一种基于transformer神经网络的图像分类方法
技术领域
1.本发明涉及图像分类技术领域,尤其涉及一种基于transformer神经网络的图像分类方法。
背景技术:
2.在传统的卷积神经网络算法中,由于其实际的感受野远小于理论上的感受野,导致网络在进行检测时不能获得整张图片的全局视野,所以在对图像的类别进行识别时存在一定程度的偏差,而transformer神经网络在对图像进行检测时,可以获得图像的全局视野,并且拥有更强的捕获长远距离特征的能力,因此,能够更好地对图像进行分类。其次,在某些场景下的图像分类需要较高的实时性,而在以往的注意力机制中需要对特征图做全局的自注意力计算,由此带来了庞大的计算量。
3.刘冰等人在《一种基于深度transformer的高光谱影像分类方法》中使用了基于全局进行自注意力计算的transformer神经网络,相较于传统的卷积神经网络,其提高了模型的特征表达能力,但同时带来了庞大的计算量,没有很好的提升模型的预测速度。
技术实现要素:
4.针对现有算法的不足,本发明解决传统的卷积神经网络在对图像进行分类时精度不够高;现有的多头注意力机制计算量大的问题。
5.本发明所采用的技术方案是:一种基于transformer神经网络的图像分类方法包括以下步骤:
6.s1、预训练:利用大型数据集对transformer神经网络进行预训练,从中提取出共性特征,减轻模型对特定任务学习的负担,使模型获得可以表达浅层且广泛特征的能力。
7.s2、微调:使用自制的数据集对transformer神经网络进行微调,使得经过预训练的模型的参数能够适应对特定的任务进行分类,从而使模型获得表达深层且具体特征的能力;
8.s3、图像分块:对采集的图像分块处理;
9.进一步的,将一张宽高为h
×
w的rgb三通道图片,切分为每个小块的宽高为4
×
4,得到块数为然后将每个小块展平,并在通道维度上进行拼接,每个小块变成形状为1
×1×
48的张量,整张图片经过分块操作后变成一个形状为的张量;
10.s4、线性变换:将张量在通道维度上对每个像素做线性变换,并对变换后的张量在通道维度上进行layernorm操作;
11.进一步的,首先,在通道维度上对每个像素做线性变换进一步的,首先,在通道维度上对每个像素做线性变换以适应transformer神经网络的输入;
12.其次,对变换后的张量在通道维度上进行layernorm操作,如式1所示:
[0013][0014]
其中,e(x)和var(x)分别为每一层输入元素的均值和方差;∈为指定的一个极小数值,γ和β为每个像素点的权重和偏置;
[0015]
s5、特征提取:将处理好的图像送入训练好的transformer神经网络进行特征提取;
[0016]
进一步的,首先,通过transforme神经网络对图片进行多次特征提取,并将得到的含有丰富目标信息的特征图用作检测源;
[0017]
三维数据经过多次下采样和多次注意力计算,变成维度为的数据;
[0018]
transformer神经网络捕获特征是基于自注意力机制对每个像素的相关性做计算,获得整张图片的全局视野,自注意力机制的实现原理如式2所示:
[0019][0020]
其中,q(query)、k(key)、v(value)为来自同一输入的三个可学习的矩阵,dk为一个query和key向量的维度,softmax(
·
)为归一化函数;
[0021]
进一步的,使用滑动窗口多头注意力机制,在对特征图做划分操作时,进行一定程度的偏移,在对图片进行特征提取的过程中,交替使用窗口注意力和滑动窗口多头注意力;
[0022]
进一步的,交替使用窗口注意力和滑动窗口多头注意力包括:
[0023]
由上一层所得到的输出x
l-1
,经过layernorm操作;然后基于窗口多头注意力机制计算各个像素点之间的相关性得到x
l
,并在x
l-1
和x
l
之间加入残差连接,随后经过下一个ln归一化层;再将输出送入多层感知机;多层感知机由一个全连接层、gelu激活函数和dropout层组成;最后,将输出x
l
送入下一个含有滑动窗口多头注意力机制模块;
[0024]
s6、检测:对s5步骤中所提取得到的最终特征进行检测,并将图片分类到得分最高的类;
[0025]
本发明的有益效果:
[0026]
1、基于transformer架构所构建的神经网络,解决了传统的卷积神经存在感受野受限以及不能很好的捕获长远距离特征的问题;
[0027]
2、原版的多头注意力机制是基于全局进行自注意力的计算,需要消耗庞大的计算资源,本发明将基于全局的自注意力计算改为基于窗口的自注意力计算,通过交替使用窗口多头注意力和滑动窗口多头注意力机制,降低了计算量,从而提高了神经网络的训练和预测速度。
附图说明
[0028]
图1是本发明基于transformer神经网络的图像分类方法的流程图;
[0029]
图2是本发明的transformer神经网络结构图;
[0030]
图3是本发明的注意力机制模块;
[0031]
图4是本发明的检测模块的结构图;
[0032]
图5是本发明的改进的多头注意力机制做切分操作时的示意图。
具体实施方式
[0033]
下面结合附图和实施例对本发明作进一步说明,此图为简化的示意图,仅以示意方式说明本发明的基本结构,因此其仅显示与本发明有关的构成。
[0034]
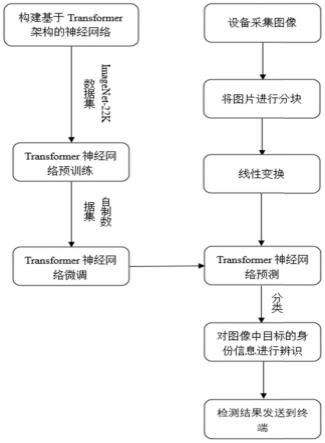
如图1所示,一种基于transformer神经网络的图像分类方法包括以下步骤:
[0035]
s1、预训练:利用大型数据集对transformer神经网络进行预训练,从中提取出尽可能多的共性特征,从而减轻模型对特定任务学习的负担,使模型获得可以表达浅层且广泛特征的能力;
[0036]
本实施例imagenet-22k数据集,包含2.2万个不同的类别、共计约1500万张图片。
[0037]
s2、微调:针对特定的分类任务,使用自制的数据集对transformer神经网络进行微调,使得经过预训练的模型的参数能够适应对特定的任务进行分类,从而使模型获得表达深层且具体特征的能力;
[0038]
本实施例cifar-100数据集,包含100个类别,每个类别有600张32
×
32的彩色图片;
[0039]
s3、图像分块:采集的图像做分块处理;
[0040]
将一张宽高为h
×
w的rgb三通道图片,切分为每个小块,每一块的宽高为4
×
4,则所得到的块数为然后将每个小块展平,并在通道维度上进行拼接,每个小块变成形状为1
×1×
48的张量,整张图片经过分块操作后变成一个形状为的张量,本实施例中图像的尺寸为384
×
384
×
3。
[0041]
s4、线性变换:将经过s3步骤处理后所得的张量,在通道维度上对每个像素做线性变换,并对变换后的张量在通道维度上进行layernorm操作;
[0042]
首先,在通道维度上对每个像素做线性变换以适应transformer神经网络的输入;
[0043]
其次,对变换后的张量在通道维度上进行layernorm操作,如式1所示:
[0044][0045]
其中,e(x)和var(x)分别为每一层输入元素的均值和方差;∈为指定的一个极小数值,其作用是为了避免分母为0的情况出现;γ和β为每个像素点的权重和偏置,用于仿射变换,本实施例中∈的值为0.00001。
[0046]
s5、特征提取:将经过s4步骤处理好的图像送入训练好的transformer神经网络进行特征提取;
[0047]
transformer神经网络将会对图片进行多次特征提取,并将最后所得到的含有丰富目标信息的特征图用作检测源,如图2为transformer神经网络的整体结构,每次经过下
采样后,输入图像数据的分辨率会减半,通道数加倍;三维数据经过多次注意力计算以及下采样后,变成维度为的数据。
[0048]
transformer神经网络捕获特征是基于自注意力机制对每个像素的相关性做计算,从而获得整张图片的全局视野;自注意力机制的实现原理如式2所示:
[0049][0050]
其中,q(query)、k(key)、v(value)为来自同一输入的三个可学习的矩阵,dk为一个query和key向量的维度,softmax(
·
)为归一化函数。
[0051]
在本发明中,针对图片输入数据,使用了基于自注意力机制为扩展的窗口多头注意力机制,将每一个阶段所提取得到的特征图划分成多个窗口,在每个窗口内进行自注意力机制的计算,相比于原本的基于全局的自注意力机制的计算量减少了约五分之三;但也带来各个窗口之间的信息无法进行交互的问题,导致网络的感受野减小。
[0052]
故本发明使用了滑动窗口多头注意力机制,在对特征图做划分操作时,进行一定程度的偏移,扩大了感受野的范围,在对图片进行特征提取的过程中,交替使用这两种注意力机制,不仅减少了计算量,同时也提升了网络的预测精度。
[0053]
如图3为图2中注意力机制模块的具体构造,由上一层所得到的输出x
l-1
,首先经过layernorm操作,以保证数据特征分布的稳定性;然后基于窗口多头注意力机制计算各个像素点之间的相关性得到x
l
,并在x
l-1
和x
l
之间加入残差连接;随后经过下一个ln归一化层;再将输出送入多层感知机,该结构由一个全连接层、gelu激活函数和dropout层组成;最后,将输出x
l
送入下一个含有滑动窗口多头注意力机制的类似模块;
[0054]
s6、检测:对s5步骤中所提取得到的最终特征进行检测,并将图片分类到得分最高的那一类;
[0055]
如图4为检测模块的结构图,首先经过layernorm层,加快模型的收敛速度;再经过平均池化层,计算图像区域的平均值作为该区域池化后的值;然后经过一个全连接层,将学到的“特征表示”映射到样本标记空间,即对目标图像进行分类,最后通过输出层输出分类结果。
[0056]
将本发明所提出的transformer神经网络和传统的卷积神经网络进行对比,验证基于transformer架构所构建的神经网络在图像分类任务上的有效性;
[0057]
本实施例采用cifar-100数据集,包含100个类别,每个类别有600张分辨率为32
×
32的彩色图像,以及分为5万张训练集图像和1万张测试集图像,学习率(learning rate)设置为0.001,批量尺寸(batch size)设为64,epoch数量设置为30,每一个epoch迭代一遍训练集;训练精确率的对比结果如表1所示:
[0058]
表1图像分类任务精确率比较
[0059]
[0060]
从表1中可以看出本发明所构建的transformer神经网络结构的准确率均优于另外的两种卷积神经网络,说明了本发明算法的优越性和有效性,更具有应用价值。
[0061]
如图5所示,本发明的改进的多头注意力机制做切分操作时的示意图;其中,黑色线条所构成的方块图为特征图,橘红色的线条为切分线条,窗口多头注意力中将会按照左图橘红色线条的布局进行切分,将一张特征图分成九个等大的小窗口,然后在每个窗口内做局部的自注意力计算,虽减少了计算量,但同时带来了各个窗口之间无法进行信息交互的问题,导致网络的感受野减少。
[0062]
故在每个使用了窗口多头注意力的模块之后跟随一个使用了滑动窗口多头注意力的模块,如图5中的右图所示,滑动窗口多头注意力在对特征图进行划分时,进行了一定程度的偏移,划分后的窗口大小不一,然后在九个窗口内分别做自注意力计算;
[0063]
表2三种多头注意力机制对比
[0064][0065]
从表2可以明显的看到,窗口多头注意力和滑动窗口多头注意力的计算量均大幅度小于多头注意力的计算量,虽然窗口多头注意力和滑动窗口多头注意力单独使用均不能获得图像的全局视野,但在本发明中,将这两种注意力交替使用在网络结构中,使得网络可以获得整张图像的全局视野,在减少计算量的同时又不降低网络的学习和表达能力。
[0066]
以上述依据本发明的理想实施例为启示,通过上述的说明内容,相关工作人员完全可以在不偏离本项发明技术思想的范围内,进行多样的变更以及修改。本项发明的技术性范围并不局限于说明书上的内容,必须要根据权利要求范围来确定其技术性范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。