基于自注意力路由与transformer的多兴趣推荐方法
技术领域
1.本发明属于图像技术领域,涉及个性化推荐算法,具体涉及一种基于自注意力路由与transformer的多兴趣推荐方法。
背景技术:
2.随着信息技术的不断进步以及网民人数的逐渐增加,互联网所承载的信息量也在爆炸式增长,因而产生了严重的信息过载问题。信息过载使得信息消费者无法快速地从浩如烟海的信息中检索出真正需要的信息,而信息生产者也无法顺利地将其优秀的产品呈现在大众的视野中。为了缓解这一问题,学者们研发了具有划时代意义的个性化推荐系统。个性化推荐系统根据用户的基本信息、历史行为以及项目信息,分析用户的兴趣偏好,并将用户感兴趣的物品或信息推荐给用户,当用户兴趣发生改变时也可以及时对推荐项目做出调整。个性化推荐系统在节约用户时间成本、提升用户生活质量的同时,还有助于增加企业的收益,促进社会繁荣发展,对于个人和社会都具有重要的现实意义。
3.自图像领域提出图像分类网络alexnet之后,对于深度学习的研究层出不穷,推荐系统的研究思路也深受此影响。zhou等人提出了深度兴趣网络din,通过注意力机制使模型对行为向量加权,从而区别不同项目对于用户兴趣的重要性。然而用户的兴趣是动态变化的,仅仅捕捉用户的静态兴趣是不够的。zhou等人在din的基础上又提出了深度兴趣进化网络,该模型利用gru捕捉用户兴趣的动态变化,从而提取出更加准确的用户兴趣。虽然用户的评论等历史行为信息中包含了丰富的偏好特征,有助于减轻由于各物品的流行度不同带来的偏差,但并不是每一条历史行为信息都能起到这样的作用。dien能够挖掘深层次用户偏好信息,但推荐结果还是会受到待推荐物品流行度的影响。volkovs等人提出了一种使用双头注意力的自动编码器推荐模型,该模型能够有效结合用户评论、隐式反馈信息两个输入源,进而减缓物品流行度带来的推荐偏差。
4.随着社会的发展,用户的兴趣越来越广泛,单个向量的表达能力非常有限,无法准确表达用户多样化的兴趣特征。针对这一问题,李超等人提出了基于动态路由算法的多兴趣网络mind,mind利用动态路由算法和胶囊网络从用户的历史行为序列中抽取出多个兴趣向量来表示用户的不同兴趣,有效缓解单个向量无法准确表达用户兴趣的问题。然而动态路由算法并不完全适合于用户兴趣提取这一场景,且路由算法的迭代次数需要人为指定,如迭代次数设置不当有可能无法准确表征用户的兴趣。此外,mind模型中缺乏对于序列信息的专门提取,有可能导致序列信息不能被有效利用。
技术实现要素:
5.针对传统个性化推荐算法仅使用单个向量导致无法准确表达用户兴趣的技术问题,本发明的目的在于,提供一种基于自注意力路由与transformer的多兴趣推荐方法。
6.为了实现上述任务,本发明采用如下的技术解决方案:
7.一种基于自注意力路由与transformer的多兴趣推荐方法,其特征在于。具体包括
如下步骤:
8.步骤1,获取公开的用户历史行为序列,对其进行预处理,得到包含项目基本信息和行为发生时间的向量;
9.步骤2,通过embedding技术将项目向量以及对应的位置向量转化为固定维度的低维向量;
10.步骤3,使用transformer模型捕获各用户历史行为序列中的顺序依赖关系,根据经过embedding技术处理的项目向量和位置向量,得到含有更多有效信息的行为向量;
11.步骤4,从大量的行为向量中抽取出用户的多个兴趣向量;
12.步骤5,通过确定各兴趣向量与目标物品之间的关系,获得用户与目标物品交互的概率;
13.步骤6,通过最小化损失函数来学习模型的参数;
14.步骤7,通过计算相似度,利用用户的多个兴趣向量从待选物品池中检索出用户最有可能感兴趣的n个物品向其推荐。
15.具体地,步骤1中所述的历史行为序列,是根据用户以往产生过行为的项目id、类别、行为发生时间等信息构成;
16.所述预处理过程为:将所有历史行为数据按照发生时间的先后进行排列,然后将它们利用one-hot编码的方式转化为向量形式,包括项目向量和位置向量。其中,项目向量用于表示用户每一次点击、购买等行为所交互的项目,包含了项目的id、类别、金额等信息;位置向量用来表示该次行为在用户行为序列中的位置。
17.进一步地,步骤2中所述的embedding技术采用item2vec模型,该item2vec模型的输入可以是用户的购买记录、观影记录等各种序列,它能够将任何项目映射为相应的嵌入。
18.进一步地,所述步骤4使用改进后的自注意力路由算法结合胶囊网络将用户的行为向量自适应地聚类为多个兴趣向量,每个兴趣向量代表用户兴趣的一个方面。
19.进一步地,步骤5中所述获得用户与目标物品交互的概率使用sample softmax函数来计算。
20.进一步地,步骤6中所述的损失函数的表达式为:
[0021][0022]
式中,u代表用户集,i代表物品集,vu代表兴趣向量,ei表示目标项目的embedding向量。
[0023]
本发明的基于自注意力路由与transformer的多兴趣推荐方法,相较于现有技术,带来的技术创新在于:
[0024]
1、通过使用胶囊网络和自注意力路由算法,从用户的历史行为中抽取出用户的多个兴趣向量,避免了使用单个向量表示用户的多种兴趣导致的信息丢失,更能提升推荐结果的多样性和准确性。
[0025]
2、使用transformer模型挖掘用户行为间的序列关系,由于transformer模型在处理序列数据时具有天然优势,因此可以有效提升推荐系统的准确度。
附图说明
[0026]
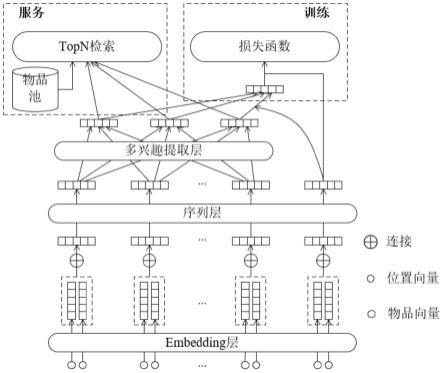
图1是本发明的基于自注意力路由与transformer的多兴趣推荐方法的模型图;
[0027]
图2是transformer模型编码器部分的结构图;
[0028]
图3是胶囊网络结构图;
[0029]
图4是自注意力路由算法结构图;
[0030]
以下结合附图和实施例对本发明作进一步解释说明。
具体实施方式
[0031]
参见图1,本实施例给出一种基于自注意力路由与transformer的多兴趣推荐方法,通过transformer挖掘用户历史行为记录中的序列关系,然后利用改进的自注意力路由算法和胶囊网络从行为向量中抽取出多个兴趣向量以表达用户的多个兴趣,进而实现多兴趣推荐,具体包括如下步骤:
[0032]
步骤1,获取公开的用户历史行为序列,对其进行预处理,得到包含项目基本信息和行为发生时间的向量;
[0033]
根据一般的数据处理方式,本实施例中的预处理过程为:将所有历史行为数据按照发生时间的先后进行排列,然后将它们利用one-hot编码的方式转化为向量形式,包括项目向量和位置向量。其中,项目向量用于表示用户每一次点击、购买等行为所交互的项目,包含了项目的id、类别、金额等信息;位置向量用来表示该次行为在用户行为序列中的位置。
[0034]
位置向量使用推荐时间和用户历史行为时间之差来计算,计算公式如下:
[0035][0036]
式中,代表算法为用户进行推荐的时间,代表用户行为vi的发生时间。
[0037]
步骤2,通过embedding技术将项目向量以及对应的位置向量转化为固定维度的低维向量,本发明使用item2vec模型进行embedding操作;
[0038]
设长度为k的历史行为序列为w1,w2,
…
,wk,则item2vec模型的优化目标为下式:
[0039][0040]
步骤3,捕获各历史行为之间的序列关系:
[0041]
本实施例使用transfomer模型的编码器部分捕获各用户历史行为序列中的顺序依赖关系,transfomer模型编码器的结构如图2所示,它的主要由多头自注意力层和前馈网络层构成。其具体流程如下:
[0042]
(1)多头自注意力层
[0043]
利用多头自注意力层将用户历史行为嵌入在多个子空间中分别进行缩放点积attention,然后将多次缩放点积attention获得的结果拼接,最后经过线性变换得到多头自注意力的结果。
[0044]
多头自注意力层的使用使得模型在多个不同的子空间中分别学习重要信息,增强了模型学习多方面内容的能力。具体计算公式如下:
[0045]
s=concat(head1,head2,...,headh)wh[0046]
headi=attention(ewq,ewk,ewv)
[0047]
其中,wq、wk、wv为权重矩阵,每个自注意力头都有一组对应的权重矩阵,它们是随机初始化的。e是由所有历史行为的行为嵌入和位置嵌入组成的矩阵,h表示多头自注意力的头数。
[0048]
多头自注意力层所使用的缩放点积attention的计算方法如下:
[0049][0050]
式中,q代表查询矩阵,k和v分别代表所有的键和值,为缩放点积注意力中的参数,它有助于减轻向量维度对注意力权重的影响。
[0051]
(2)前馈网络层
[0052]
为了增强模型的非线性表达能力,在多头自注意力层之后加入点式前馈神经网络。具体计算方法如下:
[0053]
f=ffn(s)
[0054]
式中,s代表多头自注意力层的计算结果,f代表前馈网络层的最终结果。
[0055]
模型在多头自注意力层和前馈网络层都使用了dropout技术。通过在神经网络的每个训练批次中以一定的几率将某些神经元暂时抛弃,可以有效防止过拟合现象、提高模型的泛化能力。下面是多头自注意力层和前馈网络层的最终输出的计算公式:
[0056]
s'=layernorm(s dropout(s))
[0057]
f=layernorm(s' dropout(leakyrelu(s'w
(1)
b
(1)
)w
(2)
b
(2)
))
[0058]
式中,w
(1)
和w
(2)
表示层间连线的权重,b
(1)
和b
(2)
代表各层的偏置。
[0059]
layernorm代表归一化操作,它可以增强特征分布的稳定性,加快模型收敛速度。leakyrelu激活函数对于输入小于零的情况也可以求得梯度,不会出现relu激活函数中输入小于0时输出也为0的情况。
[0060]
步骤4,从大量的行为向量中抽取出用户的多个兴趣向量:
[0061]
本实施例利用胶囊网络结合自注意力路由算法将用户的历史行为聚类为多个向量,每一个向量代表用户兴趣的某个方面。
[0062]
图3为胶囊网络模型,该模型由卷积层、初级胶囊层、高级胶囊层组成。胶囊网络由一系列的胶囊构成,每一个胶囊又由一组神经元组成。前两层仅作为高级胶囊层与输入图片交互的工具,由于本发明的输入数据是用户交互序列,因此仅使用高级胶囊层来构成胶囊网络。
[0063]
自注意力路由算法负责进行胶囊层之间的数据更新,算法整体结构如图4所示。
[0064]
该算法的输入向量为含有基本特征的初级胶囊,对于每一个初级胶囊,将其与权重矩阵相乘获得预测向量,以完成两个相邻胶囊层之间的仿射变换,预测向量的计算公式如下:
[0065][0066]
其中,v
l
即为输入矩阵,内含用户的历史行为记录信息。w
l
即l层的权重矩阵,它的
维度为(n
l
,n
l 1
,d
l
,d
l 1
),其中n
l
是第l层的胶囊个数,d
l
是l层胶囊的向量维度。
[0067]
通过对所有的预测向量进行加权求和获得胶囊网络的输出向量,计算公式如下:
[0068][0069]
上式中p
l
是对数先验矩阵,维度为(n
l
,n
l 1
),它所包含的权值与其他权值在同一时间进行有区别地学习,对与其他胶囊关联较多的胶囊给予一定的偏差,平衡全部胶囊的整体表现。c
l
是通过自注意力算法获得的耦合系数矩阵,维度为(n
l
,n
l 1
),它负责将各个低层次胶囊按照一定比重分配给它们所属实体对应的胶囊,这也是自注意力路由算法最重要的功能。
[0070]cl
的计算公式如下:
[0071][0072]
其中,a
l
为注意力矩阵,它用于计算l层各预测向量的注意力得分以便获得胶囊网络的输出,注意力矩阵采用缩放点积注意力进行计算,计算公式如下:
[0073][0074]
其中,有助于模型应对注意力分数很大的情况,同时还可以平衡对数先验矩阵和耦合系数矩阵的表现。
[0075]
自注意力路由算法输出向量的模长并不一定小于1,导致无法表示胶囊所代表的对象存在的概率。因此本实施例引入压缩函数来压缩输出向量的模长,使其位于[0,1]区间内,具体计算公式如下:
[0076][0077]
该压缩函数只会压缩向量的长度,使得短向量的长度接近于0,长向量的长度接近于1,不会改变向量的方向,使得压缩后的多个输出向量可以表示用户的兴趣。
[0078]
步骤5,通过确定各兴趣向量与目标物品之间的关系,获得用户与目标物品交互的概率;
[0079]
获得多个兴趣向量后,对于当前的目标项目,执行argmax操作从用户的所有兴趣向量中找出与目标项目最相关的兴趣向量,计算公式如下:
[0080][0081]
其中,ei表示目标项目的嵌入,它由序列信息层计算得出。vu是兴趣矩阵,由用户的所有兴趣向量组成。
[0082]
步骤6,通过最小化损失函数来学习模型的参数:
[0083]
对于用户向量vu与目标项目ei,应该最大化用户u与该目标项目发生交互的概率,出于计算成本的考虑,使用sample softmax函数来计算用户与目标项目交互的概率,通过最小化下面的目标函数训练提出的模型:
[0084][0085]
式中,u代表用户集,i代表物品集,vu代表兴趣向量,ei表示目标项目的embedding向量。
[0086]
步骤7,通过计算相似度,利用用户的多个兴趣向量从待选物品池中检索出用户最有可能感兴趣的n个物品向其推荐;
[0087]
对于步骤4抽取出的每一个兴趣向量,通过最近邻方法可以从候选项目库中检索出z个该兴趣的相似项目。若是抽取出m个兴趣,那么一共可以检索出m
×
z个候选项目。本实施例的目标是为用户进行topn推荐,即从候选项目库中选出用户最有可能交互的n个项目进行推荐,因此从m
×
z个项目中找出与用户兴趣相似度最高的前n个项目作为最终的推荐列表。
[0088]
以上所述仅为本发明较佳的具体实施例,但本发明不限于上述实施例。任何熟悉本技术领域的技术人员在本发明揭露的技术方案的前提下,对本发明的技术方案加以技术特征的增加或等同替换,都应属于本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
