1.本公开通常涉及图像编译技术,并且更具体地,涉及一种图像编译系统中基于变换的图像编译方法及其设备。
背景技术:
2.近来在各种领域中对诸如超高清(hud)图像和4k或8k或更大视频这样的高分辨率且高质量的图像和视频的需求日益增加。随着图像和视频数据变成高分辨率和高质量,与现有图像和视频数据相比,相对发送的信息量或位数增加。因此,如果使用诸如现有有线或无线宽带线这样的介质来传输图像数据或者使用现有存储介质来存储图像和视频数据,则传输成本和存储成本增加。
3.此外,近来对诸如虚拟现实(vr)、人工现实(ar)内容或全息图这样的沉浸式媒体的兴趣和需求日益增加。诸如游戏图像这样的图像特性与真实图像的图像特性不同的图像和视频的广播日益增加。
4.因此,为了有效地压缩并传输或存储并回放具有这样的各种特性的高分辨率且高质量的图像和视频的信息,需要高效的图像和视频压缩技术。
技术实现要素:
5.技术问题
6.本公开的技术方面是为了提供一种用于提高图像编译效率的方法和设备。
7.本公开的另一技术方面是为了提供一种用于提高残差编译效率的方法和设备。
8.本公开的另一技术方面是提供一种用于增加对lfnst索引进行编译的效率的方法和设备。
9.本公开的又一个技术方面是提供一种用于通过对lfnst索引进行编译来增加对双树色度块的次级变换的效率的方法和设备。
10.技术方案
11.根据本公开的实施例,提供了一种由解码设备执行的图像解码方法。该方法可以包括:通过将lfnst应用于变换系数来导出修改的变换系数;基于修改的变换系数的逆初级变换导出目标块的残差样本;以及基于残差样本生成重构图片,其中,修改的变换系数的导出可以包括:基于当前块的树类型为双树色度解析lfnst索引;以及基于lfnst索引和lfnst矩阵导出修改的变换系数。
12.在当前块的树类型为双树色度时,无论mip模式是否被应用于当前块,都可以解析lfnst索引。
13.在当前块的树类型为双树色度时,无论与当前块对应的lfnst应用宽度和lfnst应用高度是否为16或更大,都可以解析lfnst索引。
14.在当前块的树类型不是双树色度时,可以基于mip模式未被应用于当前块来解析lfnst索引。
15.在当前块的树类型不是双树色度并且mip模式被应用于当前块时,可以基于与当前块对应的lfnst应用宽度和lfnst应用高度为16或更大来解析lfnst索引。
16.在当前块被垂直分割时lfnst应用宽度可以设置为当前块的宽度除以分割的子分区的数量,并且在当前块没有被分割时lfnst应用宽度可以设置为当前块的宽度,并且当前块可以是编译块。
17.在当前块被水平分割时lfnst应用高度可以设置为当前块的高度除以分割的子分区的数量,并且在当前块没有被分割时lfnst应用高度可以设置为当前块的高度,并且当前块可以是编译块。
18.根据本公开的实施例,提供了一种由编码设备执行的图像编码方法。该方法可以包括:通过应用lfnst从变换系数导出修改的变换系数;以及对量化的残差信息和指示应用于lfnst的lfnst矩阵的lfnst索引进行编码,其中可以基于当前块的树类型为双树色度来对lfnst索引进行编码。
19.根据本公开的又一实施例,可以提供一种存储图像数据的数字存储介质,该图像数据包括编码的图像信息和根据由编码设备执行的图像编码方法生成的比特流。
20.根据本公开的又一实施例,可以提供一种数字存储介质,其存储包括编码的图像信息和比特流的图像数据,以使解码设备执行图像解码方法。
21.有益效果
22.根据本公开,能够增加整体图像/视频压缩效率。
23.根据本公开,能够增加对lfnst索引进行编译的效率。
24.根据本公开,能够通过对lfnst索引进行编译来增加对双树色度块的次级变换的效率。
25.能够通过本公开的特定示例获得的效果不限于上面列举的效果。例如,可以存在相关领域的普通技术人员能够理解或从本公开中导出的各种技术效果。因此,本公开的特定效果不限于在本公开中显式地描述的效果,并且可以包括能够从本公开的技术特征理解或导出的各种效果。
附图说明
26.图1示意性地图示本公开适用于的视频/图像编译系统的示例。
27.图2是示意性地图示本公开适用于的视频/图像编码设备的配置的图。
28.图3是示意性地图示本公开适用于的视频/图像解码设备的配置的图。
29.图4图示应用本公开的内容流传输系统的结构。
30.图5示意性地图示根据本公开的实施例的多重变换技术。
31.图6示例性地示出65个预测方向的帧内方向模式。
32.图7是用于解释根据本公开的实施例的rst的图。
33.图8是图示根据示例的将正向初级变换的输出数据排列成一维向量的顺序的图。
34.图9是图示根据示例的将正向次级变换的输出数据排列成二维块的顺序的图。
35.图10是图示根据本文档的实施例的广角帧内预测模式的图。
36.图11是图示应用lfnst的块形状的图。
37.图12是图示根据示例的正向lfnst的输出数据的排列的图。
38.图13图示根据示例的在应用了4
×
4lfnst的块中的清零。
39.图14图示根据示例的在应用了8
×
8lfnst的块中的清零。
40.图15是图示根据本公开的实施例的视频解码设备的操作的流程图。
41.图16是图示根据本公开的实施例的视频编码设备的操作的流程图。
具体实施方式
42.该文件能够以各种方式修改并且可以具有各种实施例,并且特定的实施例将在附图中图示并详细地描述。然而,这并不旨在将该文件限制于特定实施例。本说明书中通常使用的术语用于描述特定的实施例,而不是用来限制该文件的技术精神。除非在上下文中另外明确表示,否则单数的表述包括复数的表述。该说明书中的诸如“包括”或“具有”这样的术语应该被理解为指示存在本说明书中描述的特性、数字、步骤、操作、元件、组件或其组合,而没有排除存在或添加一个或更多个特性、数字、步骤、操作、元件、组件或其组合的可能性。
43.此外,为了便于与不同特征功能相关的描述,独立地图示了该文件中描述的附图中的元件。这并不意指各个元件被实现为单独的硬件或单独的软件。例如,至少两个元件可以被组合,以形成单个元件,或者单个元件可以被划分成多个元件。其中元件被组合和/或分开的实施例也被包括在该文件的权利范围内,除非它偏离了该文件的实质。
44.下文中,参考附图更具体地描述该文件的优选实施例。下文中,在附图中,相同的附图标记被用于相同的元件,并且可以省略对相同元件的冗余描述。
45.本文件涉及视频/图像编译。例如,本文件中公开的方法/示例可能涉及vvc(versatile video coding,通用视频编译)标准(itu-t建议书h.266)、vvc之后的下一代视频/图像编译标准、或其他视频编译相关标准(例如,hevc(high efficiency video coding,高效视频编译)标准(itu-t建议书h.265)、evc(essential video coding,基本视频编译)标准、avs2标准等)。
46.在本文件中,可以提供与视频/图像编译有关的各种实施例,并且,除非相反地指定,否则实施例可以被彼此组合并执行。
47.在本文件中,视频可以意指随时间推移的一系列图像的集合。通常,图片意指表示特定时间区域的图像的单元,并且切片/图块(tile)是构成图片的一部分的单元。切片/图块可以包括一个或更多个编译树单元(ctu)。一个图片可以由一个或更多个切片/图块构成。一个图片可以由一个或更多个图块组构成。一个图块组可以包括一个或更多个图块。
48.像素或像元(pel)可以意指构成一个图片(或图像)的最小单元。另外,“样本”可以被用作与像素对应的术语。样本通常可以表示像素或像素的值,并且可以仅表示亮度分量的像素/像素值,或仅表示色度分量的像素/像素值。
49.单元可以表示图像处理的基本单元。单元可以包括特定区域和与该区域相关的信息中的至少一个。一个单元可以包括一个亮度块和两个色度(例如,cb、cr)块。根据情况,可以将单元和诸如块、区域等这样的术语互换地使用。在通常情况下,mxn块可以包括由m列和n行组成的样本(或样本阵列)或变换系数的集合(或阵列)。
50.在本文件中,术语“/”和“,”应该被解释为指示“和/或”。例如,表述“a/b”可以意指“a和/或b”。另外,“a、b”可以意指“a和/或b”。另外,“a/b/c”可以意指“a、b和/或c中的至少
一个”。另外,“a/b/c”可以意指“a、b和/或c中的至少一个”。
51.另外,在该文件中,术语“或”应该被解释为指示“和/或”。例如,表述“a或b”可以包括1)“仅a”、2)“仅b”和/或3)“a和b”二者。换句话说,本文件中的术语“或”应该被解释为指示“另外地或可替选地”。
52.在本公开中,“a和b中的至少一个”可以意指“仅a”、“仅b”、或“a和b二者”。另外,在本公开中,表述“a或b中的至少一个”或“a和/或b中的至少一个”可以被解释为“a和b中的至少一个”。
53.另外,在本公开中,“a、b和c中的至少一个”可以意指“仅a”、“仅b”、“仅c”、或“a、b和c的任何组合”。另外,“a、b或c中的至少一个”或“a、b和/或c中的至少一个”可以意指“a、b和c中的至少一个”。
54.另外,本公开中使用的括号可以意指“例如”。具体地,当被指示为“预测(帧内预测)”时,这可能意味着将“帧内预测”作为“预测”的示例提出。也就是说,本公开中的“预测”不限于“帧内预测”,并且可以将“帧内预测”作为“预测”的示例提出。另外,当被指示为“预测(即,帧内预测)”时,这也可能意味着将“帧内预测”作为“预测”的示例提出。
55.在本公开中的一个附图中单独地描述的技术特征可以被单独地实现或者可以被同时地实现。
56.图1示意性地图示了可以应用该文件的实施例的视频/图像编码系统的示例。
57.参考图1,视频/图像编码系统可以包括第一装置(源装置)和第二装置(接收装置)。源装置可以经由数字存储介质或网络以文件或流传输的形式将编码后的视频/图像信息或数据传递到接收装置。
58.源装置可以包括视频源、编码装置和发送器。接收装置可以包括接收器、解码装置和渲染器。编码装置可以被称为视频/图像编码装置,并且解码装置可以被称为视频/图像解码装置。发送器可以被包括在编码装置中。接收器可以被包括在解码装置中。渲染器可以包括显示器,并且显示器可以被配置为单独的装置或外部组件。
59.视频源可以通过捕获、合成或生成视频/图像的处理来获得视频/图像。视频源可以包括视频/图像捕获装置和/或视频/图像生成装置。视频/图像捕获装置可以包括例如一个或更多个相机、包括先前捕获的视频/图像的视频/图像档案等。视频/图像生成装置可以包括例如计算机、平板计算机和智能电话,并且可以(电子地)生成视频/图像。例如,可以通过计算机等生成虚拟视频/图像。在这种情况下,视频/图像捕获处理可以被生成相关数据的处理取代。
60.编码装置可以对输入视频/图像进行编码。编码装置可以执行诸如针对压缩和编译效率的预测、变换和量化这样的一系列过程。编码后的数据(编码后的视频/图像信息)能够以比特流的形式输出。
61.发送器可以通过数字存储介质或网络以文件或流传输的形式将以比特流的形式输出的编码后的视频/图像信息或数据发送到接收装置的接收器。数字存储介质可以包括诸如usb、sd、cd、dvd、蓝光、hdd、ssd等这样的各种存储介质。发送器可以包括用于通过预定文件格式生成媒体文件的元件,并且可以包括用于通过广播/通信网络进行发送的元件。接收器可以接收/提取比特流,并且将接收/提取的比特流发送到解码装置。
62.解码装置可以通过执行与编码装置的操作对应的诸如解量化、逆变换、预测等这
样的一系列过程来解码视频/图像。
63.渲染器可以渲染解码后的视频/图像。可以通过显示器显示渲染后的视频/图像。
64.图2是示意性地描述可以应用本文件的视频/图像编码装置的配置的图。下文中,所谓的视频编码装置可以包括图像编码装置。
65.参考图2,编码装置200可以包括图像分区器210、预测器220、残差处理器230、熵编码器240、加法器250、滤波器260和存储器270。预测器220可以包括帧间预测器221和帧内预测器222。残差处理器230可以包括变换器232、量化器233、解量化器234、逆变换器235。残差处理器230还可以包括减法器231。加法器250可以被称为重构器或重构块生成器。根据实施例,上面已描述的图像分区器210、预测器220、残差处理器230、熵编码器240、加法器250和滤波器260可以由一个或更多个硬件组件(例如,编码器芯片组或处理器)构成。另外,存储器270可以包括解码图片缓冲器(dpb),并且可以由数字存储介质构成。硬件组件还可以包括存储器270作为内部/外部组件。
66.图像分区器210将输入到编码装置200的输入图像(或图片或帧)分区成一个或更多个处理单元。作为一个示例,处理单元可以被称为编译单元(cu)。在这种情况下,从编译树单元(ctu)或最大编译单元(lcu)开始,可以根据四叉树二叉树三叉树(qtbttt)结构来递归地分区编译单元。例如,可以基于四叉树结构、二叉树结构和/或三叉树结构将一个编译单元划分成深度更深的多个编译单元。在这种情况下,例如,可以首先应用四叉树结构,随后可以应用二叉树结构和/或三叉树结构。可替选地,可以首先应用二叉树结构。可以基于没有被进一步分区的最终编译单元来执行根据本文件的编译过程。在这种情况下,基于根据图像特性的编译效率,可以将最大编译单元直接用作最终编译单元。可替选地,可以按需要将编译单元递归地分区成深度进一步更深的编译单元,使得可以将最佳大小的编译单元用作最终编译单元。这里,编译过程可以包括随后将描述的诸如预测、变换和重构这样的过程。作为另一示例,处理单元还可以包括预测单元(pu)或变换单元(tu)。在这种情况下,可以从上述的最终编译单元划分或分割预测单元和变换单元。预测单元可以是样本预测的单元,并且变换单元可以是用于导出变换系数的单元和/或用于根据变换系数导出残差信号的单元。
67.根据情况,可以将单元和诸如块、区域等这样的术语互换地使用。在常规情况下,mxn块可以表示由m列和n行组成的样本或变换系数的集合。样本通常可以表示像素或像素的值,并且可以仅表示亮度分量的像素/像素值,或仅表示色度分量的像素/像素值。样本可以被用作与一个图片(或图像)的像素或pel对应的术语。
68.减法器231从输入图像信号(原始块、原始样本或原始样本阵列)中减去从预测器220输出的预测信号(预测块、预测样本或预测样本阵列)以生成残差信号(残差块、残差样本或残差样本阵列),并且所生成的残差信号被发送到变换器232。预测器220可以对处理目标块(在下文中,称为“当前块”)执行预测,并且可以生成包括当前块的预测样本的预测块。预测器220可以在当前块或cu基础上确定是应用帧内预测还是帧间预测。如稍后在每种预测模式的描述中讨论的,预测器可以生成与预测有关的各种信息,诸如预测模式信息,并且将所生成的信息发送到熵编码器240。关于预测的信息可以在熵编码器240中被编码并且以比特流的形式输出。
69.帧内预测器222可以通过参考当前图片中的样本来预测当前块。根据预测模式,参
考样本可以位于当前块的附近或与当前块分开。在帧内预测中,预测模式可以包括多种非定向模式和多种定向模式。非定向模式可以包括例如dc模式和平面模式。根据预测方向的详细程度,定向模式可以包括例如33种定向预测模式或65种定向预测模式。然而,这仅仅是示例,并且根据设置,可以使用更多或更少的定向预测模式。帧内预测器222可以通过使用应用于邻近块的预测模式来确定应用于当前块的预测模式。
70.帧间预测器221可以基于参考图片上的运动向量所指定的参考块(参考样本阵列)来导出针对当前块的预测块。此时,为了减少在帧间预测模式下发送的运动信息的量,可以基于邻近块与当前块之间的运动信息的相关性以块、子块或样本为基础来预测运动信息。运动信息可以包括运动向量和参考图片索引。运动信息还可以包括帧间预测方向(l0预测、l1预测、bi预测等)信息。在帧间预测的情况下,邻近块可以包括当前图片中存在的空间邻近块和参考图片中存在的时间邻近块。包括参考块的参考图片和包括时间邻近块的参考图片可以彼此相同或彼此不同。时间邻近块可以被称为并置参考块、并置cu(colcu)等,并且包括时间邻近块的参考图片可以被称为并置图片(colpic)。例如,帧间预测器221可以基于邻近块来配置运动信息候选列表,并且生成指示哪个候选被用于导出当前块的运动向量和/或参考图片索引的信息。可以基于各种预测模式来执行帧间预测。例如,在跳过模式和合并模式的情况下,帧间预测器221可以使用邻近块的运动信息作为当前块的运动信息。在跳过模式下,与合并模式不同,不能发送残差信号。在运动信息预测(运动向量预测、mvp)模式的情况下,邻近块的运动向量可以被用作运动向量预测项,并且可以通过用信号发送运动向量差来指示当前块的运动向量。
71.预测器220可以基于各种预测方法来生成预测信号。例如,预测器可以应用帧内预测或帧间预测以便对一个块进行预测,并且也可以同时应用帧内预测和帧间预测。这可以被称为组合帧间和帧内预测(ciip)。此外,预测器可以基于帧内块复制(ibc)预测模式或调色板模式以便对块执行预测。ibc预测模式或调色板模式可以被用于游戏等的内容图像/视频编码,诸如屏幕内容编码(scc)。尽管ibc基本上在当前块中执行预测,但是在当前块中导出参考块的方面能够类似于帧间预测执行。也就是说,ibc可以使用本公开中描述的帧间预测技术中的至少一种。
72.通过帧间预测器221和/或帧内预测器222生成的预测信号可以用于生成重构信号或者生成残差信号。变换器232可以通过对残差信号应用变换技术来生成变换系数。例如,变换技术可以包括离散余弦变换(dct)、离散正弦变换(dst)、基于图的变换(gbt)或条件非线性变换(cnt)等。这里,gbt意指当通过图来表示像素之间的关系信息时从图获得的变换。cnt是指基于使用所有先前重构的像素生成的预测信号而获得的变换。另外,变换过程可以被应用于具有相同大小的正方形像素块或者可以被应用于具有可变大小的块而不是正方形块。
73.量化器233可以对变换系数进行量化并且将它们发送到熵编码器240,并且熵编码器240可以对量化的信号(关于量化的变换系数的信息)进行编码并且在比特流中输出编码的信号。关于量化的变换系数的信息可以被称为残差信息。量化器233可以基于系数扫描顺序将块型量化的变换系数重新布置成一维向量形式,并且基于一维向量形式的量化的变换系数来生成关于量化的变换系数的信息。熵编码器240可以执行各种编码方法,诸如例如指数哥伦布(exponential golomb)、上下文自适应可变长度编码(cavlc)、上下文自适应二进
制算术编码(cabac)等。熵编码器240可以对除量化的变换系数(例如,语法元素的值等)以外的视频/图像重构所必需的信息一起或分别进行编码。编码的信息(例如,编码的视频/图像信息)可以被以比特流的形式在网络抽象层(nal)的单元基础上发送或存储。视频/图像信息还可以包括关于各种参数集的信息,诸如自适应参数集(aps)、图片参数集(pps)、序列参数集(sps)、视频参数集(vps)等。此外,视频/图像信息还可以包括一般约束信息。在本公开中,从编码装置发送/用信号发送给解码装置的信息和/或语法元素可以被包括在视频/图像信息中。视频/图像信息可以通过上述编码过程来编码并且被包括在比特流中。比特流可以通过网络来发送,或者被存储在数字存储介质中。这里,网络可以包括广播网络、通信网络和/或类似物,而数字存储介质可以包括诸如usb、sd、cd、dvd、蓝光、hdd、ssd等这样的各种存储介质。发送从熵编码器240输出的信号的发送器(未示出)和/或存储它的存储装置(未示出)可以被配置为编码装置200的内部/外部元件,或者发送器可以被包括在熵编码器240。
74.从量化器233输出的量化变换系数可以用于生成预测信号。例如,通过经由解量化器234和逆变换器235对量化的变换系数应用解量化和逆变换,可以重构残差信号(残差块或残差样本)。加法器250将重构残差信号加到从预测器220输出的预测信号,使得可以生成重构信号(重构图像、重构块、重构样本或重构样本阵列)。当如在应用跳过模式的情况下一样处理目标块没有残差时,可以将预测块用作重构块。所生成的重构信号可以被用于当前块中的下一处理目标块的帧内预测,并且如稍后描述的,可以通过滤波被用于下一图片的帧间预测。
75.同时,在图片编码和/或重构过程中,可以应用亮度映射与色度缩放(lmcs)。
76.滤波器260可以通过对重构信号应用滤波来改善主观/客观视频质量。例如,滤波器260可以通过对重构图片应用各种滤波方法来生成修改的重构图片,并且可以将修改的重构图片存储在存储器270中,具体地在存储器270的dpb中。各种滤波方法可以包括例如去块滤波、样本自适应偏移、自适应环路滤波、双边滤波等。如稍后在每种滤波方法的描述中讨论的,滤波器260可以生成与滤波有关的各种信息,并且将所生成的信息发送到熵编码器290。关于滤波的信息可以在熵编码器290中被编码并且以比特流的形式输出。
77.已被发送到存储器270的修改后的重构图片可以被用作帧间预测器280中的参考图片。通过这个,编码装置能够在应用帧间预测时避免编码装置200和解码装置中的预测失配,并且也能够改善编译效率。
78.存储器270dpb可以存储修改的重构图片以便将它用作帧间预测器221中的参考图片。存储器270可以存储已从中导出运动信息(或对其进行编码)的当前图片中的块的运动信息、和/或已经重构的图片中的块的运动信息。可以将所存储的运动信息发送到帧间预测器221以被用作邻近块的运动信息或时间邻近块的运动信息。存储器270可以存储当前图片中的重构块的重构样本,并且将它们发送到帧内预测器222。
79.图3是示意性地描述可以应用本文件的视频/图像解码装置的配置的图。
80.参考图3,视频解码装置300可以包括熵解码器310、残差处理器320、预测器330、加法器340、滤波器350和存储器360。预测器330可以包括帧间预测器331和帧内预测器332。残差处理器320可以包括解量化器321和逆变换器321。根据实施例,上面已描述的熵解码器310、残差处理器320、预测器330、加法器340和滤波器350可以由一个或更多个硬件组件(例
如,解码器芯片组或处理器)构成。另外,存储器360可以包括解码图片缓冲器(dpb),并且可以由数字存储介质构成。硬件组件还可以包括存储器360作为内部/外部组件。
81.当输入包括视频/图像信息的比特流时,解码装置300可以与据此已在图2的编码装置中处理视频/图像信息的处理对应地重构图像。例如,解码装置300可以基于与从比特流获得的与块分割相关的信息来导出单元/块。解码装置300可以通过使用在编码装置中应用的处理单元来执行解码。因此,解码的处理单元可以是例如编译单元,可以用编译树单元或最大编译单元顺着四叉树结构、二叉树结构和/或三叉树结构对其进行分割。可以用编译单元导出一个或更多个变换单元。并且,可以通过再现器来再现通过解码装置300解码并输出的重构图像信号。
82.解码装置300能够以比特流的形式接收从图2的编码装置输出的信号,并且可以通过熵解码器310对所接收到的信号进行解码。例如,熵解码器310可以解析比特流以导出图像重构(或图片重构)所需要的信息(例如,视频/图像信息)。视频/图像信息还可以包括关于诸如自适应参数集(aps)、图片参数集(pps)、序列参数集(sps)、视频参数集(vps)等这样的各种参数集的信息。此外,视频/图像信息还可以包括一般约束信息。解码装置可以进一步基于关于参数集的信息和/或一般约束信息来对图片进行解码。在本公开中,将稍后描述的用信号发送/接收的信息和/或语法元素可以通过解码过程被解码并且是从比特流获得的。例如,熵解码器310可以基于诸如指数哥伦布编码、cavlc、cabac等这样的编码方法来对比特流中的信息进行解码,并且可以输出图像重构所必需的语法元素的值和有关残差的变换系数的量化值。更具体地,cabac熵解码方法可以接收与比特流中的每个语法元素对应的bin,使用邻近和解码目标块的解码目标语法元素信息和解码信息或在前一个步骤中解码的符号/bin的信息来确定上下文模型,根据所确定的上下文模型来预测bin生成概率并且对bin执行算术解码以生成与每个语法元素值对应的符号。这里,cabac熵解码方法可以在确定上下文模型之后使用针对下一符号/bin的上下文模型解码的符号/bin的信息来更新上下文模型。在熵解码器310中解码的信息之中关于预测的信息可以被提供给预测器330,并且已在熵解码器310中对其执行了熵解码的关于残差的信息即量化的变换系数以及关联的参数信息可以被输入到解量化器321。此外,在熵解码器310中解码的信息之中关于滤波的信息可以被提供给滤波器350。同时,接收到从编码装置输出的信号的接收器(未示出)可以进一步将解码装置300构成为内部/外部元件,并且接收器可以是熵解码器310的组件。同时,根据本公开的解码装置可以被称为视频/图像/图片编码装置,并且解码装置可以被分类成信息解码器(视频/图像/图片信息解码器)和样本解码器(视频/图像/图片样本解码器)。信息解码器可以包括熵解码器310,而样本解码器可以包括解量化器321、逆变换器322、预测器330、加法器340、滤波器350以及存储器360中的至少一个。
83.解量化器321可以通过对量化后的变换系数进行解量化来输出变换系数。解量化器321可以将量化后的变换系数重新布置为二维块的形式。在这种情况下,可以基于已在编码装置中执行的系数扫描的顺序来执行重新布置。解量化器321可以使用量化参数(例如,量化步长信息)对量化后的变换系数执行解量化,并且获得变换系数。
84.逆变换器322通过对变换系数进行逆变换来获得残差信号(残差块、残差样本阵列)。
85.预测器可以对当前块执行预测,并且生成包括针对当前块的预测样本的预测块。
预测器可以基于从熵解码器310输出的关于预测的信息来确定向当前块应用帧内预测还是帧间预测,并且具体地可以确定帧内/帧间预测模式。
86.预测器可以基于各种预测方法来生成预测信号。例如,预测器可以应用帧内预测或帧间预测以便对一个块进行预测,并且也可以同时应用帧内预测和帧间预测。这可以被称为组合帧间和帧内预测(ciip)。另外,预测器可以执行帧内块复制(ibc)以便对块进行预测。帧内块复制可以被用于游戏等的内容图像/视频编译,诸如屏幕内容编译(scc)。尽管ibc基本上在当前块中执行预测,但是在当前块中导出参考块的方面能够类似于帧间预测执行。也就是说,ibc可以使用本公开中描述的帧间预测技术中的至少一种。
87.帧内预测器331可以通过参考当前图片中的样本来预测当前块。根据预测模式,所参考的样本可以位于当前块的邻居中或者远离当前块。在帧内预测中,预测模式可以包括多种非定向模式和多种定向模式。帧内预测器331可以通过使用应用于邻近块的预测模式来确定应用于当前块的预测模式。
88.帧间预测器332可以基于由参考图片上的运动向量指定的参考块(参考样本阵列)来导出当前块的预测块。此时,为了减少在帧间预测模式下发送的运动信息量,可以基于邻近块与当前块之间的运动信息的相关性在块、子块或样本基础上预测运动信息。运动信息可以包括运动向量和参考图片索引。运动信息还可以包括帧间预测方向(l0预测、l1预测、bi预测等)信息。在帧间预测的情况下,邻近块可以包括存在于当前图片中的空间邻近块和存在于参考图片中的时间邻近块。例如,帧间预测器332可以基于邻近块来配置运动信息候选列表,并且基于接收到的候选选择信息来导出当前块的运动向量和/或参考图片索引。可以基于各种预测模式来执行帧间预测,并且关于预测的信息可以包括指示用于当前块的帧间预测模式的信息。
89.加法器340可以通过将所获得的残差信号加到从预测器330输出的预测信号(预测块、预测样本阵列)来生成重构信号(重构图片、重构块、重构样本阵列)。当如在应用跳过模式的情况下一样处理目标块没有残差时,可以将预测块用作重构块。
90.加法器340可以被称为重构器或重构块生成器。所生成的重构信号可以用于当前图片中的要处理的下一块的帧内预测,可以通过如下所述的滤波而输出,或者可以用于下一图片的帧间预测。
91.此外,亮度映射与色度缩放(lmcs)可以被应用于图片解码处理。
92.滤波器350可以通过向重构后的信号应用滤波来改善主观/客观图像质量。例如,滤波器350可以通过向重构图片应用各种滤波方法来生成修改后的重构图片,并且将修改后的重构图片存储在存储器360中,具体地,存储在存储器360的dpb中。各种滤波方法可以包括例如去块滤波处理、样本自适应偏移、自适应环路滤波、双边滤波等。
93.已被存储在存储器360的dpb中的(修改后的)重构图片可以被用作帧间预测器332中的参考图片。存储器360可以存储已从中导出运动信息(或对其进行解码)的当前图片中的块的运动信息,和/或已经重构的图片中的块的运动信息。可以将所存储的运动信息发送到帧间预测器260以被用作邻近块的运动信息或时间邻近块的运动信息。存储器360可以存储当前图片中的重构块的重构样本,并且将它们发送到帧内预测器331。
94.在本说明书中,在解码装置300的预测器330、解量化器321、逆变换器322和滤波器350中描述的示例分别可以被类似地或相应地应用于编码装置200的预测器220、解量化器
234、逆变换器235和滤波器260。
95.如上所述,在执行视频编译时,执行预测以提高压缩效率。可以通过预测生成包括当前块的预测样本的预测块,即,目标编译块。在这种情况下,预测块包括空间域(或像素域)中的预测样本。在编码装置和解码装置中同样地导出预测块。编码装置可以通过向解码装置用信号发送关于原始块而非原始块的原始样本值本身与预测块之间的残差的信息(残差信息)来提高图像编译效率。解码装置可以基于残差信息来导出包括残差样本的残差块,可以通过将残差块与预测块相加来生成包括重构样本的重构块,并且可以生成包括重构块的重构图片。
96.可以通过变换和量化过程来生成残差信息。例如,编码装置可以导出原始块与预测块之间的残差块,可以通过对残差块中所包括的残差样本(残差样本阵列)执行变换过程来导出变换系数,可以通过对变换系数执行量化过程来导出量化变换系数,并且可以(通过比特流)向解码装置用信号发送相关残差信息。在这种情况下,残差信息可以包括诸如值信息、位置信息、变换方案、变换核以及量化变换系数的量化参数这样的信息。解码装置可以基于残差信息执行反量化/逆变换过程,并且可以导出残差样本(或残差块)。解码装置可以基于预测块和残差块来生成重构图片。此外,编码装置可以通过对量化后的变换系数进行反量化/逆变换来导出残差块以供后续图片的帧间预测参考,并且可以生成重构图片。
97.图4图示了应用本公开的内容流传输系统的结构。
98.此外,应用本公开的内容流传输系统可以主要包括编码服务器、流传输服务器、网络服务器、媒体存储装置、用户设备和多媒体输入装置。
99.编码服务器将从诸如智能电话、相机、摄像机等这样的多媒体输入装置输入的内容压缩成数字数据以生成比特流,并且将该比特流传输到流传输服务器。作为另一示例,当诸如智能电话、相机、摄像机等这样的多媒体输入装置直接生成比特流时,可以省略编码服务器。可以通过应用本文件的实施例的编码方法或比特流生成方法来生成比特流。并且流传输服务器可以在发送或接收比特流的处理中临时存储比特流。
100.流传输服务器基于用户的请求通过网络服务器将多媒体数据发送到用户装置,并且网络服务器用作将服务告知用户的介质。当用户向网络服务器请求所期望的服务时,网络服务器将其传送到流传输服务器,流传输服务器将多媒体数据发送到用户。在这种情况下,内容流传输系统可以包括单独的控制服务器。在这种情况下,控制服务器用于控制内容流传输系统中的装置之间的命令/响应。
101.流传输服务器可以从媒体存储器和/或编码服务器接收内容。例如,当从编码服务器接收内容时,可以实时地接收内容。在这种情况下,为了提供平稳的流传输服务,流传输服务器可以存储比特流达预定时间。
102.例如,用户设备可以包括移动电话、智能电话、膝上型计算机、数字广播终端、个人数字助理(pda)、便携式多媒体播放器(pmp)、导航、板式pc、平板pc、超极本、可穿戴装置(例如,手表型终端(智能手表)、眼镜型终端(智能眼镜)、头戴式显示器(hmd))、数字tv、台式计算机、数字标牌等。内容流传输系统中的服务器中的每一个可以作为分布式服务器被操作,并且在这种情况下,可以以分布式方式处理由每个服务器接收到的数据。
103.图5示意性地图示了根据本公开的实施例的多变换技术。
104.参考图5,变换器可以对应于上述图2的编码装置中的变换器,并且逆变换器可以
对应于上述图2的编码装置中的逆变换器,或者对应于图3的解码装置中的逆变换器。
105.变换器可以通过基于残差块中的残差样本(残差样本阵列)执行初级变换来导出(初级)变换系数(s510)。该初级变换可以被称为核心变换。在本文中,初级变换可以基于多变换选择(mts),并且当多变换被应用为初级变换时,它可以被称为多核心变换。
106.多核心变换可以表示附加地使用离散余弦变换(dct)类型2和离散正弦变换(dst)类型7、dct类型8和/或dst类型1来变换的方法。也就是说,多核心变换可以表示基于从dct类型2、dst类型7、dct类型8和dst类型1之中选择的多个变换核来将空间域的残差信号(或残差块)变换成频域的变换系数(或初级变换系数)的变换方法。在本文中,从变换器的观点可以将初级变换系数称为时间变换系数。
107.也就是说,当应用常规的变换方法时,可以通过基于dct类型2对残差信号(或残差块)应用从空间域到频域的变换来生成变换系数。然而,当应用多核心变换时,可以通过基于dct类型2、dst类型7、dct类型8和/或dst类型1对残差信号(或残差块)应用从空间域到频域的变换来生成变换系数(或初级变换系数)。这里,dct类型2、dst类型7、dct类型8和dst类型1可以被称为变换类型、变换核(kernel)或变换核心(core)。可以基于基函数来定义这些dct/dst类型。
108.如果执行多核心变换,则可以从变换核之中选择用于目标块的垂直变换核和水平变换核,可以基于垂直变换核来对目标块执行垂直变换,并且可以基于水平变换核来对目标块执行水平变换。这里,水平变换可以表示针对目标块的水平分量的变换,而垂直变换可以表示针对目标块的垂直分量的变换。可以基于包括残差块的目标块(cu或子块)的预测模式和/或变换索引来自适应地确定垂直变换核/水平变换核。
109.此外,根据一个示例,如果通过应用mts来执行初级变换,则可以通过将特定基函数设置为预定值并且组合要在垂直变换或水平变换中应用的基函数来设置变换核的映射关系。例如,当将水平变换核表达为trtypehor并且将垂直方向变换核表达为trtypever时,可以将trtypehor或trtypever值0设置为dct2,可以将trtypehor或trtypever的值1设置为dst一7,以及可以将trtypehor或trtypever的值2设置为dct-8。
110.在这种情况下,mts索引信息可以被编码并用信号发送给解码装置以指示多个变换核集中的任何一个。例如,mts索引0可以指示trtypehor和trtypever值都为0,mts索引1可以指示trtypehor和trtypever值都为1,mts索引2可以指示trtypehor值为2而trtypever值为1,mts索引3可以指示trtypehor值为1而trtypever值为2,以及mts索引4可以指示trtypehor和trtypever值都为2。
111.在一个示例中,根据mts索引信息的变换核集被图示在下表中。
112.[表1]
[0113]
tu_mts_idx[x0][y0]01234trtypehor01212trtypever01122
[0114]
变换器可以通过基于(初级)变换系数执行次级变换来导出修改的(次级)变换系数(s520)。初级变换是从空间域到频域的变换,而次级变换是指通过使用(初级)变换系数之间存在的相关性以更压缩的表达来进行变换。次级变换可以包括不可分离变换。在这种情况下,次级变换可以被称为不可分离次级变换(nsst)或模式相关不可分离次级变换
(mdnsst)。不可分离次级变换可以表示通过基于不可分离变换矩阵对通过初级变换导出的(初级)变换系数进行次级变换来为残差信号生成修改的变换系数(或次级变换系数)。此时,可以不对(初级)变换系数单独地应用垂直变换和水平变换(或者可能不独立地应用水平变换和垂直变换),而是可以基于不可分离变换矩阵一次性应用变换。换句话说,不可分离次级变换可以表示一种变换方法,在这样的变换方法中不针对(初级)变换系数的垂直方向和水平方向分开地应用,并且例如,二维信号(变换系数)通过某个确定的方向(例如,行优先方向或列优先方向)被重新布置为一维信号,然后基于不可分离变换矩阵来生成修改的变换系数(或次级变换系数)。例如,根据行优先顺序,m
×
n个块以第一行、第二行、
…
和第n行的顺序设置成一行。根据列优先顺序,m
×
n个块以第一列、第二列、
…
和第n列的顺序设置成一行。不可分离次级变换可以被应用于配置有(初级)变换系数的块(在下文中,可以被称为变换系数块)的左上区域。例如,如果变换系数块的宽度(w)和高度(h)全部等于或大于8,则可以对变换系数块的左上8
×
8区域应用8
×
8不可分离次级变换。此外,如果变换系数块的宽度(w)和高度(h)全部等于或大于4,并且变换系数块的宽度(w)或高度(h)小于8,则可以对变换系数块的左上min(8,w)
×
min(8,h)区域应用4
×
4不可分离次级变换。然而,该实施例不限于此,并且例如,即使满足仅变换系数块的宽度(w)或高度(h)等于或大于4的条件,也可以将4
×
4不可分离次级变换应用于变换系数块的左上min(8,w)
×
min(8,h)区域。
[0115]
具体地,例如,如果使用4
×
4输入块,则不可分离的次级变换可以如下执行。
[0116]4×
4输入块x可以表示如下。
[0117]
[式1]
[0118][0119]
如果x以向量的形式表示,则向量可以如下表示。
[0120]
[式2]
[0121][0122]
在式2中,向量是通过根据行优先顺序重新排列式1的二维块x而获得的一维向量。
[0123]
在这种情况下,可以如下计算不可分离的次级变换。
[0124]
[式3]
[0125][0126]
在此式中,表示变换系数向量,而t表示16
×
16(不可分离的)变换矩阵。
[0127]
通过前述式3,可以导出16
×
1变换系数向量并且可以通过扫描顺序(水平、垂直和对角线等)将向量重新组织为4
×
4块。然而,上述计算是示例,并且超立方体-吉文斯变换(hypercube-givens transform,hygt)等也可以用于不可分离的次级变换的计算,以
便降低不可分离的次级变换的计算复杂度。
[0128]
此外,在不可分离的次级变换中,可以将变换核(或变换核心、变换类型)选择为模式相关。在这种情况下,模式可以包括帧内预测模式和/或帧间预测模式。
[0129]
如上所述,可以基于以变换系数块的宽度(w)和高度(h)为基础确定的8
×
8变换或4
×
4变换来执行不可分离的次级变换。8
×
8变换是指当w和h二者都等于或大于8时可应用于变换系数块中包含的8
×
8区域的变换,并且8
×
8区域可以是变换系数块中的左上8
×
8区域。类似地,4
×
4变换是指当w和h二者都等于或大于4时可应用于变换系数块中包含的4
×
4区域的变换,并且4
×
4区域可以是变换系数块中的左上4
×
4区域。例如,8
×
8变换核矩阵可以是64
×
64/16
×
64矩阵,而4
×
4变换核矩阵可以是16
×
16/8
×
16矩阵。
[0130]
这里,为了选择模式相关的变换核,可以针对8
×
8变换和4
×
4变换二者配置用于不可分离的次级变换的、每变换集两个不可分离的次级变换核,并且可以存在四个变换集。也就是说,可以针对8
×
8变换配置四个变换集,并且可以针对4
×
4变换配置四个变换集。在这种情况下,针对8
×
8变换的四个变换集中的每个变换集可以包括二个8
×
8变换核,并且针对4
×
4变换的四个变换集中的每个变换集可以包括二个4
×
4变换核。
[0131]
然而,随着变换的大小(即,变换所应用于的区域的大小)可以为例如除了8
×
8或4
×
4之外的大小,集合的数量可以是n,并且每个集合中的变换核的数量可以是k。
[0132]
变换集可以被称为nsst集或lfnst集。可以例如基于当前块(cu或子块)的帧内预测模式来选择变换集之中的特定集。低频不可分离的变换(lfnst)可以是缩减不可分离的变换的示例,其将稍后描述,并且表示用于低频分量的不可分离的变换。
[0133]
作为参考,例如,帧内预测模式可以包括两个非定向(或非角度)帧内预测模式和65个定向(或角度)帧内预测模式。非定向帧内预测模式可以包括0号的平面帧内预测模式和1号的dc帧内预测模式,并且定向帧内预测模式可以包括2号至66号的65个帧内预测模式。然而,这是示例,并且即使帧内预测模式的数量不同也可以应用本文档。此外,在一些情况下,还可以使用67号帧内预测模式,并且67号帧内预测模式可以表示线性模型(lm)模式。
[0134]
图6示意性地示出了65个预测方向的帧内定向模式。
[0135]
参考图6,基于具有左上对角预测方向的帧内预测模式34,帧内预测模式可以划分为具有水平方向性的帧内预测模式和具有垂直方向性的帧内预测模式。在图6中,h和v分别表示水平方向性和垂直方向性,并且数字-32至32指示样本网格位置上的1/32单位的位移。这些数字可以表示对于模式索引值的偏移。帧内预测模式2至33具有水平方向性,并且帧内预测模式34至66具有垂直方向性。严格地说,帧内预测模式34可以被视为既不是水平的也不是垂直的,但在确定次级变换的变换集时可以被分类为属于水平方向性。这是因为输入数据被转置以用于基于帧内预测模式34对称的垂直定向模式,并且针对水平模式的输入数据对准方法用于帧内预测模式34。对输入数据进行转置意指将二维的m
×
n块数据的行和列切换成n
×
m数据。帧内预测模式18和帧内预测模式50可以分别表示水平帧内预测模式和垂直帧内预测模式,并且帧内预测模式2可以被称为右上对角帧内预测模式,因为帧内预测模式2具有左参考像素并且在右上方向中执行预测。类似地,帧内预测模式34可以被称为右下对角帧内预测模式,而帧内预测模式66可以被称为左下对角帧内预测模式。
[0136]
根据示例,可以映射根据帧内预测模式的四个变换集,例如,如下表所示。
[0137]
[表2]
[0138]
predmodeintralfnsttrsetidxpredmodeintra<010<=predmodeintra<=102<=predmodeintra<=12113<=predmodeintra<=23224<=predmodeintra<=44345<=predmodeintra<=55256<=predmodeintra<=801
[0139]
如表2所示,根据帧内预测模式,四个变换集中的任何一个,即,lfnsttrsetidx,可以映射到四个索引(即,0至3)中的任何一个。
[0140]
当确定特定集用于不可分离的变换时,可以通过不可分离的次级变换索引来选择特定集中的k个变换核之一。编码设备可以基于率失真(rd)校验来导出指示特定变换核的不可分离的次级变换索引,并且可以将不可分离的次级变换索引用信号发送给解码设备。解码设备可以基于不可分离的次级变换索引来选择特定集中的k个变换核中的一个。例如,lfnst索引值0可以指代第一不可分离的次级变换核,lfnst索引值1可以指代第二不可分离的次级变换核,lfnst索引值2可以指代第三不可分离的次级变换核。另选地,lfnst索引值0可以指示第一不可分离的次级变换没有被应用于目标块,并且lfnst索引值1至3可以指示三个变换核。
[0141]
变换器可以基于所选择的变换核来执行不可分离的次级变换,并且可以获得修改的(次级)变换系数。如上所述,修改的变换系数可以被导出为通过量化器量化的变换系数,并且可以被编码并用信号发送给解码设备,并且被传送到编码设备中的解量化器/逆变换器。
[0142]
此外,如上所述,如果省略了次级变换,则可以将作为初级(可分离的)变换的输出的(初级)变换系数导出为如上所述通过量化器量化的变换系数,并且可以被编码并用信号发送给解码设备,并传送到编码设备中的解量化器/逆变换器。
[0143]
逆变换器可以与在上述变换器中已经执行的顺序相反的顺序执行一系列过程。逆变换器可以接收(解量化的)变换系数,并且通过执行次级(逆)变换来导出(初级)变换系数(s550),并且可以通过对(初级)变换系数执行初级(逆)变换来获得残差块(残差样本)(s560)。就此而言,从逆变换器的视角来看,初级变换系数可以被称为修改的变换系数。如上所述,编码设备和解码设备可以基于残差块和预测块来生成重构块,并且可以基于重构块来生成重构图片。
[0144]
解码设备可以进一步包括次级逆变换应用确定器(或用于确定是否应用次级逆变换的元件)和次级逆变换确定器(或用于确定次级逆变换的元件)。次级逆变换应用确定器可以确定是否应用次级逆变换。例如,次级逆变换可以是nsst、rst或lfnst,并且次级逆变换应用确定器可以基于通过解析比特流而获得的次级变换标志来确定是否应用次级逆变换。在另一示例中,次级逆变换应用确定器可以基于残差块的变换系数来确定是否应用次级逆变换。
[0145]
次级逆变换确定器可以确定次级逆变换。在这种情况下,次级逆变换确定器可以基于根据帧内预测模式指定的lfnst(nsst或rst)变换集来确定应用于当前块的次级逆变
换。在实施例中,可以取决于初级变换确定方法来确定次级变换确定方法。可以根据帧内预测模式来确定初级变换和次级变换的各种组合。此外,在示例中,次级逆变换确定器可以基于当前块的大小来确定应用次级逆变换的区域。
[0146]
此外,如上所述,如果省略次级(逆)变换,则可以接收(解量化的)变换系数,可以执行初级(可分离的)逆变换,并且可以获得残差块(残差样本)。如上所述,编码设备和解码设备可以基于残差块和预测块来生成重构块,并且可以基于重构块来生成重构图片。
[0147]
此外,在本公开中,可以在nsst的概念中应用其中减小了变换矩阵(核)的大小的缩减次级变换(rst),以便减少不可分离的次级变换所需的计算量和存储量。
[0148]
此外,本公开中描述的变换核、变换矩阵以及构成变换核矩阵的系数,即,核系数或矩阵系数,能够以8比特来表示。这可以是在解码设备和编码设备中实现的条件,并且与现有的9比特或10比特相比,可以减少存储变换核所需的存储量,并且可以合理地适应性能劣化。另外,以8比特表示核矩阵可以允许使用小的乘法器,并且可以更适合于用于最佳软件实现的单指令多数据(simd)指令。
[0149]
在本说明书中,术语“rst”可以是指基于大小根据缩减因子而减小的变换矩阵来对目标块的残差样本执行的变换。在执行缩减变换的情况下,由于变换矩阵的大小的减小,可以减少变换所需的计算量。也就是说,rst可以用于解决在大小大的块的变换或不可分离的变换时发生的计算复杂性问题。
[0150]
rst可以被称为诸如缩减变换、缩减次级变换、缩小变换、简化变换和简单变换等之类的各种术语,并且rst可以被称为的名称不限于所列示例。另选地,由于rst主要在变换块中的包括非零系数的低频区域中执行,因此它可以被称为低频不可分离的变换(lfnst)。变换索引可以被称作lfnst索引。
[0151]
同时,当基于rst执行次级逆变换时,编码设备200的逆变换器235和解码设备300的逆变换器322可以包括基于变换系数的逆rst导出修改的变换系数的逆缩减次级变换器,以及基于对修改的变换系数的逆初级变换导出用于目标块的残差样本的逆初级变换器。逆初级变换是指应用于残差的初级变换的逆变换。在本公开中,基于变换导出变换系数可以是指通过应用变换来导出变换系数。
[0152]
图7是图示根据本公开的实施例的rst的图。
[0153]
在本公开中,“目标块”可以指代要编码的当前块,残差块或变换块。
[0154]
在根据示例的rst中,可以将n维向量映射到位于另一个空间中的r维向量,使得可以确定缩减变换矩阵,其中r小于n。n可以是指应用了变换的块的侧边的长度的平方,或与应用了变换的块相对应的变换系数的总数,并且缩减因子可以是指r/n值。缩减因子可以被称为缩减因子、缩小因子、简化因子、简单因子或其他各种术语。此外,r可以被称为缩减系数,但是根据情况,缩减因子可以是指r。此外,根据情况,缩减因子可以是指n/r值。
[0155]
在示例中,可以通过比特流来用信号发送缩减因子或缩减系数,但是示例不限于此。例如,可以在编码设备200和解码设备300中的每个中存储针对缩减因子或缩减系数的预定义值,并且在这种情况下,可以不单独用信号发送缩减因子或缩减系数。
[0156]
根据示例的缩减变换矩阵的大小可以是小于n
×
n(常规变换矩阵的大小)的r
×
n,并且可以如下面的式4所限定。
[0157]
[式4]
[0158][0159]
图7(a)中所示的缩减变换块中的矩阵t可以是指式4的矩阵tr×n。如图7(a)所示,当将缩减变换矩阵tr×n乘以用于目标块的残差样本时,可以导出用于当前块的变换系数。
[0160]
在示例中,如果应用了变换的块的大小是8
×
8并且r=16(即,r/n=16/64=1/4),则根据图7(a)的rst可以被表示为以下式5所示的矩阵运算。在这种情况下,存储和乘法计算可以通过缩减因子缩减至大约1/4。
[0161]
在本公开中,矩阵运算可以理解为通过将列向量与设置在列向量的左侧的矩阵相乘来获得列向量的运算。
[0162]
[式5]
[0163][0164]
在式5中,r1至r
64
可以表示用于目标块的残差样本,并且具体地可以是通过应用初级变换而生成的变换系数。作为式5的计算的结果,可以导出目标块的变换系数ci,并且导出ci的过程可以如式6所示。
[0165]
[式6]
[0166][0167]
作为式6的计算的结果,可以导出目标块的变换系数c1至cr。也就是说,当r=16时,可以导出目标块的变换系数c1至c
16
。如果应用常规变换而不是rst,并将64
×
64(n
×
n)大小的变换矩阵与64
×
1(n
×
1)大小的残差样本相乘,则尽管针对目标块导出了64(n)个变换系数,但因为应用了rst因此针对目标块仅导出16(r)个变换系数。由于用于目标块的变换系数的总数从n缩减到r,所以编码设备200向解码设备300发送的数据量减少,因此编码设备200与解码设备300之间的传输效率可以提高。
[0168]
当从变换矩阵的大小的视角考虑时,常规变换矩阵的大小为64
×
64(n
×
n),但缩减变换矩阵的大小缩减为16
×
64(r
×
n),因此与执行常规变换的情况相比,执行rst的情况下的存储使用率可以减小r/n比率。另外,当与使用常规变换矩阵的情况下的乘法计算的数量n
×
n相比时,使用缩减变换矩阵可以将乘法计算的数量(r
×
n)减小r/n比率。
[0169]
在示例中,编码设备200的变换器232可以通过对用于目标块的残差样本执行初级变换和基于rst的次级变换来导出用于目标块的变换系数。可以将这些变换系数传递到解
码设备300的逆变换器,并且解码设备300的逆变换器322可以基于针对变换系数的逆缩减次级变换(rst)来导出修改的变换系数,并且可以基于针对修改的变换系数的逆初级变换来导出用于目标块的残差样本。
[0170]
根据示例的逆rst矩阵tn×r的大小是小于常规逆变换矩阵n
×
n的大小的n
×
r,并且与式4中所示的缩减变换矩阵tr×n具有转置关系。
[0171]
图7(b)所示的缩减逆变换块中的矩阵t
t
可以是指逆rst矩阵tn×
rt
(上标t是指转置)。如图7(b)所示,当将逆rst矩阵t
rxnt
乘以目标块的变换系数时,可以导出目标块的修改的变换系数或目标块的残差样本。逆rst矩阵t
rxnt
可以表示为(t
rxnt
)
nxr
。
[0172]
更具体地,当逆rst被用作次级逆变换时,当逆rst矩阵t
rxnt
被乘以目标块的变换系数时,可以导出目标块的修改的变换系数。此外,可以将逆rst用作逆初级变换,并且在这种情况下,当将逆rst矩阵t
rxnt
与目标块的变换系数相乘时,可以导出目标块的残差样本。
[0173]
在示例中,如果应用逆变换的块的大小是8
×
8并且r=16(即,r/n=16/64=1/4),则根据图7(b)的rst可以被表示为以下式7所示的矩阵运算。
[0174]
[式7]
[0175][0176]
在式7中,c1至c
16
可以表示目标块的变换系数。作为式7的计算的结果,可以导出表示目标块的修改的变换系数或目标块的残差样本的ri,并且导出ri的过程可以如式8所示。
[0177]
[式8]
[0178]
对于从1到n的i
[0179]ri=0[0180]
对于从1到r的j
[0181]ri
=t
ji
*cj[0182]
作为式8的计算的结果,可以导出表示目标块的修改的变换系数或目标块的残差样本的r1至rn。从逆变换矩阵的大小的视角考虑,常规逆变换矩阵的大小为64
×
64(n
×
n),但逆缩减变换矩阵的大小缩减为64
×
16(r
×
n),因此与执行常规逆变换的情况相比,执行逆rst的情况下的存储使用率可以减小r/n比率。另外,当与使用常规逆变换矩阵的情况下的乘法计算的数量n
×
n相比时,使用逆缩减变换矩阵可以将乘法计算的数量(n
×
r)减少r/n比率。
[0183]
表2所示的变换集配置也可以应用于8
×
8rst。也就是说,可以根据表2中的变换集来应用8
×
8rst。由于根据帧内预测模式,一个变换集包括两个或三个变换(核),因此可以配置为选择包括在不应用次级变换的情况下在内的至多四个变换中的一个。在不应用次级变换的变换中,可以考虑应用恒等矩阵(identity matrix)。假设分别将索引0、1、2和3分配给四个变换(例如,可以将索引0分配给应用恒等矩阵的情况,即,不应用次级变换的情况),可以针对每个变换系数块用信号发送作为语法元素的变换索引或lfnst索引,由此指定要
应用的变换。也就是说,针对左上8
×
8块,通过变换索引,可以指定rst配置中的8
×
8nsst,或者当应用lfnst时可以指定8
×
8lfnst。8
×
8lfnst和8
×
8rst指代当要变换的目标块的w和h均等于或大于8时可应用于变换系数块中包括的8
×
8区域的变换,并且8
×
8区域可以是变换系数块中的左上8
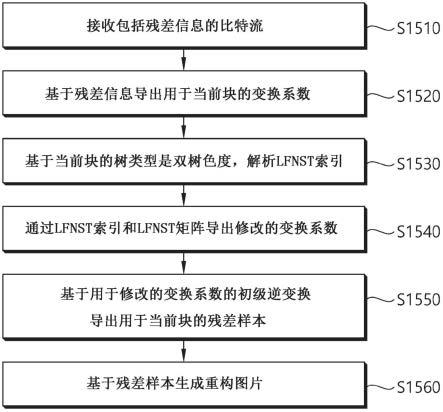
×
8区域。类似地,4
×
4lfnst和4
×
4rst指代当目标块的w和h均等于或大于4时可应用于变换系数块中包括的4
×
4区域的变换,并且4
×
4区域可以是变换系数块中的左上4
×
4区域。
[0184]
根据本公开的实施例,对于编码过程中的变换,可以仅选择48条数据,并且可以向其应用最大16
×
48变换核矩阵,而不是将16
×
64变换核矩阵应用于形成8
×
8区域的64条数据。此处,“最大”意味着m在m
×
48变换核矩阵中具有最大值16以用于生成m个系数。也就是说,当通过将m
×
48变换核矩阵(m≤16)应用于8
×
8区域来执行rst时,48条数据被输入,并且生成m个系数。当m是16时,48条数据被输入并且生成16个系数。也就是说,假设48条数据形成48
×
1向量,16
×
48矩阵和48
×
1向量依次相乘,由此生成16
×
1向量。这里,形成8
×
8区域的48条数据可以被适当地排列,由此形成48
×
1向量。例如,可以基于构成8
×
8区域之中的除了右下4
×
4区域之外的区域的48条数据来构造48
×
1向量。这里,当通过应用最大16
×
48变换核矩阵来执行矩阵运算时,生成16个修改的变换系数,并且可以根据扫描顺序将16个修改的变换系数排列在左上4
×
4区域中,并且可以用零填充右上4
×
4区域和左下4
×
4区域。
[0185]
对于解码过程中的逆变换,可以使用前述变换核矩阵的转置矩阵。也就是说,当在由解码设备执行的逆变换过程中执行逆rst或lfnst时,根据预定排列顺序在一维向量中配置应用逆rst的输入系数数据,并且通过将一维向量与在一维向量左侧的对应的逆rst矩阵相乘而获得的修改的系数向量可以根据预定排列顺序被排列到二维块中。
[0186]
总之,在变换过程中,当rst或lfnst被应用于8
×
8区域时,在8
×
8区域的除了右下区域之外的左上区域、右上区域和左下区域中的48个变换系数与16
×
48变换核矩阵的矩阵运算。对于矩阵运算,以一维阵列输入48个变换系数。当执行矩阵运算时,导出16个修改的变换系数,并且可以将修改的变换系数排列于8
×
8区域的左上区域中。
[0187]
相反,在逆变换过程中,当将逆rst或lfnst应用于8
×
8区域时,可以根据扫描顺序以一维阵列输入8
×
8区域中的变换系数之中的对应于8
×
8区域的左上区域的16个变换系数,并且可以经历与48
×
16变换核矩阵的矩阵运算。也就是说,矩阵运算可以表示为(48
×
16矩阵)*(16
×
1变换系数向量)=(48
×
1修改的变换系数向量)。这里,n
×
1向量可以被解释为具有与n
×
1矩阵相同的含义,并且因此可以被表示为n
×
1列向量。此外,*表示矩阵乘法。当执行矩阵运算时,可以导出48个修改的变换系数,并且可以将48个修改的变换系数排列在8
×
8区域中的除了右下区域之外的左上区域、右上区域和左下区域中。
[0188]
当次级逆变换基于rst时,编码设备200的逆变换器235和解码设备300的逆变换器322可以包括:逆缩减次级变换器,用于对变换系数基于逆rst导出修改的变换系数,以及逆初级变换器,用于对修改的变换系数基于逆初级变换导出用于目标块的残差样本。逆初级变换是指应用于残差的初级变换的逆变换。在本公开中,基于变换导出变换系数可以是指通过应用变换来导出变换系数。
[0189]
上面描述的不可分离的变换(lfnst)将如下详细描述。lfnst可以包括由编码设备进行的正向变换和由解码设备进行的逆变换。
[0190]
编码设备接收在应用初级(核心)变换之后导出的结果(或结果的一部分)作为输入,并且应用正向次级变换(次级变换)。
[0191]
[式9]
[0192]
y=g
t
x
[0193]
在式9中,x和y分别是次级变换的输入和输出,g是表示次级变换的矩阵,并且变换基向量由列向量组成。在逆lfnst的情况下,当变换矩阵g的维度表示为[行的数量
×
列的数量]时,在正向lfnst的情况下,矩阵g的转置变成g
t
的维度。
[0194]
对于逆lfnst,矩阵g的维度是[48
×
16]、[48
×
8]、[16
×
16]、[16
×
8],并且[48
×
8]矩阵和[16
×
8]矩阵是分别从[48
×
16]矩阵和[16
×
16]矩阵的左侧采样的8个变换基向量的部分矩阵。
[0195]
另一方面,对于正向lfnst,矩阵g
t
的维度是[16
×
48]、[8
×
48]、[16
×
16]、[8
×
16],并且[8
×
48]矩阵和[8
×
16]矩阵是通过分别从[16
×
48]矩阵和[16
×
16]矩阵的上部采样8个变换基向量而获得的部分矩阵。
[0196]
因此,在正向lfnst的情况下,[48
×
1]向量或[16
×
1]向量可以作为输入x,并且[16
×
1]向量或[8
×
1]向量可以作为输出y。在视频编译和解码中,正向初级变换的输出是二维(2d)数据,因此为了构造[48
×
1]向量或[16
×
1]向量作为输入x,需要通过将作为正向变换的输出的2d数据适当地排列来构造一维向量。
[0197]
图8是图示根据示例的将正向初级变换的输出数据排列成一维向量的顺序的图。图8的(a)和(b)的左图示出了用于构造[48
×
1]向量的顺序,并且图8的(a)和(b)的右图示出了用于构造[16
×
1]向量的顺序。在lfnst的情况下,可以通过将2d数据按与图8的(a)和(b)中相同的顺序来按序排列来获得一维向量x。
[0198]
可以根据当前块的帧内预测模式确定正向初级变换的输出数据的排列方向。例如,在当前块的帧内预测模式相对于对角线方向处于水平方向时,可以按图8的(a)的顺序排列正向初级变换的输出数据,并且在当前块的帧内预测模式相对于对角线方向处于垂直方向时,可以按图8的(b)的顺序排列正向初级变换的输出数据。
[0199]
根据示例,可以应用不同于图8的(a)和(b)的排列顺序,并且为了导出与应用图8的(a)和(b)的排列顺序时相同的结果(y向量),可以根据排列顺序重新排列矩阵g的列向量。也就是说,可以重新排列g的列向量,使得构成x向量的每个元素总是乘以相同的变换基向量。
[0200]
由于通过式9导出的输出y是一维向量,因此当在使用正向次级变换的结果作为输入的过程中(例如,在执行量化或残差编译的过程中)需要二维数据作为输入数据时,式9的输出y向量需要再次被适当地排列为2d数据。
[0201]
图9是图示根据示例的将正向次级变换的输出数据排列成二维块的顺序的图。
[0202]
在lfnst的情况下,输出值可以根据预定扫描顺序排列在2d块中。图9的(a)示出了当输出y是[16
×
1]向量时,根据对角线扫描顺序将输出值排列在2d块的16个位置。图9的(b)示出了当输出y是[8
×
1]向量时,根据对角线扫描顺序将输出值排列在2d块的8个位置,并且用零填充其余的8个位置。图9的(b)中的x指示它被填充有零。
[0203]
根据另一示例,由于可以预设在执行量化或残差编译时处理输出向量y的顺序,因此输出向量y可以不排列在如图9中所示的2d块中。然而,在残差编译的情况下,可以在2d块
(例如,4
×
4)单元(例如,cg(系数组))中执行数据编译,并且在此情况下,根据如图9的对角线扫描顺序中的特定顺序来排列数据。
[0204]
此外,解码设备可以通过根据用于逆变换的预设扫描顺序来排列通过解量化过程输出的二维数据来配置一维输入向量y。输入向量y可以通过下式输出为输出向量x。
[0205]
[式10]
[0206]
x=gy
[0207]
在逆lfnst的情况下,可以通过将作为[16
×
1]向量或[8
×
1]向量的输入向量y乘以g矩阵来导出输出向量x。对于逆lfnst,输出向量x可以是[48
×
1]向量或[16
×
1]向量。
[0208]
输出向量x根据图8中所示的顺序排列在二维块中,并且被排列为二维数据,并且该二维数据成为逆初级变换的输入数据(或输入数据的一部分)。
[0209]
因此,逆次级变换整体上是正向次级变换过程的相反,并且在逆变换的情况下,与在正向方向中不同,首先应用逆次级变换,然后应用逆初级变换。
[0210]
在逆lfnst中,可以选择8个[48
×
16]矩阵和8个[16
×
16]矩阵中的一个作为变换矩阵g。是应用[48
×
16]矩阵还是应用[16
×
16]矩阵取决于块的大小和形状。
[0211]
另外,可以从如上表2所示的四个变换集中导出8个矩阵,并且每个变换集可以由两个矩阵组成。根据帧内预测模式确定在4个变换集之中使用哪个变换集,并且更具体地,基于通过考虑广角帧内预测(waip)而扩展的帧内预测模式的值来确定变换集。通过索引信令来导出从构成所选择的变换集的两个矩阵之中选择哪个矩阵。更具体地,0、1和2可以作为发送的索引值,0可以指示不应用lfnst,并且1和2可以指示构成基于帧内预测模式值选择的变换集的两个变换矩阵中的任何一个。
[0212]
图9是图示根据本文档的实施例的广角帧内预测模式的图。
[0213]
一般帧内预测模式值可以具有从0到66以及从81到83的值,并且由于waip而扩展的帧内预测模式值可以具有所示的从-14到83的值。从81到83的值指示cclm(跨分量线性模型)模式,并且从-14到-1的值和从67到80的值指示由于waip应用而扩展的帧内预测模式。
[0214]
在预测当前块的宽度大于高度时,上参考像素通常更接近要预测的块内部的位置。因此,在左下方向中比在右上方向中进行预测可以更准确。相反,当块的高度大于宽度时,左参考像素通常更接近要预测的块内部的位置。因此,在右上方向中比在左下方向中进行预测可以更准确。因此,将重映射(即,模式索引修改)应用到广角帧内预测模式的索引可以是有利的。
[0215]
当应用广角帧内预测时,关于现有帧内预测的信息可以被用信号发送,并且在信息被解析之后,该信息可以被重映射到广角帧内预测模式的索引。因此,可以不改变用于特定块(例如,特定大小的非正方形块)的帧内预测模式的总数量,也就是说,帧内预测模式的总数量是67,并且可以不改变用于特定块的帧内预测模式编译。
[0216]
下表3示出了通过将帧内预测模式重映射到广角帧内预测模式来导出修改的帧内模式的过程。
[0217]
[表3]
[0218][0219]
在表3中,扩展的帧内预测模式值最终存储在predmodeintra变量中,并且isp_no_split指示cu块不通过当前在vvc标准中采用的帧内子分区(isp)技术划分成子分区,并且0、1和2的cidx变量值分别指示亮度分量、cb分量和cr分量的情况。表3所示的log2函数返回以2为底的log值,并且abs函数返回绝对值。
[0220]
指示帧内预测模式的变量predmodeintra以及变换块的高度和宽度等用作广角帧内预测模式映射过程的输入值,并且输出值是修改的帧内预测模式predmodeintra。变换块或编译块的高度和宽度可以是用于帧内预测模式的重映射的当前块的高度和宽度。此时,反映宽度与宽度的比率的变量whratio可以被设置为abs(log2(nw/nh))。
[0221]
对于非正方形块,帧内预测模式可以划分成两种情况并且被修改。
[0222]
首先,如果条件(1)至(3)全部被满足,(1)当前块的宽度大于高度、(2)在修改之前的帧内预测模式等于或大于2、以及(3)帧内预测模式在变量whratio大于1时小于从(8 2*whratio)导出的值并且在变量whratio小于或等于1时小于8[predmodeintra小于(whratio》1)?(8 2*whratio):8],则帧内预测模式被设置为比帧内预测模式大65的值[predmodeintra被设置为等于(predmodeintra 65)]。
[0223]
如果与以上不同,即,如果以下条件(1)至(3)被满足,(1)当前块的高度大于宽度、
(2)在修改之前的帧内预测模式小于或等于66、以及(3)帧内预测模式在变量whratio大于1时大于从(60-2*whratio)导出的值并且在变量whratio小于或等于1时大于60[predmodeintra大于(whratio》1)?(60-2*whratio):60],则帧内预测模式被设置为比帧内预测模式小67的值[predmodeintra被设置为等于(predmodeintra-67)]。
[0224]
上表2示出了如何在lfnst中基于由waip扩展的帧内预测模式值选择变换集。如图10所示,模式14到33和模式35到80关于模式34周围的预测方向对称。例如,模式14和模式54关于对应于模式34的方向是对称的。因此,相同的变换集应用于位于相互对称的方向中的模式,并且这种对称性也反映在表2中。
[0225]
此外,假设模式54的正向lfnst输入数据与模式14的正向lfnst输入数据对称。例如,对于模式14和模式54,根据图8的(a)和图8的(b)所示的排列顺序将二维数据重新排列为一维数据。另外,可以看出,图8的(a)和图8的(b)所示的顺序的图案关于由模式34指示的方向(对角线方向)是对称的。
[0226]
此外,如上所述,由变换目标块的大小和形状来确定将[48
×
16]矩阵和[16
×
16]矩阵中的哪个变换矩阵应用于lfnst。
[0227]
图11是图示lfnst被应用于的块形状的图。图11的(a)示出了4
×
4块,(b)示出了4
×
8块和8
×
4块,(c)示出了4
×
n块或n
×
4块,其中n为16或更大,(d)示出了8
×
8块,(e)示出了m
×
n块,其中m≥8、n≥8并且n》8或m》8。
[0228]
在图11中,具有厚边界的块指示lfnst被应用到的区域。对于图11(a)和(b)的块,lfnst被应用于左上4
×
4区域,并且对于图11(c)的块,lfnst被单独地应用于被连续排列的两个左上4
×
4区域。在图11的(a)、(b)和(c)中,由于lfnst以4
×
4区域为单位被应用,所以该lfnst在下文中将被称为“4
×
4lfnst”。可以基于用于式9和式10的g的矩阵维度应用[16
×
16]或[16
×
8]矩阵。
[0229]
更具体地,[16
×
8]矩阵被应用到图11的(a)的4
×
4块(4
×
4tu或4
×
4cu),并且[16
×
16]矩阵被应用到图11的(b)和(c)中的块。这是为了将最坏情况的计算复杂度调整为每样本8次乘法。
[0230]
关于图11的(d)和(e),lfnst被应用于左上8
×
8区域,并且该lfnst在下文中被称为“8
×
8lfnst”。作为对应的变换矩阵,可以应用[48
×
16]矩阵或[48
×
8]矩阵。在正向lfnst的情况下,由于[48
×
1]向量(式9中的x向量)作为输入数据被输入,所以不是左上8
×
8区域的所有样本值都被用作正向lfnst的输入值。也就是说,如可以从图8(a)的左侧顺序或图8(b)的左侧顺序看出的,可以在将右下4
×
4块原样留下的同时基于属于其余3个4
×
4块的样本来构造[48
×
1]向量。
[0231]
[48
×
8]矩阵可以应用于图11(d)中的8
×
8块(8
×
8tu或8
×
8cu),并且[48
×
16]矩阵可以应用于图11(e)中的8
×
8块。这也是为了将最坏情况的计算复杂度调整为每样本8次乘法。
[0232]
取决于块形状,当对应的正向lfnst(4
×
4或8
×
8lfnst)被应用时,生成8或16个输出数据(式9中的y向量,[8
×
1]或[16
×
1]向量)。在正向lfnst中,由于矩阵g
t
的特性,输出数据的数量等于或小于输入数据的数量。
[0233]
图12是图示根据示例的正向lfnst的输出数据的排列的图,并且示出了其中根据块形状排列正向lfnst的输出数据的块。
[0234]
在图12所示的块的左上的阴影区域对应于正向lfnst的输出数据所位于的区域,用0标记的位置指示填充有0值的样本,并且其余区域表示未被正向lfnst改变的区域。在未被lfnst改变的区域中,正向初级变换的输出数据保持不变。
[0235]
如上所述,由于所应用的变换矩阵的维度根据块的形状而变化,因此输出数据的数量也变化。如图12,正向lfnst的输出数据可能不完全填充左上4
×
4块。在图12的(a)和(d)的情况下,将[16
×
8]矩阵和[48
×
8]矩阵分别应用于由粗线指示的块或块内部的部分区域,并且生成作为正向lfnst的输出的[8
×
1]向量。也就是说,根据图9的(b)所示的扫描顺序,可以仅填充8个输出数据,如图12的(a)和(d)所示,并且可以在其余的8个位置中填充0。在图11(d)的lfnst应用的块的情况下,如图12(d)所示,与左上4
×
4块相邻的右上和左下的两个4
×
4块也被填充有0值。
[0236]
如上所述,基本上,通过用信号发送lfnst索引,指定了是否应用lfnst和要应用的变换矩阵。如图12所示,当lfnst被应用时,由于正向lfnst的输出数据的数量可以等于或小于输入数据的数量,所以出现如下填充有零值的区域。
[0237]
1)如图12的(a)所示,左上4
×
4块中的扫描顺序上的从第八个位置后面的位置的样本,即,从第九到第十六的样本。
[0238]
2)如图12的(d)和(e)中所示,当应用[48
×
16]矩阵或[8
×
8]矩阵时,与左上4
×
4块相邻的两个4
×
4块或者扫描顺序上的第二和第三4
×
4块。
[0239]
因此,如果通过检查区域1)和2)存在非零数据,则确定未应用lfnst,使得可以省略对应的lfnst索引的信令。
[0240]
根据示例,例如,在vvc标准中采用的lfnst的情况下,由于在残差编译之后执行lfnst索引的信令,因此编码设备可以通过残差编译知道在tu或cu块内的所有位置是否存在非零数据(有效系数)。因此,编码设备可以基于非零数据的存在来确定是否执行关于lfnst索引的信令,并且解码设备可以确定是否解析lfnst索引。当非零数据不存在于以上1)和2)中指定的区域中时,执行lfnst索引的信令。
[0241]
同时,对于采用的lfnst,可以应用以下简化方法。
[0242]
(i)根据示例,正向lfnst的输出数据的数量可以被限于最多16。
[0243]
在图11的(c)的情况下,4
×
4lfnst可以分别应用于与左上相邻的两个4
×
4区域,并且在这种情况下,可以生成最多32个lfnst输出数据。当正向lfnst的输出数据的数量被限制为最多16时,在4
×
n/n
×
4(n≥16)块(tu或cu)的情况下,4
×
4lfnst仅应用于左上的一个4
×
4区域,可以对图11的所有块仅应用一次lfnst。通过此,可以简化图像编译的实现方式。
[0244]
(ii)根据示例,清零可以被附加地应用于未应用lfnst的区域。在本文档中,清零可以表示用为0的值填充属于特定区域的所有位置。也就是说,可以将清零应用于没有因为lfnst而改变并且维持正向初级变换的结果的区域。如上所述,由于lfnst被划分为4
×
4lfnst和8
×
8lfnst,所以清零可以如下划分为两种类型((ii)-(a)和(ii)-(b))。
[0245]
(ii)-(a)当应用4
×
4lfnst时,未应用4
×
4lfnst的区域可以被清零。图13是图示根据示例的应用4
×
4lfnst的块中的清零的图。
[0246]
如图13所示,关于应用了4
×
4lfnst的块,即,对于图12的(a)、(b)和(c)中的所有块,未应用lfnst的整个区域可以用零填充。
[0247]
另一方面,图13的(d)示出当根据示例正向lfnst的输出数据的数量的最大值被限制为16(如图11所示)时,对未应用4
×
4lfnst的其余块执行清零。
[0248]
(ii)-(b)当应用8
×
8lfnst时,未应用8
×
8lfnst的区域可以被清零。图14是图示根据示例的应用8
×
8lfnst的块中的清零的图。
[0249]
如图14所示,关于应用8
×
8lfnst的块,即,对于图12的(d)和(e)中的所有块,lfnst未被应用到的整个区域可以用零填充。
[0250]
(iii)由于以上(ii)中呈现的清零,当lfnst被应用时用零填充的区域可能不相同。因此,可以根据对比图12的lfnst的情况更宽的区域进行(ii)中提出的清零来检查是否存在非零数据。
[0251]
例如,当(ii)-(b)被应用时,在检查图12的(d)和(e)中的用零值填充的区域是否存在非零数据之后,另外附加地检查图14中填充有0的区域是否存在非零数据,可以仅当不存在非零数据时执行针对lfnst索引的信令。
[0252]
当然,即使应用(ii)中提出的清零,也可以与现有lfnst索引信令相同的方式检查非零数据是否存在。也就是说,在检查在图12中用零填充的块中是否存在非零数据之后,可以应用lfnst索引信令。在此情况下,编码设备仅执行清零并且解码设备不假设清零,也就是,仅检查非零数据是否仅存在于图12中明确标记为0的区域中,可以执行lfnst索引解析。
[0253]
可以导出应用lfnst的简化方法((i)、(ii)-(a)、(ii)-(b)、(iii))的组合的各种实施例。当然,以上简化方法的组合不限于以下实施例,并且可以将任何组合应用于lfnst。
[0254]
实施例
[0255]-将正向lfnst的输出数据的数量限制为最大值16
→(i)[0256]-当应用4
×
4lfnst时,未应用4
×
4lfnst的所有区域被清零
→
(ii)-(a)
[0257]-当应用8
×
8lfnst时,未应用8
×
8lfnst的所有区域被清零
→
(ii)-(b)
[0258]-在检查非零数据是否也存在于填充有零值的现有区域以及由于附加的清零而填充有零的区域中((ii)-(a)、(ii)-(b))之后,仅在不存在非零数据时用信号发送lfnst索引
→
(iii)。
[0259]
在实施例的情况下,当应用lfnst时,可以存在非零输出数据的区域限于左上4
×
4区域的内部。更详细地,在图13的(a)和图14的(a)的情况下,扫描顺序上的第八个位置是可以存在非零数据的最后位置。在图13的(b)和(c)以及图14的(b)的情况下,扫描顺序上的第十六个位置(即,左上4
×
4块的右下边缘的位置)是可以存在除了0以外的数据的最后位置。
[0260]
因此,在应用lfnst时,在检查非零数据是否存在于残差编译过程不被允许的位置(在超出最后位置的位置)之后,可以确定是否用信号发送lfnst索引。
[0261]
在(ii)中提出的清零方法的情况下,由于减少了当应用了初级变换和lfnst两者时最终生成的数据的数量,所以执行整个变换过程所需的计算量可以降低。也就是说,当lfnst被应用时,由于清零被应用于存在于未应用lfnst的区域中的正向初级变换输出数据,因此不需要为在执行正向初级变换期间成为清零的区域生成数据。因此,可以降低生成对应的数据所需的计算量。在(ii)中提出的清零方法的附加效果总结如下。
[0262]
首先,如上所述,减少执行整个变换过程所需的计算量。
[0263]
特别地,当应用(ii)-(b)时,最坏情况的计算量被减少,使得可以轻量化变换过程。换句话说,一般来说,需要大量的计算来执行大尺寸的初级变换。通过应用(ii)-(b),作
为执行正向lfnst的结果而导出的数据的数量可以减小到16或更小。另外,随着整个块(tu或cu)的大小增加,减少变换操作的量的效果进一步增加。
[0264]
第二,可以减少整个变换过程所需的计算量,由此降低执行变换所需的功耗。
[0265]
第三,减少了变换过程中涉及的延迟。
[0266]
诸如lfnst之类的次级变换向现有的初级变换添加了计算量,因而增加了执行变换时涉及的总体延迟时间。特别地,在帧内预测的情况下,由于在预测过程中使用邻近块的重构数据,所以在编码期间,由于次级变换导致的延迟的增加导致直到重构的延迟的增加。这可以导致帧内预测编码的总体延迟的增加。
[0267]
然而,如果应用(ii)中建议的清零,则当应用lfnst时可以极大地减少执行初级变换的延迟时间,保持或减少整个变换的延迟时间,使得可以更简单地实现编码设备。
[0268]
同时,在传统的帧内预测中,编译的目标块被视为一个编译单元,并且在不分区的情况下执行编译。然而,isp(帧内子分区)编译指的是通过在水平方向或垂直方向上分区编译目标块来执行帧内预测编译。在这种情况下,可以通过以分区的块为单位执行编码/解码来生成重构块,并且重构块可以用作下一个分区的块的参考块。根据示例,在isp编译中,可以将一个编译块分区成两个或四个子块并且进行编译,并且在isp中,通过参考位于与其左侧或上侧相邻的子块的重构像素值对一个子块执行帧内预测。在下文中,术语“编译”可以用作包括由编码设备执行的编译和由解码设备执行的解码两者的概念。
[0269]
isp根据块的大小将预测为帧内亮度的块分区成垂直方向或水平方向上的两个或四个子分区。例如,能够应用isp的最小块大小为4x8或8x4。如果块大小大于4x8或8x4,则将块分区成四个子分区。
[0270]
当应用isp时,子块根据分区类型顺序地编译,诸如水平或垂直、从左到右或从上到下,并且可以在对一个子块通过逆变换和帧内预测执行直至恢复过程之后执行下一个子块的编译。对于最左边或最上面的子块,与在传统的帧内预测方法中一样,参考已经编译的编译块的重构像素。另外,如果前一个子块不与跟随其的内部子块的每一侧相邻,则为了导出与对应侧相邻的参考像素,如在传统的帧内预测方法中,参考已经编译的相邻的编译块的重构的像素。
[0271]
在isp编译模式中,所有子块可以用相同的帧内预测模式进行编译,并且可以用信号发送指示是否使用isp编译的标志和指示要执行方向(水平或垂直)分区的标志。此时,子块的数量可能会取决于块的形状调整为2个或4个,并且当一个子块的大小(宽x高)小于16时,可能不允许对相应的子块的分区,也可以限制为不应用isp编译本身。
[0272]
同时,在isp预测模式的情况下,将一个编译单元分区成两个或四个分区块,即,子块,并且进行预测,并且将相同的帧内预测模式应用于如此分区的两个或四个分区块。
[0273]
如上所述,水平方向(如果具有水平长度和垂直长度分别为m和n的mxn编译单元在水平方向上被划分,当被划分为两个时其被划分为mx(n/2)块,并且当划分为四个时其被划分为mx(n/4)块)和垂直方向(如果mxn编译单元在垂直方向上划分,在划分为2个时其被划分为(m/2)xn块,并且其被划分为4个时被划分为(m/4)
×
n块)两者都可以作为分区方向。当在水平方向上分区时,分区块以从上到下的顺序被编译,并且当在垂直方向上分区时,分区块以从左到右的顺序被编译。在水平(垂直)方向分区的情况下,可以通过参考上(左)分区块的重构像素值来预测当前编译的分区块。
[0274]
可以以分区块为单位将变换应用于由isp预测方法生成的残差信号。基于dst-7/dct-8组合的mts(多变换选择)技术以及现有的dct-2可以应用于基于正向的初级变换(核心变换或初级变换),而lfnst(低频不可分离变换)可以应用于根据初级变换生成的变换系数以生成最终修改的变换系数。
[0275]
也就是说,lfnst也可以应用于通过应用isp预测模式划分的分区块,并且将相同的帧内预测模式应用于如上所述划分的分区块。因此,当选择基于帧内预测模式导出的lfnst集时,导出的lfnst集可以被应用于所有的分区块。即,相同的帧内预测模式被应用于所有分区块,并且从而相同的lfnst集可以被应用于所有的分区块。
[0276]
同时,根据示例,lfnst可以仅应用于具有4或更大的水平和垂直长度的变换块。因此,当根据isp预测方法分区的分区块的水平或垂直长度小于4时,不应用lfnst并且不用信号发送lfnst索引。另外,当对每个分区块应用lfnst时,对应的分区块可以被视为一个变换块。当然,当不应用isp预测方法时,也可以对编译块应用lfnst。
[0277]
lfnst对每个分区块的应用详细描述如下。
[0278]
根据示例,在将正向lfnst应用于单个分区块之后,并且在根据变换系数扫描顺序在左上4x4区域中仅留下直至16个系数(8个或16个)之后,可以应用以0值填充所有剩余位置和区域的清零。
[0279]
可替选地,根据示例,当分区块的一侧的长度为4时,lfnst仅应用于左上4x4区域,并且当分区块的所有侧边的长度,即,宽度和高度为8或更大时,lfnst可以应用于除了左上8x8区域中的右下4x4区域之外的剩余的48个系数。
[0280]
可替选地,根据示例,为了将最坏情况的计算复杂度调整为每样本8次乘法,当每个分区块为4x4或8x8时,在应用正向lfnst之后可以仅输出8个变换系数。即,如果分区块是4x4,则可以应用8x16矩阵作为变换矩阵,并且如果分区块是8x8,则可以应用8x48矩阵作为变换矩阵。
[0281]
同时,在当前的vvc标准中,lfnst索引信令以编译单元为单位执行。因此,当使用isp预测模式并且将lfnst应用于所有分区块时,那么可以将相同的lfnst索引值应用于对应的分区块。也就是说,当在编译单元级别发送lfnst索引值一次时,对应的lfnst索引可以应用于编译单元中的所有分区块。如上所述,lfnst索引值可以具有0、1和2的值,并且0指示不应用lfnst的情况,并且1和2指示在应用lfnst时存在于一个lfnst集中的两个变换矩阵。
[0282]
如上所述,lfnst集由帧内预测模式确定,并且由于在isp预测模式的情况下在编译单元中的所有分区块都以相同的帧内预测模式进行预测,所以分区块可以参考相同的lfnst集。
[0283]
作为另一示例,lfnst索引信令仍然以编译单元为单位执行,但是在isp预测模式的情况下,在没有确定是否对所有分区块统一应用lfnst的情况下,可以通过单独的条件来确定是否将在编译单元级别用信号发送的lfnst索引值应用于每个分区块或不应用lfnst。这里,单独的条件可以通过比特流以每个分区块的标志的形式用信号发送,并且当标志值为1时,可以应用在编译单元级别用信号发送的lfnst索引值,并且当标志值是0时,可能不应用lfnst。
[0284]
在下文中,将描述在将lfnst应用于isp模式时保持最坏情况的计算复杂度的方法。
[0285]
在isp模式的情况下,为了在应用lfnst时将每样本(或每系数或每位置)的乘法次数保持在某个值或更少,可以限制lfnst的应用。取决于分区块的大小,每样本(或每系数,或每位置)的乘法次数可以通过如下应用lfnst保持在8或更少。
[0286]
1.当分区块的水平长度和垂直长度都等于或大于4时,可以应用与当前vvc标准中针对lfnst最坏情况的计算复杂度调整方法相同的方法。
[0287]
也就是说,当分区块是4x4块时,在正向方向上,可以应用通过从16x16矩阵中采样前8行获得的8x16矩阵来代替16x16矩阵,并且在后向方向上,可以应用通过从16x16矩阵中采样左8列获得的16x8矩阵。另外,当分区块是8x8块时,在正向方向上,可以应用通过从16x48矩阵中采样前8行获得的8x48矩阵来代替16x48矩阵,并且在后向方向上,可以应用通过从48x16矩阵中采样左8列获得的48x8矩阵来代替48x16矩阵。
[0288]
在4xn或nx4(n》4)块的情况下,当执行正向变换时,将16x16矩阵仅应用于左上4x4块之后生成的16个系数排列在左上4x4区域中,并且其他区域可以以0值填充。另外,当执行逆变换时,可以将位于左上4x4块中的16个系数按照扫描顺序排列以配置输入向量,并且然后通过乘以16x16矩阵可以生成16个输出数据。生成的输出数据可以排列在左上4x4区域中,并且除了左上4x4区域之外的其余区域可以用零填充。
[0289]
在8xn或nx8(n》8)块的情况下,当执行正向变换时,将16x48矩阵仅应用于左上8x8块中的roi区域(从左上8x8块排除右下4x4块的剩余区域)之后生成的16个系数可以排列在左上4x4区域中,并且其他区域可以用0值填充。另外,当执行逆变换时,可以将位于左上4x4块中的16个系数按照扫描顺序排列以配置输入向量,并且然后通过乘以48x16矩阵可以生成48个输出数据。生成的输出数据可以填充在roi区域中,并且其他区域可以填充有0值。
[0290]
作为另一示例,为了将每样本(或每系数或每位置)的乘法次数保持在某个值或更少,基于isp编译单元大小而不是isp分区块的大小的每样本(或每系数或每位置)的乘法次数可以保持在8或更小。如果在isp分区块当中只有一个满足应用lfnst的条件的块,则可以基于相应的编译单元大小而不是分区块的大小来应用针对lfnst的最坏情况的复杂度计算。例如,当某个编译单元的亮度编译块被分区成4个4x4大小的分区块并由isp编译时,并且当对于它们当中的两个分区块不存在非零变换系数时,其他两个分区块可以分别被设置以生成16个变换系数而不是8个(基于编码器)。
[0291]
在下文中,将描述在isp模式的情况下用信号发送lfnst索引的方法。
[0292]
如上所述,lfnst索引可以具有0、1和2的值,其中0指示未应用lfnst,并且1和2分别指示包括在所选lfnst集中的两个lfnst核矩阵之一。基于由lfnst索引选择的lfnst核矩阵应用lfnst。下面将描述在当前vvc标准中发送lfnst索引的方法。
[0293]
1.可以为每个编译单元(cu)发送一次lfnst索引,并且在双树的情况下,可以分别为亮度块和色度块发送单独的lfnst索引。
[0294]
2.当lfnst索引未被用信号发送时,lfnst索引值被推断为默认值0。lfnst索引值被推断为0的情况如下。
[0295]
a.在不应用变换的模式的情况下(例如,变换跳过、bdpcm、无损编译等)
[0296]
b.当初级变换不是dct-2(dst7或dct8)时,即,水平方向的变换或垂直方向的变换不是dct-2时
[0297]
c.当用于编译单元的亮度块的水平长度或垂直长度超过可变换的最大亮度变换
的大小时,例如,当可变换的最大亮度变换的大小为64时,并且当编译块的亮度块等于128x16时,不能应用lfnst。
[0298]
在双树的情况下,确定对于亮度分量的编译单元和色度分量的编译单元中的每一个是否超过最大亮度变换的大小。即,对于亮度块检查是否超过最大可变换的亮度变换的大小,并且对于色度块检查是否超过用于颜色格式的对应亮度块的水平/垂直长度以及超过最大可变换亮度变换的大小。例如,当颜色格式为4:2:0时,对应的亮度块的水平/垂直长度是对应色度块的两倍,并且对应的亮度块的变换大小是对应色度块的两倍。作为另一示例,当颜色格式为4:4:4时,对应的亮度块的水平/垂直长度和变换大小与对应的色度块相同。
[0299]
64长度的变换或32长度的变换可以意指分别应用于具有64或32长度的宽度或高度的变换,并且“变换大小”可以意指64或32作为相应的长度。
[0300]
在单树的情况下,在检查亮度块的水平长度或垂直长度是否超过最大可变换亮度变换块大小后,如果超过,则可以省略lfnst索引信令。
[0301]
d.只有当编译单元的水平长度和垂直长度都等于或大于4时,才可以发送lfnst索引。
[0302]
在双树的情况下,仅当相应分量(即,亮度或色度分量)的水平和垂直长度都等于或大于4时,才可以用信号发送lfnst索引。
[0303]
在单树的情况下,当亮度分量的水平和垂直长度都等于或大于4时,可以用信号发送lfnst索引。
[0304]
e.如果最后非零系数的位置不是dc位置(块的左上位置),并且在双树类型的亮度块的情况下,如果最后非零系数的位置不是dc位置,发送lfnst索引。在双树类型的色度块的情况下,如果cb的最后非零系数的位置和cr的最后非零系数的位置中的任何一个不是dc位置,则发送相应的lnfst索引。
[0305]
在单树类型的情况下,如果亮度分量、cb分量和cr分量中的任何一个的最后非零系数的位置不是dc位置,则发送lfnst索引。
[0306]
这里,如果指示一个变换块的变换系数是否存在的编译块标志(cbf)值为0,则不为了确定是否用信号发送lfnst索引而检查对应变换块的最后非零系数的位置。也就是说,当对应的cbf值为0时,由于对对应的块不应用变换,所以在检查lfnst索引信令的条件时可以不考虑最后非零系数的位置。
[0307]
例如,1)在双树类型和亮度分量的情况下,如果相应的cbf值为0,则不用信号发送lfnst索引,2)在双树类型和色度分量的情况下,如果用于cb的cbf值为0并且用于cr的cbf值为1,则仅检查用于cr的最后非零系数的位置并且发送相应的lfnst索引,3)在单树类型的情况下,仅针对亮度、cb和cr中的每一个的具有cbf值为1的分量检查最后非零系数的位置。
[0308]
f.当确认变换系数存在于除了可能存在lfnst变换系数的位置之外的位置时,可以省略lfnst索引信令。在4x4变换块和8x8变换块的情况下,根据vvc标准中的变换系数扫描顺序,lfnst变换系数可能存在于从dc位置起的8个位置,并且其余位置用零填充。另外,当4x4变换块和8x8变换块不存在时,根据vvc标准中的变换系数扫描顺序,lfnst变换系数可能存在于从dc位置起的16个位置,并且其余位置用零填充。
[0309]
因此,如果非零变换系数存在于在进行残差编译之后应该用零值填充的区域中,则可以省略lfnst索引信令。
[0310]
同时,isp模式也可以仅应用于亮度块,或者可以应用于亮度块和色度块两者。如上所述,当应用isp预测时,可以将对应的编译单元划分为两个或四个分区块并进行预测,并且可以对每个分区块应用变换。因此,在以编译单元为单位确定用信号发送lfnst索引的条件时,也有必要考虑lfnst可以应用于各分区块的情况。此外,当isp预测模式仅应用于特定分量(例如,亮度块)时,考虑到仅该分量被划分为分区块的事实,必须用信号发送lfnst索引。isp模式下可用的lfnst索引信令方法总结如下。
[0311]
1.可以为每个编译单元(cu)发送一次lfnst索引,并且在双树的情况下,可以分别为亮度块和色度块发送单独的lfnst索引。
[0312]
2.当不用信号发送lfnst索引时,lfnst索引值被推断为默认值0。lfnst索引值被推断为0的情况如下。
[0313]
a.在不应用变换的模式的情况下(例如,变换跳过、bdpcm、无损编译等)
[0314]
b.当编译单元的亮度块的水平长度或垂直长度超过可变换的最大亮度变换的大小时,例如,当可变换的最大亮度变换的大小为64时,并且当编译块的亮度块的大小等于128x16,不能应用lfnst。
[0315]
可以基于分区块的大小而不是编译单元来确定是否用信号发送lfnst索引。也就是说,如果对应亮度块的分区块的水平或垂直长度超过可变换的最大亮度变换的大小,则可以省略lfnst索引信令并且可以推断lfnst索引值为0。
[0316]
在双树的情况下,确定对于亮度分量的编译单元或分区块和色度分量的编译单元或分区块中的每一个是否超过最大亮度变换的大小。也就是说,如果亮度的编译单元或分区块的水平和垂直长度分别与最大亮度变换大小进行比较,并且其中至少一个大于最大亮度变换大小,则不应用lfnst,并且在色度的编译单元或分区块的情况下,用于该颜色格式的对应亮度块的水平/垂直长度和最大可变换亮度变换的大小进行比较。例如,当颜色格式为4:2:0时,对应的亮度块的水平/垂直长度是对应色度块的两倍,并且对应亮度块的变换大小是对应色度块的两倍。作为另一示例,当颜色格式为4:4:4时,对应的亮度块的水平/垂直长度和变换大小与对应的色度块的相同。
[0317]
在单树的情况下,在检查亮度块(编译单元或分区块)的水平长度或垂直长度是否超过最大可变换亮度变换块大小之后,如果其超过,则可以省略lfnst索引信令。
[0318]
c.如果应用当前vvc标准中包括的lfnst,则仅当分区块的水平长度和垂直长度都等于或大于4时才可以发送lfnst索引。
[0319]
如果除了当前vvc标准中包括的lfnst之外还应用用于2xm(1xm)或mx2(mx1)块的lfnst,则仅当分区块的大小等于或大于2xm(1xm)或mx2(mx1)块时才可以发送lfnst索引。这里,表达“pxq块等于或大于rxs块”意指p≥r并且q≥s。
[0320]
总之,仅当分区块等于或大于lfnst可应用的最小大小时才能够发送lfnst索引。在双树的情况下,仅当亮度或色度分量的分区块等于或大于lfnst可应用的最小大小时,才能够用信号发送lfnst索引。在单树的情况下,仅当亮度分量的分区块等于或大于lfnst可应用的最小大小时,才能够用信号发送lfnst索引。
[0321]
在本文档中,表达“mxn块大于或等于kxl块”意指m大于或等于k且n大于或等于l。
表达“mxn块大于kxl块”意指m大于或等于k并且n大于或等于l,并且m大于k或n大于l。表达“mxn块小于或等于kxl块”意指m小于或等于k并且n小于或等于l,而表达“mxn块小于kxl块”意指m小于或等于k并且n小于或等于l,并且m小于k或n小于l。
[0322]
d.如果最后非零系数的位置不是dc位置(块的左上位置),并且在双树类型的亮度块的情况下,如果所有分区块中的任意一个中最后非零系数的位置不是dc位置,则发送lfnst索引。在双树类型和色度块的情况下,如果用于cb的所有分区块的最后非零系数的位置(如果isp模式没有被应用于色度分量,则分区数块被认为是1)并且用于cr的所有分区块的最后非零系数的位置(如果isp模式不应用于色度分量,则分区块的数量被认为是1)中的至少一个不是dc位置,则可以发送对应的lnfst索引。
[0323]
在单树类型的情况下,如果用于亮度分量、cb分量和cr分量的所有分区块中的任何一个的最后非零系数的位置不是dc位置,则对应的lfnst索引可以被发送。
[0324]
这里,如果指示对于每个分区块是否存在变换系数的编译块标志(cbf)的值为0,则不为了确定是否用信号发送lfnst索引而检查对应分区块的最后非零系数的位置。也就是说,当对应的cbf值为0时,由于对对应的块不应用变换,所以在检查用于lfnst索引信令的条件时不考虑对应的分区块的最后非零系数的位置。
[0325]
例如,1)在双树类型和亮度分量的情况下,如果用于每个分区块的对应的cbf值为0,则在确定是否用信号发送lfnst索引时排除分区块,2)在双树类型和色度分量的情况下,如果对于每个分区块用于cb的cbf值为0并且用于cr的cbf值为1,则仅检查用于cr的最后非零系数的位置以确定是否用信号发送lfnst索引,3)在单树类型的情况下,能够通过仅为用于亮度分量、cb分量和cr分量的所有分区块的具有cbf值为1的块检查最后非零系数的位置来确定是否用信号发送lfnst索引。
[0326]
在isp模式的情况下,图像信息也可以被配置使得不检查最后非零系数的位置,并且其实施例如下。
[0327]
i.在isp模式的情况下,可以允许lfnst索引信令而不检查用于亮度块和色度块两者的最后非零系数的位置。也就是说,即使所有分区块的最后非零系数的位置是dc位置或者对应的cbf值为0,也可以允许lfnst索引信令。
[0328]
ii.在isp模式的情况下,仅对亮度块的最后非零系数的位置的检查可以被省略,并且在色度块的情况下,对最后非零系数的位置的检查可以以上述方式执行。例如,在双树类型和亮度块的情况下,允许lfnst索引信令而不检查最后非零系数的位置,并且在双树类型和色度块的情况下,可以通过以上述方式检查对于最后非零系数的位置是否存在dc位置来确定是否用信号发送相应的lfnst索引。
[0329]
iii.在isp模式和单树类型的情况下,可以应用i或ii方法。即,在isp模式的情况下并且当编号i被应用于单树类型时,能够省略对亮度块和色度块两者的最后非零系数的位置的检查并且允许lfnst索引信令。可替选地,通过应用部分ii,对于亮度分量的分区块,省略最后非零系数位置的检查,并且对于色度分量的分区块(如果对色度分量不应用isp,分区块的数量能够被认为是1),以上述方式检查最后非零系数的位置,从而确定是否用信号发送lfnst索引。
[0330]
e.当确认变换系数存在于除了lfnst变换系数可能存在的位置之外的位置时,即使对于所有分区块当中的一个分区块,也可以省略lfnst索引信令。
[0331]
例如,在4x4分区块和8x8分区块的情况下,根据vvc标准中的变换系数扫描顺序,lfnst变换系数可能存在于从dc位置的8个位置,并且其余位置被填充有零。另外,如果其等于或大于4x4并且不是4x4分区块也不是8x8分区块,则根据vvc标准中的变换系数扫描顺序,lfnst变换系数可能存在于从dc位置的16个位置,并且所有其余位置被填充有零。
[0332]
因此,如果非零变换系数存在于在进行残差编译之后应该用零值填充的区域中,则可以省略lfnst索引信令。
[0333]
同时,在isp模式的情况下,对于水平方向和垂直方向独立地查看长度条件,并且在不用信号发送mts索引情况下应用dst-7代替dct-2。确定水平或垂直长度是否大于或等于4且小于或等于16,并且根据确定结果确定初级变换核。因此,在isp模式的情况下,当能够应用lfnst时,以下变换组合配置是可能的。
[0334]
1.当lfnst索引为0时(包括lfnst索引被推断为0的情况),可以遵循当前vvc标准中包括的isp时的初级变换决定条件。换句话说,可以分别检查对于水平和垂直方向是否独立满足长度条件(等于或大于4或等于或小于16),并且如果满足,则对于初级变换可以应用dst-7代替dct-2,而如果不满足,则可以应用dct-2。
[0335]
2.对于lfnst索引大于0的情况,以下两种配置可以作为初级变换也是可能的。
[0336]
a.dct-2能够被应用于水平和垂直方向两者。
[0337]
b.可以遵循当前vvc标准中包括的isp时的初级变换决定条件。换句话说,可以分别检查对于水平和垂直方向是否独立满足长度条件(等于或大于4或等于或小于16),并且如果满足,则可以应用dst-7代替dct-2,而如果不满足,则可以应用dct-2。
[0338]
在isp模式中,可以配置图像信息,使得针对每个分区块而不是针对每个编译单元来发送lfnst索引。在这种情况下,在上述lfnst索引信令方法中,可以认为在发送lfnst索引的单元中仅存在一个分区块,并且可以确定是否用信号发送lfnst索引。
[0339]
在下文中,描述lfnst索引和mts索引的信令。
[0340]
根据示例的与lfnst索引和mts索引的信令有关的编译单元语法表、变换单元语法表和残差编译语法表如下所示。根据表4,mts索引从变换单元级语法移到编译单元级语法,并在用信号发送lfnst索引之后被用信号发送。此外,移除当将isp应用于编译单元时不允许lfnst的约束。因为当isp应用于编译单元时不允许lfnst的约束被移除,所以lfnst可以应用于所有帧内预测块。此外,mts索引和lfnst索引都在编译单元级的末尾有条件地用信号发送。
[0341]
[表4]
[0342][0343]
[表5]
[0344][0345]
[表6]
[0346][0347]
表中主要变量的含义如下。
[0348]
1.cbwidth、cbheight:当前编译块的宽度和高度
[0349]
2.log2tbwidth、log2tbheight:当前变换块的宽度和高度的以2为底的对数值,可以通过反映清零,减少到其中非零系数可能存在的左上区域。
[0350]
3.sps_lfnst_enabled_flag:指示是否启用lfnst的标志,如果标志值为0,则指示不启用lfnst,并且如果标志值为1,则指示启用lfnst。其在序列参数集(sps)中定义。
[0351]
4.cupredmode[chtype][x0][y0]:对应于变量chtype和(x0,y0)位置的预测模式,chtype可以具有0和1的值,其中0指示亮度分量并且1指示色度分量。(x0,y0)位置指示图片上的位置,并且作为cupredmode[chtype][x0][y0]的值的mode_intra(帧内预测)和mode_inter(帧间预测)是可能的。
[0352]
5.intrasubpartitionssplit[x0][y0]:(x0,y0)位置的内容与编号4中的相同。其指示(x0,y0)位置处的哪个isp分区被应用,isp_no_split指示与(x0,y0)位置对应的编译单元不被划分为分区块。
[0353]
6.intra_mip_flag[x0][y0]:(x0,y0)位置的内容与上面的编号4中的相同。intra_mip_flag是指示是否应用基于矩阵的帧内预测(mip)预测模式的标志。如果标志值为0,则其指示未启用mip,并且如果标志值为1,则指示启用mip。
[0354]
7.cidx:0的值指示亮度,并且1和2的值指示分别是色度分量的cb和cr。
[0355]
8.treetype:指示单树和双树等(single_tree:单树,dual_tree_luma:亮度分量的双树,dual_tree_chroma:色度分量的双树)
[0356]
9.tu_cbf_cb[x0][y0]:(x0,y0)位置的内容与编号4中的相同。其指示用于cb分量的编译块标志(cbf)。如果其值为0,则意指在用于cb分量的相应变换单元中不存在非零系
数,并且如果其值为1,则指示在用于cb分量的相应变换单元中存在非零系数分量。
[0357]
10.lastsubblock:其指示其中最后非零系数所位于的子块(系数组(cg))的扫描顺序中的位置。0指示其中包括dc分量的子块,并且在大于0的情况下,不是其中包括dc分量的子块。
[0358]
11.lastscanpos:其指示扫描顺序中的最后有效系数在一个子块内的位置。如果一个子块包括16个位置,则从0到15的值是可能的。
[0359]
12.lfnst_idx[x0][y0]:要解析的lfnst索引语法元素。如果不解析,则推断为值0。即,默认值被设置为0,指示不应用lfnst。
[0360]
13.cu_sbt_flag:指示当前vvc标准中包括的子块变换(sbt)是否适用的标志。标志值等于0指示sbt不适用,并且标志值等于1指示应用sbt。
[0361]
14.sps_explicit_mts_inter_enabled_flag、sps_explicit_mts_intra_enabled_flag:指示显式mts是否分别应用于帧间cu和帧内cu的标志。flag值等于0指示mts不适用于帧间cu或帧内cu,并且标志值等于1指示mts适用。
[0362]
15.tu_mts_idx[x0][y0]:要解析的mts索引语法元素。当不解析时,此元素被推断为值0。也就是说,该元素设置为默认值0,这指示dct-2被水平和垂直应用。
[0363]
如表4所示,当编译mts_idx[x0][y0]时检查多个条件,并且仅当lfnst_idx[x0][y0]等于0时才用信号发送tu_mts_idx[x0][y0]。
[0364]
tu_cbf_luma[x0][y0]是指示对于亮度分量是否存在有效系数的标志。
[0365]
根据表4,当用于亮度分量的编译单元的宽度和高度都是32或更小时,mts_idx[x0][y0]被用信号发送(max(cbwidth,cbheight)《=32),也就是说,mts是否被应用由用于亮度分量的编译单元的宽度和高度确定。
[0366]
此外,根据表4,它可以被配置成即使在isp模式(intrasubpartitionssplittype!=isp_no_split)下也用信号发送lfnst_idx[x0][y0],并且可以将相同的lfnst索引值应用于所有isp分区块。
[0367]
然而,可以仅在除isp模式以外的情况(intrasubpartitionssplit[x0][y0]==isp_no_split)下用信号发送mts_idx[x0][y0]。
[0368]
如表6所示,可以在确定log2zotbwidth和log2zotbheight的过程中省略检查mts_idx[x0][y0]的值(其中log2zotbwidth和log2zotbheight分别表示在执行清零之后剩下的左上区域的宽度和高度的以2为底的对数值)。
[0369]
根据示例,当在残差编译中确定log2zotbwidth和log2zotbheight时,可以添加检查sps_mts_enable_flag的条件。
[0370]
表4中的变量lfnstzerooutsigcoeffflag在当应用lfnst时在清零位置处存在有效系数的情况下是0,否则是1。可以根据表6所示的多个条件来设置变量lfnstzerooutsigcoeffflag。
[0371]
根据示例,表4中的变量lfnstdconly在用于对应编译块标志(cbf,当在对应块中存在至少一个有效系数时其是1,否则是0)为1的变换块的所有最后有效系数在dc位置(左上位置)处时是1,否则是0。具体地,在双树亮度中关于一个亮度变换块检查最后有效系数的位置,而在双树色度中关于用于cb的变换块和用于cr的变换块检查最后有效系数的位置。在单树中,可以关于用于亮度、cb和cr的变换块检查最后有效系数的位置。
[0372]
在表4中,mtszerooutsigcoeffflag最初被设置为1,并且可以在表6的残差编译中改变此值。当在要通过清零用0填充的区域中存在有效系数(lastsignificantcoeffx》15||lastsignificantcoeffy》15)时,变量mtszerooutsigcoeffflag被从1改变为0,在此情况下如表4所示不用信号发送mts索引。
[0373]
如表4所示,当tu_cbf_luma[x0][y0]是0时,可以省略对mts_idx[x0][y0]进行编译。也就是说,当亮度分量的cbf值是0时,不应用变换,因此不需要用信号发送mts索引。因此,可以省略对mts索引进行编译。
[0374]
根据示例,可以在另一条件语法中实现以上技术特征。例如,在执行mts之后,可以导出指示在当前块的除dc区域以外的区域中是否存在有效系数的变量,并且当该变量指示在排除dc区域的区域中存在有效系数时,能够用信号发送mts索引。也就是说,在当前块的除dc区域以外的区域中存在有效系数指示tu_cbf_luma[x0][y0]的值是1,并且在这种情况下,能够用信号发送mts索引。
[0375]
可以将该变量表达为mtsdconly,并且在编译单元级别将变量mtsdconly最初设置为1之后,当在残差编译级别确定了在当前块的除了dc之外的区域中存在有效系数时该值被改变为0。当变量mtsdconly是0时,可以配置图像信息,使得mts索引被用信号发送。
[0376]
当tu_cbf_luma[x0][y0]是0时,由于在表5的变换单元级别不调用残差编译语法,所以变量mtsdconly的初始值1被维持。在这种情况下,由于变量mtsdconly未被改变为0,所以可以配置图像信息,使得mts索引不被用信号发送。也就是说,mts索引不被解析和用信号发送。
[0377]
同时,解码设备可以确定变换系数的颜色索引cidx以导出表6的变量mtszerooutsigcoeffflag。0的颜色索引cidx意指亮度分量。
[0378]
根据示例,由于能够将mts仅应用于当前块的亮度分量,所以解码设备能够在导出用于确定是否解析mts索引的变量mtszerooutsigcoeffflag时确定颜色索引是否是亮度。
[0379]
变量mtszerooutsigcoeffflag是指示在应用mts时是否执行清零的变量。它指示,在执行mts之后由于清零而可能存在最后有效系数的左上区域中,即在除左上16x16区域以外的区域中,是否存在变换系数。如表4所示变量mtszerooutsigcoeffflag在编译单元级别被最初设置为1(mtszerooutsigcoeffflag=1),并且当在除16x16区域以外的区域中存在变换系数时,如表6所示能够在残差编译级别将其值从1改变为0(mtszerooutsigcoeffflag=0)。当变量mtszerooutsigcoeffflag的值是0时,mts索引不被用信号发送。
[0380]
如表6所示,在残差编译级别,可以取决于伴随mts的清零是否被执行而设置在其中可能存在非零变换系数的非清零区域,并且即使在这种情况下,颜色索引(cidx)也是0,可以将非清零区域设置为当前块的左上16x16区域。
[0381]
因此,当导出确定mts索引是否被解析的变量时,确定了颜色分量是亮度还是色度。然而,由于能够将lfnst应用于当前块的亮度分量和色度分量两者,所以在导出用于确定是否解析lfnst索引的变量时不确定颜色分量。
[0382]
例如,表4示出可以指示在应用lfnst时执行清零的变量lfnstzerooutsigcoeffflag。变量lfnstzerooutsigcoeffflag指示在除了当前块的左上处的第一区域之外的第二区域中是否存在有效系数。此值最初被设置为1,并且当在第二区域中存在有效系数时,能够将该值改变为0。只有当最初设置的变量
lfnstzerooutsigcoeffflag的值被维持在1时才能够解析lfnst索引。当确定并导出变量lfnstzerooutsigcoeffflag值是否是1时,由于可以将lfnst应用于当前块的亮度分量和色度分量两者,所以不确定当前块的颜色索引。
[0383]
当截断一元码作为二值化方法被应用于lfnst索引时,lfnst索引包括最多两个bin,并且为可能的lfnst索引值0、1和2分配0、10和11的二进制码。
[0384]
根据示例,可以对lfnst索引的第一bin应用基于上下文的cabac编译(常规编译),并且可以对第二bin应用旁路编译。
[0385]
根据另一示例,可以对lfnst索引的第一bin和第二bin两者应用基于上下文的cabac编译。根据上下文编译的bin分配lfnst索引的ctxinc如下所示。
[0386]
[表7]
[0387][0388]
如表7所示,对于第一bin(binidx=0),可以在单树中应用上下文0,并且可以在非单树中应用上下文1。如表14所示,对于第二bin(binidx=1),可以应用上下文2。也就是说,可以为第一bin分配两个上下文,可以为第二bin分配一个上下文,并且可以通过ctxinc值(0、1和2)来区分每个上下文。
[0389]
这里,单树指示亮度分量和色度分量用相同的编译结构编译。当编译单元用相同的编译结构分割,并且编译单元的大小变得小于或等于特定阈值大小并且因此亮度分量和色度分量用分离树结构编译时,可以将编译单元认为是双树来确定用于第一bin的上下文。也就是说,如表14所示,可以分配上下文1。
[0390]
可替选地,当变量treetype的值对于第一bin被分配为single_tree时,上下文0可以被用于编译,否则,上下文1可以被用于编译。
[0391]
根据示例,当在编码过程中尝试仅两个lfnst核候选中的第一(或第二)候选时,lfnst索引对于该候选具有两个固定bin值(当尝试仅第一候选时,可以将lfnst索引编译为10,而当尝试仅第二候选时,可以将lfnst索引编译为11)。在这种情况下,当通过旁路方法来对第二bin进行编译时,即使第二bin具有固定值(0或1),也针对第二bin引发固定量的比特,可能显著地增加用于第二bin的编译成本。当通过上下文方法而不是旁路方法来对第二bin进行编译时,如果尝试仅一个固定lfnst核候选,则第二bin出现固定值(0或1)的概率可以朝向100%更新,并且因此可以显著地降低编译成本。总之,与应用两个候选相比,尽管在编码过程中固定并应用仅一个lfnst核候选,但是通过上下文方法来对所有两个bin进行编译以便对lfnst索引进行编译可以使编译效率的损失最小化,同时降低编码复杂度,从而在编码过程中找到性能复杂度权衡时给出相当大的自由度。
[0392]
根据示例用信号发送lfnst索引的编译单元的语法表如下。
[0393]
[表8]
[0394]
[0395][0396][0397]
在表8中,lfnst_idx是指lfnst索引并且可以具有如上所述的0、1和2的值。如表8所示,只有当满足(!intra_mip_flag[x0][y0]||min(lfnstwidth,lfnstheight)》=16)的条件时才用信号发送lfnst_idx。这里,intra_mip_flag[x0][y0]是指示是否对坐标(x0,
y0)所属于的亮度块应用基于矩阵的帧内预测(mip)模式的标志。当对亮度块应用mip模式时,标志的值是1,而当不对亮度块应用mip模式时,标志的值是0。
[0398]
lfnstwidth和lfnstheight指示相对于当前编译的编译块(包括亮度编译块和色度编译块两者)应用lfnst的宽度和高度。当对编译块应用isp时,lfnstwidth和lfnstheight可以指示两个或四个分区块的每个分区块的宽度和高度。
[0399]
在以上条件中,min(lfnstwidth,lfnstheight)》=16指示只有当应用mip的块等于或大于16x16块(例如,应用mip的亮度编译块的宽度和高度都等于或大于16)时lfnst才适用。表8中包括的主要变量的含义被简要地介绍如下。
[0400]
1.cbwidth、cbheight:当前编译块的宽度和高度
[0401]
2.sps_lfnst_enabled_flag:指示lfnst是否适用的标志。当lfnst适用(启用)时,标志的值是1,而当lfnst不适用(禁用)时,标志的值是0。标志被定义在序列参数集(sps)中。
[0402]
3.cupredmode[chtype][x0][y0]:指示与chtype和位置(x0,y0)相对应的预测模式。chtype可以具有0和1的值,其中0指示亮度分量而1指示色度分量。位置(x0,y0)指示图片中的位置,具体地是当在当前图片中将左上位置设置为(0,0)时的位置。x坐标和y坐标分别从左向右并自上向下增加。作为cupredmode[chtype][x0][y0]的值,mode_intra(帧内预测)和mode_inter(帧间预测)是可能的。
[0403]
4.intrasubpartitionssplittype:指示是否对当前编译单元执行isp,并且isp_no_split指示编译单元不是分割成分区块的编译单元。isp_ver_split指示编译单元被垂直地分割,而isp_hor_split指示编译单元被水平地分割。例如,当w x h(宽度w,高度h)块被水平地分割成n个分区块时,该块被分割成w x(h/n)块,而当w x h(宽度w,高度h)块被垂直地分割成n个分区块时,该块被分割成(w/n)x h块。
[0404]
5.subwidthc、subheightc:subwidthc和subheightc是根据颜色格式(或色度格式,例如4:2:0、4:2:2或4:4:4)设置的值,并且具体地,分别表示亮度分量与色度分量之间的宽度比和高度比(参见下表)。
[0405]
[表9]
[0406]
色度格式subwidthcsubheightc单色114:2:0224:2:2214:4:4114:4:411
[0407]
6.intra_mip_flag[x0][y0]:位置(x0,y0)的内容与如上编号3相同。intra_mip_flag是指示包括在当前vvc标准中的基于矩阵的帧内预测(mip)模式是否被应用的标志。当mip模式适用(启用)时,标志的值是1,而当mip模式不适用(禁用)时,标志的值是0。
[0408]
7.numintrasubpartitions:指示在应用isp时编译单元被分割成的分区块的数目。也就是说,numintrasubpartitions指示编译单元被分割成numintrasubpartitions个分区块。
[0409]
8.lfnstdconly:对于属于当前编译单元的所有变换块,当每个最后非零系数的位
置是dc位置(即,对应变换块中的左上位置)或者不存在有效系数(即,对应cbf值为0)时,变量lfnstdconly的值是1。
[0410]
在亮度分离树或亮度双树中,可以通过仅针对编译单元中与亮度分量相对应的变换块检查以上条件来确定变量lfnstdconly的值,而在色度分离树或色度双树中,可以通过仅针对编译单元中与色度分量(cb和cr)相对应的变换块检查以上条件来确定变量lfnstdconly的值。在单树中,可以通过针对编译单元中与亮度分量和色度分量(cb和cr)相对应的所有变换块检查以上条件来确定变量lfnstdconly的值。
[0411]
9.lfnstzerooutsigcoeffflag:当应用lfnst时,lfnstzerooutsigcoeffflag在仅在可能存在有效系数的区域中存在有效系数时被设置为1,否则被设置为0。
[0412]
在4x4变换块或8x8变换块中,可以根据变换块中的扫描次序从位置(0,0)(左上)起定位直至八个有效系数,并且变换块中的剩余位置被清零。在不是4x4和8x8并且其宽度和高度等于或大于4的变换块(即,lfnst可适用的变换块)中,可以根据变换块中的扫描次序从位置(0,0)(左上)起定位最多16个有效系数(即,有效系数可以被仅定位在左上4x4块内),并且变换块中的剩余位置被清零。
[0413]
10.cidx:值0指示亮度,而值1和2分别指示色度分量cb和cr。
[0414]
11.treetype:指示单树、双树等。(single_tree:单树,dual_tree_luma:用于亮度分量的双树,dual_tree_chroma:用于色度分量的双树)
[0415]
12.tu_cbf_luma[x0][y0]:位置(x0,y0)的内容与如上编号3相同。tu_cbf_luma[x0][y0]指示用于亮度分量的编译块标志(cbf),其中0指示在用于亮度分量的对应变换块中不存在有效系数,而1指示在用于亮度分量的对应变换块中存在有效系数。
[0416]
13.lfnst_idx[x0][y0]:要解析的lfnst索引语法元素。当lfnst_idx[x0][y0]未被解析时,lfnst_idx[x0][y0]被推断为值0。也就是说,默认值0指示lfnst未被应用。
[0417]
在表8中,由于mip被仅应用于亮度分量,所以intra_mip_flag[x0][y0]是仅针对亮度分量存在的语法元素,并且可以在未被用信号发送时被推断为值0。因此,由于对色度分量来说不存在intra_mip_flag[x0][y0],所以尽管以分离树或双树的形式对色度分量进行编译,但是对色度分量来说也不单独地分配变量intra_mip_flag[x0][y0]而且不被推断为0。在表8中,当用信号发送lnfst_idx时检查(!intra_mip_flag[x0][y0]||min(lfnstwidth,lfnstheight)》=16)的条件,但是即使对色度分量来说不存在intra_mip_flag[x0][y0],也可以检查变量intra_mip_flag[x0][y0]。由于能够将lfnst应用于色度分量,所以有必要修改规范文本如下。
[0418]
[表10]
[0419]
[0420][0421][0422]
当如表10所示修改条件时,当在以分离树或双树编译中用信号发送lfnst索引时不检查mip是否被应用于色度分量。因此,可以将lfnst适当地应用于色度分量。
[0423]
如表10所示,当满足(treetype==dual_tree_chroma||!intra_mip_flag[x0]
[y0]||min(lfnstwidth,lfnstheight)》=16))的条件时,lfnst索引被用信号发送,这意味着当树类型是双树色度类型(treetype==dual_tree_chroma)、mip模式未被应用(!intra_mip_flag[x0][y0])或者被应用lfnst的块的宽度和高度中的较小者是16或更大(min(lfnstwidth,lfnstheight)》=16))时,lfnst索引被用信号发送。也就是说,当编译块是双树色度时,lfnst索引被用信号发送而不用确定mip模式是否被应用或被应用lfnst的块的宽度和高度。
[0424]
此外,以上条件可以被解释为使得当编译块不是双树色度并且mip未被应用时,lfnst索引被用信号发送,而不用确定被应用lfnst的块的宽度和高度。
[0425]
另外,以上条件可以被解释为使得当编译块不是双树色度并且mip被应用时,如果应用lfnst的块的宽度和高度中的较小者是16或更大,则用信号发送lfnst索引。
[0426]
提供以下附图以描述本公开的具体示例。因为在附图中图示的装置的特定名称或特定信号/消息/字段的名称是为了说明而提供的,所以本公开的技术特征不限于以下附图中使用的特定名称。
[0427]
图15是图示根据本公开的实施例的视频解码设备的操作的流程图。
[0428]
图15中公开的每个过程基于参考图5至图14描述的一些细节。因此,与参考图3和图5至图14描述的细节重叠的具体细节的描述将被省略或将被示意性地制作。
[0429]
根据实施例的解码设备300可以从比特流接收关于帧内预测模式、残差信息和lfnst索引的信息(s1510)。
[0430]
具体地,解码设备300可以从比特流中解码关于当前块的量化变换系数的信息,并且可以基于关于当前块的量化变换系数的信息来导出目标块的量化变换系数。关于目标块的量化变换系数的信息可以包括在序列参数集(sps)或切片报头中,并且可以包括关于是否应用rst的信息、关于缩减因子的信息、关于用于应用rst的最小变换大小的信息、关于用于应用rst的最大变换大小的信息、逆rst大小以及关于指示包括在变换集中的任何一个变换核矩阵的变换索引的信息中的至少一个。
[0431]
解码设备可以进一步接收关于当前块的帧内预测模式的信息和关于是否将isp应用于当前块的信息。解码设备可以接收并解析指示是否应用isp编译或者isp模式的标志信息,从而导出当前块是否被分割成预定数量的子分区变换块。这里,当前块可以是编译块。此外,解码设备可以通过指示当前块被分割的方向的标志信息来导出分割的子分区块的大小和数量。
[0432]
解码设备300可以通过对关于当前块的残差信息,即,量化的变换系数,进行解量化来导出变换系数(s1520)。
[0433]
导出的变换系数可以根据反向对角线扫描顺序排列在4
×
4块单元中,并且也可以根据反向对角线扫描顺序排列4
×
4块中的变换系数。也就是说,解量化的变换系数可以根据在视频编解码器中应用的反向扫描顺序排列,诸如在vvc或hevc中那样。
[0434]
解码设备可以通过将lfnst应用于变换系数来导出修改的变换系数。
[0435]
lfnst是一种不可分离变换,其中对系数应用变换而不在特定方向上分离系数,这与垂直或水平分离要变换的系数并对其进行变换的初级变换不同。此不可分离变换可以是仅对低频区域而不是块的整个区域应用正向变换的低频不可分离变换。
[0436]
lfnst索引信息作为语法信息被接收,并且语法信息作为包括0和1的二值化bin串
被接收。
[0437]
根据本实施例的lfnst索引的语法元素可以指示是否应用逆lfnst或逆不可分离变换以及包括在变换集中的任何一个变换核矩阵,并且当变换集包括两个变换核矩阵时,变换索引的语法元素可能具有三个值。
[0438]
也就是说,根据实施例,lfnst索引的语法元素的值可以包括0,其指示没有对目标块应用逆lfnst;1,其指示变换核矩阵当中的第一变换核矩阵;以及2,其指示变换核矩阵当中的第二变换核矩阵。
[0439]
可以在编译单元级别用信号发送关于帧内预测模式的信息和lfnst索引信息。
[0440]
解码设备可以基于当前块的树类型是双树色度来解析lfnst索引(s1530)。
[0441]
根据示例,当当前块的树类型是双树色度时,解码设备可以解析lfnst索引,而无论mip模式是否应用于当前块。
[0442]
当前块可以是编译块,并且当当前块在双树中编译时,当用信号发送lfnst索引时可以不检查mip是否应用于色度分量。在双树色度中,因为未应用mip,所以没有必要确定是否应用mip以便于解析lfnst索引。
[0443]
此外,当当前块的树类型是双树色度时,解码设备可以解析lfnst索引,而无论与当前块相对应的lfnst应用宽度和lfnst应用高度是否是16或更大。
[0444]
根据另一示例,当当前块的树类型不是双树色度时,解码设备可以基于mip模式未被应用于当前块来解析lfnst索引。也就是说,当当前块的树类型不是双树色度并且mip模式没有被应用于当前块时,可以解析lfnst索引。
[0445]
根据又一示例,当当前块的树类型不是双树色度并且mip模式应用于当前块时,解码设备可以基于与当前块相对应的lfnst应用宽度和lfnst应用高度是16或者更大来解析lfnst索引。
[0446]
即,当当前块不是双树色度并且应用mip模式时,当lfnst应用宽度和lfnst应用高度满足指定条件时,可以解析lfnst索引。
[0447]
当当前块被垂直分割时,与当前块对应的lfnst应用宽度被设置为当前块的宽度除以分割的子分区的数量,否则,即,当当前块没有被分割时,其被设置为当前块的宽度。
[0448]
同样,当当前块被水平分割时,与当前块对应的lfnst应用高度被设置为当前块的高度除以分割的子分区的数量,否则,即,当当前块没有被分割时,其被设置为当前块的高度。如上所述,当前块可以是编译块。
[0449]
随后,解码设备可以基于lfnst索引和用于lfnst的lfnst矩阵从变换系数导出修改的变换系数(s1540)。
[0450]
解码设备可以基于从关于帧内预测模式的信息导出的帧内预测模式来确定包括lfnst矩阵的lfnst集,并且可以基于lfnst集和lfnst索引来选择多个lfnst矩阵中的任意一个。
[0451]
这里,可以将相同的lfnst集和相同的lfnst索引应用于当前块被分割成的子分区变换块。也就是说,因为将相同的帧内预测模式应用于子分区变换块,所以基于帧内预测模式确定的lfnst集也可以同等地应用于所有子分区变换块。此外,因为lfnst索引在编译单元级别被用信号发送,所以可以将相同的lfnst矩阵应用于当前块被分割成的子分区变换块。
[0452]
如上所述,可以根据要变换的变换块的帧内预测模式来确定变换集,并且可以基于包括在由lfnst索引指示的变换集中的变换核矩阵,即,任何一个lfnst矩阵来执行逆lfnst。应用于逆lfnst的矩阵可以称为逆lfnst矩阵或lfnst矩阵,并且只要该矩阵是用于正向lfnst的矩阵的转置,就可以用任何术语来指代。
[0453]
在示例中,逆lfnst矩阵可以是非正方形矩阵,其中列数小于行数。
[0454]
解码设备可以基于修改的变换系数的初级逆变换导出当前块的残差样本(s1550)。
[0455]
这里,作为初级逆变换,可以使用传统的可分离变换,或者可以使用前述的mts。
[0456]
随后,解码设备300可以基于当前块的残差样本和当前块的预测样本来生成重构样本(s1560)。
[0457]
提供以下附图以描述本公开的具体示例。因为在附图中图示的装置的特定名称或特定信号/消息/字段的名称是为了说明而提供的,所以本公开的技术特征不限于以下附图中使用的特定名称。
[0458]
图16是图示根据本公开的实施例的视频编码设备的操作的流程图。
[0459]
图16中公开的每个过程基于参考图5至图14描述的一些细节。因此,与参考图2和图5至图14描述的细节重叠的具体细节的描述将被省略或将被示意性地制作。
[0460]
根据实施例的编码设备200可以基于应用于当前块的帧内预测模式来导出当前块的预测样本。
[0461]
当对当前块应用isp时,编码设备可以对每个子分区变换块执行预测。
[0462]
编码设备可以确定是否对当前块(即,编译块)应用isp编译或isp模式,并且可以确定当前块被分割的方向,并且可以根据确定结果导出分割的子块的大小和数量。
[0463]
相同的帧内预测模式可以应用于当前块被分割成的子分区变换块,并且编码设备可以为每个子分区变换块导出预测样本。即,编码设备根据子分区变换块的分割形式,例如,水平或垂直,或从左到右或从上到下依次执行帧内预测。对于最左边或最上面的子块,已经编译的编译块的重构像素被参考,如在传统的帧内预测方法中一样。进一步地,对于与前一个子分区变换块不相邻的后续内部子分区变换块的每一侧,为了导出与该侧相邻的参考像素,参考已经编译的相邻编译块的重构像素,如与传统的帧内预测方法中一样。
[0464]
编码设备200可以基于预测样本导出当前块的残差样本(s1610)。
[0465]
编码设备200可以通过将lfnst或mts中的至少一个应用于残差样本来导出当前块的变换系数,并且可以根据预先确定的扫描顺序排列变换系数。
[0466]
编码设备可以基于残差样本的初级变换来导出当前块的变换系数(s1620)。
[0467]
可以通过多个变换核来执行初级变换,如在mts中,在这种情况下,可以基于帧内预测模式来选择变换核。
[0468]
编码设备200可以确定是否对当前块的变换系数执行次级变换或不可分离变换,特别是lfnst,并且可以通过将lfnst应用于变换系数来导出修改的变换系数。
[0469]
lfnst是一种不可分离的变换,其中变换应用于系数而不在特定方向上分离系数,这与垂直或水平分离要变换的系数并对其进行变换的初级变换不同。此不可分离变换可以是仅对低频区域而不是要变换的整个目标块应用变换的低频不可分离变换。
[0470]
编码设备可以基于当前块的树类型来确定lfnst是否适用于当前块,并且可以基
于用于lfnst的lfnst矩阵从变换系数导出修改的变换系数(s1630)。
[0471]
根据示例,当当前块的树类型是双树色度时,编码设备可以应用lfnst,而无论mip模式是否应用于当前块。
[0472]
当前块可以是编译块,并且当当前块在双树中编译时,因为在双树色度中没有应用mip,所以在确定是否应用lfnst时没有必要确定是否应用mip。
[0473]
此外,当当前块的树类型是双树色度时,编码设备可以确定应用lfnst,而无论对应于当前块的lfnst应用宽度和lfnst应用高度是否是16或更高。
[0474]
根据另一示例,当当前块的树类型不是双树色度时,编码设备可以基于mip模式未被应用于当前块来确定应用lfnst并且可以执行lfnst。即,当当前块的树类型不是双树色度并且mip模式未被应用于当前块时,可以执行lfnst。
[0475]
根据又一示例,当当前块的树类型不是双树色度并且mip模式应用于当前块时,编码设备可以基于与当前块对应的lfnst应用宽度和lfnst应用高度为16或更大来执行lfnst。
[0476]
即,当当前块不是双树色度并且应用mip模式时,可以在lfnst应用的宽度和lfnst应用的高度满足指定条件时执行lfnst。
[0477]
当当前块垂直分割时与当前块对应的lfnst应用的宽度设置为当前块的宽度除以分割的子分区的数量,否则,即,当前块没有被分割时,设置为当前块的宽度。
[0478]
同样地,当当前块水平分割时与当前块对应的lfnst应用的高度设置为当前块的高度除以分割的子分区的数量,否则,即,当前块没有被分割时,设置为当前块的宽度。如上所述,当前块可以是编译块。
[0479]
编码设备200可以根据应用于当前块的帧内预测模式基于映射关系来确定lfnst集,并且可以基于lfnst集中包括的两个lfnst矩阵中的任何一个来执行lfnst,即,不可分离变换。
[0480]
这里,可以将相同的lfnst集和相同的lfnst索引应用于当前块被分割成的子分区变换块。也就是说,因为将相同的帧内预测模式应用于子分区变换块,所以基于帧内预测模式确定的lfnst集也可以同等地应用于所有子分区变换块。此外,因为lfnst索引由编译单元编码,所以相同的lfnst矩阵可以应用于当前块被分割成的子分区变换块。
[0481]
如上所述,可以根据要被变换的变换块的帧内预测模式来确定变换集。应用于lfnst的矩阵是用于逆lfnst的矩阵的转置。
[0482]
在示例中,lfnst矩阵可以是其中行数小于列数的非正方形矩阵。
[0483]
编码设备可以通过对当前块的修改的变换系数进行量化来导出量化的变换系数,并且可以基于当前块的树类型是双树色度对关于量化的变换系数和指示lfnst矩阵的lfnst索引的信息进行编码(s1640)。
[0484]
当在双树中对当前块进行编译时,因为在双树色度中未应用mip,所以编码设备可以对lfnst索引进行编码而不确定是否应用mip。
[0485]
当当前块的树类型是双树色度时,编码设备可以对lfnst索引进行编码,而无论与当前块对应的lfnst应用的宽度和lfnst应用的高度是否为16或更大。
[0486]
根据另一示例,当当前块的树类型不是双树色度时,编码设备可以基于mip模式未被应用于当前块来对lfnst索引进行编码。也就是说,当当前块的树类型不是双树色度并且
mip模式没有被应用于当前块时,可以对lfnst索引进行编码。
[0487]
根据又一示例,当当前块的树类型不是双树色度并且mip模式被应用于当前块时,编码设备可以基于与当前块相对应的lfnst应用的宽度和lfnst应用的高度是16或者更大对lfnst索引进行编码。
[0488]
即,当当前块不是双树色度并且应用mip模式时,当lfnst应用的宽度和lfnst应用的高度满足指定条件时,可以对lfnst索引进行编码。
[0489]
编码设备可以生成包括关于量化的变换系数的信息的残差信息。残差信息可以包括前述的变换相关信息/语法元素。编码设备可以对包括残差信息的图像/视频信息进行编码,并且可以以比特流的形式输出图像/视频信息。
[0490]
具体地,编码设备200可以生成关于量化的变换系数的信息并且可以对关于量化的变换系数的信息进行编码。
[0491]
根据本实施例的lfnst索引的语法元素可以指示是否应用(逆)lfnst和lfnst集中包括的lfnst矩阵中的任何一个,并且当lfnst集合包括两个变换核矩阵时,lfnst索引的语法元素可以具有三个值。
[0492]
根据示例,当当前块的分割的树结构是双树类型时,可以针对亮度块和色度块中的每一个对lfnst索引进行编码。
[0493]
根据实施例,变换索引的语法元素的值可以包括:0,其指示没有(逆)lfnst被应用于当前块;1,其指示lfnst矩阵当中的第一lfnst矩阵;以及2,其指示lfnst矩阵当中的第二lfnst矩阵。
[0494]
在本公开中,可以省略量化/解量化和/或变换/逆变换中的至少一个。当省略量化/解量化时,量化的变换系数可以被称为变换系数。当省略变换/逆变换时,变换系数可以被称为系数或残差系数,或者为了表达的一致性可以仍然被称为变换系数。
[0495]
此外,在本公开中,量化的变换系数和变换系数分别可以被称为变换系数和缩放的变换系数。在这种情况下,残差信息可以包括关于变换系数的信息,并且可以通过残差编译语法来发信号通知关于变换系数的信息。可以基于残差信息(或关于变换系数的信息)来导出变换系数,并且可以通过变换系数的逆变换(缩放)来导出缩放的变换系数。可以基于缩放的变换系数的逆变换(变换)来导出残差样本。也可以在本公开的其他部分中应用/表达这些细节。
[0496]
在上述实施例中,借助于一系列步骤或框来基于流程图说明方法,但是本公开不限于步骤的顺序,并且可以在与上述顺序或步骤不同的顺序或步骤中或与另一步骤同时地执行某个步骤。此外,本领域的普通技术人员可以理解,流程图所示的步骤不是排他性的,并且在不影响本公开的范围的情况下,可以并入另一步骤或者移除流程图的一个或更多个步骤。
[0497]
可以将根据本公开的上述方法实现为软件形式,并且根据本公开的编码装置和/或解码装置可以被包括在诸如tv、计算机、智能电话、机顶盒、显示装置等这样的图像处理用装置中。
[0498]
当本公开中的实施例由软件具体实现时,可以将上述方法具体体现为用于执行上述功能的模块(过程、功能等)。模块可以被存储在存储器中并且可以由处理器执行。存储器可以在处理器内部或外部并且可以以各种公知方式连接到处理器。处理器可以包括专用集
成电路(asic)、其他芯片组、逻辑电路和/或数据处理器件。存储器可以包括只读存储器(rom)、随机存取存储器(ram)、闪速存储器、存储卡、存储介质和/或其他存储器件。也就是说,可以在处理器、微处理器、控制器或芯片上具体实现和执行本公开中描述的实施例。例如,可以在计算机、处理器、微处理器、控制器或芯片上具体实现和执行每个附图所示的功能单元。
[0499]
此外,应用本公开的解码装置和编码装置可以被包括在多媒体广播收发器、移动通信终端、家庭影院视频装置、数字影院视频装置、监视相机、视频聊天装置、诸如视频通信这样的实时通信装置、移动流传输装置、存储介质、摄像机、视频点播(vod)服务提供装置、过顶(ott)视频装置、因特网流传输服务提供装置、三维(3d)视频装置、视频电话视频装置和医疗视频装置,并且可以用于处理视频信号或数据信号。例如,过顶(ott)视频装置可以包括游戏机、蓝光播放器、因特网接入tv、家庭影院系统、智能电话、平板pc、数字视频记录机(dvr)等。
[0500]
另外,应用本公开的处理方法可以以由计算机执行的程序的形式产生,并且被存储在计算机可读记录介质中。具有根据本公开的数据结构的多媒体数据也可以被存储在计算机可读记录介质中。计算机可读记录介质包括其中存储有计算机可读数据的所有种类的存储装置和分布式存储装置。计算机可读记录介质可以包括例如蓝光光盘(bd)、通用串行总线(usb)、rom、prom、eprom、eeprom、ram、cd-rom、磁带、软盘和光学数据存储装置。此外,计算机可读记录介质包括以载波(例如,通过因特网的传输)的形式具体体现的介质。另外,通过编码方法生成的比特流可以被存储在计算机可读记录介质中或者通过有线或无线通信网络发送。附加地,本公开的实施例可以通过程序代码被具体体现为计算机程序产品,并且可以通过本公开的实施例在计算机上执行程序代码。程序代码可以被存储在计算机可读载体上。
[0501]
可以以各种方式组合本文公开的权利要求。例如,能够组合本公开的方法权利要求的技术特征以在设备中被实现或执行,并且能够组合设备权利要求的技术特征以在方法中被实现或执行。此外,能够组合方法权利要求和设备权利要求的技术特征可以组合以在设备中被实现或执行,并且能够组合方法权利要求和设备权利要求的技术特征以在方法中被实现或执行。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。