1.本发明涉及视频处理与识别技术领域,具体涉及一种基于transformer第一视角下的下一个交互物体预测方法。
背景技术:
2.第一视角视频是通过头戴式摄像机以人眼的视角捕捉的视频。交互物体是指人在发生动作时候,施加动作的对象物体,即人与物体交互。在第一视角视频下,对于交互物体的识别对于第一视角视频下的行为识别的性能具有显著影响。行为识别是指识别出当前的动作,行为预期指识别未来的动作。在第一视角视频下,行为预期任务相比起行为识别问题难度更大,也更有意义。因为第一视角下的视频的行为预期可以反应出人的意图,使得机器能够学习出人的意图,变得更加智能。与行为识别相同,下一个交互物体识别的性能也显著影响着行为预期任务。
3.在第一视角视频下下一个交互物体预测问题已经有相关的研究。furnari等人2017年在jvci期刊和jiang等人2021年在neurocomputing期刊提出了下一个交互物体预测的方法。但是他们的方法都需要额外的标注,比如物体检测框标注和手部框的标注,在实际应用场景中不一定能够获得这些额外的标注。在没有额外标注,只有交互物体类别作为标签的情况下,如何有效的预测下一个交互物体成为一个困难和挑战。而在第一视角的行为预期的研究上,研究主要是针对动作进行预测,并通过动作分解出动词和名词,使用名词来指代交互物体,这类方法忽视了对交互物体的预测。并且现有的研究方法只考虑已观察视频的特征并没有考虑到预测间隔的信息对下一个交互物体预测的影响。
技术实现要素:
4.为了克服现有技术存在的缺陷与不足,本发明提供一种基于transformer第一视角下的下一个交互物体预测方法,本发明将需要预测视频的特征(包括预测间隔的特征和下一个交互物体的特征)初始化为可训练的参数并与已观察视频的特征拼接作为transformer网络的输入,识别视频下的所有交互物体,通过transformer网络来获取已观察视频的特征和需要预测视频的特征之间的关系,因此本发明不仅考虑到已观察视频的特征,也考虑到预测间隔视频的特征,为了进一步利用下一个交互物体发生动作前预测间隔的特征,本发明将通过transformer网络的需要预测视频的特征进行池化,并通过分类器细化对下一个交互物体的预测,在模型效果上取得进一步提升。
5.本发明的第二目的在于提供一种基于transformer第一视角下的下一个交互物体预测系统。
6.本发明的第三目的在于提供一种存储介质。
7.本发明的第四目的在于提供一种计算设备。
8.为了达到上述目的,本发明采用以下技术方案:
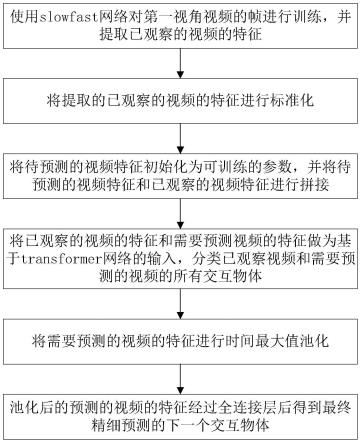
9.本发明提供一种基于transformer第一视角下的下一个交互物体预测方法,包括
下述步骤:
10.采用slowfast网络作为特征提取网络,在第一视角视频上对当前视频片段的交互物体进行识别训练,以识别交互物体;
11.将训练后的slowfast网络用于已观察视频帧的特征提取;
12.将提取的已观察视频的特征进行标准化;
13.用可训练的参数初始化待预测视频的特征;
14.将已观察视频的特征和待预测视频的特征进行拼接;
15.预处理交互物体的标签;
16.将拼接后的特征作为transformer网络和全连接分类网络的输入,对已观察和待预测的视频上的所有交互物体进行识别,使用交叉熵损失函数进行训练;
17.提取出通过transformer网络之后、全连接分类网络之前待预测的视频的特征;
18.将提取出的全连接网络之前待预测视频的特征进行池化,通过另一个全连接分类网络对下一个交互物体进行预测。
19.作为优选的技术方案,所述采用slowfast网络作为特征提取网络,在第一视角视频上对当前视频片段的交互物体进行识别训练,以识别交互物体,具体步骤包括:
20.slowfast网络在kinetics-400进行预训练,并使用预训练参数初始化slowfast网络;
21.在视频片段上随机选取视频帧作为slowfast网络的输入,在随机选取的视频帧上等间隔采样不同帧数的视频帧,分别作为fast通道和slow通道的输入;
22.对输入数据进行数据增强;
23.构建交叉熵损失函数,采用交叉熵损失函数对slowfast的预测结果交互物体的标签进行损失计算和梯度计算,并通过反向传播更新基准网络;
24.采用端到端的训练方式训练slowfast网络,设置初始学习率,在迭代训练过程中使用学习率下降策略,达到预设的迭代次数后,保存模型训练参数文件。
25.作为优选的技术方案,所述slowfast网络设有slow通道和fast通道,slow通道采用3d resnet101作为基准网络,fast通道采用3d resnet50作为基准网络。
26.作为优选的技术方案,所述将训练后的slowfast网络用于已观察视频帧的特征提取,具体步骤包括:
27.slowfast网络加载在第一视角视频上对当前视频片段的交互物体进行识别训练的参数,作为特征提取网络的初始化;
28.对于每一个交互物体的预测,从交互物体开始的时间的前σa到σa σo秒提取特征,σa为预测间隔时间,σo为观察时间;
29.以观察时间为中心提取多帧视频片段作为slowfast网络的输入,以提取特征;
30.使用slowfast网络进行特征提取时,移除最后的全连层,对于每一个交互物体的预测,已观察视频最终提取出的特征大小为n
×
c,其中,n为片段数量,c为通道大小。
31.作为优选的技术方案,所述用可训练的参数初始化待预测视频的特征,具体步骤包括:
32.f
as
=concat(fa,fs)
33.其中,fa表示预测间隔部分的特征,fs表示为下一个交互物体的特征,f
as
为拼接后
的特征,concat表示为特征拼接;
34.待预测视频的特征分为预测间隔部分和下一个交互物体交互部分,设为一组可训练参数。
35.作为优选的技术方案,所述预处理交互物体的标签,具体步骤包括:
36.伪标签的生成:在第一人称的视频片段中,如果有片段没有标注交互物体标签,如果此片段与某一有标注物体标签的片段重叠,则把此片段的标签设为与其有重叠且有标签的片段的标签;
37.如果没有任何一个有标签的片段与其重叠,则将此片段的交互物体标签设置为与其距离最近的有标签的视频片段的交互物体标签;
38.进行标签平滑处理,具体表示为:
[0039][0040]
其中,y为one-hot标签,α为平滑参数,k代表标签的数量。
[0041]
作为优选的技术方案,所述将提取出的全连接网络之前待预测视频的特征进行池化,通过另一个全连接分类网络对下一个交互物体进行预测,具体计算公式为:
[0042]yp
=mlp(maxpool(f
as
))
[0043]
其中,y
p
表示预测的结果,mlp表示全连接层,maxpool表示时间最大值池化,f
as
表示通过transformer网络的需要预测视频的特征。
[0044]
为了达到上述第二目的,本发明采用以下技术方案:
[0045]
一种基于transformer第一视角下的下一个交互物体预测系统,包括:特征提取网络构建模块、已观察视频帧特征提取模块、待预测视频特征初始化模块、视频特征拼接模块、标签预处理模块、交互物体识别模块、待预测视频特征提取模块和下一个交互物体预测模块;
[0046]
所述特征提取网络构建模块用于采用slowfast网络作为特征提取网络,在第一视角视频上对当前视频片段的交互物体进行识别训练,以识别交互物体;
[0047]
所述已观察视频帧特征提取模块用于采用训练后的slowfast网络提取已观察视频帧的特征;
[0048]
所述待预测视频特征初始化模块用于使用一组可训练的参数取表示待预测视频的特征;
[0049]
所述视频特征拼接模块用于将可观察视频和待预测视频的特征在时间维度上进行拼接;
[0050]
所述标签预处理模块用于预处理交互物体的标签;
[0051]
所述交互物体识别模块用于将拼接后的特征作为transformer网络和全连接分类网络的输入,对已观察和待预测的视频上的所有交互物体进行识别,使用交叉熵损失函数进行训练;
[0052]
所述待预测视频特征提取模块用于提取出通过transformer网络之后、全连接分类网络之前待预测的视频的特征;
[0053]
所述下一个交互物体预测模块用于将提取出的全连接网络之前待预测视频的特征进行池化,通过另一个全连接分类网络对下一个交互物体进行预测。
[0054]
为了达到上述第三目的,本发明采用以下技术方案:
[0055]
一种计算机可读存储介质,存储有程序,所述程序被处理器执行时实现上述基于transformer第一视角下的下一个交互物体预测方法。
[0056]
为了达到上述第四目的,本发明采用以下技术方案:
[0057]
一种计算设备,包括处理器和用于存储处理器可执行程序的存储器,所述处理器执行存储器存储的程序时,实现上述基于transformer第一视角下的下一个交互物体预测方法。
[0058]
本发明与现有技术相比,具有如下优点和有益效果:
[0059]
本发明不仅考虑到已观察视频的特征,还考虑到预测间隔的环境信息对下一个交互物体预测的影响,将需要预测视频的特征设为一组可训练的参数,并通过transformer学习它们和已观察视频特征的关系,最后通过最大值池化需要预测视频的特征来细化对下一个交互物体的预测,这种方案解决了当前技术中各支路仅仅考虑已观察视频的信息来预测下一个交互物体,而忽略预测间隔信息的问题,并且在epic-kitchens公开数据集上提升3.2%的效果,验证了该解决方案的有效性,证明考虑到预测间隔视频的环境信息的重要性。
附图说明
[0060]
图1为本发明基于transformer第一视角下的下一个交互物体预测方法的流程示意图;
[0061]
图2为本发明基于transformer第一视角下的下一个交互物体预测方法的整体框架示意图;
[0062]
图3为本发明基于transformer第一视角下的下一个交互物体预测方法的baseline的框架图。
具体实施方式
[0063]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0064]
实施例1
[0065]
如图1、图2所示本发明提供一种基于transformer第一视角下的下一个交互物体预测方法,包括下述步骤:
[0066]
s1:采用在kinetics-400预训练的slowfast网络作为特征提取网络,在第一视角视频上对当前视频片段的交互物体进行识别训练,以识别交互物体;
[0067]
在本实施例中,slowfast网络结构包括slow通道和fast通道,slow通道采用3d resnet101作为基准网络,fast通道采用3d resnet50作为基准网络。
[0068]
具体步骤为:
[0069]
由于第一视角的视频数据的大小远小于第三视角视频的数据的大小,从头开始学习模型是有难度的,因此借鉴迁移学习的方法,slowfast网络先在kinetics-400进行预训练,并将训练得到的参数初始化slowfast网络,而slowfast的分类器采用随机初始化;
[0070]
在60fps的视频片段上随机选取128帧作为slowfast网络的输入,其中fast通道的输入为在128帧的视频等间隔采样64帧,slow通道的输入在128帧的视频等间隔采样16帧;
[0071]
对输入数据进行数据增强,包括在将图像随机缩放到224-288的大小;图像中随机剪裁224x224的部分图像作为网络的输入;以0.5的概率随机翻转,以0.5的概率随机丢弃神经元;
[0072]
构建交叉熵损失函数,采用交叉熵损失函数对slowfast的预测结果交互物体的标签进行损失计算和梯度计算,并通过反向传播更新基准网络;
[0073]
slowfast的训练方法采用端到端的训练方式,设置初始学习率,在迭代训练过程中使用学习率下降策略,迭代训练30轮后,保存模型训练参数文件。
[0074]
s2:将训练过的slowfast用于已观察视频帧的特征提取;
[0075]
在本实施例中,slowfast网络加载在第一视角视频上对当前视频片段的交互物体进行识别训练的参数,作为特征提取网络的初始化;
[0076]
对于每一个交互物体的预测,从交互物体开始的时间的前σa到σa σo秒提取特征,其中σa为预测间隔通常为1秒,σo为观察时间,在本发明中将σo固定为6秒;
[0077]
可观察视频的输入片段为9个,分别从σo=1s,1.5s,2s,2.5s,3s,3.5s,4s,4.5,5s为中心提取128帧的视频片段作为slowfast网络的输入,以提取特征;
[0078]
在进行特征提取的时候,直接输入整张图像,不进行任何裁剪;
[0079]
使用slowfast网络进行特征提取时,移除最后的全连层,对于每一个交互物体的预测,已观察视频最终提取出的特征大小为n
×
c,其中n为片段数量,在本实施例优选为9,c为通道大小,本实施例优选为2304。
[0080]
s3:将提取的已观察视频的特征进行标准化,将已观察的视频的特征减去均值,除以方差;
[0081]
s4:用可训练的参数初始化需要预测视频(包括预测间隔和下一个交互物体的视频)的特征;
[0082]
在本实施例中,可表示为:
[0083]fas
=concat(fa,fs)
[0084]
需要预测视频可以分为预测间隔部分和下一个交互物体交互部分,设为一组可训练参数。其中fa表示预测间隔部分的特征,大小为na×
c,fs表示为下一个交互物体的特征,大小为ns×
c,f
as
为拼接后的特征,大小为(na ns)
×
c,concat表示为特征拼接。
[0085]
s5:将已观察视频的特征和待预测视频的特征进行拼接;
[0086]
在本实施例中,具体可表示为:
[0087]foas
=concat(fo,f
as
)
[0088]
其中fo表示已观察视频的特征,大小为no×
c,f
as
表示为需要预测视频的特征,大小为n
as
×
c,fo为拼接后的特征,大小为(no n
as
)
×
c,concat表示为特征拼接。
[0089]
s6:预处理交互物体的标签;
[0090]
s61:伪标签的生成:在第一人称的视频片段中,如果有片段没有标注交互物体标签,如果此片段与某一有标注物体标签的片段重叠,则把此片段的标签设为与其有重叠且有标签的片段的标签。如果没有任何一个有标签的片段与其重叠,则将此片段的交互物体标签设置为与其距离最近的有标签的视频片段的交互物体标签;
[0091]
s62:label smoothing(标签平滑),软化标签的分布,降低正确标签的置信度,并提高其余标签的置信度,具体可以表示为:
[0092][0093]
其中y为one-hot标签,α为平滑参数,范围在0-1之间,在本实施例设置为0.4。k代表标签的数量。
[0094]
s7:将拼接后的特征作为transformer网络和全连接分类网络的输入,对已观察和需要预测的视频上的所有交互物体进行识别,使用交叉熵损失函数进行训练;
[0095]
如图2所示,transformer网络由两个transformer模块串联,其中每一个transformer模块由layer norm、mulit-head attention、layer norm和mlp串联,并添加两个shortcut连接;
[0096]
在本实施例中,采用交叉熵损失函数进行训练,可表示为:
[0097][0098][0099]
其中,t代表所有的视频片段的数目,即交互物体的标签数,为交叉熵损失,l
cls
为所有交互物体的损失的和。
[0100]
s8:提取出通过transformer网络后,全连接分类网络前时需要预测的视频的特征;
[0101]
s9:将提取出的全连接网络之前需要预测视频的特征进行时间最大值池化,通过另一个全连接分类网络对下一个交互物体进行预测;
[0102]
如图2所示,具体可表示为:
[0103]yp
=mlp(maxpool(f
as
))
[0104]
其中y
p
代表预测的结果,mlp代表全连接层,maxpool代表时间最大值池化,f
as
为通过transformer网络的需要预测视频的特征。
[0105]
在本实施例中,使用交叉熵损失,可表示为:
[0106]
l
next
=-y
t
kogy
p
[0107]
网络采用总交叉熵损失函数进行损失计算和梯度计算,具体设置平衡参数,用于调节l
next
与l
cls
的比重,具体表示为:
[0108]
l
total
=αl
cls
βl
next
[0109]
其中,α,β为超参数,在本实施例中α=β=0.5;
[0110]
网络的具体的训练为:采用adamw优化器对网络进行参数更新,批尺寸固定为128,初始学习率设置为1e-4,总共训练20个epoch,采用余弦退火策略使得学习率下降到20epoch的时候学习率为零。
[0111]
为了验证本发明的有效性,在第一视角下的视频epic-kitchens数据集上进行了实验,标签为名词noun,即交互物体,采用class-mean recall@5的衡量标准,其计算方法为:首先得到所有样本每一类的confidence score,再对confidence score进行排序,针对
标签中每一类计算出top-5recall,最后对所有类的top-5recall取平均得到class-mean recall@5。
[0112]
本发明对比实验结果如下表1所示,表1中,第一栏为基础transformer模型,即如图3所示;第二栏为使用本发明考虑预测间隔的环境信息之后的模型,结合图2所示,可以看到本发明的方法对比基础模型有明显提升。
[0113]
表1性能对比表
[0114]
methodclass-mean recall@5(noun)baseline30.1baseline 本发明33.3
[0115]
如下表2所示,本发明与当前最好效果的已发表方法在epic-kitchens上的结果进行对比,由此证明本发明的算法的有效性。
[0116]
表2本发明与其它方法在epic-kitchens上的对比数据表
[0117][0118][0119]
实施例2
[0120]
本实施例提供一种基于transformer第一视角下的下一个交互物体预测系统,包括:特征提取网络构建模块、已观察视频帧特征提取模块、待预测视频特征初始化模块、视频特征拼接模块、标签预处理模块、交互物体识别模块、待预测视频特征提取模块和下一个交互物体预测模块;
[0121]
在本实施例中,特征提取网络构建模块用于采用slowfast网络作为特征提取网络,在第一视角视频上对当前视频片段的交互物体进行识别训练,以识别交互物体;
[0122]
在本实施例中,已观察视频帧特征提取模块用于采用训练后的slowfast网络提取已观察视频帧的特征;
[0123]
在本实施例中,待预测视频特征初始化模块用于使用一组可训练的参数取表示待预测视频的特征;
[0124]
在本实施例中,视频特征拼接模块用于将可观察视频和待预测视频的特征在时间维度上进行拼接;
[0125]
在本实施例中,标签预处理模块用于预处理交互物体的标签;
[0126]
在本实施例中,交互物体识别模块用于将拼接后的特征作为transformer网络和全连接分类网络的输入,对已观察和待预测的视频上的所有交互物体进行识别,使用交叉熵损失函数进行训练;
[0127]
在本实施例中,待预测视频特征提取模块用于提取出通过transformer网络之后、全连接分类网络之前待预测的视频的特征;
[0128]
在本实施例中,下一个交互物体预测模块用于将提取出的全连接网络之前待预测视频的特征进行池化,通过另一个全连接分类网络对下一个交互物体进行预测。
[0129]
实施例3
[0130]
本实施例提供一种存储介质,存储介质可以是rom、ram、磁盘、光盘等储存介质,该存储介质存储有一个或多个程序,程序被处理器执行时,实现实施例1的基于transformer第一视角下的下一个交互物体预测方法。
[0131]
实施例4
[0132]
本实施例提供一种计算设备,该计算设备可以是台式电脑、笔记本电脑、智能手机、pda手持终端、平板电脑或其他具有显示功能的终端设备,该计算设备包括处理器和存储器,存储器存储有一个或多个程序,处理器执行存储器存储的程序时,实现实施例1的基于transformer第一视角下的下一个交互物体预测方法。
[0133]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。