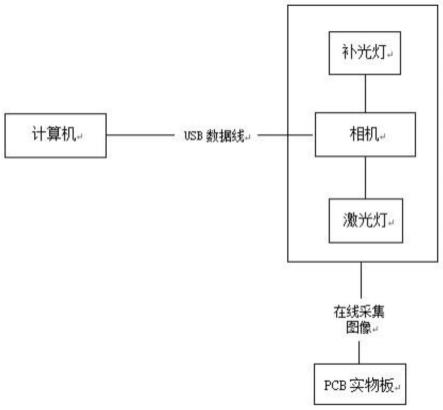
1.本发明属于人工智能技术领域,特别涉及一种融合词根词缀和音标的蒙古语预训练情感分析方法。
背景技术:
2.文本情感分析又称意见挖掘,是指对带有情感色彩的主观性文本进行分析,挖掘其中蕴含的情感倾向,对情感态度进行划分。文本情感分析作为自然语言处理的研究热点,在舆情分析、用户画像和推荐系统中有很大的研究意义。
3.由于蒙古语属于小语种语言,这使得有关蒙古语的自然语言处理研究起步较晚,并且蒙古语情感分析的研究进展相对缓慢。目前基于深度学习的情感分析方法都需要大量的语料数据做驱动,蒙古语情感语料目前处于匮乏阶段,如何缓解资源不足的问题已经成为蒙古语情感分析的一个重要的研究课题。
4.最新的基于深度学习的情感分析方法大多基于对预训练模型的微调来实现更好的情感分析效果,由于bert等预训练模式最初为英文设计,但是蒙古语属于黏着语,与英语的构词方法不同,因此通过对bert模型微调进行蒙古语的情感分析效果很差。
5.那么,对蒙古语语料进行数据增强的同时,再结合蒙古语的语言特点,利用蒙古语单语语料通过对bert模型进行预训练,从而提升下游情感分析任务的准确率是一个亟待解决的问题。
技术实现要素:
6.为了克服上述现有技术的缺点,本发明的目的在于提供一种融合词根词缀和音标的蒙古语预训练情感分析方法,采用融合词根词缀和音标对bert模型进行预训练,另外,将对比学习的方法融入到mlm任务中,通过对比学习来实现数据增强,从而提高模型的准确率,进而也可以提高情感分析的准确性。
7.为了实现上述目的,本发明采用的技术方案是:
8.一种融合词根词缀和音标的蒙古语预训练情感分析方法,包括如下步骤:
9.步骤1,对蒙古语语料进行预处理;
10.步骤2,构建蒙古语bert预训练模型,其中,在其嵌入层构造词嵌入、词根嵌入、词缀嵌入和音标嵌入;将所述嵌入进行拼接后得到融合嵌入,然后再将融合嵌入与位置嵌入相加,形成模型输入;
11.步骤3,在所述蒙古语bert预训练模型中,将对比学习和mlm的融合任务进行预训练;
12.步骤4,对蒙古语情感语料进行预处理;
13.步骤5,用训练好的融合词根词缀和音标的蒙古语bert预训练模型对蒙古语情感语料进行情感分析。
14.与现有技术相比,本发明的有益效果是:
15.本发明利用蒙古语自身的语言特点,融合蒙古语的词根、词缀和音标设计了一款专属蒙古语的bert预训练模型,在模型的预训练任务中加入对比学习来进行数据增强,这样的设计不仅缓解了蒙古语数据匮乏的问题,而且有效的提高了蒙古语情感分析任务的准确率;同样,该模型也可以应用到其他蒙古语的自然语言处理任务中,这有助于提高机器翻译、句子语义相似度等任务的准确率;再次,本发明也可以为其他小语种语言提供模型参考。
附图说明
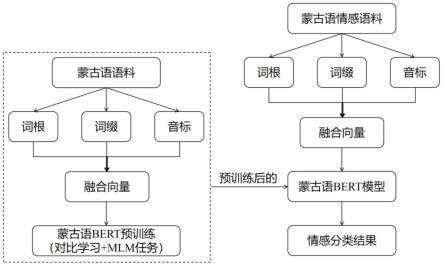
16.图1是本发明整体流程示意图。
17.图2是本发明模型预训练流程示意图。
18.图3是本发明情感分析流程示意图。
19.图4是本发明例句的词根词缀拆分示意图。
20.图5是本发明词根嵌入。
21.图6是本发明词缀嵌入。
22.图7是本发明音标嵌入。
23.图8是本发明融合嵌入。
24.图9是本发明预训练模型整体结构。
具体实施方式
25.下面结合附图和实施例详细说明本发明的实施方式。
26.如图1所示,本发明为一种融合词根词缀和音标的蒙古语预训练情感分析方法。本发明分两部分,第一部分是融合词根词缀和音标的蒙古语bert预训练过程,预训练任务由对比学习和mlm任务融合构成,如图2所示。第二部分是利用上述预训练好的模型进行情感分析任务,如图3所示。
27.本发明实施例中,具体步骤包括:
28.步骤1,对蒙古语语料进行预处理操作。
29.示例地,本发明的预处理包括数据清洗和分词。先对蒙古语语料进行数据清洗操作,再利用bpe对蒙古语进行分词操作。
30.对于分词操作,将每个蒙古语词汇以词根词缀为单位分开。例如:译为“已经来了”,分词要将其分为前缀(来)和后缀(表示过去)。对于无法切分为词根词缀的词汇则保持原样。以“人们工作去了”为例,其对应的蒙古语表示为按照词根词缀分词的结果如图4所示。
31.步骤2,构建由嵌入层和bert encoder结构构成的蒙古语bert预训练模型。为了结合蒙古语自身的语言特点,在预训练的嵌入层构造了词嵌入、词根嵌入、词缀嵌入和音标嵌入,模型将这四个嵌入进行拼接后得到融合嵌入,然后再将融合嵌入与位置嵌入相加,形成模型的输入。
32.其中,传统bert的嵌入层由融合嵌入、位置嵌入和文本嵌入构成,本发明的改进点是将底层的融合嵌入融入了除词嵌入之外的词根嵌入、词缀嵌入和音标嵌入。
33.在本发明的一个实施例中,由于只有在进行nsp训练任务时,才在位置嵌入后一起加入文本嵌入得到模型输入,本发明的用例没有涉及到nsp任务,故在嵌入层中不需要加文本嵌入。也即,本发明嵌入层在传统bert嵌入层中词嵌入、位置嵌入和文本嵌入的基础上,去掉文本嵌入,加入了词根嵌入、词缀嵌入和音标嵌入,由融合嵌入和位置嵌入构成本发明的嵌入层。bert encoder结构与传统bert相同,即由多层的transformer encoder堆叠形成。
34.由于蒙古语是以动词为核心的语言,动词的词尾变化决定一句话的语境。比如蒙古语中表示否定的后缀为这对于包含该后缀的句子来说,其情感色彩显而易见。因此构建词根嵌入和词缀嵌入有助于提高下游情感分析任务的准确率。
35.其中:
36.词嵌入是在词粒度上进行嵌入,与原始bert模型中的token embedding一样。
37.词根嵌入是将分词后的词根进行嵌入,本发明对该序列采用cnn与最大池化得到最终的词根序列,以词语(人们)为例,如图5所示。
38.词缀嵌入是将分词后的词缀进行嵌入,本发明对该序列采用cnn与最大池化得到最终的词缀序列,以词语(人们)为例,如图6所示。对于无法进行词根词缀切分的词汇,则直接将其原型作为词根和词缀进行嵌入。
39.音标嵌入是将蒙古语词汇对应的国际音标进行嵌入。本发明对该序列采用cnn与最大池化得到最终的音标序列,以词语(人们)为例,如图7所示。因为蒙古语与汉语相似,存在“多音字”的情况,比如在表示“星星”意思时的发音为而在表示“现在”的意思时其发音为因此,音标嵌入有助于提高模型训练的精确性。
40.融合嵌入是将词嵌入、词根嵌入、词缀嵌入和音标嵌入经过cnn后得到的矩阵拼接在一起,经过一个全连接层后得到该蒙古语词汇对应的融合嵌入,以词语(人们)为例,如图8所示。
41.每个蒙古语词汇对应的融合嵌入与位置嵌入相加,作为模型输入。
42.容易理解,在本发明的一个实施例中,在需要进行nsp训练任务时,嵌入层由融合嵌入、位置嵌入和文本嵌入构成,将融合嵌入与位置嵌入和文本嵌入相加,形成模型输入。
43.步骤3,在蒙古语bert预训练模型中,进行对比学习和mlm任务的预训练。在对比学习的任务中,以随机丢弃掩码的方法作为数据增强的方式进行对比学习中正样本的构造,将同一个样本即由嵌入层得到的输入向量分两次输入到蒙古语bert预训练模型中,通过随机丢弃掩码得到两个不同的向量si和s
′i,将这两个向量作为正样本对,随机采样一个batch中的另一个输入作为负样本sj。
44.对比学习的损失函数li为:
[0045][0046]
其中ω为超参数,n为一个batch的大小。
[0047]
cos(si,s
′i)为向量si和向量s
′i的余弦相似性,其公式为:
[0048][0049]
cos(si,sj)为向量si和向量sj的余弦相似性,其公式为:
[0050][0051]
mlm预训练任务采用随机遮蔽一部分(例如15%)的token,在随机掩码的过程中有第一比例(例如10%)的词被替换为其他词,第二比例(例如10%)的词不变,剩余的词(80%)被替换为掩码[mask],mlm预训练任务的损失函数为:
[0052][0053]
其中θ为蒙古语bert预训练模型中encoder部分的参数,θ
′
为mlm预训练任务中在encoder上所接输出层中的参数,m为被掩码的词集合,mk为被掩码的词,p为样本k的预测概率,|v|为词典大小;
[0054]
因此,融合对比学习和mlm预训练任务的损失函数为:
[0055][0056]
以(人们工作去了)为例,预训练模型整体结构如图9所示。
[0057]
步骤4,对蒙古语情感语料进行预处理。
[0058]
与步骤1中的预处理操作相同,对蒙古语情感语料进行数据清洗操作,再利用bpe将蒙古语以词根词缀为单位进行分词操作,对于无法切分为词根词缀的词汇保持原样。
[0059]
步骤5,用训练好的融合词根词缀和音标的蒙古语bert预训练模型对蒙古语情感语料进行情感分析。
[0060]
将切分好的语料放入模型中进行情感分析,并为模型添加softmax层得到情感分类。以(不值这个价格)为例,送入模型后会得到
“‑
1”(消极)的分类结果。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。