1.本发明涉及一种系统、方法和计算机程序,用于在评估听力损失时对用户、特别是听力受损的用户进行交互式支持,尤其是用于对助听器进行配置、特别是初始配置。
背景技术:
2.助听器通常理解为补偿听力受损者的听力缺陷的设备。特别是,这种助听器具有特定于用户的与频率相关的放大功能,其取决于个体的听力损伤。现代的助听器还有许多其它的功能。
3.为了获得令人满意的听力结果,必须将每个助听器单独匹配于用户。除了在设计方面不同的不同类型的助听器之外,助听器还必须针对其助听器功能、尤其是针对个体的与频率相关的放大功能进行参数化。因此,必须单独确定调整参数的设置值,并且将其传输至助听器。
4.如今,助听器通常由听力学家来调整。为了识别个体的听力损伤,这经常以向用户、即听力受损者提供不同的听力样本的方式来进行。用户评估他或者她如何感知这些声音样本。这些声音样本例如是语音样本、音乐样本或者其它声音或噪声。
5.总的来说,确定个体的听力损伤以及确定调整助听器所需的设置是复杂并且耗时的。对于还没有助听器的首次用户来说,这经常是一个阻止门槛。这经常导致如下事实,即,这些首次用户,尽管听力受损,但是不使用助听器,这可能对他们的社会关系产生负面影响。
技术实现要素:
6.基于上述内容,本发明旨在尤其是针对首次用户,简化助听器的配置、特别是初始配置。
7.根据本发明,上述任务由如下的系统、方法和计算机程序来解决,该系统、方法和计算机程序用于在评估听力受损的用户的听力损失时,尤其是在对助听器进行(初始)配置时,支持用户、特别是听力受损的用户。下面结合系统列出的优点和优选配置也可以类似地应用于方法和计算机程序。所述系统通常包括专门被设计为用于执行该过程的一个或多个设备。所述系统包括:
[0008]-显示元件,用于显示示出环境情况的图像。该图像特别地是真实环境的表示。真实环境的图像应当理解为例如照片,但是也可以理解为以自然的方式再现环境、即人、建筑物、街道、车辆等的动画表示。
[0009]-输入单元,用于检测用户输入,尤其是用于选择基于用户输入呈现的环境情况的一个片段。该输入单元例如被设计为触摸屏、单独的输入设备、例如键盘或者鼠标,或者被设计为用于接收语音命令或者手势命令。
[0010]-处理单元,用于控制显示单元并且用于处理用户输入。处理单元通常是计算机单元,即具有通常关联的部件、例如存储器、用于控制显示元件的显卡、用于用户输入的接口
等的处理器。处理单元也可以分布在几个不同的硬件设备上。
[0011]
处理单元被配置为用于执行以下步骤,这些步骤也表征该过程。计算机程序具有命令,当系统执行程序时,这些命令使该系统根据用户输入执行以下步骤:
[0012]
a)将环境情况显示在显示元件上,
[0013]
b)基于用户输入,确定并且突出显示环境情况的选择的片段(16),
[0014]
c)基于用户进行的选择显示特定听力情况,
[0015]
d)显示评估标度,基于该评估标度,用户可以输入其针对特定听力情况的听力能力的自我评估的听力值,并且记录用户输入的听力值,
[0016]
e)重复步骤a)至d),并且在每种情况下针对不同的特定听力情况记录听力值,以及可选地
[0017]
f)基于用户输入的听力值确定助听器的设置值。
[0018]
该过程具有以下优点,即,通过环境情况的图形自然表示和图形动画用户交互来提供交互式界面,用户可以直观、有趣地操作该交互式界面。同时,尤其是与不同的环境情况、因此与不同的听力情况相关地记录关于用户的听力损伤的第一相关信息。
[0019]
在所选择的以图形表示的特定听力情况的图像中显示的评估标度例如包含笑脸符号形式的图形符号、分级标度或者显示的控制面板。优选使用图形符号。
[0020]
通过重复地从图像中选择与特定听力情况相关的特定片段,用户针对不同的听力情况进行自我评估。基于此,系统尤其是针对个体的与频率相关的放大功能来确定设置值,然后使用这些设置值来对助听器进行进一步的配置。
[0021]
所提出的系统以及所提出的方法
[0022]
a)(仅)用于辅助用户评估用户的听力损失,
[0023]
b)可选地附加地与基于在步骤a)中对听力损失的评估对助听器的配置一起使用,其中,
[0024]
c)配置可以是用于助听器、例如购买的助听器的首次基本配置的(初始)配置输入,
[0025]
d)替换地或者附加地,配置可以是对用户(佩戴者)已经使用的已经配置的助听器的微调,例如用于使助听器匹配于新的听力情况,尤其是用于使助听器匹配于佩戴者的新的听力行为。
[0026]
例如还在购买过程期间的试用阶段在听力学家处使用所述系统和所述方法。附加地或者替换地,所述系统和所述方法用于助听器评估、助听器研究。
[0027]
优选不与该系统和过程一起提供声音样本。这意味着,仅使用用户针对不同的图形表示的特定听力情况进行的自我评估来确定设置。在这方面,不存在通过提供和评估诸如语音、音乐、声音、噪声等的声音样本来“测量”用户的听力损伤。
[0028]
优选所述系统包括本地设备、尤其是便携式设备、例如平板计算机或者智能电话。替换地,设备可以是本地个人计算机。平板计算机、智能电话或者个人计算机可以具有安装的控制过程的计算机程序。通常,通过该本地设备来进行用户输入。本地设备包含输入元件、显示元件以及输入单元和处理单元的至少一部分。根据第一实施例,在本地设备上安装有应用(计算机程序),用于执行用于辅助用户的所有步骤。在这种情况下,本地设备的处理单元是系统的唯一的处理单元。
[0029]
替换地,为了安装在本地设备上,提供具有本地设备和远程设备的分离系统。例如使用基于网络(web)的解决方案,用户可以通过因特网浏览器来控制这种解决方案。在这种情况下,应用安装或者驻留在远程设备上。在这种分离系统的情况下,通常,处理单元在物理上被划分为本地部分和远程部分。
[0030]
优选仅由电子系统来辅助用户,而不与人、例如听力专家等医疗保健专业人员进行任何交互。
[0031]
根据优选的替换方案,由人、例如听力专家等医疗保健专业人员来辅助用户。优选用户和医疗保健专业人员彼此距离较远。远程设备包括另外的显示元件。尤其是针对这种情况,在显示元件和该另外的显示元件上显示相同的内容。这确保听力专家能够跟踪用户交互,并且用户和听力专家看到相同的图片。
[0032]
优选在图像中突出显示用户选择的片段。根据一个设计变形方案,例如,为此目的使用所谓的“斑点技术(spot technique)”,其中,以光锥的方式突出显示所选择的区域。
[0033]
优选在所显示的图像中描绘几个环境情况,所描绘的这些环境情况中的每一个表征不同的听力场景。用户可以选择个体的听力场景。因此,图像包含几个表示一般的真实生活场景的区域,这些生活场景代表不同的听力场景。以视觉方式表示这些不同的区域或者环境情况,例如通过显示对话情况、游乐场、音乐厅、体育场、餐厅等。这些不同的区域/环境情况覆盖不同的听力场景。例如,在图像中显示3个以上、优选5个以上不同的听力场景。
[0034]
听力场景应当理解为一般可能出现几个特定听力情况的复杂的听力环境。特定听力情况一般由一个或多个特定声源或者声源类型来定义。
[0035]
听力场景包括诸如“办公室”、“音乐厅”、“儿童游乐场”、“体育设施”、“餐厅”等听力环境。
[0036]
听力情况的示例是“儿童的声音”、“对话”、“鸟叫声”、“交通噪声”等。
[0037]
优选作为新的细节图像来显示用户选择的片段、尤其是用户选择的听力场景。在该细节图像中,提供不同的特定听力情况,以供用户选择。如果用户选择这些特定听力情况中的一个,那么优选再次突出显示该情况。特别是,针对所选择的该特定听力情况显示评估标度,并且记录用户输入的听力值。因此,该系统版本被设计为用于,在针对特定听力情况显示评估标度之前,由用户进行多阶段选择。
[0038]
这种方法基于如下事实,即,在一般的听力场景、例如儿童游乐场内,可能出现不同的特定听力情况、即尤其是不同的声源,并且对这些听力情况单独进行评估。以这种方式,可以实现更准确的设置。这些不同的特定听力情况例如包括“对话”、诸如鸟或者交通的“环境声音”或者“儿童的声音”。
[0039]
优选显示另外的评估标度,使得用户能够利用参考值来评估所选择的听力情况与他的相关性。对相应的听力情况的相关性的这种评估使得能够得出关于用户行为的结论。
[0040]
替换地或者除此之外,基于用户选择的片段,特别是基于用户选择的听力场景,自动推导出不同的特定听力场景与用户的相关性。这基于如下考虑,即,用户将仅从所显示的总体图像中选择与用户相关的那些环境情况和环境场景。
[0041]
对用户输入进行评估。为此目的,特别是执行以下步骤:
[0042]
优选存储定义的用户类别,并且基于用户的输入,特别是基于用户选择的片段,将用户分配到存储的用户类别中的一个。特别是基于用户选择的听力场景来进行分配。通过
选择,用户揭示关于其一般的行为以及关于其生活方式的一些情况。这使得能够将用户分类,例如分类为主动或者被动的人,这也影响设置的选择。
[0043]
优选基于用户的输入来自动确定在哪些特定听力情况下存在听力缺陷以及听力缺陷的程度。然后,在此基础上推导出针对该用户的设置、特别是与频率相关的放大因子。
[0044]
此外,优选定义听力损失类别,并且基于针对特定听力情况的听力值,将用户分配给预先定义的听力损失类别中的一个。听力损失类别通常对听力损伤的类型进行分类。这意味着,每个听力损失类别定义一种不同类型的听力损伤。听力损失的可能的类别例如是:
[0045]-宽带高频损失(从250hz至1khz的频率范围内以及附加地在1khz至4khz之间的高频范围内的听力缺陷,这特别是适用于语音理解),
[0046]-高频陡峭衰减(在更高频率下具有强衰减的从1khz至8khz的高频范围内的听力缺陷)
[0047]-传导性听力损失。
[0048]
因此,听力损失类别明确地定义了不同频率范围内的听力缺陷。
[0049]
针对每个特定听力情况的听力值通常确定一对值,其由所选择的特定听力情况、经常是特定声源和自我评估的听力值构成。可以将相应的特定听力情况分配给一个或多个听力损失类别。
[0050]
为了将用户分配至听力损失类别,第一种方法涉及将针对各种特定听力情况的听力值相加,以形成总值,并且基于该总值,将用户分配至听力损失类别。
[0051]
为了进行更准确的分类,优选以下方法:
[0052]
将几个听力损失类别分配至一个听力情况,利用特定于所选择的听力情况的加权因子对每个听力损失类别进行加权。因此,每个特定听力情况由加权的听力损失类别来定义,该加权的听力损失类别表示该特定听力损失类别对该特定听力情况的重要性。加权因子在0和1之间。
[0053]
此外,利用用户针对不同的听力情况输入的听力值,对针对不同听力情况分配并且加权的听力损失类别进行加权。因此,对于每个听力情况,针对分配的每个听力损失类别获得特定于用户的类别值。最后,对各种特定听力情况,对针对每个听力损失类别的个体的类别值进行汇总,并且针对相应的听力损失类别获得总类别值。因此,针对每个听力损失类别获得总类别值。然后,基于确定的总类别值进行分配。
[0054]
例如,特定听力情况“对话”被分配至具有加权因子1的听力损失类别“宽带高频损失”和具有加权因子0.2的听力损失类别“高频陡峭衰减”。相对于此,特定听力情况“儿童的声音”被分配至各自具有加权因子0.5的听力损失类别“宽带高频下降”和“高频陡峭衰减”。
[0055]
这种分配也可以理解为向量,由此每个特定听力情况由具有几个元素的向量来表示。每个元素对应于一个听力损失类别,每个元素分配有加权因子。然后,将向量与针对该特定听力情况输入的听力值相乘。由此,针对特定听力情况针对每个听力损失类别获得类别值。然后,通过将向量相加来获得针对每个听力损失类别的总类别值。结果是作为对听力损失类别的加权分配的度量的总类别值或者所产生的总向量。这产生了一种更加差异化的方法,其允许对助听器进行更准确的调节。
[0056]
基于对听力损失类别中的一个的分配,最终推导出设置值,尤其是增益值的与频率相关的集合。例如,依据分配的听力损失类别,根据查找表或者算法来确定这些设置。
[0057]
另外,确定关键听力情况,针对关键听力情况,从预先定义的听力程序的集合中选择特定于情况的听力程序,并且应用于助听器。特别是,选择预先定义的参数差值的集合。基于分配的用户类别和/或基于用户认为其听力能力差(poor)的特定听力情况来确定关键听力情况。在这种情境下,差(poor)应当理解为是指用户陈述他或她的听力能力处于针对自我评估提供的评估标度的下半部分中。这通常用于识别由于听力缺陷而对用户来说关键的听力情况。在对助听器的操作期间,通过存储专门为这种听力情况设计的这种听力程序,来实现更准确的适配(fitting)。如果出现这种关键听力情况,那么将助听器专门切换到用于这种特殊的关键听力情况的特殊的听力程序。这一般通过提供指示与正常设置的偏差的差值来进行。听力程序是标准化的听力程序,并且与具体用户无关。优选助听器包括所谓的分类器,其能够自动区分并且识别听力情况。如果分类器识别出这种关键听力情况,那么系统自动切换到特定听力程序。
[0058]
优选基于用户的输入来选择适合用户的助听器。特别是基于分配的用户类别和/或确定的听力损失类别。特别是,从各种助听器类型(ite、bth、ric、cic
…
)中选择合适的助听器。除了生活方式信息之外,还考虑关于听力损伤的信息,从而能够做出决定,例如是否应当向用户提供ite(in the ear,入耳式)助听器、ric/cic(receiver/completely in canal,接收器/完全在耳道内)助听器或者bth(behind the ear,耳后式)助听器。
[0059]
最后,配置所选择的助听器,即利用所确定的设置值将所选择的助听器参数化。由此,自动对助听器进行初始配置。
[0060]
然后,使助听器对于用户可用。这例如通过将其直接交付给用户来进行。
[0061]
总之,在此呈现的设计使得第一次配置助听器变得容易,使阻止门槛保持尽可能低,尤其是对于首次用户来说。这种首次用户可以容易地确定并且配置合适的助听器,并且例如通过基于网络的应用将其发送来进行测试。
附图说明
[0062]
下面,结合附图来说明其它细节和示例。
[0063]
图1以简化的图示示出了用于在助听器的初始配置期间交互式地辅助用户的系统的高度简化的图示,
[0064]
图2a以简化的图示示出了具有几个环境情况的具有(总体)图像的显示元件的简化的图示,
[0065]
图2b以简化的图示示出了根据用户的选择显示详细图像的如图2a所示的显示元件,
[0066]
图3a以简化的图示示出了根据第二变形方案的类似于图2a的图示,
[0067]
图3b以简化的图示示出了在用户进行选择之后具有突出显示的片段的根据图3a的图示。
具体实施方式
[0068]
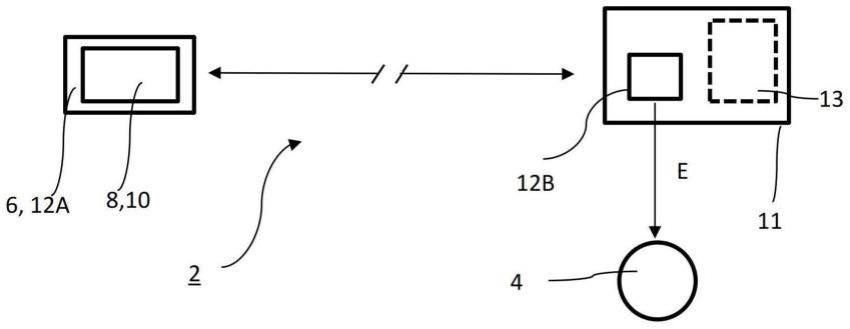
图1所示的系统2用于在助听器4的初始配置期间对用户的交互式支持。在根据图1的实施例中,系统2包括本地用户设备、例如平板计算机6,其具有显示器作为显示元件8,由此显示元件8被设计为触摸屏,因此形成输入单元10。由于平板计算机6的计算能力,其还具
有处理用户输入的(第一)处理单元12a。在图1中指示的实施例中,存在经由因特网与具有另外的处理单元12b的远程设备11的连接。这可以是助听器的制造商或者助听器的经销商的计算机。两个处理单元12a、12b一起形成公共处理单元,用于执行所述方法,并且用于对用户进行交互式支持。根据第一实施例,不存在人的辅助。
[0069]
替换地,存在人、尤其是听力专家的辅助。尤其是,在这种情况下,远程设备具有另外的显示元件13(以虚线示出)。在显示元件8上显示的图片也显示在另外的显示元件13上,使得听力专家可以跟踪用户输入。
[0070]
基于用户输入来确定设置值e,将设置值e传输至助听器4来进行配置。然后,将助听器4交付给用户。可以在处理单元12a、12b的每个部分上进行设置值的确定。
[0071]
图2a、2b示出了简单的以图形辅助的支持的第一实施例。在图3a、3b中示出了第二实施例。这两个示例的共同点是,在显示元件8上示出了具有至少一个环境情况的图像14。在这两个实施例中,用户可以选择不同的环境情况。
[0072]
在根据图2a的第一实施例中,将图像14作为概览图像呈现给用户,其中示出了不同的环境情况,每个环境情况与特定听力场景相关。概览图像是真实图像,或者至少是动画真实图像,其中示出了一般的日常情况。这些都通过对不同的听力场景、例如游乐场、音乐厅、体育场、餐厅、办公室、道路交通等的自然描绘来表示。
[0073]
图3a所示的第二实施例提供下拉菜单,其允许用户选择不同的环境情况,因此选择不同的听力场景。图3a示出了用户已经做出了选择的情况。在这种情况下,用户选择了听力场景“家庭晚餐”。
[0074]
在根据图2a的第一实施例中,用户通过点击在概览图像14中示出的听力场景中的一个来选择特定听力场景。为此,用户选择了片段16。在如图2b所示的新的细节图像18中示出了所选择的片段16。所示出的示例为听力场景“儿童游乐场”。在该听力场景中包括用户可以选择的几个特定听力场景。显示元件还示出了评估标度20,在该示例中其通过不同的笑脸符号来表示。用户使用这些笑脸符号来输入他或者她针对所选择的特定听力情况的听力能力的自我评估。依据选择,针对所选择的听力情况记录听力值h。例如,为每个图像符号分配数值。例如,值越高表示听力越差。
[0075]
用户在所选择的听力场景中,优选针对不同的听力情况(声源)重复特定听力情况的选择和自我评估。附加地或者替换地,用户针对另外的听力场景重复自我评估。因此,获得大量的值对,每个值对表示特定听力情况以及相关联的听力值。基于这些值对推导出用于助听器4的初始设置的设置值e。
[0076]
在根据图3a、3b的第二实施例中,第一步骤是选择听力场景。在根据图3a的图示中,用户选择了在图像中突出显示的片段16。在第二实施例中,这以斑点技术的方式来进行,即,以光锥的方式照亮所选择的片段,或者使图像的其余部分变暗。在该实施例中还显示评估标度20,用户可以利用该评估标度来进行自我评估,并且记录针对特定听力情况的听力值。在图3中,作为“家庭晚餐”听力场景的一部分,选择了特定听力情况“男性的语音”。
[0077]
在第二实施例中,显示了另外的评级标度22,用户可以使用该评估标度来输入附加的相关值r。根据用户的评估,相关值r指示该特定听力情况的重要性,即例如对于用户理解男性的语音来说有多重要。
[0078]
在第一实施例中,也至少隐含记录这种相关值r,即,通过用户在概览图像14中进
行的对不同的听力场景的选择来记录这种相关值r。基于所选择的听力场景以及未选择的听力场景,隐含可以推导出相关值r。
[0079]
使用以下过程来评估用户的输入:
[0080]
a)用户类别n
[0081]
在第一步骤中,将用户分配给预先定义的用户类别中的用户类别n。该分配基于用户选择的听力场景和/或用户针对个体的听力场景输入的相关值r。具体的特定听力情况通常对应于一般的声源、例如成人对话、儿童的语音、交通噪声、音乐、鸟叫声等。根据该信息,可以得出关于用户的习惯的结论,从而可以将用户分配到用户类别。例如,可以简单地区分为类别“主动的人”和“被动的人”。
[0082]
b)听力损失类别l
[0083]
还将用户分配到听力损失类别l。该分配基于从用户输入获得的值对(具有分配的听力值的听力情况)。
[0084]
在简单的分配过程之后,将用户输入的各个听力值相加,并且获得总值。这是人的听力损伤的度量。
[0085]
根据用于向听力损失类别l的分配的更准确的过程,应用加权:为每个特定听力情况(声源)分配向量。向量由作为加权因子的各个元素构成,将每个加权因子都分配给听力损失类别。例如,这种向量由2个元素构成:
[0086]
v=(l1,l2)
[0087]
其中,
[0088]
l1是听力损失类别1、例如宽带高频损失的加权值,并且
[0089]
l2是听力损失类别2、例如高频陡峭衰减的加权值。
[0090]
可以对不同的听力情况(声源)分配以下向量,例如:
[0091]
对于听力情况1、例如“对话”,v1=(1.0,0.2),
[0092]
对于听力情况2、例如“儿童的语音”,v2=(0.5,0.5),以及
[0093]
对于听力情况3、例如“鸟叫声”,v3=(0.2,1.0)。
[0094]
例如,受中等宽带高频衰减影响,从而他或者她在250hz到1khz的范围内具有听力缺陷,并且在1khz到4khz的范围内也具有听力缺陷的首次用户,一般难以听懂对话,因为人声位于1-4khz的范围内。儿童的语音包含更高频的分量,并且鸟叫声甚至更高。因此,该第一用户将在与人的对话中经历最大的限制。相应地,他或者她例如将为听力情况1(对话)分配听力值h1=4,为听力情况2(儿童的语音)分配听力值h2=3,并且为听力情况3(“鸟叫声”)分配听力值h3=2。对各个向量进行加权,尤其是将其乘以这些听力值h1、h2、h3。因此,以下的向量相加产生总向量,其各个元素各自由相应的听力损失类别的总类别值形成:
[0095]
4*v1 3*v2 2*v3=(5.9;4.2)
[0096]
可以看到,所分配的收听值是对具有宽带高频损失的用户的评估的一般结果。在这方面,用户被分配到听力损失类别“宽带高频损失”。
[0097]
相对来说,例如,第二用户受“高频陡峭衰减”影响,从而他在250hz到1khz的范围内几乎没有任何听力缺陷,但是在1khz到8khz的范围内具有严重的听力缺陷。与向前的用户相比,他与成年人交流的问题更少。相对来说,他不太能听到儿童的语音,并且在倾听鸟叫声时,他的听力损失特别明显。相应地,他将选择以下听力值,例如h1=0,h2=4,h3=5,
这在如下的向量相加中产生总向量:
[0098]
0*v1 4*v2 5*v3=(3.0;7.0)。
[0099]
因此,对于宽带高频听力损失类别存在总类别值3.0,并且对于高频陡峭衰减听力损失类别存在总类别值7.0。该结果是对具有高频陡峭衰减的人的评估的一般结果。
[0100]
听力类别的这种加权的相加允许对听力损失类别进行更加差异化的评估。这两个用户具有总值(各个听力值的和)9,但是具有不同的听力损伤。
[0101]
c)设置值e
[0102]
最后,基于听力损失类别l和/或用户类别n来确定设置值e。特别是,确定与频率相关的增益设置的集合,并且必要时,确定压缩设置。这例如借助于查找表或者以其它方式、例如借助于算法来进行,因此所述方法与用户使用的音频系统无关。
[0103]
所述方法的一个重要特征也是(仅)使用预先定义的标准设置值e,其仅仅被设计为用于不同的用户类别n和/或不同的听力损失类别l。另外,设置值的选择仅基于用户进行的用户输入。例如不通过提供并且评估声音样本来对听力缺陷进行测量。
[0104]
d)听力程序
[0105]
除了以这种方式获得的设置值e之外,优选选择一个或多个特定听力程序,尤其是对于用户评估为关键的听力场景或者听力情况。例如,如果用户对用于特定听力场景(例如“办公室”或者“音乐厅”)的听力情况给出了负面评估,那么从预先定义的听力程序的集合中选择用于该听力场景的特定听力程序,并且进行存储。如果用户对听力情况做出了负面的自我评估,例如如果听力值超过了阈值,那么该听力场景或者听力情况被视为是负面的。在听力场景的情况下,例如,如果用户输入的一个或多个听力值或者其针对该听力场景的总和超过了指定的总值,那么给出负面评估。具体听力程序一般由差分值(differential value)的集合来定义。这些差分值提供与标准设置e的差值。当激活这种听力程序时,通过差值来调节标准设置。听力程序也是预先定义的标准听力程序,其不单独匹配于用户。
[0106]
助听器4一般配备有所谓的分类器,分类器可以识别不同的听力场景或者听力情况,然后选择对应地分配的听力程序。
[0107]
e)助听器
[0108]
在随后的步骤中,基于用户输入来确定合适的助听器或者几个合适的助听器。优选考虑所确定的用户类别n和听力损失类别l两者。在最简单的情况下,使用查找表来选择助听器。特别是,考虑助听器4的以下因素:设计、尺寸(形状因子)、放大、复杂性和易用性。因此,听力损失类别l限制了可能的助听器类型的选择。如果一个人具有严重的听力损失,那么需要功能强大的助听器。用户类别n还提供关于用户的生活方式的信息。
[0109]
一般针对不同的客户群体,因此针对用户类别n,定制不同类型的助听器4,并且不同类型的助听器4具有针对这些特殊的客户群体的特殊的特征。因此,基于用户类别n的分配,除了基本设定(set up)之外,例如还考虑以下特征:
[0110]-自适应的定向麦克风,
[0111]-噪声抑制(麦克风噪声抑制、风噪声抑制
…
)
[0112]-声音平滑,即,消除短干扰峰值(例如汤匙撞击咖啡杯)的一种声音边缘平滑,
[0113]-频率压缩,其将高频语音分量传输到较低的频率范围内(这使在高频范围内具有非常严重的听力损失的人能够在较低的频率范围内听到这些分量)。
[0114]
信号处理之外的特征特别是包括以下因素:
[0115]-助听器的类型(ite、ite、ric、cic
…
)
[0116]-壳体的形状和设计
[0117]-壳体特性、例如颜色、防脏涂层、防溅、防水,
[0118]-通信可能性,例如利用遥控器进行操作,将智能电话用作助听器的遥控器;与音频流设备、例如智能电话进行通信,以拨打电话、播放音乐等,以及将助听器用作耳机/头戴式耳机
[0119]
f)配置和交付
[0120]
然后,将先前确定的设置值e和所选择的听力程序(如适用)传输到所选择的助听器4(或者几个助听器4)。这意味着利用使得用户能够使用助听器4的初始设置来配置所选择的助听器4。
[0121]
将选择并且预先配置的助听器交付给用户。原则上,可以提供几个不同的助听器供选择。
[0122]
附图标记列表
[0123]2ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
系统
[0124]4ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
助听器
[0125]6ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
平板计算机
[0126]8ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
显示元件
[0127]
10
ꢀꢀꢀꢀꢀꢀꢀꢀ
输入单元
[0128]
11
ꢀꢀꢀꢀꢀꢀꢀꢀ
远程设备
[0129]
12a、12b
ꢀꢀꢀ
处理单元
[0130]
13
ꢀꢀꢀꢀꢀꢀꢀꢀ
另外的显示元件
[0131]
14
ꢀꢀꢀꢀꢀꢀꢀꢀ
图像
[0132]
16
ꢀꢀꢀꢀꢀꢀꢀꢀ
片段
[0133]
18
ꢀꢀꢀꢀꢀꢀꢀꢀ
详细图像
[0134]
20
ꢀꢀꢀꢀꢀꢀꢀꢀ
评估标度
[0135]
22
ꢀꢀꢀꢀꢀꢀꢀꢀ
另外的评估标度
[0136]eꢀꢀꢀꢀꢀꢀꢀꢀꢀ
设置值
[0137]hꢀꢀꢀꢀꢀꢀꢀꢀꢀ
听力值
[0138]rꢀꢀꢀꢀꢀꢀꢀꢀꢀ
相关值
[0139]nꢀꢀꢀꢀꢀꢀꢀꢀꢀ
用户类别
[0140]
l
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
听力损失类别
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
