一种基于dna甲基化的肿瘤分类方法
技术领域
1.本发明涉及dna甲基化分析领域,具体涉及一种基于dna甲基化的肿瘤分类算法。
背景技术:
2.甲基化数据聚类分析在机器学习中属于非监督学习的范畴,从定义上讲,聚类就是针对大量数据或者样品,根据数据本身的特性研究分类方法,并遵循这个分类方法对数据进行合理的分类,最终将相似数据分为一组,也就是“同类相同、异类相异”。对于甲基化数据,由于中枢神经系统肿瘤和软组织肉瘤是有多种类别,其dna甲基化数据必然是存在差异,不同类之间会有一定差异,通过无监督聚类分析,就能找出不同的类别从而通过结合运用来定义不同的肿瘤类别,甚至能发掘出新的肿瘤类别。
3.甲基化数据的分类是一种基本的数据挖掘方式,根据其特点,可将数据对象划分为不同的部分和类型,再进一步分析,能够进一步挖掘事物的本质。分类方法是一种对离散型随机变量建模或预测的监督学习方法。
4.其中分类学习的目的是从给定的人工标注的分类训练样本数据集中学习出一个分类函数或者分类模型,也常常称作分类器(classifier)。当新的数据到来时,可以根据这个函数进行预测,将新数据项映射到给定类别中的某一个类中。对于dna甲基化数据,设计一个针对性的分类器,当有新的甲基化数据输入时,分类器经过处理,在保证可靠性的情况下,能快速输出相应的分类结果。
5.由于甲基化数据根据探针数,分为450k,850k等等,在机器学习当中,对应的特征数是非常大的,但对应的样本数比较小,这在数据处理过程中,就涉及到了高维小样本的处理,比较适用的方法即是对特征数据进行降维处理。其次,对于分类器,其输出结果只是一个数值,并不能代表其概率,此时分类器的校准模型能够解决这一问题,通过分类器校准模型的输出,即可知道分类准确率及分类的效果评估,做到分类结果有依据,分类效果可评估。
6.因此,如何能够高效的针对基于dna甲基化的肿瘤数据进行分类,需要对算法进行优化处理和设计。
技术实现要素:
7.为了克服现有技术的上述缺陷,本发明的目的在于提供一种基于dna甲基化的神经肿瘤分类算法。
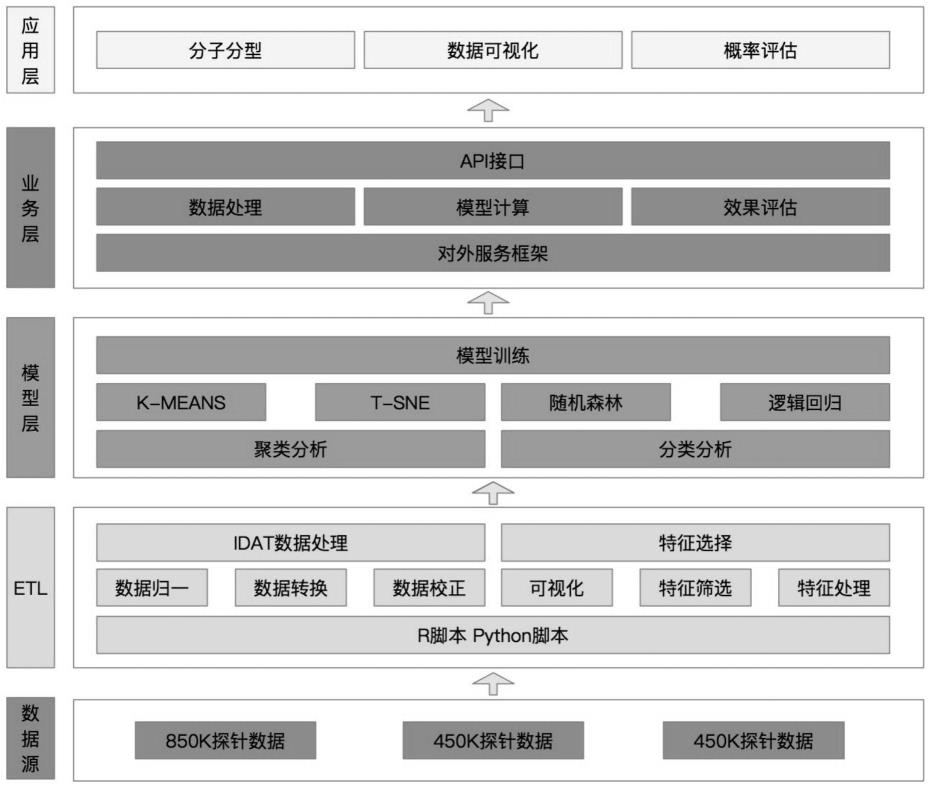
8.通过本发明的算法对甲基化数据进行分类,可以使用甲基化指纹鉴定81种肿瘤类型。同时可以应用tsne方法可视化聚类样本的结果。
9.一种基于dna甲基化的神经肿瘤分类算法,包括如下步骤:
10.甲基化数据校正处理步骤:
11.将基于dna甲基化的神经肿瘤数据运用r语言处理获取原始idat文件信号强度,通过数据校正计算,最终获取所有甲基化探针的信号值用作进一步分析;
12.甲基化数据聚类分析步骤:
13.通过无监督聚类分析k-means,对甲基化样本数据进行聚类分析,同时对聚类结果做效果评估,找出聚类分析的最优类别数;
14.后通过t-sne降维分析来展现聚类后的不同类数据;
15.甲基化数据分类分析步骤:
16.运用有监督的分类分析,建立随机森林模型,
17.后将数据集分成多个部分,进行10倍交叉验证,在每次迭代中,保留一份数据作为验证集并使用其他部分作为训练集;
18.然后使用随机森林方法训练并实现分类功能,随机森林当中采用若干节点进行分类学习;
19.高维小样本的处理步骤:
20.通过特征选择,利用校准分类器对所有特征进行排序,通过选取特征值重要性95%以上的特征集合,本质是防止模型过拟合;
21.所述的dna甲基化的神经肿瘤数据具体为850k探针数据或450k探针数据或450k探针数据。
22.在本发明的一个优选实施例中,所述的r语言处理具体是采用如下的处理步骤:
23.第一步,读取idat甲基化芯片原始数据和建立rgset对象;
24.第二步,对第一步处理后的数据进行质控过滤,过滤强度为p值小于0.05;
25.第三步,对过滤后的数据进行标准化,所述标准化具体为对探针的beta值进行校正,使得重复样本之间的beta值分布更加的接近,减少重复样本间的差异;采用minif包中的preprocessswan()函数进行归一化;
26.第四步,对标准化后的数据进行过滤去掉重复数据和去除x染色体甲基化和y染色体甲基化数据;
27.第五步,将第四步当中进行数据去除后的数据输出形成数据矩阵。
28.在本发明的一个优选实施例中,所述数据校正计算的处理方式具体为
29.应用r语言中minif包中的归一化函数进行背景降噪和归一化处理。
30.在本发明的一个优选实施例中,所述无监督聚类分析k-means,对甲基化样本数据进行聚类分析具体为:
31.步骤s1,在样本集中随机选取91个样本点作为均值的初始点;
32.步骤s2,计算每个样本和每个均值点之间的欧式距离;
33.步骤s3,将样本划入距离最近的均值点所在的簇;
34.步骤s4,计算所有簇内样本的平均值,将计算后的平均值作为更新后的均值点;
35.步骤s5,重复步骤s2-4至聚类中心不再变化得到该簇的数据;
36.步骤s6,获得最终91个簇的数据即完成聚类分析。
37.在本发明的一个优选实施例中,所述效果评估为采用如下指标1-3进行评估:
38.指标1为inertias指标,所述inertias指标指的是k-means模型对象的属性,它作为没有真实分类结果标签下的非监督式评估指标,用于表示样本到最近的聚类中心的距离总和;
39.所述inertias的数值越小越好,越小表示样本在类间的分布越集中;
40.指标2为兰德系数指标,所述兰德系数指标用c表示实际的类别划分,k表示聚类结果;
41.定义a为在c中被划分为同一类,在k中被划分为同一簇的实例对数量;定义b为在c中被划分为不同类别,在k中被划分为不同簇的实例对数量;定义n为实例总数,则兰德系数ri=2(a b)/n*(n-1);
42.指标3为互信息指标,所述互信息指标指的是相同数据的两个标签之间的相似度,即也是在衡量两个数据分布的相似程度;
43.利用互信息来衡量聚类效果需要知道实际类别信息。
44.在本发明的一个优选实施例中,所述t-sne降维分析的处理方式为使用对称版的sne来简化梯度公式;所述梯度公式为梯度grad公式;
45.在低维空间下,使用t分布替代高斯分布表达两点之间的相似度。
46.在本发明的一个优选实施例中,所述数据集分成10个部分,随机森林采用10000个节点进行分类学习。
47.在本发明的一个优选实施例中,所述校准分类器具体是把分类的结果作为新的训练集,用逻辑回归再训练一个关系,得到具体的概率值,不同肿瘤类型校准分数不同,应用概率值后可反应结果的可信度;
48.应用sigmoid函数对校准分数进行正则化处理,使得分类结果既有校准分数同时有概率值后输出结果。
49.在本发明的一个优选实施例中,所述逻辑回归为多分类模型,由条件概率分布p(y|x)表示,形式为参数话的逻辑回归;
50.随机变量x取实数,随机变量y取0或1;
51.通过监督学习方法估计模型参数:p(y=1|x)=exp(w*x b)/1 exp(w*x b)。
52.本发明的有益效果在于:
53.本发明在应用于基于dna甲基化的肿瘤分类算法当中的准确率比传统的svm(支持向量机)、逻辑回归和决策树方法均要高。
54.本发明的特点可参阅本案图式及以下较好实施方式的详细说明而获得清楚地了解。
附图说明
55.图1为本发明的原理示意图。
具体实施方式
56.为使本发明的目的、技术方案和优点更加清楚明了,下面通过附图及实施例,对本发明进行进一步详细说明。但是应该理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限制本发明的范围。此外,在以下结构中,省略了对公知结构和技术的描述,以避免不必要的混淆本发明的概念。
57.首先在数据预处理部分,本实施例执行以下步骤:
58.步骤1,数据提取:从geo数据下载编号为gse109381的甲基化数据。
59.步骤2,探针筛选:去除x,y染色体上的探针,去除850k中不存在的探针。最后剩余
428,799个甲基化探针。
60.其次在模型训练部分,本实施例执行以下步骤:
61.步骤3,只关注筛选后的探针对应的探针值,将原始训练数据作为向量x,并将向量x以8:2的比例划分为训练集向量和测试集向量。同样地,将原始训练数据对应的类别向量y做相同的操作,得到训练集y和测试集y。
62.步骤4,将向量x及其对应的类别标签向量y输入由n(实现时,设置n=10000)个决策树组成的随机森林模型中。模型随机对输入训练样本进行有放回的采样,得到n组训练数据。决策树为1000个时,准确率79%,决策树为2000个时,准确率为82%;决策树为5000个时,准确率为92%;决策树为10000个时,准确率为98.1%。
63.步骤5,对步骤2中的n组训练数据,训练得到n个不同的分类器(决策树)。将n个分类器对样本预测的类别概率进行平均,可以得到样本的类别预测向量p。
64.步骤6,为使得类别预测概率p的值能反映模型预测的信心,使用基于platt的sigmoid校准器对概率p进行校准操作得到校准后概率p。
65.最后在模型测试部分,本实施例执行以下步骤:
66.步骤7,参考数据预处理部分的方法,处理测试集数据,得到其对应测试集向量x。
67.步骤8,将测试集向量x输入模型和概率校准器,得到对应输入测试样本的概率预测结果,选择其中概率最大的类别作为模型的输出类别;
68.并将输出类别对应的预测概率值作为记录模型参考分数score。参考分数大于0.9被认为结果可信。
69.本发明方法与其他方法比较结果如表1所示:
70.算法准确率本发明方法98.1%svm(支持向量机)93.5%逻辑回归85.6%决策树90.4%
71.以上显示和描述了发明的基本原理和主要特征和本发明的优点。
72.本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内,本发明要求保护范围由所附的权利要求书及其等效物界定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。