技术特征:
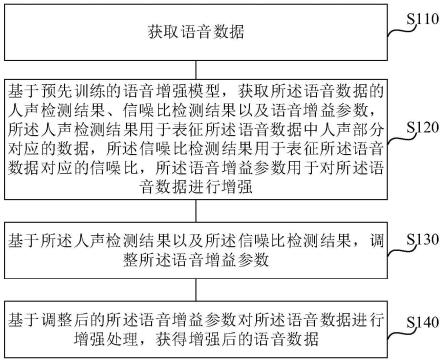
1.一种语音增强方法,其特征在于,所述方法包括:获取语音数据;基于预先训练的语音增强模型,获取所述语音数据的人声检测结果、信噪比检测结果以及语音增益参数,所述人声检测结果用于表征所述语音数据中人声部分对应的数据,所述信噪比检测结果用于表征所述语音数据对应的信噪比,所述语音增益参数用于对所述语音数据进行增强;基于所述人声检测结果以及所述信噪比检测结果,调整所述语音增益参数;基于调整后的所述语音增益参数对所述语音数据进行增强处理,获得增强后的语音数据。2.根据权利要求1所述的方法,其特征在于,所述基于所述人声检测结果以及所述信噪比检测结果,调整所述语音增益参数,包括:基于所述人声检测结果以及所述信噪比检测结果,确定所述语音数据中的第一数据以及第二数据,所述第一数据为人声占比大于预设比例的数据,所述第二数据为所述语音数据中除所述第一数据以外的数据;降低所述第一数据对应的所述语音增益参数,以及提升所述第二数据对应的所述语音增益参数。3.根据权利要求2所述的方法,其特征在于,所述基于所述人声检测结果以及所述信噪比检测结果,确定所述语音数据中的第一数据以及第二数据,包括:基于所述人声检测结果,确定所述语音数据中人声部分对应的数据,作为第三数据;基于所述信噪比检测结果,从所述第三数据中确定出信噪比大于预设信噪比的数据,作为所述第一数据,所述预设信噪比基于所述预设比例设置;从所述语音数据中获取除所述第一数据以外的数据,作为所述第二数据。4.根据权利要求1所述的方法,其特征在于,所述语音增强模型通过如下步骤进行训练:获取所述样本语音集合,所述样本语音集合包括多段混噪语音,每段所述混噪语音被标注有人声标签以及信噪比标签,所述每段混噪语音由干净语音样本以及噪声样本进行混噪得到,所述人声标签用于表征所述混噪语音中人声部分对应的数据,所述信噪比标签用于表征所述混噪语音对应的信噪比;根据所述样本语音集合,以及所述混噪语音对应的干净语音样本和噪声样本,对初始增强模型进行训练,直到初始增强模型满足预设条件,得到训练后的语音增强模型。5.根据权利要求4所述的方法,其特征在于,所述初始增强模型包括第一输入模块、第一输出模块、第二输出模块以及第三输出模块,所述根据所述样本语音集合,以及所述混噪语音对应的干净语音样本和噪声样本,对初始增强模型进行训练,直到初始增强模型满足预设条件,得到训练后的语音增强模型,包括:将所述混噪语音对应的幅度谱输入至所述第一输入模块,获得所述混噪语音对应的隐藏表征,以及基于所述隐藏特征得到的初始语音增益参数;将所述隐藏表征分别输入至所述第一输出模块、第二输出模块以及第三输出模块,得到所述第一输出模块输出的初始人声检测结果,所述第二输出模块输出的初始信噪比检测结果,以及所述第三输出模块输出的初始噪声幅度谱;
基于所述混噪语音标注的标签数据、所述初始语音增益参数、所述初始人声检测结果、所述初始信噪比检测结果、所述初始噪声幅度谱、以及所述混噪语音对应的干净语音样本和噪声样本,确定所述初始增强模型的总损失值;根据所述总损失值,对所述初始增强模型进行迭代训练,直至所述初始增强模型满足预设条件。6.根据权利要求5所述的方法,其特征在于,所述基于所述混噪语音标注的标签数据、所述初始语音增益参数、所述初始人声检测结果、所述初始信噪比检测结果、所述初始噪声幅度谱、以及所述混噪语音对应的干净语音样本和噪声样本,确定所述初始增强模型的总损失值,包括:基于增强幅度谱与所述干净语音样本对应的幅度谱之间的差异,确定第一损失值,所述增强幅度谱基于所述初始语音增益参数对所述混噪语音对应的幅度谱进行增强处理得到;基于所述初始人声检测结果与所述人声标签之间的差异,确定第二损失值;基于所述初始信噪比检测结果,与所述信噪比标签之间的差异,确定第三损失值;基于所述初始噪声幅度谱与所述噪声样本对应的幅度谱之间的差异,确定第四损失值;基于所述第一损失值、第二损失值、第三损失值以及第四损失值,确定所述初始增强模型的总损失值。7.根据权利要求4所述的方法,其特征在于,所述获取所述样本语音集合,包括:获取多个干净语音样本以及多个噪声样本;获取对所述干净语音中的人声段以及非人声段进行标注的人声标签;将所述干净语音以及噪声按照不同的信噪比进行混合,得到多段所述混噪语音;基于混合每段所述混噪语音时采用的信噪比,对每段所述混噪语音标注信噪比标签,以及基于所述干净语音的人声标签对每段所述混噪语音标注人声标签,得到所述样本语音集合。8.根据权利要求7所述的方法,其特征在于,在所述根据所述样本语音集合,以及所述混噪语音对应的干净语音样本和噪声样本,对初始增强模型进行训练,直到初始增强模型满足预设条件,得到训练后的语音增强模之前,所述方法还包括:对所述多段混噪语音中的部分混噪语音进行混响处理,将混响处理后的混噪语音加入所述样本语音集合。9.一种语音增强装置,其特征在于,所述装置包括:语音获取模块、数据获取模块、增益调整模块以及语音增强模块,其中,所述语音获得模块用于获取语音数据;所述数据获取模块用于基于预先训练的语音增强模型,获取所述语音数据的人声检测结果、信噪比检测结果以及语音增益参数,所述人声检测结果用于表征所述语音数据中人声部分对应的数据,所述信噪比检测结果用于表征所述语音数据对应的信噪比,所述语音增益参数用于对所述语音数据进行增强;所述增益调整模块用于基于所述人声检测结果以及所述信噪比检测结果,调整所述语音增益参数;
所述语音增强模块用于基于调整后的所述语音增益参数对所述语音数据进行增强处理,获得增强后的语音数据。10.一种计算机设备,其特征在于,所述计算机设备包括:一个或多个处理器;存储器;一个或多个应用程序,其中所述一个或多个应用程序被存储在所述存储器中并被配置为由所述一个或多个处理器执行,所述一个或多个程序配置用于执行如权利要求1-8任一项所述的方法。11.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质中存储有程序代码,所述程序代码可被处理器调用执行如权利要求1-8任一项所述的方法。
技术总结
本申请公开了一种语音增强方法、装置、计算机设备及存储介质。该方法包括获取语音数据;基于预先训练的语音增强模型,获取语音数据的人声检测结果、信噪比检测结果以及语音增益参数,所述人声检测结果用于表征语音数据中人声部分对应的数据,所述信噪比检测结果用于表征语音数据对应的信噪比,语音增益参数用于对语音数据进行增强;基于人声检测结果以及信噪比检测结果,调整语音增益参数;基于调整后的语音增益参数对语音数据进行增强处理,获得增强后的语音数据。本方法能够实现对语音数据的动态增强,提升语音数据的清晰度和可懂度。提升语音数据的清晰度和可懂度。提升语音数据的清晰度和可懂度。
技术研发人员:于洪伟 陈东鹏
受保护的技术使用者:深圳市声扬科技有限公司
技术研发日:2022.03.18
技术公布日:2022/7/21
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。