1.本发明涉及一种网络广告作弊行为的检测领域,具体涉及一种低速率作弊流量的检测方法及装置。
背景技术:
2.本部分的描述仅提供与本发明公开相关的背景信息,而不构成现有技术。
3.随着信息技术的快速发展,网络广告业务不断增加,网络广告作弊行为也随之暴露并有指数上涨的趋势。网络广告作弊行为——作弊流量是指以谋取不正当利益为目的,利用自动化脚本技术或人工模拟正常网络用户对网络广告进行交互的行为。作弊流量不仅直接损害了广告主的经济利益,而且也降低了广告平台的商业信用和公众信誉。因此,如何高效识别及过滤作弊流量是广告行业的当务之急。在现有方案中,绝大多数方案可高效识别自动脚本生成的作弊流量,但在人工点击的作弊流量识别以及低速率随机生成的作弊流量识别表现欠佳。
4.应该注意,上面对技术背景的介绍只是为了方便对本发明的技术方案进行清楚、完整的说明,并方便本领域技术人员的理解而阐述的。不能仅仅因为这些方案在本发明的背景技术部分进行了阐述而认为上述技术方案为本领域技术人员所公知。
技术实现要素:
5.本发明要解决的技术问题是提供一种低速率作弊流量的检测方法及装置。
6.为了解决上述技术问题,一种低速率作弊流量的检测方法,包括,
7.字符型特征处理:得到字符型特征的异常评分s
str
;
8.数值型特征处理:得到数值型特征的异常评分s
num
;
9.数据集标识化:根据字符型特征的异常评分s
str
及数值型特征的异常评分s
num
,得到最终样本评价得分score
fin
。
10.优选地,所述的字符特征处理包括,
11.针对字符特征,进行编码处理;
12.判断编码处理后的字段是否为空,采用示性函数表达空字段的影响程度,其中s
null
>s
ok
,当字段为空时,i=s
null
,当字段不为空时,i=s
ok
,
[0013][0014]
字段概率统计:字段概率值为其中n表示字符特征的数量,ci表示某类字符特征;
[0015]
异常评分设置:计算字符型特征的异常评分s
str
,
[0016]sstr
=i*(1-prc)
ꢀꢀꢀ
(2)。
[0017]
优选地,所述的数值型特征处理包括,
[0018]
空值处理:采用示性函数表达空字段的影响程度,其中s
null
>s
ok
,当字段为空时,i=s
null
,当字段不为空时,i=s
ok
;
[0019][0020]
标准化处理:使数据服从正态分布;
[0021]
基于高斯核函数的相似度计算:通过使用核函数,将标准化处理好的数据映射至高维的特征空间中,式(3)中,使用高斯核函数进行相似度计算,式(4)是计算欧式距离的公式,其中d为权重,α={α1,α2,...,αn},其中
[0022][0023][0024]
异常评分设置:式(5)中,根据已知的异常样本计算未知数据的异常评分,得到数值特征异常评分s
num
,
[0025][0026]
所述的数据集标识化包括,计算最终样本评价得分score
fin
,其中,ω
p
为分配给s
str
的权重,
[0027]
score
fin
=ω
psstr
(1-ω
p
)s
num
ꢀꢀꢀ
(6)。
[0028]
优选地,所述的检测方法还包括数据清洗,所述的数据清洗包括,
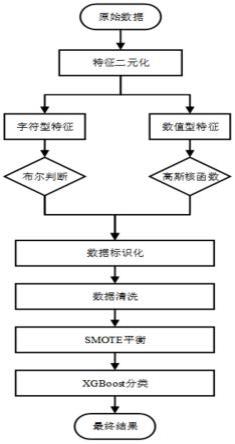
[0029]
基于严格策略的标识异常:计算字符型特征的异常评分s
str
与数值特征异常评分s
num
的差值,当差值在设定阈值内时,输出数据样本,当差值超过设定阈值时,将该类数据样本进行人工审计,判断该类样本是否为可用样本集,当判断为可采集样本时,输出该可采集数据样本集,当判断为不可采集样本时,则丢弃样本,
[0030]
所述的数据清洗还包括,基于广告效果的标识异常:当最终样本评价得分score
fin
不在预设范围内,则该广告效果标识异常,当该广告效果被标识异常,则将历史数据中所有相同类别的内容标识异常,并通过人工审计的方式决定该类样本是否为可用样本集,当广告效果标识为非异常则进行基于严格策略的标识异常的步骤,
[0031]
所述的检测方法还包括经过数据清洗后的数据样本集做数据平衡处理,所述的数据平衡包括,
[0032]
计算少数类样本k个邻近:基于交叉验证找到k值,式(7)中,基于欧式距离,计算每一个少数类样本到k个邻近的距离,
[0033][0034]
计算待合成样本量:amount
com
=amount
multi-amount
less
ꢀꢀꢀ
(8),其中,amount
multi
为数据集中正常流量数量,amount
less
为数据集中作弊流量数量;
[0035]
随机线性插值:采用可放回抽样的方式在这k条“直线”上随机选择要添加的合成少数类样本,其中,合成样本的位置由式(8)决定,x为原始样本点位置,为领近点位置,x
new
为合成样本的位置,
[0036][0037]
所述的数据平衡还包括数据融合,所述的数据融合包括将合成样本与原始样本进行拼接,以合成一个等比的正负样本数据集。
[0038]
优选地,所述的检测方法还包括,基于sk-learn库直接调用xgboost模型对数据集进行分类,其中超参数有max_depth,eta,objective,通过调节所述超参数来提高模型的分类准确率,其中目标函数objective,如式10、11所示,
[0039][0040][0041]
其中,表示模型的预测值,yi表示第i个样本的类别标签,k表示树的数量,fk表示第k棵树模型,t表示每棵树的叶子节点数量,w表示每棵树的叶子节点的分数组成的集合,γ和λ表示系数,在实际应用中需要调参。
[0042]
本技术是提供一种低速率作弊流量的检测装置,所述的检测装置包括,字符型特征处理模块,用于得到字符型特征的异常评分s
str
;
[0043]
数值型特征处理模块,用于得到数值型特征的异常评分s
num
;
[0044]
数据集标识化模块,用于根据字符型特征的异常评分s
str
及数值型特征的异常评分s
num
,得到最终样本评价得分score
fin
。
[0045]
优选地,所述的字符型特征处理模块包括,
[0046]
编码处理子模块,用于针对字符特征,进行编码处理;
[0047]
判空子模块,用于判断编码处理后的字段是否为空,采用示性函数表达空字段的影响程度,其中s
null
>s
ok
,当字段为空时,i=s
null
,当字段不为空时,i=s
ok
,
[0048][0049]
字段概率统计子模块,用于计算字段概率值为其中n表示字符特征的数量,ci表示某类字符特征;
[0050]
字符型特征异常评分设置子模块,用于计算字符型特征的异常评分s
str
,
[0051]sstr
=i*(1-pre)
ꢀꢀꢀ
(2),
[0052]
所述的数值型特征处理模块包括,
[0053]
空值处理子模块,用于采用示性函数表达空字段的影响程度,其中s
null
>s
ok
,当字段为空时,i=s
null
,当字段不为空时,i=s
ok
,
[0054][0055]
标准化处理子模块,用于使数据服从正态分布;
[0056]
基于高斯核函数的相似度计算子模块,用于通过使用核函数,将处理好的数据映射至高维的特征空间中,式(3)中,使用高斯核函数进行相似度计算,式(4)是计算欧式距离的公式,其中α为权重,α={α1,α2,...,αn},其中
[0057][0058][0059]
数值型特征异常评分设置子模块,用于根据已知的异常样本计算未知数据的异常评分,得到数值特征异常评分s
num
,
[0060][0061]
所述的数据集标识化模块计算最终样本评价得分score
fin
,其中,ω
p
为分配给s
str
的权重,
[0062]
score
fin
=ω
psstr
(1-ω
p
)s
num
ꢀꢀꢀ
(6)。
[0063]
优选地,所述的检测装置还包括,数据清洗模块和数据平衡模块,
[0064]
所述的数据清洗模块,用于严格策略的标识异常,计算字符型特征的异常评分s
str
与数值特征异常评分s
num
的差值,当差值在设定阈值内时,输出数据样本,当差值超过设定阈值时,将该类数据样本进行人工审计,判断该类样本是否为可用样本集,当判断为可采集样本时,输出可采集数据样本集,当判断为不可采集样本时,则丢弃样本;
[0065]
所述的数据清洗模块还用于基于广告效果的标识异常子,当最终样本评价得分score
fin
不在预设范围内,则该广告效果标识异常,当该广告效果被标识异常,则将历史数据中所有相同类别的内容标识异常,并通过人工审计的方式决定该类样本是否为可用样本集,当广告效果标识为非异常则进行基于严格策略的标识异常的步骤,
[0066]
所述的数据清洗模块输出的数据样本集作为所述的数据平衡模块的输入,数据平衡模块用于计算少数类样本k个邻近,基于交叉验证找到k值,式(7)中,基于欧式距离,计算每一个少数类样本到k个邻近的距离,
[0067]
[0068]
数据平衡模块还用于计算待合成样本量:amount
com
=amount
multi-amount
less
(8),其中,amount
multi
为数据集中正常流量数量,amount
less
为数据集中作弊流量数量;
[0069]
数据平衡模块还用于随机线性插值,采用可放回抽样的方式在这k条“直线”上随机选择要添加的合成少数类样本,其中,合成样本的位置由式(8)决定,x为原始样本点位置,为领近点位置,x
new
为合成样本的位置,
[0070][0071]
所述的数据平衡模块还包括数据融合子模块,所述的数据融合子模块用于将合成样本与原始样本进行拼接,以合成一个等比的正负样本数据集。
[0072]
本技术还提供一种计算机设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时,实现上述检测方法。
[0073]
本技术还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述检测方法。
[0074]
借由以上的技术方案,本发明的有益效果如下:
[0075]
本发明的低速率作弊流量的检测方法及装置,能够高效且准确的识别与检测出人工点击方式生成的作弊流量以及基本半自动化脚本生成的作弊流量,本技术将整体架构进行了解耦化,方便部署以及试错检查、此外具有良好的可扩展性和迁移性。
附图说明
[0076]
图1是本技术的低速率作弊流量检测的整体框架图;
[0077]
图2是本技术的字符类特征异常评分流程图;
[0078]
图3是本技术的数值类特征异常评分流程图;
[0079]
图4是本技术的数据清洗阶段时的逻辑流程图;
[0080]
图5是本技术实现数据平衡处理流程图。
具体实施方式
[0081]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0082]
需要说明的是,在本发明的描述中,术语“第一”、“第二”等仅用于描述目的和区别类似的对象,两者之间并不存在先后顺序,也不能理解为指示或暗示相对重要性。此外,在本发明的描述中,除非另有说明,“多个”的含义是两个或两个以上。
[0083]
参照图1为本技术的低速率作弊流量检测方法,所述的检测方法包括,字符型特征处理:得到字符型特征的异常评分s
str
;数值型特征处理:得到数值型特征的异常评分s
num
;数据集标识化:根据字符型特征的异常评分s
str
及数值型特征的异常评分s
num
,得到最终样本评价得分score
fin
;数据清洗;数据平衡;xgboost分类,得到最终结果。
[0084]
参照图2为本技术的字符类特征异常评分流程图,所述的字符类特征处理具体包括,
[0085]
针对字符特征,进行编码处理,针对字符特征,如广告账户,用户设备型号等,需要进行编码处理。由于字符特征的值类别过多,直接进行编码处理不利于模型的构建,因此在进行编码前还需要利用过滤规则将部分类似的值类别进行合并,限定其取值类别。例如:”xxx视频-13-0317”与”xxx视频-0309-30”应视为一类;
[0086]
判断编码处理后的字段是否为空,考虑到字段为空时,可能为一种异常的情况,以此为依据可为每条数据设置异常的评分值。例如,通过重放数据包的方式进行作弊,可能导致采集到的数据部分字段为空。这里采用示性函数表达空字段的影响程度,其中s
null
>s
ok
,当字段为空时,i=s
null
,当字段不为空时,i=s
ok
,
[0087][0088]
字段概率统计:某字段中各个值出现的概率不同,概率越低,异常的可能性更大,进而影响异常评分的值。例如,通过重放数据包的方式进行作弊,某个字段的值不属于合法值。字段概率值为其中n表示字符特征的数量,ci表示某类字符特征;
[0089]
异常评分设置:针对字符特征的异常评分如式2所示,当字段为空时,
[0090]
i=s
null
,异常评分值相对越高。字段值出现的概率越低,异常评分值相对越高,
[0091]sstr
=i*(1-prc)
ꢀꢀꢀ
(2)。
[0092]
参照图3是本技术的数值类特征异常评分流程图,所述的数值型特征处理包括,
[0093]
空值处理:数值特征中空值处理是模型检测不可或缺的流程。对于用以判断异常的关键字段,若其为空值,则可能为异常的情况,直接为其设置异常值。可采用式1中的示性函数表达空字段的影响程度。对于其它非关键字段,需要根据众数进行填充,用于后续模型的评估。
[0094]
标准化处理:使数据服从正态分布,便于后续相似度计算;
[0095]
基于高斯核函数的相似度计算:通过使用核函数,将处理好的数据映射至高维的特征空间中,从而在计算相似度的时候更能体现相互间的关系。具体地,式(3)中,使用高斯核函数进行相似度计算,式(4)是计算欧式距离的公式,其中α为权重,α={α1,α2,...,αn},其中
[0096][0097][0098]
高斯核函数为就是某种沿径向对称的标量函数。通常定义为空间中任一点x到某一中心xc之间欧氏距离的单调函数,其作用往往是计算相似度;
[0099]
异常评分设置:利用人工标记的数据集,能够根据已知的异常样本计算未知数据的异常评分,针对数值特征的异常评分如式5所示,当关
键字段为空时,异常评分值相对越高。当未知样本与异常样本相似度越高,样本距离越小,异常评分值相对越高。
[0100][0101]
数据集标识化包括,计算最终样本评价得分score
fin
,其中,ω
p
为分配给s
str
的权重,
[0102]
score
fin
=ω
psstr
(1-ω
p
)s
num
ꢀꢀꢀ
(6)。
[0103]
如图4所示,为本技术的数据清洗阶段时的逻辑解释的流程图,所述的数据清洗包括,
[0104]
基于广告效果的标识异常:当最终样本评价得分score
fin
不在预设范围内,则该广告效果标识异常,当该广告效果被标识异常,则将历史数据中所有相同类别的内容标识异常,并通过人工审计的方式决定该类样本是否为可用样本集,当广告效果标识为非异常则进行基于严格策略的标识异常的步骤;
[0105]
基于严格策略的标识异常:计算字符型特征的异常评分s
str
与数值特征异常评分s
num
的差值,当差值在设定阈值内时,输出数据样本,当差值超过设定阈值时,将该类数据样本进行人工审计,判断该类样本是否为可用样本集,当判断为可采集样本时,输出该可采集数据样本集,当判断为不可采集样本时,则丢弃样本。
[0106]
如图5所示,所述的检测方法还包括经过数据清洗后的数据样本集做数据平衡处理,所述的数据平衡包括,
[0107]
基于交叉验证找到一个合适的k值,以保障不会出现过拟合现象。并基于欧式距离如式7所示、计算每一个少数类样本到k个邻近的距离;
[0108][0109]
计算待合成样本量:基于零信任网络理念,我们假设每两个流量中存在一个作弊流量。因此我们将考虑1:1的正负样本数据集。因此对于少数类待合成样本量如式8所示,
[0110]
amount
com
=amount
multi-amount
less
ꢀꢀꢀ
(8),
[0111]
其中,amount
multi
为数据集中正常流量数量,amount
less
为数据集中作弊流量数量;
[0112]
随机线性插值,采用可放回抽样的方式在这k条“直线”上随机选择要添加的合成少数类样本,其中,合成样本的位置由式(8)决定,x为原始样本点位置,为领近点位置,x
new
为合成样本的位置,
[0113][0114]
数据融合:执行拼接操作将合成样本与原始样本进行拼接,以合成一个等比的正负样本数据集。
[0115]
所述的检测方法还包括,基于sk-1earn库直接调用xgboost模型对数据集进行分类,其中超参数有max_depth,eta,objective,其中,max_depth为树深,eta为学习率,objective为目标函数,xgboost为extreme gradient boosting,是基于决策树的一种集成学习模型。通过调节所述超参数来提高模型的分类准确率,目标函数objective如式10、11
所示,
[0116][0117][0118]
本技术还提供一种低速率作弊流量的检测装置,所述的检测装置包括,
[0119]
字符型特征处理模块,用于得到字符型特征的异常评分s
str
;
[0120]
数值型特征处理模块,用于得到数值型特征的异常评分s
num
;
[0121]
数据集标识化模块,用于根据字符型特征的异常评分s
str
及数值型特征的异常评分s
num
,得到最终样本评价得分score
fin
。
[0122]
数据清洗模块和数据平衡模块。
[0123]
所述的字符型特征处理模块包括,
[0124]
编码处理子模块,用于针对字符特征,进行编码处理;
[0125]
判空子模块,用于判断编码处理后的字段是否为空,采用示性函数表达空字段的影响程度,其中s
null
>s
ok
,当字段为空时,i=s
null
,当字段不为空时,i=s
ok
,
[0126][0127]
字段概率统计子模块,用于计算字段概率值为其中n表示字符特征的数量,ci表示某类字符特征;
[0128]
字符型特征异常评分设置子模块,用于计算字符型特征的异常评分s
str
,
[0129]sstr
=i*(1-prc)
ꢀꢀꢀ
(2),
[0130]
所述的数值型特征处理模块包括,
[0131]
空值处理子模块,用于采用示性函数表达空字段的影响程度,其中s
null
>s
ok
,当字段为空时,i=s
null
,当字段不为空时,i=s
ok
,
[0132][0133]
标准化处理子模块,用于使数据服从正态分布;
[0134]
基于高斯核函数的相似度计算子模块,用于通过使用核函数,将处理好的数据映射至高维的特征空间中,式(3)中,使用高斯核函数进行相似度计算,式(4)中,根据不同特征的重要程度,为各特征设置不同的权重α={α1,α2,...,αn},其中
[0135][0136]
[0137]
数值型特征异常评分设置子模块,用于根据已知的异常样本计算未知数据的异常评分,得到数值特征异常评分s
num
,
[0138][0139]
所述的数据集标识化模块计算最终样本评价得分score
fin
,其中,ω
p
为分配给s
str
,的权重,
[0140]
score
fin
=ω
psstr
(1-ω
p
)s
num
ꢀꢀꢀ
(6)。
[0141]
所述的数据清洗模块,用于严格策略的标识异常,计算字符型特征的异常评分s
str
与数值特征异常评分s
num
的差值,当差值在设定阈值内时,输出数据集,当差值超过设定阈值时,将该类数据样本进行人工审计,判断该类样本是否为可用样本集,当判断为可采集样本时,输出数据集,当判断为不可采集样本时,则丢弃样本;
[0142]
所述的数据清洗模块还用于基于广告效果的标识异常子,当最终样本评价得分score
fin
不在预设范围内,则该广告效果标识异常,当该广告效果被标识异常,则将历史数据中所有相同类别的内容标识异常,并通过人工审计的方式决定该类样本是否为可用样本集,当广告效果标识为非异常则进行基于严格策略的标识异常的步骤,
[0143]
所述的数据清洗模块输出的数据样本集作为所述的数据平衡模块的输入,数据平衡模块用于计算少数类样本k个邻近,基于交叉验证找到k值,式(7)中,基于欧式距离,计算每一个少数类样本到k个邻近的距离,
[0144][0145]
数据平衡模块还用于计算待合成样本量:amount
com
=amount
multi-amount
less
(8),其中,amount
multi
为数据集中正常流量数量,amount
less
为数据集中作弊流量数量;
[0146]
数据平衡模块还用于随机线性插值,采用可放回抽样的方式在这k条“直线”上随机选择要添加的合成少数类样本,其中,合成样本的位置由式(8)决定,x为原始样本点位置,为领近点位置,x
new
为合成样本的位置,
[0147][0148]
所述的数据平衡模块还包括数据融合子模块,所述的数据融合子模块用于将合成样本与原始样本进行拼接,以合成一个等比的正负样本数据集。
[0149]
本技术还提供一种计算机设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时,实现上述检测方法。
[0150]
本技术还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述检测方法。
[0151]
以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。