1.本发明涉及脑机接口技术领域,涉及一种脑机接口的冷启动方法。
背景技术:
2.脑机接口(brain computer interface,bci),指在人或动物大脑与外部设备之间创建的直接连接,实现脑与设备的信息交换。这一概念其实早已有之,但直到上世纪九十年代以后,才开始有阶段性成果出现。2008年,匹兹堡大学神经生物学家宣称利用脑机接口,猴子能用操纵机械臂给自己喂食。
3.脑机接口技术的应用前景广泛,不仅其能够在智能家居、环境交互、游戏娱乐等诸多领域发挥作用,而且更能够在运动康复、神经干预等领域大展身手。目前传统的康复方式,大多比较被动,比如按摩、针灸、卧床训练、离床训练等,无法唤醒病人强烈的运动意念,患者容易疲劳,也无法达到理想的训练协同性,治愈率在国内不会超过50%。而利用脑机接口技术实现人机交互康复训练,其作为一种基于视觉运动的新型脑控康复方式,能够通过主被动协同的方式实现其有效性,经过医院对照试验证明,经康复训练后,使用脑控康复床患者效果明显优于传统康复训练患者,其临床效果相较于传统康复提升了近20%。
4.在当前的eeg(脑电信号)研究领域,不同受试间的巨大信号特征差异是主要的研究难题之一。正是由于不同受试的eeg之间的巨大特征模式的差异,导致相关的基于机器学习的方法很难通过监督学习任务来训练得到一个具有很强的泛化能力并适用于大多数受试的模型。为获取适用性较好的模型往往需要先进行长时间的训练(需要大量训练数据),花费较大的时间成本。因此,现有的基于脑机接口的医疗康复产品,往往无法广泛的适用于的大多数患者,而是针对性的适用于病情特定、身体条件特定和治疗环境特定的某类患者,并对于不符合产品目标类型的患者性能较差。
5.因此,开发一种无需大量训练即可被bci提取清晰信息的技术手段极具现实意义。
技术实现要素:
6.由于现有技术存在上述缺陷,本发明提供了一种无需大量训练即可被bci提取清晰信息的技术手段,克服了当前技术条件下需要大量训练数据才能获取准确性较好且适用性较好的bci模型的缺陷。
7.为了实现上述目的,本发明提供以下技术方案:
8.一种脑机接口的冷启动方法,利用脑机接口获取目标的脑电信号后,数据处理单元运行数据处理模型处理脑机接口所获取的目标的脑电信号,数据处理模型输出与脑电信号对应的信息;
9.所述数据处理单元通过脑机接口与目标连接;
10.所述数据处理模型为迁移学习网络模型,所述迁移学习网络模型的训练过程为以训练数据集中的脑电信号数据作为输入,以脑电信号数据对应的已知标签信息作为理论输出,不断调整迁移学习网络的参数的过程,训练的终止条件为模型在固定的训练轮次内,在
评测数据集上的准确率不再提升。
11.在当前的eeg研究领域,使用小样本数据实现bci系统冷启动是主要的研究难题之一。正是由于当前主流的基于自发eeg的bci系统对于每位新受试都需要大量的训练数据进行长时间的模型训练后,才能被新受试正常的使用,导致这些bci系统对于数据样本数较少的新受试往往性能表现较差。本发明运用迁移学习网络模型对信号进行处理,通过对已知受试数据的处理,迁移所学习到的知识并应用于处理新受试的数据,从而实现仅使用少量新受试数据,基于预训练模型就可以快速的提取新受试的特征模式。
12.作为优选的技术方案:
13.如上所述的一种脑机接口的冷启动方法,所述迁移学习网络模型包括用于特征提取的lstm模块、用于特征匹配的注意力模块和用于特征分类的cnn模块。
14.如上所述的一种脑机接口的冷启动方法,所述lstm模块、注意力模块及cnn模块顺序连接。
15.如上所述的一种脑机接口的冷启动方法,所述lstm模块应用模型迁移方法,具体为:首先将lstm模块在源域受试数据集进行有监督的学习,将学习好的网络模块权重固定,并将预训练网络模型直接迁移到目标域受试数据集上,用于实现对于目标域受试数据集特征提取的少样本学习,lstm网络的模式公式如下:
16.z=tanh(w
·
concatenation(x
t
,h
t-1
))
17.zf=σ(wf·
concatenation(x
t
,h
t-1
))
18.zi=σ(wi·
concatenation(x
t
,h
t-1
))
19.zo=σ(wo·
concatenation(x
t
,h
t-1
))
20.c
t
=zf*c
t-1
zi*z
21.h
t
=zo*tanh(c
t
)
22.y
t
=σ(wo·ht
)
[0023][0024][0025]
其中,z为当前状态,x
t
为输入,h
t-1
为上一个隐藏层状态,zf为遗忘门,zi为信息门,zo为输出门,w、wf、wi、wo为对应门的权重,c
t
为当前时刻元素状态,c
t-1
为上一时刻元素状态,h
t
为隐藏层状态。
[0026]
将特征提取lstm模块在源域受试数据集上学习到的预训练网络模型迁移到目标域受试上,实现对于新受试特征提取的冷启动。
[0027]
如上所述的一种脑机接口的冷启动方法,所述注意力模块应用特征迁移方法,具体为:将特征组合注意力模块在源域受试数据集进行有监督的学习,将网络模型在训练过程中得到的特征选取注意力参数,迁移到目标域受试模型的注意力模块中,用于实现对于目标域受试数据集特征组合的少样本学习。
[0028]
注意力机制的公式如下:
[0029]
μ
it
=tanh(ww·hit
bw)
[0030][0031]
si=∑
t
α
it
·hit
[0032]
其中,μ
it
为输入序列在时刻t的隐藏层向量,h
it
为隐藏层在时刻t的状态,ww和bw为参数权重,a
it
为隐藏层在时刻t的权重,μw为权重。
[0033]
将特征组合注意力模块在源域受试数据集上学习到的注意力特征迁移到目标域受试上,实现对于新受试特征选择的冷启动。
[0034]
如上所述的一种脑机接口的冷启动方法,其特征在于,所述cnn模块应用模型微调方法,具体为:首先将特征分类cnn模块在源域受试数据集进行有监督的学习,将学习好的网络模块权重记录,并迁移到目标域受试模型的cnn模块中,接下来基于目标域受试的少样本数据继续训练微调所迁移的网络权重,用于实现对于目标域受试数据集特征分类的少样本学习。将特征分类cnn模块在源域受试数据集上学习到的预训练网络模型迁移到目标域受试上继续学习训练,实现对于新受试特征分类的冷启动。
[0035]
以上技术方案仅为本发明的一种可行的技术方案而已,本发明的保护范围并不仅限于此,本领域技术人员可根据实际需求合理调整具体设计。
[0036]
上述发明具有如下优点或者有益效果:
[0037]
本发明的脑机接口的冷启动方法,通过对于基于迁移学习方法的小样本学习问题的研究,设计了特定的迁移学习网络模型,通过对于带有清晰的eeg特征模型的源域受试数据的学习,以迁移的方式来辅助模型对于eeg特征模式不清晰的目标域受试数据的学习,从而进一步提升模型的泛化能力,其适用性好,通过模型迁移和知识迁移的思想,将在源域受试数据集上训练的模型与学习到的知识迁移到目标域上,从而促使目标域模型仅使用少量的数据样本和少量的训练轮次就能高效的获得较优的性能表现,并实现基于自发eeg的bci系统冷启动,本发明为eeg跨受试迁移领域中受试差异和受试关联性的研究提供新的研究思路和研究基础,对于推动相关研究课题的发展有着较积极的影响,极具应用前景。
附图说明
[0038]
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明及其特征、外形和优点将会变得更加明显。在全部附图中相同的标记指示相同的部分。并未可以按照比例绘制附图,重点在于示出本发明的主旨。
[0039]
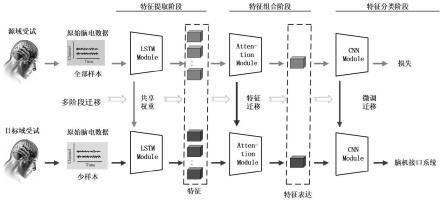
图1是本发明的脑机接口的冷启动方法的运行流程示意图。
具体实施方式
[0040]
下面结合附图和具体的实施例对本发明中的结构作进一步的说明,但是不作为本发明的限定。
[0041]
实施例1
[0042]
一种脑机接口的冷启动方法,利用脑机接口获取目标的脑电信号后,数据处理单元运行数据处理模型处理脑机接口所获取的目标的脑电信号,数据处理模型输出与脑电信号对应的信息,数据处理单元通过脑机接口与目标连接;
[0043]
数据处理模型为迁移学习网络模型,迁移学习网络模型包括顺序连接的用于特征
提取的lstm模块、用于特征匹配的注意力模块和用于特征分类的cnn模块,其数据处理过程如图1所示;
[0044]
lstm模块应用模型迁移方法,具体为:将lstm模块在源域受试数据集进行有监督的学习,将学习好的网络模块权重固定,并将预训练网络模型直接迁移到目标域受试数据集上;
[0045]
注意力模块应用特征迁移方法,具体为:将注意力模块在源域受试数据集进行有监督的学习,将网络模型在训练过程中得到的特征选取注意力参数,迁移到目标域受试模型的注意力模块中;
[0046]
cnn模块应用模型微调方法,具体为:将cnn模块在源域受试数据集进行有监督的学习,将学习好的网络模块权重记录,并迁移到目标域受试模型的cnn模块中,接下来基于目标域受试的少样本数据继续训练微调所迁移的网络权重;
[0047]
迁移学习网络模型的训练过程为以训练数据集中的脑电信号数据作为输入,以脑电信号数据对应的已知标签信息作为理论输出,不断调整迁移学习网络的参数的过程,训练的终止条件为模型在固定的训练轮次内,在评测数据集上的准确率不再提升。
[0048]
对比例1
[0049]
一种脑机接口的冷启动方法,其与实施例1基本相同,不同在于其数据处理模型为机器学习模型。
[0050]
分别应用实施例1和对比例1的方法完成脑机接口的冷启动,发现实施例1所需的训练数据仅为对比例1所需的训练数据的1/20,由此可见本发明的方法相比于传统方法大大减少了所需训练数据量。
[0051]
本发明通过设计合适的注意力机制,实现仅需要少量的单个目标域受试的样本,就可以进行对于源域受试样本特征的模式匹配,从而将网络框架应用于小样本学习问题。这样的小样本学习模型相较于当前最新的其他研究方法模型,需要更少的目标域受试的带标签样本。通过设计综合性的多阶段迁移学习网络框架,同时解决自发eeg领域的跨受试迁移和小样本学习问题,整个方法模型可以被应用于搭建高性能且具有很强的泛化能力和高可用性的bci系统。
[0052]
本领域技术人员应该理解,本领域技术人员在结合现有技术以及上述实施例可以实现变化例,在此不做赘述。这样的变化例并不影响本发明的实质内容,在此不予赘述。
[0053]
以上对本发明的较佳实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,其中未尽详细描述的设备和结构应该理解为用本领域中的普通方式予以实施;任何熟悉本领域的技术人员,在不脱离本发明技术方案范围情况下,都可利用上述揭示的方法和技术内容对本发明技术方案做出许多可能的变动和修饰,或修改为等同变化的等效实施例,这并不影响本发明的实质内容。因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所做的任何简单修改、等同变化及修饰,均仍属于本发明技术方案保护的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。