要根据实际情况确定。
101.具体的,“根据热点服务器包含的每个数据存储文件的相关信息,从热点服务器包含的分区中确定预设数目个热点分区”的过程可以包括:
102.步骤b11、根据热点服务器包含的每个数据存储文件的相关信息,计算热点服务器包含的每个数据存储文件对应的热点分数。
103.如前述实施例中的介绍,热点服务器包含的每个数据存储文件的相关信息可以被存储在热点服务器信息存储器中,则本步骤需要先从热点服务器信息存储器中获取热点服务器包含的每个数据存储文件的相关信息,可选的,相关信息可以通过相关信息获取器进行获取,例如,参见图6所示,通过storefile信息获取器进行获取。
104.可选的,在获取相关信息后,可以将相关信息记录在表格中,例如,每个热点服务器的每个分区记录一个相关信息表,以hbase集群中的分区服务器为例,假设热点服务器a的分区1共包含n个storefile,则参见表1示出的热点服务器a的分区1对应的相关信息表。
105.表1热点服务器a的分区1对应的相关信息表
[0106][0107]
需要说明的是,表1仅为示例,不作为对本技术的限定。
[0108]
在获得相关信息后,本步骤即可以根据每个数据存储文件的相关信息,计算每个数据存储文件对应的热点分数,可选的,该过程可以通过相关信息处理器(例如,图6示出的storefile信息处理器)实现。
[0109]
可选的,“根据热点服务器包含的每个数据存储文件的相关信息,计算热点服务器包含的每个数据存储文件对应的热点分数”时,可以采用加权调和平均法进行计算,即相关信息处理器从相关信息获取器中获取每个数据存储文件的相关信息后,采用加权调和平均法计算热点服务器包含的每个数据存储文件对应的热点分数。
[0110]
这里,用p和r表示影响得分的两个因素,用f表示得分,用a表示调和参数,则加权调和平均法的计算公式如下:
[0111][0112]
在本步骤中具体计算热点分数时,令a=1,得到每个数据存储文件(例如,hbase中的storefile)对应的热点分数(hotscore)的计算公式如下:
[0113][0114]
式中,rowsize表示对应数据存储文件的数据量大小,requestcnt表示对应数据存储文件的请求量。
[0115]
可选的,由于数据量大小和请求量字段在单位和数值上量纲不同,为了综合考虑该两种字段信息,采用最大最小标准化(min-max normalization)消除大小与请求量量纲不同的影响(即将结果映射到0~1之间)。例如,以storefile大小标准化为例,x表示原始大小,x
min
表示相关信息表中记录的storefile大小的最小值,x
max
表示最大值,x'为标准化结果,则标准化公式如下:
[0116][0117]
也即,本步骤先对数据量大小和请求量进行标准化,然后再根据标准化后的数据量大小和请求量,计算热点分数。
[0118]
步骤b12、根据热点服务器包含的每个数据存储文件对应的热点分数,确定热点服务器包含的每个分区对应的热点分数。
[0119]
由于每个分区包含至少一个数据存储文件,则本步骤可以根据热点服务器的每个分区包含的数据存储文件对应的热点分数,计算该每个分区对应的热点分数。
[0120]
可选的,每个分区的热点分数的计算公式为:
[0121][0122]
式中,m表示每个分区包含的数据存储文件的个数,hotscorei(i=1...m)表示第i个数据存储文件对应的热点分数。
[0123]
步骤b13、根据热点服务器包含的每个分区对应的热点分数,从热点服务器包含的分区中确定预设数目个热点分区。
[0124]
可选的,本步骤可以对每个热点服务器包含的各分区,依据regionhotscore得分从高到低排序,并将排名topn(预设数目)的分区作为本步骤中的热点分区,该热点分区也即本次均衡计划涉及的分区。
[0125]
步骤b2、根据热点服务器包含的每个热点分区所包含的数据存储文件的相关信息,从热点服务器包含的每个热点分区中确定待迁移子分区。
[0126]
可以理解的是,热点分区包含的热点数据相对较多,因此需要将热点分区包含的部分热点数据迁移到空闲服务器,以降低热点服务器的负载,提高服务器集群的整体性能与稳定性。
[0127]
在本步骤中,会从每个热点服务器包含的每个热点分区中均确定一个待迁移子分区。
[0128]
可选的,“根据热点服务器包含的每个热点分区所包含的数据存储文件的相关信息,从热点服务器包含的每个热点分区中确定待迁移子分区”的过程可以包括:
[0129]
步骤b21、对于热点服务器包含的每个热点分区,从该热点分区中确定热点分数最高的数据存储文件,在热点分数最高的数据存储文件中设置切分点,作为该热点分区对应的切分点。
[0130]
对于每个热点服务器包含的每个热点分区,该热点分区包含至少一个数据存储文件,在前述步骤已经计算出该至少一个数据存储文件对应的热点分数的前提下,本步骤可以确定出热点分数最高的数据存储文件,并在该热点分数最高的数据存储文件中设置切分
点。
[0131]
例如,以hbase集群中的热点服务器为例,本步骤可以将切分点(splitkey)定义为热点分数最高的storefile的起始rowkey与结束rowkey的中间值(midkey)。
[0132]
在本步骤中,确定了切分点的位置后,可以将分区信息(即热点服务器包含的热点分区的标识信息)和分区信息对应的切分点信息(即热点分区包含的目标数据存储文件,以及,切分点在目标数据存储文件中的位置)添加到分区切分计划,以便基于分区信息和切分点信息确定切分点在热点服务器中哪个热点分区包含的哪个数据存储文件的哪个位置。
[0133]
可选的,参见图6所示,本步骤可通过region均衡计划生成器(该region均衡计划生成器生成的均衡计划包括切分计划和迁移计划)实现,即region均衡计划生成器接收相关信息处理器(图6具体为storefile信息处理器)输出的每个分区对应的热点分数,并基于该每个分区对应的热点分数确定切分点,从而生成了切分计划。
[0134]
步骤b22、基于热点服务器包含的每个热点分区对应的切分点,将热点服务器包含的每个热点分区切分为两个子分区,以得到热点服务器包含的每个热点分区所包含的两个子分区。
[0135]
可以理解的是,多个数据存储文件在对应分区中按顺序存储,基于此,本步骤可以将每个热点服务器包含的每个热点分区切分为两个子分区,其中,切分点之前的数据存储文件在一个子分区中,切分点之后的数据存储文件在另一个子分区中。
[0136]
可选的,本步骤可以通过图7所示的region切分计划执行器实现。
[0137]
步骤b23、对于热点服务器包含的每个热点分区,根据该热点分区包含的两个子分区分别包含的数据存储文件的相关信息,计算该热点分区包含的两个子分区分别对应的热点分数,并将该热点分区包含的两个子分区中,对应热点分数高的子分区作为该热点分区中的待迁移子分区。
[0138]
本步骤“根据该热点分区包含的两个子分区分别包含的数据存储文件的相关信息,计算该热点分区包含的两个子分区分别对应的热点分数”的过程与前述计算分区对应的热点分数的过程相同,即采用公式(2)~(4)进行计算,在此不再赘述。
[0139]
可选的,本步骤可通过图6所示的region均衡计划生成器实现,即本步骤为region均衡计划生成器生成的迁移计划。
[0140]
经由上述步骤b1~b2可以确定出每个热点服务器包含的每个热点分区中的待迁移子分区,本实施例可以针对每个热点服务器包含的每个热点分区分别生成一条均衡计划,由这些均衡计划组成计划列表(可选的,可以在计划列表中按照每个热点服务器包含的每个分区对应的热点分数由高到低排序),以便后续依据计划列表,依次执行每条均衡计划。
[0141]
在一可选实施例中,上述实施例中的“步骤s104、将热点服务器包含的每个热点分区中的待迁移子分区迁移到空闲服务器中”的过程可以包括:
[0142]
按照热点服务器包含的每个分区对应的热点分数,遍历热点服务器包含的每个热点分区:对于当前遍历到的热点分区,从空闲服务器中确定目标服务器;将当前遍历到的热点分区中的待迁移子分区迁移到目标服务器。
[0143]
可选的,本步骤确定目标服务器的过程包括:对于从计划列表中取出的第一条均衡计划,该均衡计划对应的热点分区即第一次遍历的热点分区,本步骤可以采用上述公式
(2)~(4),计算每个空闲服务器包含的每个分区对应的热点分数,然后再将所有空闲服务器中,热点分数最低的分区所属的空闲服务器,作为第一次遍历对应的目标服务器;对于从计划列表中取出的后续均衡计划,可以在前一次遍历结束时,重新按照公式(2)~(4)计算每个空闲服务器包含的每个分区对应的热点分数,然后再将所有空闲服务器中,热点分数最低的分区所属的空闲服务器,作为本次遍历对应的目标服务器。
[0144]
直至取完计划列表中的均衡计划,完成本次均衡。
[0145]
可选的,本步骤可以通过图7所示的region迁移计划执行器实现。
[0146]
需要说明的是,如果一次均衡未达到均衡目标,可以按照本技术提供的数据均衡方法执行多次均衡,以更好地提高服务器集群的整体性能和稳定性。
[0147]
本技术实施例还提供了一种数据均衡装置,下面对本技术实施例提供的数据均衡装置进行描述,下文描述的数据均衡装置与上文描述的数据均衡方法可相互对应参照。
[0148]
请参阅图8,示出了本技术实施例提供的数据均衡装置的结构示意图,如图8所示,该数据均衡装置可以包括:指标数据采集模块801、热点空闲服务器确定模块802、待迁移子分区确定模块803和待迁移子分区迁移模块804。
[0149]
指标数据采集模块801,用于采集服务器集群中每个服务器的运行状态指标数据,其中,服务器集群中每个服务器包含至少一个分区,每个分区内包含至少一个数据存储文件,运行状态指标数据能够反映对应服务器的负载情况。
[0150]
热点空闲服务器确定模块802,用于根据服务器集群中每个服务器的运行状态指标数据,确定服务器集群中的热点服务器和空闲服务器。
[0151]
待迁移子分区确定模块803,用于获取热点服务器和空闲服务器分别包含的每个数据存储文件的相关信息,并根据热点服务器包含的每个数据存储文件的相关信息,从热点服务器包含的每个热点分区中确定待迁移子分区,其中,相关信息能够反映对应数据存储文件包含的数据是否为热点数据。
[0152]
待迁移子分区迁移模块804,用于将热点服务器包含的每个热点分区中的待迁移子分区迁移到空闲服务器中。
[0153]
本技术提供的数据均衡装置,首先指标数据采集模块采集服务器集群中每个服务器的运行状态指标数据,然后热点空闲服务器确定模块根据服务器集群中每个服务器的运行状态指标数据,确定服务器集群中的热点服务器和空闲服务器,接着待迁移子分区确定模块获取热点服务器和空闲服务器分别包含的每个数据存储文件的相关信息,并根据热点服务器包含的每个数据存储文件的相关信息,从热点服务器包含的每个热点分区中确定待迁移子分区,最后待迁移子分区迁移模块将热点服务器包含的每个热点分区中的待迁移子分区迁移到空闲服务器中。本技术能够根据采集的运行状态指标数据确定出热点服务器和空闲服务器,然后再将热点服务器包含的热点分区中的待迁移子分区迁移到空闲服务器,提高了服务器集群热点数据的均衡效果。
[0154]
在一种可能的实现方式中,指标数据采集模块801具体可以用于采集服务器集群中每个服务器的性能指标数据、堆内存指标数据和业务系统指标数据。
[0155]
在一种可能的实现方式中,热点空闲服务器确定模块802可以包括:运行状态向量确定单元、负载相关值确定单元和热点空闲服务器确定单元。
[0156]
其中,运行状态向量确定单元,用于将服务器集群中每个服务器的运行状态指标
数据映射为向量,得到的向量作为服务器集群中每个服务器的运行状态向量。
[0157]
负载相关值确定单元,用于根据服务器集群中每个服务器的运行状态向量,确定服务器集群中每个服务器对应的负载相关值。
[0158]
热点空闲服务器确定单元,用于根据预设的相关值阈值和筛选个数,以及,服务器集群中每个服务器对应的负载相关值,确定服务器集群中的热点服务器和空闲服务器。
[0159]
在一种可能的实现方式中,负载相关值确定单元具体可以用于将服务器集群中每个服务器的运行状态向量输入到预先训练的神经网络模型中,得到服务器集群中每个服务器对应的负载相关值,其中,神经网络模型采用训练运行状态向量和训练运行状态向量对应的标注负载相关值进行训练。
[0160]
在一种可能的实现方式中,热点空闲服务器确定单元可以包括:待筛选服务器确定单元和热点空闲服务器筛选单元。
[0161]
其中,待筛选服务器确定单元,用于将服务器集群中每个服务器对应的负载相关值分别与预设的热点相关值阈值和空闲相关值阈值进行比较,得到负载相关值大于热点相关值阈值的服务器,作为待筛选热点服务器,以及,负载相关值小于空闲相关值阈值的服务器,作为待筛选空闲服务器。
[0162]
热点空闲服务器筛选单元,用于根据热点筛选个数,从待筛选热点服务器中确定热点服务器,并根据空闲筛选个数,从待筛选空闲服务器中确定空闲服务器。
[0163]
在一种可能的实现方式中,待迁移子分区确定模块803可以包括:热点分区确定单元和待迁移子分区确定单元。
[0164]
其中,热点分区确定单元,用于根据热点服务器包含的每个数据存储文件的相关信息,从热点服务器包含的分区中确定预设数目个热点分区。
[0165]
待迁移子分区确定单元,用于根据热点服务器包含的每个热点分区所包含的数据存储文件的相关信息,从热点服务器包含的每个热点分区中确定待迁移子分区。
[0166]
在一种可能的实现方式中,热点分区确定单元可以包括:第一热点分数计算单元、第二热点分数计算单元和热点分区筛选单元。
[0167]
其中,第一热点分数计算单元,用于根据热点服务器包含的每个数据存储文件的相关信息,计算热点服务器包含的每个数据存储文件对应的热点分数。
[0168]
第二热点分数计算单元,用于根据热点服务器包含的每个数据存储文件对应的热点分数,确定热点服务器包含的每个分区对应的热点分数。
[0169]
热点分区筛选单元,用于根据热点服务器包含的每个分区对应的热点分数,从热点服务器包含的分区中确定预设数目个热点分区。
[0170]
在一种可能的实现方式中,待迁移子分区确定单元可以包括:切分点确定单元、分区切分单元和热点分数比较单元。
[0171]
其中,切分点确定单元,用于对于热点服务器包含的每个热点分区,从该热点分区中确定热点分数最高的数据存储文件,在热点分数最高的数据存储文件中设置切分点,作为该热点分区对应的切分点;
[0172]
分区切分单元,用于基于热点服务器包含的每个热点分区对应的切分点,将热点服务器包含的每个热点分区切分为两个子分区,以得到热点服务器包含的每个热点分区所包含的两个子分区;
[0173]
热点分数比较单元,用于对于热点服务器包含的每个热点分区,根据该热点分区包含的两个子分区分别包含的数据存储文件的相关信息,计算该热点分区包含的两个子分区分别对应的热点分数,并将该热点分区包含的两个子分区中,对应热点分数高的子分区作为该热点分区中的待迁移子分区。
[0174]
在一种可能的实现方式中,待迁移子分区迁移模块804具体可以用于按照热点服务器包含的每个分区对应的热点分数,遍历热点服务器包含的每个热点分区,对于当前遍历到的热点分区,从空闲服务器中确定目标服务器,将当前遍历到的热点分区中的待迁移子分区迁移到目标服务器。
[0175]
本技术实施例还提供了一种数据均衡设备。可选的,图9示出了数据均衡设备的硬件结构框图,参照图9,该数据均衡设备的硬件结构可以包括:至少一个处理器901,至少一个通信接口902,至少一个存储器903和至少一个通信总线904;
[0176]
在本技术实施例中,处理器901、通信接口902、存储器903、通信总线904的数量为至少一个,且处理器901、通信接口902、存储器903通过通信总线904完成相互间的通信;
[0177]
处理器901可能是一个中央处理器cpu,或者是特定集成电路asic(application specific integrated circuit),或者是被配置成实施本发明实施例的一个或多个集成电路等;
[0178]
存储器903可能包含高速ram存储器,也可能还包括非易失性存储器(non-volatile memory)等,例如至少一个磁盘存储器;
[0179]
其中,存储器903存储有程序,处理器901可调用存储器903存储的程序,所述程序用于:
[0180]
采集服务器集群中每个服务器的运行状态指标数据,其中,服务器集群中每个服务器包含至少一个分区,每个分区内包含至少一个数据存储文件,运行状态指标数据能够反映对应服务器的负载情况;
[0181]
根据服务器集群中每个服务器的运行状态指标数据,确定服务器集群中的热点服务器和空闲服务器;
[0182]
获取热点服务器和空闲服务器分别包含的每个数据存储文件的相关信息,并根据热点服务器包含的每个数据存储文件的相关信息,从热点服务器包含的每个热点分区中确定待迁移子分区,其中,相关信息能够反映对应数据存储文件包含的数据是否为热点数据;
[0183]
将热点服务器包含的每个热点分区中的待迁移子分区迁移到空闲服务器中。
[0184]
可选的,所述程序的细化功能和扩展功能可参照上文描述。
[0185]
本技术实施例还提供一种可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现如上述数据均衡方法。
[0186]
可选的,所述程序的细化功能和扩展功能可参照上文描述。
[0187]
最后,还需要说明的是,在本文中,诸如和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在
包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
[0188]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
[0189]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本技术。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本技术的精神或范围的情况下,在其它实施例中实现。因此,本技术将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。