1.本发明总体上涉及计算机处理,并且更具体地,涉及跨人口统计群体估计普查级受众、印象和持续时间的方法、系统和装置。
背景技术:
2.用户可以通过各种平台访问媒体内容。例如,媒体内容可以在电视机上、通过互联网、在移动设备上、在家中或户外、现场或有时移地观看。了解消费者在各种平台内或跨各种平台(例如,电视、在线的、移动的和新兴的)的媒体的参与度允许内容提供商和网站开发人员提高用户对其媒体内容的参与度。
附图说明
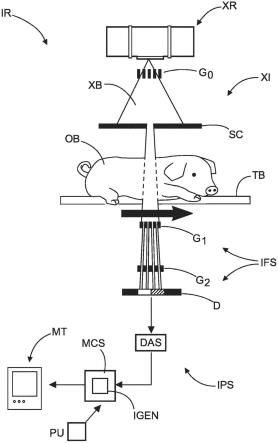
3.图1是示出根据本发明的教导构造的示例操作环境的框图,其中实现受众度量估计器以跨人口统计群体确定普查级受众、印象和持续时间。
4.图2是图1的受众度量估计器的示例实现方式的框图。
5.图3是表示可以被执行以实现图1-图2的示例受众度量估计器的元素的机器可读指令的流程图。
6.图4是表示可以被执行以实现图1-图2的示例受众度量估计器的元素的机器可读指令的流程图,该流程图表示用于生成概率分布的指令。
7.图5是表示可以被执行以实现图1-图2的示例受众度量估计器的元素的机器可读指令的流程图,该流程图表示用于确定概率散度的指令。
8.图6是表示可以被执行以实现图1-图2的示例受众度量估计器的元素的机器可读指令的流程图,该流程图表示用于评估图5的概率散度参数的指令。
9.图7a-图7d包括表示机器可读指令的示例编程代码,该指令可以被执行以实现图1-图2的示例受众度量估计器,以基于第三方订户数据和普查级数据总印象数和总印象持续时间,跨多个人口统计群体估计普查级独特受众规模、普查级印象数和普查级印象持续时间。
10.图8a包括用于定义第三方订户和普查级数据参数的示例变量集,这些参数由图1-图2的示例受众度量估计器使用,以跨多个人口统计群体生成独特受众、印象和持续时间的普查级估计。
11.图8b-图8c包括提供第三方订户和普查级数据的示例数据集,普查级数据包括图1-图2的示例受众度量估计器使用的总印象和总持续时间数据,以跨人口统计信息生成独特受众、印象、和持续时间的普查级估计。
12.图9示出了基于比例无关性和比例不变性的示例变量表征,图1-图2的示例受众度量估计器生成与比例无关的普查级独特受众和印象的估计、以及不随比例变化的普查级持续时间的估计。
13.图10是构造成执行图3-图6的指令以实现图1-图2的示例受众度量估计器的示例处理平台的框图。
14.附图未按比例绘制。通常,在整个附图和随附的书面描述中将使用相同的附图标记来指代相同或相似的部分。连接引用(例如,附接、联接、连接和接合)将被广义地解释,并且可以包括元件集合之间的中间构件和元件之间的相对移动,除非另有说明。因此,连接引用不一定暗示两个元件直接连接并且彼此具有固定关系。
15.当识别可单独提及的多个元件或组件时,本文使用描述符“第一”、“第二”、“第三”等。除非基于其使用上下文另有规定或理解,否则此类描述符不旨在赋予任何优先级、物理顺序、或列表中的排列的含义,或者在时间上排序,而仅仅是用作标记,用于分别指代多个元素或组件,以便于理解所公开的示例。在一些示例中,描述符“第一”可用于指代具体实施方式中的元件,而同一元件可在权利要求中用不同的描述符(例如“第二”或“第三”)来指代。在这种情况下,应当理解,使用这种描述符仅仅是为了便于引用多个元件或组件。
具体实施方式
16.受众测量实体(ame)执行测量以确定参与看电视、收听无线电台或浏览网站的人(例如,受众)的数量。鉴于制作内容和/或广告的公司和/或个人希望了解其内容的覆盖范围和有效性,识别此类信息是有用的。为了实现这一点,诸如尼尔森(美国)有限公司的公司利用设备上计量器(on-device meter,odm)来监控自愿成为小组一部分的个人(例如小组成员)的手机、平板电脑(例如,ipads
tm
)和/或其他计算设备(例如,pda、笔记本电脑等)的使用情况。小组成员是在注册到小组时已经提供人口统计信息的用户,允许他们的人口统计信息链接到他们选择收听或观看的媒体。因此,小组成员(例如,受众)代表了媒体消费者的大群体(例如,普查)的统计上相当数量的样本,从而允许广播公司和广告商能够更好地了解谁在使用他们的媒体内容并最大化收入潜力。
17.设备上计量器(odm)可以通过收集与被监控设备的使用有关的感兴趣数据的软件来实现。odm可以收集指示小组成员所暴露于的媒体访问活动的数据(例如,网站名称、访问日期/时间、页面浏览量、访问持续时间、点击流数据、和/或其他媒体识别信息(例如,网页内容、广告等))。该数据定期或不定期地上传到数据收集设施(例如,受众测量实体服务器)。鉴于小组成员在向ame注册时提交了他们的人口统计数据,odm数据的优势在于它将该人口统计信息与odm收集的活动数据联系起来。此类监控活动通过使用监控指令标记要跟踪的互联网媒体来执行,例如基于在blumenau的美国专利no.6,108,637的中公开的示例来执行,该专利通过引用整体并入本文。监控指令形成媒体印象请求,其提示监控数据从odm客户端发送到监控实体(例如,ame,如尼尔森有限公司),以汇集准确的使用统计数据。每当用户(例如,从服务器、从高速缓存)访问媒体时,都会执行印象请求。当媒体用户也是ame小组的一部分(例如,小组成员)时,ame能够将小组成员的人口统计数据(例如,年龄、职业等)与小组成员的媒体使用数据(例如,基于用户的印象数、基于用户的印象持续时间)匹配。如本文所使用的,印象被定义为家庭或个体访问和/或暴露于媒体(例如,广告、页面视图或视频视图形式的内容、广告组和/或内容集合等)的事件。
18.在互联网(例如,facebook、google、youtube等)上运行的数据库所有者向注册订户提供服务(例如,社交网络、流媒体等)。通过设置cookie和/或其他设备/用户标识符,数
据库所有者可以在订户使用指定服务时识别他们的订户。mainak等人的美国专利no.8,370,489(其整体并入本文)中公开的示例,允许ame与数据库所有者合作,以通过在接收到来自用户的初始印象请求(例如,由于观看广告)后向数据库所有者发送印象请求来收集更广泛的互联网使用数据。由于用户可能是非小组成员(例如,不是具有可用相关联人口统计数据的ame小组的成员),假设如果给定用户是订户,与订户相对应的数据库所有者记载/记录对于用户的数据库所有者人口统计印象,则ame可以从该数据库所有者获取数据。然而,为了保护其订户的隐私,数据库所有者通过聚合数据来概括订户级的受众度量。因此,ame可以访问第三方聚合的基于订户的受众度量,其中按人口统计类别报告印象数和独特受众规模(例如,15-20岁的女性、15-20岁的男性、21-26岁的女性、21-26岁的男性等)。
19.如本文所使用的,独特受众规模基于可彼此区分的受众成员,使得多次暴露于相同媒体的单个受众成员/订户被识别为单个的独特受众成员。如本文所使用的,媒体的全域受众(例如,总受众)是在特定的感兴趣地理范围内和/或在与媒体受众度量相关的感兴趣时间期间访问媒体的总人数。确定某些媒体(例如,广告)是否接触到更大的独特受众可用于识别ame客户端(例如,广告商)是否接触到更大的受众群。当ame记录与任何人口统计信息无关的用户访问媒体的印象时,记录的印象计为普查级印象。因此,可以为同一用户记录多个普查级印象,因为该用户未被识别为独特受众成员。对个体人口统计群体的普查级独特受众、印象数(例如,已经浏览网页的次数)和印象持续时间的估计可以提高监控实体(如ame)提供的使用统计数据的准确性。
20.在一些示例中,对于普查级信息,ame可以访问总印象数(例如,浏览网页的总次数)和总印象持续时间(例如,浏览网页的时长),而不是总独特受众(例如,可区分用户的总数)。ame可以接收附加的第三方数据,这些数据仅限于订阅第三方(例如数据库所有者)提供的服务的用户。例如,普查级数据包括其人口统计信息可能不可用的个体的总印象数和总印象持续时间,而第三方级数据包括与特定人口统计群体(例如,人口统计级数据)相关的受众规模、印象数和印象持续时间的订户级数据。因此,第三方数据可以基于提供第三方数据的数据库所有者执行的订户数据与不同人口统计类别的匹配,向ame提供部分受众、印象数和印象持续时间信息,直至总体人口统计级别。但是,出于订户隐私的考虑,第三方数据不会提供与特定订户相关的受众、印象数和印象持续时间。本文公开的示例方法、系统和装置允许基于提供针对群体全域的子集的跨不同人口统计类别的受众规模、印象数和印象持续时间的第三方订户数据,来估计跨不同人口统计类别的普查级受众规模、印象数和印象持续时间。
21.本文公开的示例使用独立于可用人口统计群体的实际数量来求解的两个变量(例如,普查级和每个个体的基于订户的数据库中的印象数和印象持续时间)。本文公开的示例利用提供关于印象数、印象持续时间和独特受众规模的部分信息的第三方订户级受众度量,来在估计媒体的总独特受众规模时克服普查级印象的匿名性。本文公开的示例应用信息论来获得将普查级信息解析为基于人口统计群体的数据的解决方案。在本文公开的示例中,普查级受众度量估计器通过以下来跨人口统计群体确定普查级独特受众、印象数和印象持续时间:针对每个受众规模、印象数和印象持续时间,确定给定人口统计群体中的个体是第三方订户数据的成员的概率;确定第三方订户数据和普查级数据之间的概率散度;以及在基于等式约束的界限内建立搜索空间,所述等式约束由每个人口统计群体的普查级印
象数的总和等于总参考普查级印象数,并且每个人口统计群体的普查级印象持续时间的总和等于总参考普查级印象持续时间来定义。本文公开的示例允许在逻辑上与所有约束、比例独立性和不变性一致的估计。
22.虽然结合网站媒体曝光监控描述了本文公开的示例,但是所公开的技术也可以结合不限于网站的其他类型的媒体曝光的监控来使用。本文公开的示例可用于监控任何一种或多种媒体类型(例如,视频、音频、网页、图像、文本等)的媒体印象。此外,本文公开的示例可用于除受众监控之外的应用(例如,确定群体规模、参加者的数量、观察的数量等)。虽然所公开的示例包括与印象数和/或受众有关的数据集,但这些数据集还可以包括从其他来源(例如,货币交易、医疗数据等)获得的数据。
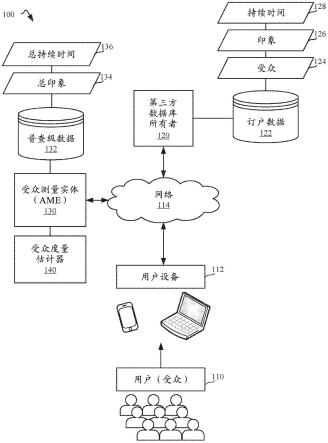
23.图1是示出示例操作环境100的框图,在该示例操作环境100中,实现受众度量估计器以跨人口统计群体确定普查级受众、印象和印象持续时间。图1的示例操作环境100包括示例用户110(例如,受众)、示例用户设备112、示例网络114、示例第三方数据库所有者120和示例受众测量实体(ame)130。第三方数据库所有者120包括示例订户数据库122。订户数据库122包括示例订户受众规模数据124、示例印象数据126和示例印象持续时间数据128。ame 130包括示例普查级数据132和示例受众度量估计器140。普查级数据132包括示例总印象数134(例如,总印象)和示例总印象持续时间136(例如,总持续时间)。
24.用户110包括在一个或多个用户设备112上访问媒体的任何个人,使得访问和/或暴露于媒体的发生产生媒体印象(例如,观看广告、电影、网页横幅、网页等)。示例用户110可以包括在向示例ame 130注册时已经提供了他们的人口统计信息的小组成员。当作为小组成员的示例用户110利用示例用户设备112通过示例网络114访问媒体内容时,ame 130(例如,ame服务器)存储与其人口统计信息相关联的小组成员活动数据。用户110还包括不是小组成员的个体(例如,没有向ame 130注册)。用户110包括作为数据库所有者120提供的服务的订户并且通过他们的(一个或多个)用户设备112使用这些服务的个体。
25.用户设备112可以是固定或便携式计算机、手持计算设备、智能电话、互联网设备和/或可以连接到网络(例如,互联网)并能够呈现媒体的任何其他类型的设备。在图1所示的示例中,(一个或多个)客户端设备102包括智能手机(例如,motorola
tm moto x
tm
、nexus 5、android
tm
平台设备等)和膝上型计算机。然而,可以附加地或替选地使用任何其他(一种或多种)类型的(一个或多个)设备,例如平板电脑(例如,ipad
tm
、motorola
tm xoom
tm
等)、台式计算机、照相机、互联网兼容电视、智能电视等。图1的(一个或多个)用户设备112用于访问(例如,请求、接收、表现和/或呈现)例如由web服务器提供的在线媒体。例如,用户110可以在(一个或多个)用户设备112上运行web浏览器以从媒体托管服务器请求流媒体(例如,通过http请求)。web服务器可以是任何web浏览器,用于提供由示例用户110在(一个或多个)示例用户设备112上通过示例网络114访问的媒体内容(例如youtube)。网络114可以使用任何合适的(一个或多个)有线和/或无线网络来实现,包括例如一个或多个数据总线、一个或多个局域网(lan)、一个或多个无线lan、一个或多个蜂窝网络、互联网等。短语“通信”(包括其变型)包含直接通信和/或通过一个或多个中间组件的间接通信,并且不需要直接物理(例如,有线)通信和/或持续通信,而是另外包括以周期性或非周期性间隔、以及一次性事件进行的选择性通信。
26.在一些示例中,媒体(也称为媒体项目)被标记或编码以包括监控或标记指令。监控指令是由访问媒体内容(例如,通过网络114)的web浏览器执行的计算机可执行指令(例如,java或任何其他计算机语言或脚本)。监控指令的执行导致web浏览器向ame 130的服务器和/或数据库所有者120发送印象请求。当访问媒体的用户设备112被识别为属于数据库所有者120的服务的注册订户时,由数据库所有者120记录人口统计印象。数据库所有者120在订户数据存储器122中存储为注册订户生成的数据。同样,ame 130记录用户设备112的普查级媒体印象(例如,普查级印象),而不管人口统计信息是否可用于此类记录的印象。ame 130将普查级数据信息存储在普查级数据存储器132中。在标题为“methods and apparatus to determine impressions using distributed demographic information”的美国专利no.8,370,489、标题为“methods and apparatus to collect distributed user information for media impressions and search terms”的美国专利no.8,930,701、以及标题为“methods and apparatus to collect distributed user information for media impressions and search terms”的美国专利no.9,237,138中公开了收集印象数据的监控指令和方法的其他示例,所有这些专利通过引用整体并入本文。
27.ame 130作为独立方操作以测量和/或验证与数据库所有者120的订户访问的媒体有关的受众测量信息。当用户112访问媒体时,ame 130将普查级信息存储在普查级数据存储器132中,普查级信息包括总印象数134(例如,网页浏览次数)和总印象持续时间136(例如,查看网页的时长)。第三方数据库所有者120向ame 130提供混淆个人特定数据的聚合订户数据,使得人口统计群体内的个体之间的参考聚合(例如,第三方聚合的基于订户的受众度量)可用。例如,订户受众数据124、印象数数据126和印象持续时间数据128按人口统计级别(例如,15-20岁的女性、15-20岁的男性、21-26岁的女性、21-26岁的男性等)提供。例如,订户受众数据124对应于每个人口统计类别的聚合中的独特受众规模数据。
28.ame 130的受众度量估计器140接收第三方聚合的基于订户的受众度量数据(例如,受众规模数据124、印象数数据126和印象持续时间数据128)。受众度量估计器140使用聚合数据来估计普查级受众规模数据、普查级印象数数据和普查级印象持续时间数据。此外,受众度量估计器140使用可用于ame 130的普查级数据(例如,总印象数134和总印象持续时间136)来为基于订户的数据进行普查级受众、印象和持续时间估计,如下面结合图2进一步描述的。
29.图2是图1的受众度量估计器140的示例实现方式的框图。示例受众度量估计器140包括示例数据存储器210、示例概率分布生成器220和示例概率散度确定器230,所有这些都使用示例总线240连接。
30.数据存储器210存储从第三方数据库所有者120检索的第三方聚合的基于订户的受众度量数据。例如,从第三方数据库所有者120检索并存储在数据存储器210中的数据可以包括订户数据122(例如,第三方受众规模124、第三方印象数126和第三方印象持续时间128)。数据存储器210还可以存储普查级数据132(例如,总印象134和总印象持续时间136)。受众度量估计器140可以从数据存储器210检索第三方数据和普查级数据以执行普查级估计计算(例如,确定给定人口统计群体的普查级独特受众规模、普查级印象数、和普查级印象持续时间)。数据存储器210可以由任何用于存储数据的存储设备和/或存储盘实现,例如闪存、磁介质、光介质等。此外,存储在数据存储器210中的数据可以是任何数据格式,例如
二进制数据、逗号分隔的数据、制表符分隔的数据、结构化查询语言(sql)结构等。虽然在所示示例中,数据存储器210被示出为单个数据库,但数据存储器210可以由任意数量和/或(一种或多种)类型的数据库实现。
31.概率分布生成器220为给定群体中的任何个体生成概率分布的单个估计,使得该分布受制于个体在受众中、具有平均印象数(例如,页面浏览量)、并具有平均印象持续时间的概率。
32.分布参数求解器222求解与给定群体的每个个体的概率分布相关联的参数。分布参数求解器222可以使用迭代器224和收敛器226,基于参数是可以直接求解还是需要使用迭代器来收敛到最终解,来确定最终概率分布参数。例如,概率分布生成器220将概率密度函数、边际概率和/或个人特定概率分布分配给基于第三方订户的受众个体。在一些示例中,使用第三方订户印象126和印象持续时间128的数据,使用具有与印象持续时间(t)无关的印象数量(n)的边际概率,将概率密度函数分配给订户受众个体。在一些示例中,概率分布生成器220基于个体在受众中、具有平均印象数、并具有平均印象持续时间的概率,为人口统计群体(k)内的个体分配个人特定概率分布,如所述结合图4更详细地描述的。例如,分布参数求解器222使用迭代器224执行定点迭代以求解否则不能直接求解的变量。在一些示例中,分布参数求解器222使用收敛器226来收敛到个体概率分布估计的解,如结合图4更详细描述的。在一些示例中,迭代器224可以使用初始起始值的一阶近似作为估计概率分布估计的解的一部分。
33.概率散度确定器230使用示例搜索空间识别器232、示例散度参数求解器234、示例迭代器236和示例普查级输出计算器238来跨人口统计群体确定普查级受众、页面浏览量和持续时间。
34.概率散度确定器230可用于使用图1的可用第三方订户数据122和普查级数据132来确定给定人口统计群体中的先验分布和后验分布之间的概率散度。例如,概率散度确定器230可以将第三方数据定义为第k个人口统计群体中的先验概率分布,并将普查级数据定义为第k个人口统计群体中的后验概率分布,如下面结合图5更详细描述的。在一些示例中,可以使用两个分布之间的kullback-leibler(kl)散度来确定概率散度。
35.为了基于概率散度产生针对不同人口统计类别的普查级受众、印象数和印象持续时间的解,概率散度确定器230使用搜索空间识别器232来基于普查级印象和持续时间等式约束来建立一组给定界限内的搜索空间。例如,一旦建立了等式约束,则散度参数求解器234可以基于等式约束来评估散度参数。在一些示例中,散度参数求解器234使用迭代器236来在由搜索空间识别器232确定的搜索空间上迭代,直到满足等式约束(例如,由以下定义的等式约束:每个人口统计群体的普查级印象数的总和等于总参考普查级印象数,并且每个人口统计群体的普查级印象持续时间的总和等于总参考普查级印象持续时间)。普查级输出计算器238基于满足上述等式约束的解来估计普查级个体数据(例如,受众、印象和持续时间),如结合图6更详细描述的。
36.虽然在图1和2中示出了实现受众度量估计器140的示例方式,但图1和图2中所示的一个或多个元件、过程和/或设备可以以任何其他方式组合、划分、重新布置、省略、消除和/或实现。此外,图1-图2的示例性数据存储器210、概率分布生成器202、概率散度确定器230、和/或更一般地,示例性受众度量估计器140可以通过硬件、软件、固件和/或硬件、软件
和/或固件的任何组合来实现。因此,例如,图1-图2的示例数据存储器210、示例概率分布生成器220、示例概率散度确定器230、和/或更一般地,示例受众度量估计器140中的任一者可由一个或多个模拟或数字电路、逻辑电路、(一个或多个)可编程处理器、(一个或多个)可编程控制器、(一个或多个)图形处理单元(gpu)、(一个或多个)数字信号处理器(dsp)、(一个或多个)专用集成电路(asic)、(一个或多个)可编程逻辑器件(pld)和/或(一个或多个)现场可编程逻辑器件(fpld)来实现。当阅读本专利的任何装置或系统权利要求以涵盖纯软件和/或固件实现时,示例数据存储器210、示例概率分布生成器220和/或示例概率散度确定器230中的至少一者,在此明确定义为包括非暂时性计算机可读存储设备或存储盘,例如包括软件和/或固件的存储器、数字多功能盘(dvd)、光盘(cd)、蓝光光盘等。此外,示例受众度量估计器140可以包括一个或多个元件、过程和/或设备(除了或代替图1和图2所示的元件、过程和/或设备),和/或可以包括所示元件、过程和设备的任一者或所有的多于一个。如本文所使用的,短语“通信”(包括其变型)包含直接通信、和/或通过一个或多个中间组件的间接通信,并且不需要直接物理(例如,有线)通信和/或持续通信,而是另外包括以周期性间隔、预先安排的间隔、非周期性间隔和/或一次性事件进行的选择性通信。
37.图3-图6中分别示出了表示用于实现图1-图2的示例受众度量估计器140的示例机器可读指令的流程图。机器可读指令可以是一个或多个可执行程序或可执行程序的(一个或多个)部分,该一个或多个可执行程序或可执行程序的(一个或多个)部分用于由处理器(例如下面结合图3-图6讨论的示例处理器平台900中所示的处理器906)执行。程序可以实施在存储在非暂时性计算机可读存储介质(例如cd-rom、软盘、硬盘驱动器、数字多功能盘(dvd)、蓝光光盘、或与处理器906相关联的存储器)上的软件中,但是整个程序和/或其部分可替选地由处理器906以外的设备执行和/或以固件或专用硬件实施。此外,尽管参考图3-图6所示的流程图来描述示例程序,但可替选地,可以使用实现示例受众度量估计器140的许多其他方法。例如,可以改变框的执行顺序,和/或可以改变、消除或组合所描述的一些框。附加地或替选地,任何或所有框可由构造成在不运行软件或固件的情况下执行相应操作的一个或多个硬件电路(例如,离散电路、和/或集成模拟和/或数字电路、fpga、asic、比较器、运算放大器(op-amp)、逻辑电路等)来实现。
38.本文所述的机器可读指令可以压缩格式、加密格式、分散格式、打包格式等中的一种或多种存储。如本文所述的机器可读指令可存储为可用于创建、制造和/或产生机器可执行指令的数据(例如,指令的一部分、代码、代码的表示等)。例如,机器可读指令可以被分散并存储在一个或多个存储设备和/或计算设备(例如,服务器)上。机器可读指令可能需要安装、修改、适应、更新、组合、补充、配置、解密、解压缩、解包、分发、重新分配等中的一者或多者,以使其由计算设备和/或其他机器直接可读和/或可执行。例如,机器可读指令可以存储在多个部分中,这些部分被单独压缩、加密并存储在单独的计算设备上,其中这些部分在被解密、解压缩、以及组合时形成一组可执行指令,该组可执行指令指令实现如本文所述的程序。
39.在另一示例中,机器可读指令可以计算机可读取的状态存储,但需要添加库(例如,动态链接库(dll))、软件开发工具包(sdk)、应用程序编程接口(api)等,以在特定计算设备或其他设备上执行指令。在另一示例中,在机器可读指令和/或(一个或多个)相应程序可以全部或部分执行之前,可能需要配置机器可读指令(例如,存储的设置、数据输入、记录
的网络地址等)。因此,所公开的机器可读指令和/或(一个或多个)相应程序旨在涵盖这种机器可读指令和/或(一个或多个)程序,而不管机器可读指令和/或(一个或多个)程序在存储时或相反在静止或传输中的特定格式或状态如何。
40.本文描述的机器可读指令可以由任何过去、现在或未来的指令语言、脚本语言、编程语言等来表示。例如,机器可读指令可以使用以下语言中的任何一种来表示:c、c 、java、c#、perl、python、javascript、超文本标记语言(html)、结构化查询语言(sql)、swift等。
41.如上所述,图3、图4、图5和/或图6的示例性过程可以使用存储在非暂时性计算机和/或机器可读介质上的可执行指令(例如,计算机和/或机器可读指令)来实现,非暂时性计算机和/或机器可读介质例如硬盘驱动器、闪存、只读存储器(rom)、光盘(cd)、数字多功能盘(dvd)、高速缓存、随机存取存储器(ram)、和/或其中信息可存储任意持续时间(例如,长时间、永久、短暂、临时缓冲和/或高速缓存信息)的任何其他存储设备或存储磁盘。如本文所使用的,术语非暂时性计算机可读介质被明确定义为包括任何类型的计算机可读存储设备和/或存储盘,并排除传播信号和排除传输介质。
[0042]“包括”和“包含”(及其所有形式和时态)在本文用作开放式术语。因此,每当权利要求采用任何形式的“包括”或“包含”(例如,包括(comprises、includes、comprising、including)、具有等)作为前序,或在任何种类的权利要求陈述中,应当理解,可以存在附加的元素、术语等,而不会超出相应权利要求或陈述的范围。如本文所使用的,当短语“至少”在例如权利要求的前序中用作过渡术语时,其以与术语“包括”和“包含”相同的方式是开放式的。例如,当以诸如a、b和/或c的形式使用术语“和/或”时,指a、b、c的任何组合或子集,例如(1)仅a、(2)仅b、(3)仅c、(4)a与b、(5)a与c、(6)b与c、以及(7)a与b与c。如本文在描述结构、组件、项目、对象和/或事物的上下文中所使用的,短语“a和b中的至少一者”意指包括(1)至少一个a、(2)至少一个b、和(3)至少一个a和至少一个b中的任何一者的实现方式。类似地,如本文在描述结构、组件、项目、对象和/或事物的上下文中所使用的,短语“a或b中的至少一者”意指包括(1)至少一个a、(2)至少一个b、和(3)至少一个a和至少一个b中的任何一者的实现方式。如本文在描述过程、指令、动作、活动和/或步骤的执行或运行的上下文中所使用的,短语“a和b中的至少一者”意指包括(1)至少一个a、(2)至少一个b、和(3)至少一个a和至少一个b中的任何一者的实现方式。类似地,如本文在描述过程、指令、动作、活动和/或步骤的执行或运行的上下文中所使用的,短语“a或b中的至少一者”意指包括(1)至少一个a、(2)至少一个b、和(3)至少一个a和至少一个b中的任何一者的实现方式。
[0043]
如本文所使用的,单数引用(例如,“一”、“一个”、“第一”、“第二”等)不排除复数。如本文所使用的,术语“一”或“一个”实体是指该实体中的一个或多个。术语“一”(或“一个”)、“一个或多个”和“至少一个”在本文中可以互换使用。此外,尽管单独列出,但多个装置、元件或方法动作可以通过例如单个单元或处理器来实现。此外,尽管单独的特征可以包括在不同的示例或权利要求中,但是这些特征可以可能地被组合,并且不同的示例或权利要求中的包括并不意味着特征的组合是不可行的和/或不有利的。
[0044]
图3是表示可以被执行以实现图2的示例性受众度量估计器140的元素的机器可读指令的流程图300。示例受众度量估计器140针对每个人口统计群体(k)从数据存储器202检索第三方订户数据(例如,可从图1的数据库所有者120获得)(框302)。第三方数据库所有者
120基于当订户暴露于用户设备112上的印象(例如,第三方媒体)时收集的订户数据122来确定订户的不同人口统计类别的受众规模、印象数和印象持续时间数据。例如,记录的印象126与特定订户(例如,用户110)和记录的印象的特定持续时间128相关联。基于该数据,受众度量估计器140可以针对不同的聚合人口统计类别,检索基于订户的受众规模{ak}数据(例如,受众规模数据124)、印象数{rk}数据(例如,印象数数据126)和印象持续时间{dk}数据(例如,印象持续时间数据128)的输入。示例受众度量估计器140还从ame 130的普查级数据存储器132检索普查级数据(框304)。例如,ame 130还可以访问用户110在使用设备112时产生的记录印象,但是当这些用户不是ame小组的成员时,该数据不与用户的特定人口统计群体相关联,使得ame 130可以确定总记录印象134(例如,用户110的普查级印象的总数)和对应的总普查级印象持续时间136,而不区分各个用户。因此,普查级数据存储器132向受众度量估计器140提供输入:总普查级印象(t)数据(例如,总印象数据134)和总普查级持续时间(v)数据(例如,总持续时间数据136)。使用第三方和普查级数据,示例受众度量估计器140的示例概率分布生成器220确定给定人口统计群体k中的个体是第三方订户数据(例如,受众规模{ak}数据、印象数{rk}数据和印象持续时间{dk}数据)的成员的概率,并为受制于这些约束的总群体中的每个个体生成概率分布,使得分布参数求解器222确定分布参数,该分布参数可进一步用于确定普查级受众、印象和持续时间数据的潜在解(框306)。一旦已经生成了概率分布,图2的示例概率散度确定器230就可以确定第三方和普查级数据之间的概率散度(框308)。此外,示例概率散度确定器230基于使用分布参数求解器222计算的概率分布参数和使用散度参数求解器234计算的概率散度参数,使用普查级输出计算器238估计普查级个体数据(例如,独特受众规模、印象和持续时间)(框310)。示例受众度量估计器140提供普查级输出,包括普查级受众规模{xk}(框312)、普查级印象数{tk}(框314)和普查级印象持续时间{vk}(框316)的输出估计。因此,使用普查级数据(例如,总印象数134和总持续时间136)和第三方数据(例如,受众规模124、印象数125和持续时间128),受众度量估计器140估计各个人口统计类别的普查级独特受众312、印象314和持续时间316。
[0045]
图4是表示机器可读指令的流程图306,该机器可读指令可以被执行以实现图2的示例受众度量估计器140的元素以生成概率分布。例如,概率分布生成器220使用印象数(n)和印象持续时间(t)为小组受众个体(i)分配概率密度函数[p
n,t(i)
](框402)。每个人在普查级和第三方数据库中都有固定但未知的印象数(n)和印象持续时间(t)(例如,“john smith”浏览网页5次,总计20分钟,其中只有3次浏览和10分钟在数据库中注册,或者根本没有在数据库中注册)。然而,聚合信息使个人特定数据模糊,并在人口统计群体中的个体之间留下了一个参考聚合,因此每个人的不确定性可以以概率分布的形式表示。这种分布是点质量分布和双变量分布(在一个维度上是连续的,在另一个维度上是离散的)的混合。点质量分布在n=0时表示个体没有浏览任何页面,因此没有持续时间。双变量分布部分(p
n,t
)在n={1,....,∞}上是离散的,而在开区间t∈(0,∞)上是连续的。例如,平行的连续曲线片(每条曲线在每个n值处间隔开)提供这些分布的可视化表示。
[0046]
为了使用示例概率分布生成器220得出个体概率分布估计的解,假设在总群体中有总共u个个体。可以分别使用域n={1,....,∞}和t∈(0,∞),针对每个人,跨每个个体有任何印象数(n)和任何印象持续时间(t)、以及没有任何印象的可能性,表达u概率分布集合的不确定性,使得,例如,如果u=5,则为个人1-5分配如下概率:
和概率分布生成器220分配p
0(i)
作为第i个个人没有任何印象数的概率(例如点质量分布),并且分配作为概率密度函数,该概率密度函数表示第i个个人在持续时间t内有n次印象的概率,其中持续时间t对应于n次印象的总持续时间。在一些示例中,对于网页浏览的印象的给定数量n,连续部分可以是每次网页浏览的平均视频的持续时间的分布,从而表示每个印象数的平均印象持续时间。由于唯一可用的普查级聚合信息是总印象数(例如,总印象数134)和总印象持续时间(例如,总持续时间136),因此每次网页浏览的平均持续时间被认为是恒定的。例如,注册1次网页浏览的用户比观看100次网页浏览的用户更有可能观看更长的视频。虽然与仅浏览1次网页的用户相比,具有100次网页浏览记录的用户的视频浏览量可能会更短,但假定他们的总持续时间是相等的(例如,1次浏览
×
10分钟/平均每次浏览=5次浏览
×
2分钟/平均每次浏览=10分钟持续时间)。基于该信息,概率分布生成器220分配与印象持续时间t无关的具有n次印象的边际概率。用户具有n次印象数(例如,n次网页浏览)的边际概率(与这些印象的持续时间无关),可以根据下面的等
[0047]
式1表示:
[0048][0049]
每个个体的总概率可以根据下面的等式2进一步表示,使得与个体相关联的所有概率的组合被限制为总数1:
[0050][0051]
在没有关于个体行为的可用信息的示例中,给定人口统计群体中的每个个体都被分配相同的概率分布。例如,如果100个人总共有300次印象数(例如,页面浏览),总持续时间为600分钟,则平均每个人总共有3次印象数,总持续时间为6分钟,其中每次印象的平均持续时间为2分钟。
[0052]
鉴于受众度量估计器140可以访问第三方订户信息(例如,受众数据124、印象数数据126和持续时间数据128),可以根据下面的等式3-7生成个人特定分布(例如,通过在人口统计群体内的个体之间划分数据):
[0053][0054]
受制于
[0055][0056][0057][0058]
概率分布生成器220分配等式3的个人特定分布(h),其提供群体内任何个体的分布的估计,受制于等式4-7的约束。等式4表示给定个体的估计概率分布总计为1的约束(结
合上述等式1-2进行了解释)。等式5是控制个体在受众中(例如,具有至少一次印象)的概率(d1)的约束。等式6是控制个体的平均印象数(d2)的约束。等式7是控制个体的平均印象持续时间(d3)的约束。概率分布生成器220由此基于所呈现的等式4-7的约束为人口统计群体中的个体分配和初始化个人特定概率分布(h)的值(框404)。概率分布生成器220可以根据等式9-12重新安排等式3-7的个人特定分布问题的解(例如,用z表示法表示),但受制于根据等式8表示的集合的最终解{zj}(框406):
[0059][0060][0061][0062][0063][0064]
分布参数求解器222求解变量z0、z1、z2和z3。在一些示例中,分布参数求解器222可以直接求解z0和z3,而z1的解是直接基于z2的解获得的,z2的解可以使用例如迭代器224的定点迭代来求解(框408)。例如,z0和z3的直接解分别由下面的等式13和14表示。z2的解可以用等式15表示,因此z1的解基于z2的解,如等式16所示:
[0065]
z0=1-d1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
等式13
[0066][0067][0068][0069]
在本文呈现的示例中,迭代器224应用定点迭代来生成z2的解,从而可以识别0≤z2≤1内的唯一解,前提是d2≥d1(例如,印象数(d2)等于或超过受众的个体数量(d1))。例如,可以假设至少一个受众成员具有至少一个印象数。迭代器224使用例如定点迭代生成与等式17一致的z2的表达式。初始起始值的一阶近似在等式18中示出。迭代器224继续基于初始起始值(例如,等式18)迭代,并且收敛器2226用于收敛到个体概率分布估计(h)的最终解:
[0070][0071][0072]
在一些示例中,可以使用允许收敛的任何方法(例如,收敛算法)来实现到最终解的收敛,并且不限于使用上述定点迭代作为求解个体概率分布估计(h)的示例方法。
[0073]
一旦个体概率分布估计的解可用,则可以为每个个体(例如,受众成员)计算任何概率的估计。例如,如果在100个个体中,有50人的受众和200个印象数(例如,页面浏览量),持续时间为400个时间单位,z0、z1、z2和z3可以如下面的示例1所示基于公式13-18求解:
[0074][0075][0076][0077][0078]
在该示例中,可以为每个个体计算任何概率的估计值,使得如果p0=z0=0.5,则该个体有50%的机会没有印象数且没有持续时间。为了估计该示例中的受众具有3个印象数(例如,n=3)的概率,受众度量估计器140可以应用等式1来生成估计,如下面的示例2中所示:
[0079][0080]
受众度量估计器140还可以确定给定n个印象数的总印象持续时间,如示例3所示,其中分母表示是受众的概率,分子表示n次印象的平均持续时间:
[0081][0082]
示例3的表达式与印象数n无关。例如,将分子乘以n并重点关注具有n个印象数的个体,以得出给定n个印象数的总持续时间。然而,该解和与个体相关联的印象数的未知数量(例如,根据示例1中呈现的信息,50个个体中有400个持续时间单位,平均产生8个时间单位)无关。
[0083]
图5是表示机器可读指令的流程图308,该机器可读指令可以被执行以实现图2的示例受众度量估计器140的元素,该流程图表示用于确定概率散度的指令。一旦如上面结合图4所描述的,受众度量估计器140使用概率分布生成器220生成概率分布,则概率散度确定器230确定概率散度。概率散度允许在两个概率分布之间进行比较。在本文公开的示例中,
概率散度允许在第三方订户数据的分布和普查级数据的分布之间进行比较。在本文公开的示例中,使用kullback-leibler概率散度(kl散度)来测量这两个概率分布之间的差异(例如,确定一个概率分布与另一个概率分布的近似程度)。例如,概率散度确定器230将第三方订户数据定义为先验分布(q),将普查级数据定义为后验分布(p)。受众规模和印象持续时间在第k个人口统计群体(uk)中的整个个体群体中均匀划分,因此u表示群体全域估计。全域估计(例如,总受众)可以定义为,例如,在与媒体受众度量相关的特定感兴趣地理界限内和/或在感兴趣的时间期间访问媒体的总人数。例如,全域估计可以基于在评估用户设备112记录的印象期间由ame 130获得的普查级数据132。例如,第k个人口统计群体可以表示人口统计类别(例如,35-40岁的女性、35-40岁的男性等)。因此,概率散度确定器230以与如下等式19-22一致的方式,将第三方数据定义为第k个人口统计群体中的先验概率分布(qk)(框502),并且将普查级数据定义为第k个人口统计群体中的后验概率分布(pk)(框504):
[0084][0085][0086][0087][0088]
在等式19-22中,第k个人口统计群体中的特定个体是第三方聚合的订户受众总数(ak)的成员的概率被定义为ak/uk,第k个人口统计群体中的特定个体具有在第三方聚合的订户印象数总数(rk)中的印象数的概率被定义为rk/uk,第k个人口统计群体中的特定个体具有在第三方聚合的印象持续时间总和(dk)中的印象持续时间的概率被定义为dk/uk。在本文公开的示例中,受众度量估计器140访问第三方数据(例如,图1的订户数据122),其提供订户受众(ak)、印象数(rk)和印象持续时间(dk)(例如,分别是图1的受众124数据、印象126数据和持续时间128数据)的匿名化聚合数据。然而,对于普查级数据,受众度量估计器140只能访问普查级总印象数134和总印象持续时间136。在等式19-22中,第k个人口统计群体中的特定个体是普查级独特受众总数(xk)的成员的概率被定义为xk/uk,第k个人口统计群体中的特定个体具有在普查级印象数总数(tk)中的印象数的概率被定义为tk/uk,第k个人口统计群体中的特定个体具有在普查级印象持续时间总和(vk)中的印象持续时间的概率被定义为vk/uk。一旦概率散度确定器230分别定义了第三方订户数据和普查级数据的先验分布和后验分布(框502和504),则散度参数求解器234确定第k个人口统计群体中的先验分布和后验分布之间的散度,以便为普查级独特受众、印象数和印象持续时间找到解(框506),如下面结合图6详细描述的。
[0089]
图6是表示机器可读指令的流程图506,该机器可读指令可以被执行以实现图2的示例受众度量估计器140的元素,该流程图表示用于确定图5的概率散度的指令。除了具有不同的值外,先验分布(qk)和后验分布(pk)在同一个域中,并且具有相同的线性约束。因此,散度参数求解器234根据如下等式23定义个体的从第三方订户数据到普查级数据的散度(例如,kullback-leibler散度kl(pk:qk),其中pk是定义普查级数据的后验概率分布,qk是
定义第三方订户数据的先验概率分布):
[0090][0091]
在等式23中,散度参数求解器234用z表示法表示kl散度,参考如前所述在等式13-16中确定的z0、z1、z2和z3的解,并在下面再现为等式24-27:
[0092]
z0=1-d1ꢀꢀꢀꢀ
等式24
[0093][0094][0095][0096]
在一些示例中,散度参数求解器234扩展等式23以根据等式28产生关于任何特定个体在第k个人口统计群体中的分布如何变化的描述:
[0097][0098][0099]
鉴于假定第k个人口统计群体中的所有个体都具有相同的行为,散度参数求解器234将kl(pk:qk)乘以第k个人口统计群体(uk)中的个体数量以确定人口统计群体中的个体可以如何共同改变(例如,由于散度相同,因此使用乘法而不是将每个单独的kl散度加在一起)。为了确定跨群体的总散度,散度参数求解器234根据等式29跨所有散度和所有人口统计群体求和(框604):
[0100][0101]
为了充分描述受众的行为和持续时间,散度参数求解器234根据等式30最小化等式29:
[0102][0103]
受制于
[0104][0105]
在等式30中,{xk}、{tk}和{vk}分别表示与独特受众规模、印象数和印象持续时间有关的普查级数据,所有这些都是未知的。然而,等式30受制于总普查级印象数(t)和总参考普查级印象持续时间(v)的参考值(例如,总印象134和总持续时间136)。在一些示例中,散度参数求解器234通过根据等式31-34取等式30组的拉格朗日量来求解该等式组,其中该解针对所有人口统计群体k={1,2,...,k},除了将关于拉格朗日乘数(λ1和λ2)的偏导数设置为等于0(例如,等式35)外:
[0106][0107][0108][0109][0110][0111]
散度参数求解器234使用拉格朗日乘数(λ1和λ2)求解等式31的拉格朗日量,以表示包括在总普查级印象数(t)的参考普查级数据中的普查级印象数约束(λ1)、和包括在总参考普查级印象持续时间(v)中的普查级印象持续时间约束(λ2)。除了跨人口统计群体(k)的总印象数约束(λ1)和总持续时间约束(λ2)之外,每个人口统计群体都是相互排斥的,不会影响其他人口统计群体。因此,除了增加上述约束之外,普查级独特受众规模{xk}、印象数{tk}和印象持续时间{vk}的基于拉格朗日量的导数涉及相同人口群体的方面(例如,35-40岁的女性)。
[0112]
搜索空间识别器232在基于普查级印象(λ1)和普查级持续时间(λ2)等式约束的界限内建立搜索空间{δ1,δ2}(框602、604)。例如,搜索空间{δ1,δ2}可以根据等式36-37定义:
[0113][0114][0115]
在等式36中,δ1的上限定义为跨所有人口统计群体(k)的1/max(z
q2,k
),其中z2对应于等式17-18中确定的z2的解,q对应于与第三方订户数据相关联的先验分布。在等式37中,δ2的上限由第三方订户数据中跨所有人口统计群体的每个印象持续时间(dk)的第三方订户受众规模(ak)的最小值定义。搜索空间{δ1,δ2}的示例推导和等式30-31的相应拉格朗日解推导在下面的“示例拉格朗日解”小节中更详细地描述。
[0116]
一旦概率散度确定器230已经得出等式30-31的解,并且搜索空间识别器232已经识别了搜索空间{δ1,δ2},散度参数求解器234使用迭代器236和普查级输出计算器238基于z0、z1、z2和z3以及搜索空间参数来评估散度参数(框606),验证满足等式约束以估计普查级个体数据的独特受众规模{xk}、印象数{tk}和印象持续时间{vk}(框608)。例如,等式30-31的解可以根据等式38-43来表示(如“示例拉格朗日解”小节中所述的,其中c0、c1、c2、c3、c4的推导在等式79-83中示出):
[0117][0118][0119][0120]
等式38-39表示当迭代器236在由搜索空间识别器232和普查级输出计算器238建立的搜索空间{δ1,δ2}上迭代时,向量{xk,tk,vk}的普查级数据估计验证已经满足该等式约束(例如,该等式约束对应于参考总普查级印象数(t)和参考总普查级印象持续时间(v))。在一些示例中,普查级输出计算器238验证等式约束对于跨所有人口统计群体的普查级受众度量是有效的。因此,对第三方订户数据的访问允许受众度量估计器140通过求解{xk,tk,vk}来估计普查级独特受众规模、印象数和印象持续时间。
[0121]
图7a-图7d包括表示机器可读指令的示例编程代码,该机器可读指令可以被执行以实现图1-图2的示例受众度量估计器,以基于第三方订户数据122(例如,受众规模124、印象数126和印象持续时间128)和普查级总印象数134和总印象持续时间136,来跨多个人口统计群体估计普查级独特受众规模312、普查级印象数314和普查级印象持续时间316。图3-图6的示例指令可用于matlab开发环境。然而,类似的指令可用于在其他开发环境中实现本文公开的技术。在图7a中,附图标记702的示例指令实现上面的等式20-22以定义个体在受众中的概率分布(d1)、具有平均印象数的概率(d2)和具有平均印象持续时间的概率(d3)。附图标记704(图7b)的示例指令基于等式13-14以z表示法定义针对个人特定分布问题的解。附图标记706的示例指令直接定义z0和z3,而z1的解是基于z2的解定义的,z2可以使用例如定点迭代来求解(例如,基于等式16、17和18的指令)。附图标记708的示例指令可以基于等式
36-37,该等式36-37用于在基于z表示法的普查级印象(z2)和普查级持续时间(z3)等式约束的界限内建立搜索空间{δ1,δ2}。附图标记710和712的示例指令创建结构数据类型以对相关数据进行分组(例如,在数组中),同时还定义全域估计(例如,总受众估计),并清除存储在z0到z3中的任何值。
[0122]
图7c用附图标记714示出了使用有界非线性最小二乘来求解等式组的示例指令。例如,上界是使用附图标记708的指令设置的。附图标记716-718的示例指令进一步定义了使用非线性最小二乘法求解的变量,而附图标记720和722的示例指令是用于求解针对普查级个体数据的独特受众规模{xk}、印象数{tk}和印象持续时间{vk},这基于等式38-40和等式79-83(参见“示例拉格朗日解”小节)使用附图标记724处的示例指令实现的。尽管非线性最小二乘法用于求解普查级个体数据,但可以实施适合于求解所提出的等式组的任何其他方法。
[0123]
图8a-图8c包括用于定义由图1-图2的示例受众度量估计器使用的第三方订户和普查级数据参数的示例变量集、以及提供第三方订户和普查级数据的示例数据集。图8a列出了表800,其具有在基于第三方订户数据确定普查级数据时自始至终使用的符号。例如,附图标记802标识人口统计群体k(例如,人口统计群体1可以指代35-40岁的女性,人口统计群体2可以指代35-40岁的男性等)。附图标记804标识群体(例如,每个人口统计群体(uk)的全域受众(u))。附图标记806标识第三方订户数据,包括用于受众规模(ak)、印象数(rk)和印象持续时间(dk)的订户数据。附图标记808标识普查级数据,包括普查级独特受众(xk)、普查级印象数(tk)和普查级印象持续时间(vk)。附图标记810标识每个数据组的总计数,包括总全域受众(u)、第三方总受众规模(a)、第三方总印象数(r)、第三方总印象持续时间(d)、普查级总受众规模(x)、普查级总印象数(t)和普查级总印象持续时间(v)。
[0124]
图8b示出了表820,具有可从图1的第三方订户数据122获得的示例数据集以及图1的普查级总印象134和总印象持续时间136可用的示例数据集。例如,考虑总共三个不同的人口统计群体(k)(附图标记822)。对于每个人口统计群体(例如,k=1-3),群体824(例如,全域受众,uk)的范围对于人口统计群体1-3分别为从总共1000到总共3000人。第三方订户数据826包括每个人口统计群体的受众、印象和持续时间值,以及总受众规模、总印象数和总印象持续时间的值。普查级数据828仅包括总印象数(例如,5000)和总印象持续时间(例如,15000),而人口统计群体特定的独特受众规模、印象数和印象持续时间以及总独特受众规模都是使用贯穿本技术描述的方法求解并应用于以下示例的变量。例如,使用可用于第一人口统计群体(k=1)的数据,可以应用等式19-22来计算特定于第三方订户数据的概率值,如示例4所示:
[0125][0126][0127]
[0128][0129]
使用上面示例4的示例计算,可以确定所有人口统计群体k的其余概率,以生成每个zq值的示例向量(示例5):
[0130][0131][0132][0133][0134]
示例6示出了在等式36-37定义的空间内的示例搜索以及基于等式30定义的约束,{δ1,δ2}的所得示例解:
[0135][0136][0137]
受约束
[0138]
{δ1,δ2}={1.0285,0.0267}
[0139]
基于等式79-83(参见“示例拉格朗日解”小节),第一人口统计群体的解可以在示例7中确定如下:
[0140][0141]
c1=log(1-c0)=-3.1361
[0142][0143][0144][0145]
等式38-40可用于确定人口统计群体k=1的普查级独特受众规模(例如x1)、普查级印象数(例如t1)和普查级别印象持续时间(例如v1)的解,如示例8所示:
[0146][0147]
[0148][0149]
人口统计群体k=2和k=3的解可以类似地使用上述方法与示例9和10中生成的向量一致地确定:
[0150]
c0={ 0.9565, 0.9291, 0.8752}
ꢀꢀ
示例9
[0151]
c1={-3.1361,-2.6459,-2.0812}
[0152]
c2={-0.0399,-0.0967,-0.1816}
[0153]
c3={-0.0736,-0.1123,-0.1895}
[0154]
c4={ 10.7395, 11.7410, 11.3203}
[0155]
x={457.4870,276.7211,124.3517}
ꢀꢀ
示例10
[0156]
t={3,211.3,1,369.6,419.1}
[0157]
v={11,454,2,861,685}
[0158]
如示例6中所述,当满足普查级约束时,上述解有效。例如,上述解(例如示例10)与σt=5000和σv=15000一致。上面确定的最终值填充在图8b的表820中,使得对于每个人口统计群体k=1,2和3,普查级数据830包括独特受众规模(xk)、印象数(tk)和印象持续时间(vk)。
[0159]
图8c示出了具有可从图1的第三方订户数据122获得的示例数据集846的表840、以及可用于图1的普查级总印象数134和总印象持续时间136的示例数据集848。在图8c的示例表840中,第三方订户数据846的印象持续时间具有与图8b的表820相同的针对每个人口统计群体842的受众规模数据和印象数数据、以及相同的群体规模844。同样,普查级数据848的总印象数(例如,5000)保持不变,总印象持续时间(例如,250)也是如此。然而,第三方订户数据846的印象持续时间对于每个人口统计群体842比图4b的表820中所示的要短得多。例如,如果将持续时间更改为新单位(例如,通过乘以缩放因子),则普查持续时间的最终估计值也应按相同因子缩放,而受众规模和印象数的估计值应保持不变。例如,图8b的第三方订户数据826的印象持续时间除以60(例如,将分钟更改为小时、或秒更改为分钟,这取决于原始单位),会产生对于每个人口统计群体k的第三方订户数据846的印象持续时间。如图8b所描述的求解过程与图8c中所示的数据保持相同,其中确定的概率向量集如示例11所示:
[0160][0161][0162][0163][0164]zq
向量可以使用示例11的dq向量来求解,示例12中示出了zq向量的解:
[0165][0166]
[0167][0168][0169]
如前所述,{δ1,δ2}的搜索空间和对应解可以表示为如下例13所示:
[0170][0171][0172]
{δ1,δ2}={1.0285,1.6036}
[0173]
可以基于在示例11-13中执行的计算来确定表840的普查级数据848的普查级估计,使得满足设置约束的最终向量和普查级估计可以表示为下面的示例14和15中所示:
[0174]
c0={0.9565,0.9291,0.8752}
ꢀꢀ
示例14
[0175]
c1={-3.1361,-2.6459,-2.0812}
[0176]
c2={-2.3964,-5.8038,-10.8964}
[0177]
c3={-4.4172,-6.7357,-11.3676}
[0178]
c4={644.3716,704.4621,679.2174}
[0179]
x={457.4870,276.7211,124.3517}
ꢀꢀ
示例15
[0180]
t={3,211.3,1,369.6,419.1}
[0181]
v={190.9083,47.6795,11.4122}
[0182]
基于这些结果,图8c的表840可以用示例15中所示的确定的独特受众规模(xk)、印象数(tk)和印象持续时间(vk)的普查级数据850填充。
[0183]
图9示出了具有基于比例独立性和比例不变性的示例变量表征的表900,图1-图2的示例受众度量估计器生成普查级独特受众和印象的估计。例如,如用于填充图8c的表840的示例解中所描述的,由于印象持续时间(d)中使用的时间单位针对任何单位(例如,秒、分钟、小时等)进行缩放,每个人口统计群体的估计普查级印象持续时间(d)也按相同的因子缩放,而估计的受众规模(a)和印象数(r)可以保持不变(例如,参见表900的由附图标记908表示的子部分)。因此,受众和印象数都与比例无关,但印象持续时间不随比例变化。示例表900包括变量的列表902、以及变量是与比例无关的列表904(例如,保持不变)还是不随比例的变化而变化的列表906(例如,缩放性)。表900示出了当持续时间被缩放时每个变量如何改变(例如,持续时间被缩放而所有其他变量保持不变)。示例表900进一步划分为子部分(例如,附图标记908-920)以说明在确定普查级估计时比例变化如何影响使用的变量。例如,附图标记910指示与第三方订户数据先验分布(q)的概率相关联的变量(其与持续时间相关联)被缩放,而与受众规模和印象数相关联的其余变量未被缩放。例如,第k个人口统计群体中的特定个体是第三方聚合的订户受众总数(ak)成员的概率被定义为d
1q
,第k个人口统计群体中的特定个体具有在第三方聚合的订户印象数总数(rk)中的印象数的概率被定义为d
2q
,第k个人口统计群体中的特定个体具有在第三方聚合的印象持续时间总和(dk)中的印象持续时间的概率被定义为d
3q
(例如,唯一的被缩放的概率,如子部分910所示)。表900的子部分912指示,当z
1q
和z
3q
被缩放时,用于基于第三方的订户数据的基于z表示法的解不
受z
0q
和z
2q
缩放的影响。同样,搜索空间变量δ1边界不受缩放影响(例如,子部分914和916),而鉴于δ2上限包括持续时间变量(d)(例如,基于等式37),δ2边界被缩放。子部分第918指示,普查级估计{x,t,v}的最终解包括不受缩放影响的变量c0和c1,而变量c
2,
、c3和c4被缩放,鉴于基于等式79-83(参见“示例拉格朗日解”部分),c0和c1解基于不受缩放影响的变量(例如z
2q
),而变量c
2,
、c3和c4基于可缩放的变量(例如,z
1q
和z
3q
)。因此,最终普查级估计{x,t,v}包括不受缩放影响的受众规模和印象数,而印象持续时间被缩放,如先前在图8c的表840的示例解中所示。
[0184]
图10是构造成执行图3-图6的指令以实现图1-图2的示例受众度量估计器的示例处理平台的框图。处理器平台1000可以是,例如,服务器、个人计算机、工作站、自学习机(例如,神经网络)、移动设备(例如,手机、智能手机、诸如ipad
tm
的平板电脑)、个人数字助理(pda)、互联网设备、或者任何其他类型的计算设备。
[0185]
所示示例的处理器平台1000包括处理器1006。所示示例的处理器1006是硬件。例如,处理器1006可以由一个或多个集成电路、逻辑电路、微处理器、gpu、dsp、或来自任何期望家族或制造商的控制器来实现。硬件处理器1006可以是基于半导体(例如,基于硅)的设备。在该示例中,处理器1006实现图2的示例概率分布生成器220和示例概率散度确定器230。
[0186]
所示示例的处理器1006包括本地存储器1008(例如,高速缓存)。所示示例的处理器1006通过总线1018与包括易失性存储器1002和非易失性存储器1004的主存储器通信。易失性存储器1002可以由同步动态随机存取存储器(sdram)、动态随机存取存储器(dram)、动态随机存取存储器和/或任何其他类型的随机存取存储器设备来实现。非易失性存储器1004可以由闪存和/或任何其他期望类型的存储器设备来实现。对主存储器1002、1004的访问由存储器控制器控制。
[0187]
所示示例的处理器平台1000还包括接口电路1014。接口电路1014可以由任何类型的接口标准实现,例如以太网接口、通用串行总线(usb)、接口、近场通信(nfc)接口、和/或pci-express(串行总线)接口。
[0188]
在所示示例中,一个或多个输入设备1012连接到接口电路1014。(一个或多个)输入设备1012允许用户向处理器1006输入数据和/或命令。(一个或多个)输入设备可以由例如音频传感器、麦克风、照相机(静物或视频)、键盘、按钮、鼠标、触摸屏、轨迹板、轨迹球、等点、和/或语音识别系统来实现。
[0189]
一个或多个输出设备1016也连接到所示示例的接口电路1014。输出设备1016例如可以由显示设备(例如,发光二极管(led)、有机发光二极管(oled)、液晶显示器(lcd)、阴极射线管显示器(crt)、就地开关(ips)显示器、触摸屏等)、触觉输出设备、打印机和/或扬声器来实现。因此,所示示例的接口电路1014通常包括图形驱动卡、图形驱动芯片和/或图形驱动处理器。
[0190]
所示示例的接口电路1014还包括通信设备(例如发射器、接收器、收发器、调制解调器、住宅网关、无线接入点和/或网络接口),以促进通过网络1024与外部机器(例如,任何种类的计算设备)交换数据。通信可以通过例如以太网连接、数字用户线路(dsl)连接、电话线连接、同轴电缆系统、卫星系统、直线对传式无线系统、蜂窝电话系统等实现。
[0191]
所示示例的处理器平台1000还包括用于存储软件和/或数据的一个或多个大容量存储设备1010。此类大容量存储设备1010的示例包括软盘驱动器、硬盘驱动器、光盘驱动器、蓝光光盘驱动器、独立磁盘冗余阵列(raid)系统和数字多功能盘(dvd)驱动器。大容量存储设备1010包括图2的示例数据存储器202。
[0192]
图3-图6中表示的机器可执行指令1020可以存储在大容量存储设备1020、易失性存储器1002、非易失性存储器1004、和/或可移除的非暂时性计算机可读存储介质(例如cd或dvd)上。
[0193]
示例拉格朗日解
[0194]
跨所有k个人口统计群体的拉格朗日量,包括普查级浏览量和持续时间约束以及乘数,使用等式29和31来定义,如上文所述并在下文再现:
[0195][0196][0197]
鉴于除基于普查的约束外,每个人口统计群体都是独立的,因此在下面呈现的推导中删除了下标k,该推导描述了基于单个人口统计群体的解,以说明推导过程。等式29和31可以根据等式41扩展:
[0198][0199][0200]
假设所有zq都是基于第三方订户数据求解的,这些可以用作每个人口统计群体的参考常数。z
p
的表达式(例如,普查级数据,p)可以用d
p
变量代替,如等式42-45所示:
[0201][0202][0203][0204][0205]
可以进一步定义基于普查级的数据人口统计变量,如等式46-49中所示(例如,以上结合等式19-22描述的)。例如,特定个体是普查级独特受众总数(x)成员的概率被定义为
x/u,特定个体具有在普查级印象数总数(t)中的印象数的概率被定义为t/u,特定个体具有在普查级印象持续时间总和(v)中的印象持续时间的概率被定义为v/u:
[0206][0207][0208][0209][0210]
拉格朗日量可以进一步根据下面的等式50使用等式46-49来表示:
[0211][0212]
每个普查变量{x,t,v}中的偏导数可以如下所示在等式51-53中获得:
[0213][0214][0215][0216]
在等式51-53中,保留了z
p2
项,同时还呈现了它们对每个变量的偏导数中的所有偏导数(例如,)。z2的表达式(例如,为了简化而取消下标p)可以根据下面的等式54来表示:
[0217][0218]
虽然z2不是直接使用等式54求解的,但可以分别使用等式55、56和57,利用隐式微分来表示普查级独特受众总数(x)、普查级印象数总数(t)和普查级印象持续时间总和(v):
[0219][0220]
[0221][0222]
所得到的等式55-57的偏导数可以根据等式58-60分别求解为每个表达式的{t,x,z2}的函数:
[0223][0224][0225][0226]
虽然z2也不是直接求解的,但它的偏导数是基于z2的值。因此,为了消除log(1-z2)项,等式56可以重写为下面的等式61:
[0227][0228]
等式61可以进一步代入等式58-60以减少仅基于z2的偏导数,如下面的等式62-64所示:
[0229][0230][0231][0232]
使用等式62-64,等式51-53中的拉格朗日导数可以进一步简化,如下面的等式65-67所示:
[0233][0234][0235][0236]
使用等式66,z2的项现在可以表示为等式68(例如,当等式66设置为等于0时),这样它就变成了参数:
[0237][0238]
鉴于每个偏导数应该是基于{x,t,v}的,等式66可以被重写,使得当所有三个表达
式都等于0时可以同时求解等式65-67的所有三个偏导数。因此,等式69-70用于进一步代入的是66,从而得到等式71:
[0239]
z2=exp(log(z2))对于z2》0
ꢀꢀꢀ
等式69
[0240][0241][0242]
可以通过将等式68代入等式65、67和71中偏导数的三个表达式来进行进一步调整。得到的等式72-74是基于三个变量{x,t,v}和两个参数{λ1,λ2}的表达式:
[0243][0244][0245][0246]
因此,当所有表达式都等于0时,可以针对每个变量求解等式72-74,从而得到以下等式75-77:
[0247][0248][0249][0250]
每个人口统计群体的最终结果可以通过简化得出的表达式来获得,首先通过符号的变化(例如,从λ到δ,如等式78所示),然后为等式75-77中的部分定义新的变量(例如,变量c
0-c4,如等式79-83所示):
[0251][0252][0253]
c1=log(1-c0)
ꢀꢀꢀꢀꢀꢀꢀ
等式80
[0254]
[0255][0256][0257]
基于下面的等式79-83,每个人口统计群体对普查级独特受众(x)、普查级印象数(t)和普查级印象持续时间(v)的解可以表示为以下等式84-86:
[0258][0259][0260][0261]
由于{λ1,λ2}={0,0}将普查数据返回给第三方订户数据,因此δ的等效中性值为{δ1,δ2}={1,0}。为了跨所有人口统计群体找到有效{δ1,δ2}的域,对数内的表达式1-c0对于所有人口统计群体都应该是正的,使得在下面的等式87中,跨所有人口统计群体,最大值大于z
q2
。同样,第三方订户数据中跨所有人口统计群体的每持续时间的受众最小值可以表示为等式88:
[0262][0263][0264]
因此,对于按比例缩小而不是按比例放大,δ的下限不再是有限的,而是各自无界到负无穷大(-∞)。
[0265]
根据上文,可以理解,示例系统、方法和装置允许使用第三方订户级受众度量,其提供关于印象数、印象持续时间和独特受众规模的部分信息,以克服在估计媒体的总独特受众规模时普查级印象的匿名性。在本文公开的示例中,受众度量估计器通过以下来跨人口统计群体确定普查级独特受众、印象数和印象持续时间:生成概率分布和确定第三方普查级数据和订户数据之间存在的概率散度,以及基于等式约束建立界限内的搜索空间,使得在满足等式约束之前在搜索空间上进行迭代会产生普查级个体数据估计。本文公开的示例使用第三方得出的部分受众度量和总普查级持续时间来确定不同人口统计群体在普查级别上的受众规模和持续时间。本文公开的示例允许在逻辑上与所有约束、比例独立性和不变性一致的估计。此外,本文公开的示例允许监控任何一种或多种媒体类型的媒体印象。
[0266]
尽管本文已经公开了某些示例方法、装置和制品,但是本专利的覆盖范围不限于此。相反,本专利涵盖了完全落入本专利权利要求范围内的所有方法、装置和制品。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。