1.本发明涉及一种非机动车违规行为检测方法,尤其是一种融合注意力机制的非机动车违规行为检测方法。
背景技术:
2.目前对非机动车违规行为检测的研究工作相对较少,其主要工作流程包括目标检测和目标跟踪。
3.对目标检测而言,根据网络结构的不同大致可划分为两类:基于候选区域的算法和基于回归的算法,基于候选区域的类算法通过设置候选区域进行特征提取,主要包括r-cnn、fast r-cnn、faster r-cnn等算法,但由于每个候选区域都需要进行卷积操作,导致运行速度慢;基于回归的算法以ssd系列和yolo系列算法为代表,不生成候选区域,直接对提取到的特征进行类别预测和位置回归,提高了检测的运行效率,其中yolov5的主干网络选用csp1_x结构,缓解了大量推理计算问题,不仅减轻了模型的计算量而且保证了对目标检测的精度,并且yolov5采用了fpn pan的结构用来传递深层语义特征和浅层位置信息,进一步提高了模型的检测精度,取得了优异的检测效果,但是yolov5算法对微小目标的特征提取尚有待改进,在实际检测中仍存在定位不准、漏检、误检等问题。
4.对目标跟踪而言,主流算法是基于匈牙利算法的后端跟踪优化算法,主要包括sort和deepsort算法,其中,sort算法将检测到的目标状态传播到未来帧中,将当前检测与现有目标相关联,管理跟踪目标的生命周期;deepsort算法在sort算法的基础上加入了外观信息以实现较长时间遮挡的目标跟踪,但由于基于匈牙利算法的后端跟踪优化算法的跟踪效果依赖于目标检测器的准确率和特征区分的程度,对微小目标以及密集目标的漏检率相对较高。
技术实现要素:
5.本发明所要解决的技术问题是提供一种融合注意力机制的非机动车违规行为检测方法,不但提高了对微小目标的检测率,而且提高了检测的准确率。
6.本发明解决上述技术问题所采用的技术方案为:一种融合注意力机制的非机动车违规行为检测方法,包括以下步骤:
①
预设非机动车辆违规行为数据库,所述的非机动车辆违规行为数据库包括未戴头盔行驶、载人行驶和逆向行驶,通过路面监控摄像头采集含有非机动车辆行驶的图像并建立样本数据集,对样本数据集进行预处理的得到预处理后的样本数据集,对预处理后的样本数据集进行人工标注并得到标注信息;
②
通过在yolov5网络中加入se注意力机制和transformer注意力机制构建得到目标检测网络,设置训练参数,将人工标注后的样本数据集输入至目标检测网络中进行训练,得到目标检测器;
③
将待检测的视频流输入到目标检测器中并从第一帧开始逐帧进行目标检测,得
到检测目标的位置信息;
④
将检测目标的位置信息输入到deepsort跟踪器中进行目标跟踪,得到检测目标的id和运动轨迹;
⑤
根据由步骤
③
得到的检测目标的位置信息以及由步骤
④
得到的检测目标的id和运动轨迹,使用预设的非机动车辆违规行为数据库检测当前帧中是否存在违规行为,若是,则输出检测结果;若否,则执行步骤
⑥
;
⑥
判断当前帧是否为待检测的视频流的最后一帧,若否,则将下一帧作为当前帧并返回执行步骤
⑤
;若是,则结束。
7.所述的步骤
①
中对预处理后的样本数据集进行人工标注并得到标注信息的具体过程如下:利用label img标注工具对样本数据集中的每张非机动车辆图像中的各个需要检测的检测目标进行标注,得到并保存标注信息;所述的标注信息包括标注框的四个顶点坐标信息以及标注框的类别信息;所述的检测目标包括头、头盔、二轮车和三轮车。
8.所述的步骤
③
中,所述的位置信息包括检测框的中心点坐标信息、四个顶点坐标信息和类别信息。
9.所述的步骤
⑤
中使用预设的非机动车辆违规行为数据库检测当前帧中是否存在违规行为的具体过程如下:
⑤‑
1判断当前帧中的检测目标的检测框的类别信息是否有非机动车辆,所述的非机动车辆包括二轮车和三轮车,若否,则返回步骤
③
;若是,则执行步骤
⑤‑
2;
⑤‑
2判断当前帧是否为待检测的视频流的第一帧,若是,则执行步骤
⑤‑
5;若否,则执行步骤
⑤‑
3;
⑤‑
3判断该非机动车辆在当前帧和上一帧的id是否一致,若否,则执行步骤
⑥
;若是,则执行步骤
⑤‑
4;
⑤‑
4判断该非机动车辆在当前帧和上一帧的运动轨迹是否符合正常行驶时的交通规则,若否,则当前帧中存在逆向行驶的违规行为;若是,则执行步骤
⑤‑
5;所述的正常行驶时的交通规则具体参照城市交通规则;
⑤‑
5判断该非机动车辆的检测框内是否有检测框的类别信息为头,且头的检测框的四个顶点坐标信息在该非机动车辆的检测框的中心点坐标信息上方,若是,则执行步骤
⑤‑
6;若否,则执行步骤
⑤‑
7;
⑤‑
6判断是否有超过一个的检测框的类别信息为头,若是,则当前帧中存在载人行驶的违规行为;若否,则当前帧中存在未戴头盔行驶的违规行为;
⑤‑
7判断该非机动车辆的检测框内是否有检测框的类别信息为头盔,且头盔的检测框的四个顶点坐标信息在该非机动车辆的检测框的中心点坐标信息上方,若否,则执行步骤
⑥
;若是,则执行步骤
⑤‑
8;
⑤‑
8判断是否有超过一个的检测框的类别信息为头盔,若否,则当前帧为正常行驶,执行步骤
⑥
;若是,则当前帧中存在载人行驶的违规行为。
10.所述的步骤
①
中,所述的样本数据集包括至少2500张未戴头盔行驶的非机动车辆图像、至少2500张载人行驶的非机动车辆图像、至少2500张逆向行驶的非机动车辆图像和至少2500张正常行驶的非机动车辆图像。
11.所述的步骤
①
中所述的预处理为对所述的样本数据集中每张非机动车辆图像进
行亮度调整扩充样本数据集。
12.所述的步骤
①
之后还包括,调整所述的训练集和所述的验证集中的所有图像至统一大小。
13.所述的步骤
②
中的目标检测网络的具体构成包括:在yolov5网络的第八卷积层加入se注意力机制来增强有用特征提取,在yolov5网络的第十一卷积层加入transformer注意力机制来增强全局特征提取。
14.所述的步骤
②
中训练参数的设置为:batch_size为8,迭代次数为300,batch_size是指批处理参数,其极限值为样本数据集的总数。
15.所述的步骤
④
中,通过所述的deepsort跟踪器中的卡尔曼滤波预测目标的运动轨迹,通过所述的deepsort跟踪器中的匈牙利算法生成目标的id并将目标的id与目标的运动轨迹相对应。
16.与现有技术相比,本发明的优点在于可以对密集场景下头、头盔、二轮车、三轮车进行准确检测和跟踪,并进一步完成违规行为的实时识别,针对密集场景,在原yolov5网络中引入transformer注意力机制,强化了对全局特征的提取能力,进而提升不同尺度的检测目标的检测准确率和定位能力,同时,在原yolov5网络中加入se注意力机制,在提取的全局特征中保留有用特征,丰富了微小的检测目标的局部特征,并进一步融合提取的全局特征和局部特征,优化目标跟踪的idswith问题;本发明对微小目标的检测准确率明显提高,同时本发明的idswith明显下降,在实际应用场景中可实时准确地识别未戴头盔、违规载人、逆向行驶等违规行为,具有良好的实用价值。
附图说明
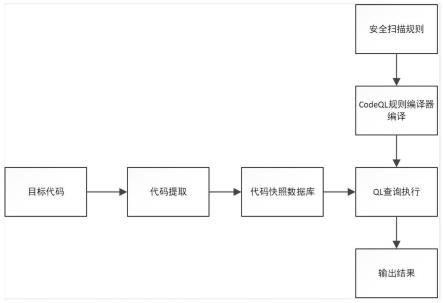
17.图1为本发明的整体流程示意图;图2为本实施例中的步骤
⑥
的流程示意图;图3为本发明的目标检测网络的网络结构示意图;图4(a)为本实施例中的部分预处理前的非机动车辆图像;图4(b)为本实施例中的部分预处理后的非机动车辆图像;图5(a)~图5(c)为未使用本发明的方法对实地采集的道路交通视频进行检测的部分结果示意图片;图5(d)~图5(f)为使用本发明的方法对实地采集的道路交通视频进行检测的部分结果示意图片。
具体实施方式
18.以下结合附图实施例对本发明作进一步详细描述。
19.如图1所示,一种融合注意力机制的非机动车违规行为检测方法,包括以下步骤:
①
预设非机动车辆违规行为数据库,所述的非机动车辆违规行为数据库包括未戴头盔行驶、载人行驶和逆向行驶,通过路面监控摄像头采集含有非机动车辆行驶的图像并建立样本数据集,对样本数据集进行预处理的得到预处理后的样本数据集,对预处理后的样本数据集进行人工标注并得到标注信息;步骤
①
中对预处理后的样本数据集进行人工标注并得到标注信息的具体过程如
下:利用label img标注工具对样本数据集中的每张非机动车辆图像中的各个需要检测的检测目标进行标注,得到并保存标注信息;标注信息包括标注框的四个顶点坐标信息以及标注框的类别信息;检测目标包括头、头盔、二轮车和三轮车;步骤
①
中,样本数据集包括至少2500张未戴头盔行驶的非机动车辆图像、至少2500张载人行驶的非机动车辆图像、至少2500张逆向行驶的非机动车辆图像和至少2500张正常行驶的非机动车辆图像;步骤
①
中预处理为对样本数据集中每张非机动车辆图像进行亮度调整扩充样本数据集;步骤
①
之后还包括,调整训练集和验证集中的所有图像至统一大小;
②
通过在yolov5网络中加入se(squeeze-and-excitation)注意力机制和transformer注意力机制构建得到目标检测网络,设置训练参数,将人工标注后的样本数据集输入至目标检测网络中进行训练,得到目标检测器;步骤
②
中的目标检测网络的具体构成包括:在yolov5网络的第八卷积层加入se注意力机制来增强有用特征提取,在yolov5网络的第十一卷积层加入transformer注意力机制来增强全局特征提取;步骤
②
中训练参数的设置为:batch_size为8,迭代次数为300,batch_size是指批处理参数,其极限值为样本数据集的总数;
③
将待检测的视频流输入到目标检测器中并从第一帧开始逐帧进行目标检测,得到检测目标的位置信息;位置信息包括检测框的中心点坐标信息、四个顶点坐标信息和类别信息;
④
将检测目标的位置信息输入到deepsort跟踪器中进行目标跟踪,得到检测目标的id和运动轨迹;步骤
④
中,通过deepsort跟踪器中的卡尔曼滤波预测目标的运动轨迹,通过deepsort跟踪器中的匈牙利算法生成目标的id并将目标的id与目标的运动轨迹相对应;
⑤
根据由步骤
③
得到的检测目标的位置信息以及由步骤
④
得到的检测目标的id和运动轨迹,使用预设的非机动车辆违规行为数据库检测当前帧中是否存在违规行为,若是,则输出检测结果;若否,则执行步骤
⑥
;如图2所示,使用预设的非机动车辆违规行为数据库检测当前帧中是否存在违规行为的具体过程如下:
⑤‑
1判断当前帧中的检测目标的检测框的类别信息是否有非机动车辆,所述的非机动车辆包括二轮车和三轮车,若否,则返回步骤
③
;若是,则执行步骤
⑤‑
2;
⑤‑
2判断当前帧是否为待检测的视频流的第一帧,若是,则执行步骤
⑤‑
5;若否,则执行步骤
⑤‑
3;
⑤‑
3判断该非机动车辆在当前帧和上一帧的id是否一致,若否,则执行步骤
⑥
;若是,则执行步骤
⑤‑
4;
⑤‑
4判断该非机动车辆在当前帧和上一帧的运动轨迹是否符合正常行驶时的交通规则,若否,则当前帧中存在逆向行驶的违规行为;若是,则执行步骤
⑤‑
5;所述的正常行驶时的交通规则具体参照城市交通规则;
⑤‑
5判断该非机动车辆的检测框内是否有检测框的类别信息为头,且头的检测框
的四个顶点坐标信息在该非机动车辆的检测框的中心点坐标信息上方,若是,则执行步骤
⑤‑
6;若否,则执行步骤
⑤‑
7;
⑤‑
6判断是否有超过一个的检测框的类别信息为头,若是,则当前帧中存在载人行驶的违规行为;若否,则当前帧中存在未戴头盔行驶的违规行为;
⑤‑
7判断该非机动车辆的检测框内是否有检测框的类别信息为头盔,且头盔的检测框的四个顶点坐标信息在该非机动车辆的检测框的中心点坐标信息上方,若否,则执行步骤
⑥
;若是,则执行步骤
⑤‑
8;
⑤‑
8判断是否有超过一个的检测框的类别信息为头盔,若否,则当前帧为正常行驶并不输出,执行步骤
⑥
;若是,则当前帧中存在载人行驶的违规行为;
⑥
判断当前帧是否为待检测的视频流的最后一帧,若否,则将下一帧作为当前帧并返回执行步骤
⑤
;若是,则结束。
20.在本实施例中,用于实现目标检测网络的构建方法的程序代码如下:# parametersnc: 4
ꢀꢀ
# number of classes 检测目标的种类数量depth_multiple: 0.33
ꢀꢀ
# model depth multiple模型深度#用于控制模块的数量,当模块的数量number不为1时,模块的数量 = number * depthwidth_multiple: 0.50
ꢀꢀ
# layer channel multiple 模型的宽度#用于控制卷积核的数量,卷积核的数量 = 数量 * width# anchorsanchors:
ꢀꢀ‑ꢀ
[ 19,27,
ꢀꢀ
44,40,
ꢀꢀ
38,94 ]
ꢀꢀ
# p3/8
ꢀꢀ‑ꢀ
[ 96,68,
ꢀꢀ
86,152,
ꢀꢀ
180,137 ]
ꢀꢀ
# p4/16
ꢀꢀ‑ꢀ
[ 140,301,
ꢀꢀ
303,264,
ꢀꢀ
238,542 ]
ꢀꢀ
# p5/32
ꢀꢀ‑ꢀ
[ 436,615,
ꢀꢀ
739,380,
ꢀꢀ
925,792 ]
ꢀꢀ
# p6/64# yolov5 backbonebackbone:
ꢀꢀ
# [from, number, module, args]# from
ꢀꢀꢀ
第一列 输入来自哪一层
ꢀꢀ‑
1代表上一层,4代表第4层
ꢀꢀ
# number 第二列 循环次数
ꢀꢀ
# module 第三列 模块名称 包括:conv、focus、c3、spp等
ꢀꢀ
# args
ꢀꢀꢀ
第四列 模块的参数#第四列[]只有一个参数,表示通道数#第四列[]有两个参数,依次表示为通道数和卷积核大小#第四列[]有三个参数,依次表示为通道数、卷积核大小和步长
ꢀꢀ
[ [
ꢀ‑
1, 1, focus, [ 64, 3 ] ],
ꢀꢀ
# 0-p1/2第0层 [64,3]中64表示通道数,3表示卷积核大小
ꢀꢀꢀꢀ
[
ꢀ‑
1, 1, conv, [ 128, 3, 2 ] ],
ꢀꢀ
# 1-p2/4 第一层 [128,3,2]中128表示通道数,3表示卷积核大小,2表示步长
ꢀꢀꢀꢀ
[
ꢀ‑
1, 3, c3, [ 128 ] ], #第二层 [128]中的128表示通道数
ꢀꢀꢀꢀ
[
ꢀ‑
1, 1, conv, [ 256, 3, 2 ] ],
ꢀꢀ
# 3-p3/8 第三层
ꢀꢀꢀꢀ
[
ꢀ‑
1, 9, c3, [ 256 ] ], #第四层
ꢀꢀꢀꢀ
[
ꢀ‑
1, 1, conv, [ 512, 3, 2 ] ],
ꢀꢀ
# 5-p4/16 第五层
ꢀꢀꢀꢀ
[
ꢀ‑
1, 9, c3, [ 512 ] ], #第六层
ꢀꢀꢀꢀ
[
ꢀ‑
1, 1, conv, [ 768, 3, 2 ] ],
ꢀꢀ
# 7-p5/32 第七层
ꢀꢀꢀꢀ
[
ꢀ‑
1, 3, selayer, [ 768, 16 ] ], #第八层加入se注意力机制
ꢀꢀꢀꢀ
[
ꢀ‑
1, 1, conv, [ 1024, 3, 2 ] ],
ꢀꢀ
# 9-p6/64 第九层
ꢀꢀꢀꢀ
[
ꢀ‑
1, 1, spp, [ 1024, [ 3, 5, 7 ] ] ], #第十层为池化层
ꢀꢀꢀꢀ
[
ꢀ‑
1, 3, c3tr, [ 1024, false ] ],
ꢀꢀ
# 11 第十一层加入transformer注意力机制 false=shortcut
ꢀꢀ
]# yolov5 headhead:
ꢀꢀ
[ [
ꢀ‑
1, 1, conv, [ 768, 1, 1 ] ],
ꢀꢀ
#第十二层
ꢀꢀꢀꢀ
[
ꢀ‑
1, 1, nn.upsample, [ none, 2, 'nearest' ] ], #第十三层为上采样层
ꢀꢀꢀꢀ
[ [
ꢀ‑
1, 7, 8], 1, concat, [ 1 ] ],
ꢀꢀ
# cat backbone p5 第十四层拼接第十三层、第七层和第八层
ꢀꢀꢀꢀ
[
ꢀ‑
1, 3, c3, [ 768, false ] ],
ꢀꢀ
# 15 第十五层
ꢀꢀꢀꢀ
[
ꢀ‑
1, 1, conv, [ 512, 1, 1 ] ], #第十六层
ꢀꢀꢀꢀ
[
ꢀ‑
1, 1, nn.upsample, [ none, 2, 'nearest' ] ], #第十七层为上采样层
ꢀꢀꢀꢀ
[ [
ꢀ‑
1, 5, 6], 1, concat, [ 1 ] ],
ꢀꢀ
# cat backbone p4 第十八层拼接第十七层、第五层和第六层
ꢀꢀꢀꢀ
[
ꢀ‑
1, 3, c3, [ 512, false ] ],
ꢀꢀ
# 19 第十九层
ꢀꢀꢀꢀ
[
ꢀ‑
1, 1, conv, [ 256, 1, 1 ] ], #第二十层
ꢀꢀꢀꢀ
[
ꢀ‑
1, 1, nn.upsample, [ none, 2, 'nearest' ] ], #第二十一层为上采样层
ꢀꢀꢀꢀ
[ [
ꢀ‑
1, 3, 4], 1, concat, [ 1 ] ],
ꢀꢀ
# cat backbone p3 第二十二层拼接第二十一层、第三层和第四层
ꢀꢀꢀꢀ
[
ꢀ‑
1, 3, c3, [ 256, false ] ],
ꢀꢀ
# 23 (p3/8-small) #第二十三层
ꢀꢀꢀꢀ
[
ꢀ‑
1, 1, conv, [ 256, 3, 2 ] ], #第二十四层
ꢀꢀꢀꢀ
[ [
ꢀ‑
1, 20 ], 1, concat, [ 1 ] ],
ꢀꢀ
# cat head p4 第二十五层拼接第二十四层和第二十层
ꢀꢀꢀꢀ
[
ꢀ‑
1, 3, c3, [ 512, false ] ],
ꢀꢀ
# 26 (p4/16-medium) #第二十六层
ꢀꢀꢀꢀ
[
ꢀ‑
1, 1, conv, [ 512, 3, 2 ] ],# 第二十七层
ꢀꢀꢀꢀ
[ [
ꢀ‑
1, 16 ], 1, concat, [ 1 ] ],
ꢀꢀ
# cat head p5#第二十八层拼接第二十七层和第十六层
ꢀꢀꢀꢀ
[
ꢀ‑
1, 3, c3, [ 768, false ] ],
ꢀꢀ
# 29 (p5/32-large) 第二十九层
ꢀꢀꢀꢀ
[
ꢀ‑
1, 1, conv, [ 768, 3, 2 ] ], #第三十层
ꢀꢀꢀꢀ
[ [
ꢀ‑
1, 12 ], 1, concat, [ 1 ] ],
ꢀꢀ
# cat head p6 第三十一层拼接第三十层和第十二层
ꢀꢀꢀꢀ
[
ꢀ‑
1, 3, c3, [ 1024, false ] ],
ꢀꢀ
# 32 (p6/64-xlarge) 第三十二层
ꢀꢀꢀꢀ
[ [ 23, 26, 29, 32 ], 1, detect, [ nc, anchors ] ],
ꢀꢀ
# detect(p3, p4, p5, p6)检测输出层
ꢀꢀ
]本发明构建后的目标检测网络的网络结构如图3所示;本发明所选用实验的硬件为:gpu:iamd ryzen 7 5800x,ram:16g,cpu:igame geforce rtx 3090 neptune oc;所选用实验开发环境为:pytorch框架、cuda11.1、cudnn8.0.4。
[0021]
本发明的样本数据集中共有10000张非机动车辆图像,经过预处理后样本数据集中共有20000张非机动车辆图像,其中每张非机动车辆图像的尺寸为:1920*1080,部分预处理前后的非机动车辆图像对照如图4(a)、图4(b)所示;将样本数据集划分为70%的训练集和30%的验证集,目标检测网络的输入为640*640的三通道图像,因此将训练集和验证集中的所有图像调整至统一大小即640*640;将se注意力机制及transformer注意力机制加入原yolov5网络中得到目标检测网络,设置训练参数,利用训练集对目标检测网络进行训练,得到目标检测器,并将验证集输入目标检测器中进行验证,输出的验证结果使用map值作为评价目标检测器验证效果的评估指标,若map值大于或等于90%,则将记录该目标检测器中se注意力机制和transformer注意力机制在目标检测网络中的位置及对应的通道数、目标检测网络中拼接层的输入层以及训练参数,若map值小于90%,则调整se注意力机制及transformer注意力机制在目标检测网络中的位置及对应的通道数并修改目标检测网络中拼接层的输入层得到新的目标检测网络,重新利用训练集对新的目标检测网络进行训练;因此,将本发明的batch_size设置为8,迭代次数设置为300,在原yolov5网络的第八层加入se注意力机制、原yolov5网络的第十一层加入transformer注意力机制;如表1所示,通过在原yolov5网络的第八层加入se注意力机制、第十一层加入transformer注意力机制,加强了目标检测网络对有用特征信息的定位能力,本发明的map(平均检测精度)值高达92.2%,较yolov5相比提高了1.6%,且本发明的每个类别的ap(检测精度)值都有所提高,其中对于头盔的检测提升相对明显,对于头的检测也有一定的提升;表1 不同算法关于目标检测的实验结果性能对比
processing (icip) (2017): 3645-3649。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。