一种基于svm-tradboost模型迁移的xrf小样本元素分类方法
技术领域
1.本发明属于x荧光光谱元素检测分析技术领域,具体涉及一种基于svm-tradboost模型迁移的xrf小样本元素分类方法。
背景技术:
2.x射线荧光光谱法(x-ray fluorescence spectrometry,xrf)是用于对物质中元素成分和含量进行定性、定量以及试样物理特征分析的一种方法,该方法具有操作简单、检测效率高、样品预处理简单、非破坏性以及测定迅速等特点,适合于土壤、中药、矿石等领域的分析与研究。当通过xrf获取到元素成分时,对微量元素进行分类,传统的分类方法有判别分析、模糊聚类分析法、卷积神经网络分析法等。在实验样本充足的条件下,这些传统的分类方法也能够达到很好的效果;但是传统的机器学习分类方法通常建立在训练集和测试集服从相同的数据分布的基础上,但在实际情况下,这种条件并不一定能够满足。
3.在此之前,研究人员对光谱变化时分析方法的研究集中于在仪器、环境等测量条件发生改变时如何修正分析模型,但是当样品的物理性质以及化学成分的变化,即样品种类发生改变,也会导致样品光谱的差异;同时,原有的分析模型不包含这些由于变化而产生的新信息,故用原有的模型预测这化学、物理性质发生改变的样品,其预测误差将增大。为了保证结果的可靠性,往往需要重新设计分析模型,但是重新设计新的模型同样非常繁琐、耗时,造成大量样品数据的浪费,且不具有普遍性;同时,由于一些标准样品稀少、价格昂贵,如果使用大量检测样品的方法来建立新的分析模型,会产生成本大幅度提高甚至难以实现的问题。
技术实现要素:
4.针对背景技术所存在的问题,本发明的目的在于提供一种基于svm-tradboost模型迁移的xrf小样本元素分类方法。该方法基于与目标样本具有关联性的另一种样本的现有结果,通过模型迁移获取目标样本的分类模型,优化了目标样本待分析元素在小样本条件下使用已有的简单分类算法无法准确得到分类结果的缺点,同时使得原有的方法应用在其它种类的样本建立分类模型时,仍能将分类的准确性保持在90%以上。
5.更具体地,针对待分析的小样本目标,选择另一种数据量较多且与目标样本理化性质和元素组成相似的样本作为辅助样本,根据拥有的辅助样本数据建立分析模型,并从中筛选有效数据,通过boosting方法建立权重调整机制,增加有效数据权重,降低无效数据权重;在分类算法实施的过程中,过滤掉与目标样本不匹配的辅助样本数据,使得元素分类朝正确的方向进行,进而实现在原有的大量辅助样本模型的基础上迁移至目标样本元素分类,并能够准确地预测。
6.为实现上述目的,本发明的技术方案如下:
7.一种基于svm-tradboost模型迁移的xrf小样本元素分类方法,包括以下步骤:
8.步骤1:通过xrf荧光光谱仪获取目标样本待分类元素的峰值数据,构成源样例空
间数据集xb,同时获取若干个与目标样本元素组成相似的辅助样本的峰值数据,构成辅助样例空间数据集xa,同时对源样例空间数据集和辅助样例空间数据集中的峰值数据进行预处理;
9.步骤2:选定训练集x和测试集s,其中,将源样例空间数据集xb随机划分为两个子数据集x
b1
和x
b2
,所述训练集x包含源样例空间子数据集x
b1
和为辅助样例空间xa中的所有数据,测试集s为源样例空间子数据集x
b2
;
10.步骤3:设定类别空间,按照预设分类条件构建类别空间矩阵y;
11.步骤4:基于训练集x与类别空间矩阵y构造最终训练数据集t,具体构造形式为,t∈{(x=x
b1
∪xa)
×
y};
12.步骤5:初始化权重向量w1、权重分布p
t
与迭代次数n;其中,
[0013][0014]
其中,n为辅助样例空间数据集的大小,即与目标样本不同分布的数据集xa中所含数据的个数;m为源样例空间子数据集的大小,即与目标样本同分布的子数据集x
b1
中所含数据的个数;
[0015]
权重分布表达式为:
[0016]
当t=1时,w
t
=w1,
[0017]
基于初始化权重向量w1对最终训练数据集t中每个峰值数据的权重进行归一化处理;
[0018]
步骤6:定义svm分类算法中的高斯核函数及相关参数;
[0019]
定义高斯核函数为,
[0020]
k(xu,xv)=exp(-γ||x
u-xv||2),
[0021]
其中,k为核函数,xu,xv为训练集x中每一个数据的特征内积,γ为超参参数,需要进行调参;
[0022]
根据测试集s、步骤4得到的训练数据集t,以及t上的权重分布p
t
,基于svm算法,得到一个在测试集s上的弱分类器h
t
:x
→
y;
[0023]
步骤7:计算弱分类器h
t
在源样例空间子数据集x
b1
上的错误率ε
t
,具体计算公式为:
[0024][0025]
其中,c(xi)为布尔函数,即从x到y的映射,xi为训练集x中的第i个数据;
[0026]
步骤8:设置新的权重向量根据步骤7中错误率ε
t
的结果调整权重,对分类没有用的数据降低权重,有用的提升权重,从而使分类准确率上升,具体为:
[0027][0028]
其中,β与β
t
分别为辅助样例空间数据集xa与源样例空间子数据集x
b1
权重调整的速率;
[0029]
步骤9:重复步骤5至步骤8,直至达到迭代次数n,即可得到最终分类器hf(x),,
[0030][0031]
步骤10:将测试集s中待分类的目标样本xrf元素峰值数据输入到步骤9得到的最终分类器hf(x),即可得到目标样本待测数据的分类结果。
[0032]
进一步地,步骤1中的预处理包括去噪、去除本底等操作。
[0033]
进一步地,步骤1中辅助样本与目标样本元素组成相似即辅助样本与目标样本至少含有8中相同元素,且应含有与目标样本待分类元素相同的元素;辅助样本峰值数据数量至少应大于目标样本数据数量。
[0034]
进一步地,步骤2中测试集s为源样例空间子数据集x
b2
,具体为:j=1,2,
…
,k,k为测试集s中包含的数据数量,t=1,
…
,n,n为迭代次数。
[0035]
进一步地,步骤3中设定类别空间即按照分类条件,设z={-1,1}为类别空间,若大于分类条件阈值,则标记为1,小于或等于阈值,则标记为-1;对训练集中的所有数据都进行标记,从而得到类别空间矩阵y。
[0036]
进一步地,步骤6中相关参数还包括惩罚系数c,惩罚系数c为大于0的实数;γ为正实数。
[0037]
进一步地,步骤7中的错误率ε
t
的值应小于1/2。
[0038]
进一步地,步骤8中,辅助样例空间数据集xa的权重调整速率β具体为,源样例空间子数据集x
b1
的权重调整速率β
t
具体为,β
t
=ε
t
/(1-ε
t
)。
[0039]
综上所述,由于采用了上述技术方案,本发明的有益效果是:
[0040]
本发明可以有效利用已有关联性辅助样本数据来分类未知且只具有少量样本的待分类目标数据。当一个辅助训练的数据被误分类,那么这个数据可能和待测目标的训练数据是矛盾的,那么就降低这个数据的权重;在若干次迭代以后,辅助样本数据中符合目标样本数据特征的数据会拥有更高的权重,而不符合目标样本数据的权重会降低。因此可以针对少量样本的情况,利用原本不具有相同分布的其它数据进行分析,达到快速分类的目的。本发明方法增强了xrf分类模型的通用性,即当光谱发生变化、样品种类发生改变时,减少了建立新模型需要大量的测试数据带来的样本材料和成本浪费;同时解决了少量样本模型建立困难的问题。本发明方法可以扩展至大多数的样本xrf分类检测领域,具普遍意义和通用性。
附图说明
[0041]
图1为本发明元素分类方法的流程示意图。
[0042]
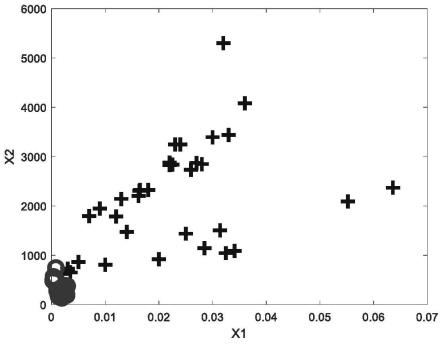
图2为本发明实施例1的训练数据集图。
[0043]
图3为本发明实施例1的最终分类结果图。
[0044]
图4为对比例1仅使用svm算法的分类结果图。
具体实施方式
[0045]
为使本发明的目的、技术方案和优点更加清楚,下面结合实施方式和附图,对本发明作进一步地详细描述。
[0046]
一种基于svm-tradboost模型迁移的xrf小样本元素分类方法,包括以下步骤:
[0047]
步骤1:通过xrf荧光光谱仪获取目标样本待分类元素峰值数据,构成源样例空间数据集xb,同时获取若干个与目标样本元素组成相似的辅助样本峰值数据,构成辅助样例空间数据集xa,同时对源样例空间数据集和辅助样例空间数据集中的光谱峰值数据进行预处理;
[0048]
步骤2:选定训练集x和测试集s,其中,将源样例空间数据集xb随机划分为两个子数据集x
b1
和x
b2
,所述训练集x包含源样例空间子数据集x
b1
和为辅助样例空间xa中的所有数据,测试集s为源样例空间子数据集x
b2
;
[0049]
步骤3:设定类别空间,按照预设分类条件构建类别空间矩阵y;
[0050]
步骤4:基于训练集x与类别空间矩阵y构造最终训练数据集t,具体构造形式为,t∈{(x=x
b1
∪xa)
×
y};
[0051]
步骤5:初始化权重向量w1、权重分布p
t
与迭代次数n;其中,与迭代次数n;其中,
[0052]
其中,n为辅助样例空间数据集的大小,即与目标样本不同分布的数据集xa中所含数据的个数;m为源样例空间子数据集的大小,即与目标样本同分布的子数据集x
b1
中所含数据的个数;
[0053]
权重分布表达式为:
[0054]
当t=1时,w
t
=w1,
[0055]
基于初始化权重向量w1对最终训练数据集t中每个峰值数据的权重进行归一化处理;
[0056]
步骤6:定义svm分类算法中的高斯核函数及相关参数;
[0057]
定义高斯核函数为,
[0058]
k(xu,xv)=exp(-γ||x
u-xv||2),
[0059]
其中,k为核函数,xu,xv为训练集x中每一个数据的特征内积,γ为超参参数,需要进行调参;
[0060]
根据测试集s、步骤4得到的训练数据集t,以及t上的权重分布p
t
,基于svm算法,得到一个在测试集s上的弱分类器h
t
:x
→
y;
[0061]
步骤7:计算弱分类器h
t
在源样例空间子数据集x
b1
上的错误率ε
t
,具体计算公式为:
[0062][0063]
其中,c(xi)为布尔函数,即从x到y的映射,xi为训练集x中的第i个峰值数据;
[0064]
步骤8:设置新的权重向量根据步骤7中错误率ε
t
的结果调整权重,对分类没有用的数据降低权重,有用的提升权重,从而使分类准确率上升,具体为:
[0065][0066]
其中,β与β
t
分别为辅助样例空间数据集xa与源样例空间子数据集x
b1
权重调整的速率;β
t
=ε
t
/(1-ε
t
);
[0067]
步骤9:重复步骤5至步骤8,直至达到迭代次数n,即可得到最终分类器hf(x),
[0068][0069]
步骤10:将测试集s中待分类的目标样本xrf元素峰值数据输入到步骤9得到的最终分类器hf(x),即可得到目标样本待测数据的分类结果。
[0070]
实施例1
[0071]
本实施例根据已拥有的大量土壤样本数据的分析模型与少量中药样本数据,从原土壤样本数据中,筛选有效数据,过滤掉与目标中药样本不匹配的数据,通过boosting方法建立权重调整机制,增加有效数据权重,降低无效数据权重,使得分类朝正确的方向进行,进而实现在原有的土壤模型的基础上迁移至中药重金属元素分类并能够准确地预测。
[0072]
一种检测中药中重金属元素pb是否超标的分类方法,元素定性分类方法的流程示意图如图1所示,具体步骤如下:
[0073]
步骤1:通过xrf荧光光谱仪获取25份中药金银花样本中待分类的重金属pb元素的峰值数据,构成源样例空间数据集xb,同时获取59份土壤辅助样本峰值数据,构成辅助样例空间数据集xa,同时对源样例空间数据集和辅助样例空间数据集中的光谱数据进行预处理,具体地,对采集到的元素峰值谱图进行去除本底信息,得到pb元素的峰值信息;
[0074]
步骤2:选定训练集x和测试集s,其中,将源样例空间数据集xb随机划分为两个子数据集x
b1
和x
b2
,所述训练集x包含源样例空间子数据集x
b1
和为辅助样例空间xa中的所有数据,测试集s为源样例空间子数据集x
b2
;具体为:j=1,2,
…
,k,k为测试集s中包含的数据数量,t=1,
…
,n,n为迭代次数;
[0075]
其中,源样例空间子数据集x
b1
作为同分布的少量训练数据集,辅助样例空间xa为不同分布的训练数据集,所有训练集数据如图2所示;
[0076]
步骤3:设定类别空间,按照预设分类条件构建类别空间矩阵y,具体过程为:设定类别空间即按照分类条件,设z={-1,1}为类别空间,对训练集x中的所有数据进行类别标记,若pb元素超标,则标记为1,否则标记为-1;
[0077]
步骤4:基于训练集x与类别空间矩阵y构造最终训练数据集t,具体构造形式为,t∈{(x=x
b1
∪xa)
×
y};
[0078]
步骤5:初始化权重向量w1、权重分布p
t
与迭代次数n;其中,
[0079][0080]
其中,n为辅助样例空间数据集的大小,即与目标样本不同分布的数据集xa中所含数据的个数;m为源样例空间子数据集的大小,即与目标样本同分布的子数据集x
b1
中所含数据的个数;
[0081]
权重分布表达式为:
[0082]
当t=1时,w
t
=w1,
[0083]
基于初始化权重向量w1对最终训练数据集t中每个峰值数据的权重进行归一化处理;
[0084]
步骤6:定义svm分类算法中的高斯核函数及相关参数;
[0085]
定义高斯核函数为,
[0086]
k(xu,xv)=exp(-γ||x
u-xv||2),
[0087]
其中,k为核函数,xu,xv为训练集x中每一个数据的特征内积,γ为超参参数,需要进行调参,并定义惩罚系数c;具体地,c=200,γ=0.6,迭代次数n=50;
[0088]
根据测试集s、步骤4得到的训练数据集t,以及t上的权重分布p
t
,基于svm算法,得到一个在测试集s上的弱分类器h
t
:x
→
y;
[0089]
步骤7:计算弱分类器h
t
在源样例空间子数据集x
b1
上的错误率ε
t
,具体计算公式为:
[0090][0091]
其中,c(xi)为布尔函数,即从x到y的映射,xi为训练集x中的第i个峰值数据;
[0092]
步骤8:设置新的权重向量根据步骤7中错误率ε
t
的结果调整权重,对分类没有用的数据降低权重,有用的提升权重,从而使分类准确率上升,具体为:
[0093][0094]
其中,β与β
t
分别为辅助样例空间数据集xa与源样例空间子数据集x
b1
权重调整的
速率;β
t
=ε
t
/(1-ε
t
);
[0095]
步骤9:重复步骤5至步骤8,直至达到迭代次数n,即可得到最终分类器hf(x),,
[0096][0097]
步骤10:将测试集s中待分类的金银花样本xrf元素峰值数据输入到步骤9得到的最终分类器hf(x),即可得到待测金银花样本的分类结果。
[0098]
本实施例得到的金银花中pb元素是否超标的分类结果如图3所示。
[0099]
对比例1
[0100]
仅采用svm算法对相同待测金银花样本进行pb元素是否超标进行分类。
[0101]
本对比例的分类结果如图4所示。
[0102]
图2为本发明实施例1的训练数据集图。从图中可以看出,十字形标记代表辅助样例空间即土壤样本,圆圈标记代表源样例空间,即中药样本。从图中可以看出,两种物质具有不同的样本分布。
[0103]
图3为本发明实施例1的最终分类结果图。从图中可以看出,圆圈中有十字标记代表分类错误,没有标记代表分类正确,明显看出图3相对于图4,其分类错误的样本更少。本发明方法分类的准确率可达96%。图4为对比例1仅使用svm算法的分类结果图,可以看出,仅使用svm算法进行分类的准确率仅为84%,相较于本发明低了12个百分点。
[0104]
因此,本发明基于svm-tradboost算法能够实现使用与待测样本不同分布的其他大量有效数据进行模型迁移训练,提高了小样本分类模型的准确预测,证明了实施例的有效性。
[0105]
以上所述,仅为本发明的具体实施方式,本说明书中所公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换;所公开的所有特征、或所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以任何方式组合。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
