1.本发明涉及一种融合句法结构信息的关键词生成方法及装置,属于互联网与人工智能技术领域。
背景技术:
2.随着计算机网络的普及和通信技术的发展,在社会经济文化活动以及日常生活中,人们接触到各式各样的媒体平台发布的新闻文章。在数据规模呈指数型增长的时代,运用计算机技术对新闻长文章进行信息压缩,提炼出核心内容,可以帮助读者快速地甄别出有价值的信息。
3.当前关键词生成模型都是基于一种序列到序列(sequence to sequence,seq2seq)模型。该模型采用编码器-解码器架构,其中编码器负责将输入文本序列编码为一个中间向量,解码器从该向量中进行解码,生成对应的输入序列。然而,现有的方法通常使用循环神经网络(rerrentneuralnetwork,rnn)实现编码器和解码器,而rnn存在长时遗忘问题,不能有效地捕获文章全局信息。另一方面,基础的seq2seq模型不能很好地建模文章和其关键词之间的“一对多”关系。为此,本发明提出基于文本句法结构信息的关键词生成模型,利用图卷积网络(graph convolutionalnetwork,gcn)挖掘文本深层结构信息,并通过聚类方式显示指导解码器生成多样化的关键词。
技术实现要素:
4.针对现有技术中存在的问题与不足,本发明提供一种融合句法结构信息的关键词生成方法及装置,通过文本的句法结构将序列化文本转化为图结构,并通过gcn学习节点的向量表示,表示中包含文本的结构特征,通过结构化信息弥补rnn编码存在的不足,利用聚类方法显示指导模型生成具有差异的关键词,提高关键词的质量。
5.为实现上述发明目的,本发明所述的一种融合句法结构信息的关键词生成方法,首先利用对文章进行分句分词,利用句法依存分析工具得到句法分析结果;然后根据句法分析结构构造句法图,将文本单词映射为图中节点,单词之间的关系通过边体现;之后构建顺序和图编码器得到文章的特征表示;最后将特征表示输入解码器生成新闻文章的关键词。本发明方法主要包括四个步骤,具体如下:
6.步骤1:新闻文章采集。通过爬虫工具收集多个媒体平台的新闻文章,积累样本数据集,然后对样本数据集进行过滤以减少样本重复率;对样本集中每一个样本采用人工标注构造训练样例:新闻文章和标准关键词;
7.步骤2:文本预处理。对文章进行分句、分词,利用句法依存分析工具得到句法分析结果;其次根据句法分析结构构造句法图,将文本单词映射为图中节点,单词之间的关系通过边体现;
8.步骤3:训练基于句法结构信息融合的关键词生成模型。首先通过顺序编码和结构编码双编码方式学习单词表示。然后子图聚类网络根据整个文本的含义,对文本内容进行
划分,从而为每个解码器构建独特的子主题表示。之后带注意力机制的顺序解码器根据生成的子主题表示生成相应的关键词;最后利用交叉熵作为损失函数对模型参数进行优化;
9.步骤4:对待处理的新闻文章生成关键词。对于需预测关键词的新闻文章,首先用句法依存分析工具分析句法,再构建文本句法图,将新闻文章原文与句法图输入到步骤3中训练好的关键词生成模型中,生成该新闻文章的关键词。
10.进一步的,所述步骤3包括如下子步骤:
11.子步骤3-1,构建输入层,输入层接收文本单词序列作为输入,利用预训练的word2vec模型将每个词映射为对应的词向量,得到原文单词向量表示序列ew;
12.子步骤3-2,构建文本编码层,采用一个两层bigru对词向量序列ew进行顺序语义编码,得到词向量序列ew的隐层状态向量bigru(ew):
[0013][0014][0015][0016]
其中u
t
为词嵌入,表示前一个gru单元的状态向量,表示下一个gru单元的状态向量;
[0017]
采用gcn网络学习构建好的文本图数据;gcn利用邻居节点聚合方式进行节点信息更新,定义如下:
[0018]hl
=relu(ah
l-1wl
)
[0019]
其中a是文本图的邻接矩阵,h
l
表示当前层的输出结果,用单词的表示初始化每个节点表示,w
l
是训练参数;对于l层的图卷积网络,节点获得了l阶邻居节点的信息,因此在节点的特征向量表示中具有了结构信息;
[0020]
子步骤3-3,构建子图生成层,在文本图基础上,对文本图进行拆分聚类,得到多个包含文章不同方面的子图;对于每个节点,利用下式计算节点属于每个子图的概率:
[0021]
assigments=softmax(wah
l
ba)
[0022]
其中,h
l
表示gcn最后一层的输出,wa、ba是可学习参数,a表示计算注意力权重的网络,softmax是归一化函数;
[0023]
之后,对节点表示加权求和可获得子图的表示:
[0024][0025]
子步骤3-4,构建关键词解码层;采用多个相同的解码器并行解码方式生成关键词;其中,单个解码器采用单向gru实现,并结合复制机制;在解码时间步j时,根据上一个单词的表示u
j-1
和上一个时刻隐层状态s
j-1
,计算得到当前隐藏状态:
[0026]
sj=gru(u
j-1
,s
j-1
)
[0027]
之后,利用注意力机制,计算输入文本中每个单词的注意力权重:
[0028][0029]
αj=softmax(ej)
[0030]
其中,表示文本序列第i个单词经过bigru计算得到的特征向量,e
ij
衡量预测的
第j个单词与原文第i个单词相关程度,ej表示预测第j个单词时原文单词的注意力权重;
[0031]
通过对单词特征向量加权求和,得到当前上下文表示向量:
[0032][0033]
然后,结合子图表示、上下文向量和隐藏状态,得到单词在词表上的分布:
[0034]
p
vocab
=softmax(wg[sj;cj;g] bg)
[0035]
其中,g为计算得到词表分布的网络;
[0036]
最终,时间步j时,预测单词的最后分布如下式所示,
[0037]
p
final
=(1-λj)
·
p
vocab
λj·
p
copy
[0038]
λj=sigmoid(w
λ
[cj;u
j-1
;sj;g] b
λ
)
[0039]
其中p
copy
=αj,λj表示从原文复制单词的概率,λ是计算复制概率的网络;
[0040]
子步骤3-5,构建损失函数层,本层生成的关键词与参考关键词的交叉熵损失作为所述模型的训练损失函数;按如下损失函数计算公式得到本组样本的训练损失:
[0041][0042]
其中,d为训练数据集,x为输入文本,y为目标关键词,θ为模型的参数集合;
[0043]
子步骤3-6,训练所述模型;采用随机初始化的方式初始化所有待训练参数,在训练过程中采用adam优化器进行梯度反向传播来更新模型参数,当训练损失不再下降或训练轮数超过一定轮数时,模型训练结束。
[0044]
进一步的,所述句法依存分析工具为hanlp。
[0045]
本发明还提供了一种融合句法结构信息的关键词生成装置,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,该计算机程序被加载至处理器时实现上述的融合句法结构信息的关键词生成方法。
[0046]
与现有技术相比,本发明具有如下优点和有益效果:
[0047]
(1)本发明引入结构化知识,能够有效地提取文本的结构特征弥补顺序编码存在的不足,顺序语义与结构语义相互补充,有效提高了模型捕捉文本全局特征信息的能力,克服现有关键词生成方法无法有效捕捉全局信息的问题,从而提高关键词生成质量;
[0048]
(2)本发明采用聚类方法,显示的将新闻文章划分多个包含子主题的部分,并为每个子主题分配独立的编码器,采用多解码器并行解码方法生成关键词,能够提高模型生成关键词的多样性。
附图说明
[0049]
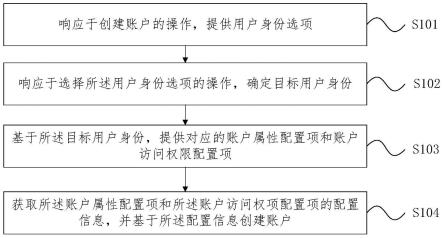
图1为本发明实施例的处理流程图。
[0050]
图2为本发明实施例的方法总体框架图。
具体实施方式
[0051]
以下将结合具体实施例对本发明提供的技术方案进行详细说明,应理解下述具体实施方式仅用于说明本发明而不用于限制本发明的范围。
[0052]
本发明提供的一种融合句法结构信息的关键词生成方法,其处理流程如图1所示,
实现框架如图2所示,包括如下具体实施步骤:
[0053]
步骤1,新闻文章数据集采集。不失一般性,本实施例首先通过爬虫工具从互联网上搜集大量新闻文章,然后进行过滤以减少样本重复率;并采取人工标注训练样例:新闻文章和标准关键词,它们共同构成样本数据集d。
[0054]
步骤2,数据预处理,首先对数据集d的每篇新闻文章预处理,进行分词、分句,然后采用句法分析工具hanlp对文本进行句法解析,得到文本的句法依存关系;过滤停用词;根据句法分析结果构造句法图,将文本单词映射为图中节点,单词之间的关系通过边体现。
[0055]
步骤3,利用步骤2处理后的数据集d对融合句法结构信息的关键词生成模型进行训练,该步骤的实施可以分为以下子步骤:
[0056]
子步骤3-1,构建输入层,输入层接收文本单词序列作为输入,利用预训练的word2vec模型将每个词映射为对应的词向量,得到原文单词向量表示序列ew。
[0057]
子步骤3-2,构建文本编码层,本实施例采用一个两层bigru对词向量序列ew进行顺序语义编码,得到词向量序列ew的隐层状态向量bigru(ew):
[0058][0059][0060][0061]
其中u
t
为词嵌入,表示前一个gru单元的状态向量,表示下一个gru单元的状态向量。
[0062]
采用gcn网络学习构建好的文本图数据。通过多层的gcn,单词节点不仅能够获取邻居的单词信息,也能获取到更远的单词信息。gcn利用邻居节点聚合方式进行节点信息更新,定义如下:
[0063]hl
=relu(ah
l-1wl
)
[0064]
其中a是文本图的邻接矩阵,h
l
表示当前层的输出结果,用单词的表示初始化每个节点表示,w
l
是训练参数。对于l层的图卷积网络,节点获得了l阶邻居节点的信息,因此在节点的特征向量表示中具有了结构信息。
[0065]
子步骤3-3,构建子图生成层,在文本图基础上,对文本图进行拆分聚类,得到多个包含文章不同方面的子图。对于每个节点,利用下式计算节点属于每个子图的概率:
[0066]
assigments=softmax(wah
l
ba)
[0067]
其中,h
l
表示gcn最后一层的输出,wa、ba是可学习参数,a表示计算注意力权重的网络,softmax是归一化函数。
[0068]
之后,对节点表示加权求和可获得子图的表示:
[0069][0070]
子步骤3-4,构建关键词解码层。本实施例采用多个相同的解码器并行解码方式生成关键词。其中,单个解码器采用单向gru实现,并结合复制机制。在解码时间步j时,根据上一个单词的表示u
j-1
和上一个时刻隐层状态s
j-1
,计算得到当前隐藏状态:
[0071]
sj=gru(u
j-1
,s
j-1
)
[0072]
之后,利用注意力机制,计算输入文本中每个单词的注意力权重:
[0073][0074]
αj=softmax(ej)
[0075]
其中,是可学习参数,表示文本序列第i个单词经过bigru计算得到的特征向量,e
ij
衡量预测的第j个单词与原文第i个单词相关程度,ej表示预测第j个单词时原文单词的注意力权重(未归一化)。
[0076]
通过对单词特征向量加权求和,得到当前上下文表示向量:
[0077][0078]
其中,hs为原文单词特征向量构成的特征矩阵。
[0079]
然后,结合子图表示、上下文向量和隐藏状态,得到单词在词表上的分布:
[0080]
p
vocab
=softmax(wg[sj;cj;g] bg)
[0081]
其中,g为计算得到词表分布的网络。除了从词表生成单词,从源文本复制单词也是生成单词一种方式。在复制机制中,可以将单词的注意力权重视为当前时刻,生成的单词在源文本中的分布。
[0082]
最终,时间步j时,预测单词的最后分布如下式所示,
[0083]
p
final
=(1-λj)
·
p
vocab
λj·
p
copy
[0084]
λj=sigmoid(w
λ
[cj;u
j-1
;sj;g] b
λ
)
[0085]
其中p
copy
=αj,λj表示从原文复制单词的概率,g为子主题特征向量。
[0086]
子步骤3-5,构建损失函数层,本层生成的关键词与参考关键词的交叉熵损失作为所述模型的训练损失函数。按如下损失函数计算公式得到本组样本的训练损失:
[0087][0088]
其中,d为训练数据集,x为输入文本,y为目标关键词,θ为模型的参数集合。
[0089]
子步骤3-6,训练所述模型。本实施例采用随机初始化的方式初始化所有待训练参数,在训练过程中采用adam优化器进行梯度反向传播来更新模型参数,初始学习率设置为0.001。当训练损失不再下降或训练轮数超过10轮时,模型训练结束。
[0090]
步骤4,利用训练完毕的参数初始化关键词模型生成关键词。该模型以经过文本预处理后的新闻文章为输入,首先用句法依存分析工具hanlp分析句法,再构建文本句法图,具体先对文章进行顺序编码和结构编码,然后在解码层逐词生成短语作为目标关键词,初始单词为一个特殊的开始标记“《start》”,每一时刻的预测词为指针生成层输出的概率最大的词,当输出结束标记“《end》”时,停止单词的生成,输出已生成的单词序列作为输入新闻文章的预测关键词。
[0091]
基于相同的发明构思,本发明实施例还提供一种融合句法结构信息的关键词生成装置,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,该计算机程序被加载至处理器时实现上述的融合句法结构信息的关键词生成方法。
[0092]
本发明方案所公开的技术手段不仅限于上述实施方式所公开的技术手段,还包括由以上技术特征任意组合所组成的技术方案。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。