技术特征:
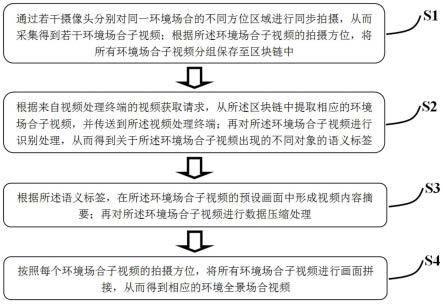
1.基于深度学习的自动化视频摘要生成方法,其特征在于,其包括如下步骤:步骤s1,通过若干摄像头分别对同一环境场合的不同方位区域进行同步拍摄,从而采集得到若干环境场合子视频;根据所述环境场合子视频的拍摄方位,将所有环境场合子视频分组保存至区块链中;步骤s2,根据来自视频处理终端的视频获取请求,从所述区块链中提取相应的环境场合子视频,并传送到所述视频处理终端;再对所述环境场合子视频进行识别处理,从而得到关于所述环境场合子视频出现的不同对象的语义标签;步骤s3,根据所述语义标签,在所述环境场合子视频的预设画面中形成视频内容摘要;再对所述环境场合子视频进行数据压缩处理;步骤s4,按照每个环境场合子视频的拍摄方位,将所有环境场合子视频进行画面拼接,从而得到相应的环境全景场合视频。2.如权利要求1所述的基于深度学习的自动化视频摘要生成方法,其特征在于:在所述步骤s1中,通过若干摄像头分别对同一环境场合的不同方位区域进行同步拍摄,从而采集得到若干环境场合子视频具体包括:将若干摄像头的摄像方向分别对准同一环境场合沿周向方向的不同方位区域,同时调整每个摄像头的拍摄视场角,使得所有摄像头的整体拍摄视场角能够完全覆盖所述环境场合的整体周向方位区域;再指示所有摄像头以相同焦距进行同步拍摄,从而采集得到若干环境场合子视频。3.如权利要求2所述的基于深度学习的自动化视频摘要生成方法,其特征在于:在所述步骤s1中,根据所述环境场合子视频的拍摄方位,将所有环境场合子视频分组保存至区块链中具体包括:获取每个摄像头的拍摄方位信息,将所述拍摄方位信息作为视频索引信息添加至相应的环境场合子视频中;再将所有环境场合子视频分组保存至区块链中。4.如权利要求3所述的基于深度学习的自动化视频摘要生成方法,其特征在于:在所述步骤s2中,根据来自视频处理终端的视频获取请求,从所述区块链中提取相应的环境场合子视频,并传送到所述视频处理终端具体包括:从来自视频处理终端的视频获取请求中提取相应的视频拍摄时间范围条件,再从所述区块链中提取得到与所述视频拍摄时间范围相匹配的环境场合子视频;再提取得到的所有环境场合子视频同步传送到所述视频处理终端。5.如权利要求4所述的基于深度学习的自动化视频摘要生成方法,其特征在于:在所述步骤s2中,对所述环境场合子视频进行识别处理,从而得到关于所述环境场合子视频出现的不同对象的语义标签具体包括:按照所述环境场合子视频的视频流时间轴顺序,将所述环境场合子视频分解为若干环境场合图片帧;对每个环境场合图片帧进行识别处理,从而得到所述环境场合图片帧初选的不同对象的身份属性信息和动作属性信息;根据所述身份属性信息和所述动作属性信息,生成关于所述对象的身份属性语义标签和动作属性语义标签。6.如权利要求5所述的基于深度学习的自动化视频摘要生成方法,其特征在于:
在所述步骤s3中,根据所述语义标签,在所述环境场合子视频的预设画面中形成视频内容摘要具体包括:根据所述身份属性语义标签和所述动作属性语义标签,生成关于所述对象的身份状态和动作状态的文字摘要;在所述对象出现的环境场合图片帧中选定预定的摘要添加画面区域,其中所述摘要添加画面区域与所述对象在所述环境场合图片帧中的出现画面区域不重叠;将所述文字摘要添加到所述摘要添加画面区域后,将所述文字摘要进行自字体放大显示。7.如权利要求6所述的基于深度学习的自动化视频摘要生成方法,其特征在于:在所述步骤s3中,对所述环境场合子视频进行数据压缩处理具体包括:按照所述环境场合子视频的视频流时间轴顺序,将所有环境场合图片帧依次重新组合后得到环境场合子视频,再对所述环境场合子视频进行保真压缩处理。8.如权利要求7所述的基于深度学习的自动化视频摘要生成方法,其特征在于:在所述步骤s3中,对所述环境场合子视频进行保真压缩处理具体包括:步骤s301,利用下面公式(1),根据所述环境场合子视频筛选出所述视频的保真压缩像素值,在上述公式(1)中,l表示所述环境场合子视频的保真压缩像素值;l
a
(i,j)表示所述环境场合子视频第a帧图像的第i行第j列像素点的像素值;m表示所述环境场合子视频的每一帧图像的每一行像素点个数;n表示所述环境场合子视频的每一帧图像的每一列像素点个数;表示将i的值从1取值到n,将j的值从1取值到m得到括号内的最小值;g表示所述环境场合子视频的总帧数;表示将a的值从1取值到g得到括号内的最小值;;步骤s302,利用下面公式(2),根据所述保真压缩像素值对所述环境场合子视频进行保真压缩处理,在上述公式(2)中,表示对所述环境场合子视频进行保真压缩后的第a帧图像的像素数据(数据为像素矩阵形式);表示将i的值从1取值到n,将j的值从1取值到m代入到括号内进行所有计算;步骤s303,利用下面公式(3),根据压缩后的所述环境场合子视频数据判断所述压缩是否为有效压缩,并控制压缩后的数据是否需要进行还原,在上述公式(3)中,y表示数据的还原控制值;h()表示求取括号内数据的数据量;若y=1,表示进行保真压缩后的所述环境场合子视频需要进行还原;
若y=0,表示进行保真压缩后的所述环境场合子视频不需要进行还原。9.如权利要求7所述的基于深度学习的自动化视频摘要生成方法,其特征在于:在所述步骤s4中,按照每个环境场合子视频的拍摄方位,将所有环境场合子视频进行画面拼接,从而得到相应的环境全景场合视频具体包括:按照每个环境场合子视频的拍摄方位以及每个环境场合子视频的拍摄时间轴,将所有环境场合子视频进行画面无缝拼接,从而得到相应的环境全景场合视频。
技术总结
本发明提供了基于深度学习的自动化视频摘要生成方法,其对同一环境场合的不同方位区域进行同步拍摄,得到若干环境场合子视频;对环境场合子视频进行识别处理,得到关于环境场合子视频出现的不同对象的语义标签,继而在环境场合子视频的预设画面中形成视频内容摘要;最后按照每个环境场合子视频的拍摄方位,将所有环境场合子视频进行画面拼接,从而得到相应的环境全景场合视频,这样可对不同摄像头拍摄的环境场合子视频进行同步识别分析,对环境场合子视频中的对象进行标定,并生成相匹配的视频内容摘要,从而对视频进行全面和准确的筛选识别,提高对视频识别处理的自动化和智能化程度。度。度。
技术研发人员:兰雨晴 唐霆岳 余丹 邢智涣 王丹星 黄永琢
受保护的技术使用者:慧之安信息技术股份有限公司
技术研发日:2022.03.31
技术公布日:2022/7/5
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。