1.本发明涉及数据监控技术领域,尤其是一种基于综合监控管理的数据监控方法及系统。
背景技术:
2.随着互联网行业的快速发展,为了保证数据的完整性、正确性和安全性对输入数据进行监控和校验,其是互联网技术中对系统和用户数据安全的一种重要的手段。现有的数据监控框架大多都是通过主备库的方式进行数据备份和校验。这样不仅成倍数地增加了存储容量,并且每次数据校验都要耗费大量资源。
技术实现要素:
3.本发明的目的是通过提出一种基于综合监控管理的数据监控方法及系统,以解决上述背景技术中提出的缺陷。
4.本发明采用的技术方案如下:
5.提供一种基于综合监控管理的数据监控方法,包括如下步骤:
6.根据预设时间段随机抓取目标时间段内即将存入标准数据库的数据,将目标时间段内的数据根据时间段长度进行等分,存入监控数据库的分布式存储数据格,按照初次存入的时间段对各个存储数据格内的数据打上时间节点标签,在下一个预设时间段开始前对通过分布式存储数据格中时间节点标签对应标准数据库进行匹配,若匹配失败,则定位到标准数据库中对应数据的位置进行数据校验。
7.作为本发明的一种优选技术方案:所述随机抓取目标时间段内即将存入标准数据库的数据采用以下原则,对存入标准数据库的数据进行起始点标记和终止点标记,通过所述起始点标记和终止点标记计算数据存入时间,若数据存入时间落入存入时间阈值范围内,则对该数据和其间隔段的数据进行抓取。
8.作为本发明的一种优选技术方案:所述对该数据随机间隔段的数据进行抓取为对当前抓取数据前后间隔的数据进行抓取,其中,t
δ
为当前存入标准数据库的数据与上一个存入标准数据库的时间的间隔时间,t
l
为当前数据存入时间,n为目标时间段内当前存入数据的数量。
9.作为本发明的一种优选技术方案:所述在下一个预设时间段开始前对通过分布式存储数据格中时间节点标签对应标准数据库进行匹配具体通过如下公式进行匹配:
[0010][0011]
其中,si表示第i个时间节点,α指的是每个时间段内的存储数据格内的数据样本,p表示数据格的数量,q表示的是数据根据时间段长度等分的数量。
[0012]
作为本发明的一种优选技术方案:还包括根据匹配不成功的数据进行前后时间节
点定位,在标准数据库中定位到前后时间节点之间的数据,将该段数据进行删除,并从数据输入历史记录中重新调取数据对删除的数据进行补充,补充完成后再次通过分布式存储数据格中时间节点标签对应标准数据库进行匹配。
[0013]
作为本发明的一种优选技术方案:所述输入历史记录为当前预设时间段数据存入标准数据库之前存储在本地的临时数据,在下一个预设时间段开始后进行清零。
[0014]
一种基于综合监控管理的数据监控系统,包括标准数据库和监控数据库,所述监控数据库包括若干分布式存储数据格,所述标准数据库用于存储服务器的数据,所述监控数据库用于通过分布式数据格分别存储输入的监控数据段。
[0015]
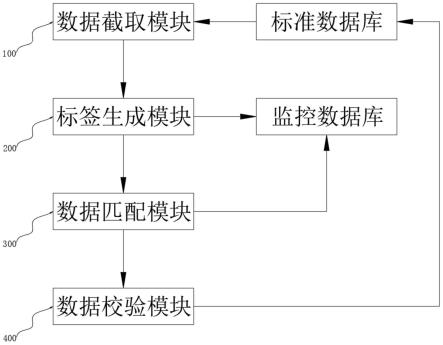
作为本发明的一种优选技术方案:还包括数据截取模块、标签生成模块、数据匹配模块和数据校验模块,所述数据截取模块用于根据预设时间段随机抓取目标时间段内即将存入标准数据库的数据,将目标时间段内的数据根据时间段长度进行等分,存入监控数据库的分布式存储数据格,所述标签生成模块用于按照初次存入的时间段对各个存储数据格内的数据打上时间节点标签,所述数据匹配模块用于在下一个预设时间段开始前对通过分布式存储数据格中时间节点标签对应标准数据库进行匹配,所述数据校验模块用于在数据匹配模块匹配任务失败时定位到标准数据库中对应数据的位置进行数据校验。
[0016]
作为本发明的一种优选技术方案:所述数据截取模块包括数据标记单元和截取判断单元,所述数据标记单元用于对存入标准数据库的数据进行起始点标记和终止点标记,所述截取判断单元用于通过所述起始点标记和终止点标记计算数据存入时间,若数据存入时间落入存入时间阈值范围内,则对该数据和其间隔段的数据进行抓取。
[0017]
作为本发明的一种优选技术方案:所述数据校验模块包括数据定位单元和数据处理单元,所述数据定位单元根据匹配不成功的数据进行前后时间节点定位,在标准数据库中定位到前后时间节点之间的数据,所述数据处理单元用于将所述数据定位单元定位到的数据进行删除,并从数据输入历史记录中重新调取数据对删除的数据进行补充。
[0018]
本发明提供的基于综合监控管理的数据监控方法及系统,本发明根据每种不同类型的数据必然会有易传输出错的字节长度,来进行选定存入时间阈值范围,以通过其来判断出数据段的字节长度。这样能够选定一些易传输出错的数据来进行监测。其次通过数据的字节长度越大且与上一个存入数据的时间越长,抓取的间隔就越小,而反之抓取的间隔越大。保证了当前时间段传输的数据越密集,就相应的扩大抓取间隔,确保抓取的数据分布范围足够广,这样才能够具有足够的覆盖性,通过临时存储在服务器内存中的数据来替换校验出错的数据,则能够实时保证数据的完整度和精确度,同时占用资源小。
附图说明
[0019]
图1为本发明优选实施例的整体系统架构图;
[0020]
图2为本发明优选实施例中数据截取模块的模块图;
[0021]
图3为本发明优选实施例中数据校验模块的模块图。
[0022]
图中各个标记的意义为:
[0023]
100、数据截取模块;101、数据标记单元;102、截取判断单元;200、标签生成模块;300、数据匹配模块;400、数据校验模块;401、数据定位单元;402、数据处理单元。
具体实施方式
[0024]
需要说明的是,在不冲突的情况下,本实施例中的实施例及实施例中的特征可以相互组合,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0025]
参照图1-3,本发明优选实施例提供了一种基于综合监控管理的数据监控方法及系统,包括如下步骤:
[0026]
根据预设时间段随机抓取目标时间段内即将存入标准数据库的数据,将目标时间段内的数据根据时间段长度进行等分,存入监控数据库的分布式存储数据格,按照初次存入的时间段对各个存储数据格内的数据打上时间节点标签,在下一个预设时间段开始前对通过分布式存储数据格中时间节点标签对应标准数据库进行匹配,若匹配失败,则定位到标准数据库中对应数据的位置进行数据校验。
[0027]
具体的,随机抓取目标时间段内即将存入标准数据库的数据采用以下原则,对存入标准数据库的数据进行起始点标记和终止点标记,通过所述起始点标记和终止点标记计算数据存入时间,若数据存入时间落入存入时间阈值范围内,则对该数据和其间隔段的数据进行抓取。其中,存入时间阈值范围可根据不同的数据类型,通过机器学习算法训练出一个合理的时间阈值范围,因服务器在进行数据传输过程中,每种不同类型的数据必然会有易传输出错的字节长度,存入时间阈值范围的选定即是根据该原理来进行选定,不同的数据字节长度其传输时间也必然不同,所以,选定时间阈值范围的实际作用是通过其来判断出数据段的字节长度。这样能够选定一些易传输出错的数据来进行监测。
[0028]
除此之外,对该数据随机间隔段的数据进行抓取为对当前抓取数据前后间隔的数据进行抓取,其中,t
δ
为当前存入标准数据库的数据与上一个存入标准数据库的时间的间隔时间,t
l
为当前数据存入时间,n为目标时间段内当前存入数据的数量。通过数据的字节长度越大且与上一个存入数据的时间越长,那么抓取的间隔就越小,而反之抓取的间隔越大。主要是保证当前时间段传输的数据越密集,那么相应的扩大抓取间隔,确保抓取的数据分布范围足够广,这样才能够具有足够的覆盖性。
[0029]
在下一个预设时间段开始前对通过分布式存储数据格中时间节点标签对应标准数据库进行匹配具体通过如下公式进行匹配:
[0030][0031]
其中,si表示第i个时间节点,α指的是每个时间段内的存储数据格内的数据样本,p表示数据格的数量,q表示的是数据根据时间段长度等分的数量。通过这种矩阵式的匹配方式,能够有效提高鲁棒性。
[0032]
还包括根据匹配不成功的数据进行前后时间节点定位,在标准数据库中定位到前后时间节点之间的数据,将该段数据进行删除,并从数据输入历史记录中重新调取数据对删除的数据进行补充,补充完成后再次通过分布式存储数据格中时间节点标签对应标准数
据库进行匹配。输入历史记录为当前预设时间段数据存入标准数据库之前存储在本地的临时数据,在下一个预设时间段开始后进行清零。输入历史记录存储在服务器的内存中,即为临时存储文件,在下一个时间段开始前及时将其清理,既能够保证数据有误时及时对标准数据库进行校正,也能够保证其不占用数据库的内存资源。
[0033]
标准数据库和监控数据库,监控数据库包括若干分布式存储数据格,标准数据库用于存储服务器的数据,监控数据库用于通过分布式数据格分别存储输入的监控数据段。还包括数据截取模块100、标签生成模块200、数据匹配模块300和数据校验模块400,数据截取模块100用于根据预设时间段随机抓取目标时间段内即将存入标准数据库的数据,将目标时间段内的数据根据时间段长度进行等分,存入监控数据库的分布式存储数据格,标签生成模块200用于按照初次存入的时间段对各个存储数据格内的数据打上时间节点标签,数据匹配模块300用于在下一个预设时间段开始前对通过分布式存储数据格中时间节点标签对应标准数据库进行匹配,数据校验模块400用于在数据匹配模块300匹配任务失败时定位到标准数据库中对应数据的位置进行数据校验。数据截取模块100包括数据标记单元101和截取判断单元102,数据标记单元101用于对存入标准数据库的数据进行起始点标记和终止点标记,截取判断单元102用于通过起始点标记和终止点标记计算数据存入时间,若数据存入时间落入存入时间阈值范围内,则对该数据和其间隔段的数据进行抓取。数据校验模块400包括数据定位单元401和数据处理单元402,数据定位单元401根据匹配不成功的数据进行前后时间节点定位,在标准数据库中定位到前后时间节点之间的数据,数据处理单元402用于将数据定位单元401定位到的数据进行删除,并从数据输入历史记录中重新调取数据对删除的数据进行补充。
[0034]
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
[0035]
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。