一种基于深度强化学习的efsm输入序列生成方法
技术领域
1.本发明属于基于模型的测试用例生成领域,具体涉及一种基于深度强化学习的efsm输入序列生成方法。
背景技术:
2.软件测试是使用人工或自动的手段来运行或测定某个软件系统的过程,其目的在于检验软件系统是否满足规定的需求或弄清预期结果与实际结果之间的差别。从测试过程是否需要执行待测程序的角度,软件测试方法可分为静态测试和动态测试,静态测试方法不运行被测软件,只是静态地检查程序代码、界面或文档中可能存在的错误,而动态测试方法是指通过运行被测程序,检查运行结果与预期结果的差异,并分析运行效率、正确性和健壮性等性能。
3.动态测试方法由三部分组成:构造测试用例、执行程序、分析程序的输出结果。测试用例生成这一步至关重要,而在众多自动化测试用例生成方法中,基于模型的测试是一种常见的测试方法,主要过程是在不同的抽象层次上创建软件状态行为模型,然后利用该模型生成测试用例,以揭示缺陷并验证实现是否符合其规范。其中最为广泛使用的是扩展有限状态机(efsm)。efsm是一种由有限数量的状态、状态之间的变迁组成的行为模型,它可以用有限的输入/输出参数集、状态转换函数和输出函数来描述,同时包含控制部分和数据部分。
4.目前,针对efsm生成测试序列的研究主要都是使用基于搜索的算法,遗传算法的单一使用可能会限制结果并扼杀创造力,而且这些算法需要在搜索测试数据之前手动详细说明,这会限制测试数据生成的质量和效率。此外,对于每个测试数据生成,这些方法通常必须启动一个新的迭代搜索过程,难以使用之前的搜索经验,也减少了进一步提升性能的机会。因此,如何快速高效地得到输入序列,在频繁需要测试数据的场景中能够减少输入序列生成带来的时间开销是当前急需解决的问题。
5.深度强化学习(drl)是深度学习和强化学习的结合。drl的主要目标是通过与环境的交互来训练智能体,以尝试和错误的方式学习解决顺序决策问题的最佳行为。依托深度学习强大的感知能力,drl突破了传统强化学习的规模限制,可以应用于具有高维状态和动作空间的决策任务。例如,在玩游戏中的出色成功显示了其超人的水平。
6.因此,如果能基于drl提供一种新颖的方法来有效地自动生成efsm输入序列,则在软件测试领域是一大突破。
技术实现要素:
7.针对以上背景与问题,本发明提出了一种基于深度强化学习的efsm输入序列生成方法,将输入序列生成问题看作是一个复杂的优化问题,求解最优解的过程就是利用元启发式算法对可执行路径中的每条变迁搜索满足其谓词判断条件的输入参数解。其中,元启发式算法被使用强化学习算法训练好的智能体来代替,智能体通过在本发明设计的动作空
间内选择动作来改变输入参数的值,然后根据奖赏函数获取对应的奖赏值以指导下一步动作的选择。
8.本发明具体步骤如下:
9.(1)基于efsm抽象模型搭建深度强化学习算法所需的深度强化学习环境:从软件的规格说明中提取出efsm抽象模型,按照深度强化学习算法的组成要素,设计将efsm抽象模型作为深度强化学习环境要实现的奖赏函数、状态空间和动作空间,对状态空间和动作空间进行初始化,并完成reset()和step()方法的实现,其中,reset()方法用于在每个回合重置深度强化学习环境的状态,step()方法接收来自智能体给出的动作以改变深度强化学习环境得到下一个时刻的深度强化学习环境状态,并调用奖赏函数给出当前动作的奖励反馈,来决定是否结束当前回合;
10.(2)智能体训练:将efsm抽象模型中谓词判断条件包含输入参数的所有变迁提取出来,作为目标训练集,通过不断的试错和交互,智能体便能够很好地指导生成合适的输入参数来触发目标训练集中的每一条变迁;训练结束后,得到各个状态机的决策模型,决策模型中包含用于指导深度强化学习环境输入序列生成的高级决策信息;
11.(3)输入序列生成:使用训练好的智能体为已有的可执行测试路径生成相应的输入序列集。
12.优选地,所述步骤(1)中奖赏函数的设计如下:
13.r
t
=f(ipd
t-1
)-f(ipd
t
)
14.其中,ipd
t
表示用来触发t时刻对应状态目标变迁的输入参数数据,ipd
t-1
全称表示用来触发t-1时刻对应状态目标变迁的输入参数数据,f是适应度函数,用来奖励能够满足谓词判断条件的输入参数数据,输入参数数据越容易触发目标变迁,f的值越小。
15.优选地,所述步骤(1)中状态空间的设计如下:
16.s
t
=(t
t
,d
t
)
17.其中t
t
表示t时刻学习的目标变迁,d
t
表示t时刻的偏差向量(d0,d1,d2,
…
,di,
…
,d
n-1
),偏差向量长度等于efsm抽象模型的输入参数向量v
ip
的长度,而偏差向量d
t
中的元素di取值为v
ip
中第i个输入参数为满足当前变迁谓词判断条件与上下文变量或者常量之间的偏差值。
18.优选地,所述偏差向量d
t
中元素di的取值有两种情况:
19.1)目标变迁t
t
的谓词判断条件仅有一个原子条件,输入参数vi,i=1,
…
,n∈v
ip
的偏差值di计算如下:
[0020][0021]
其中n为输入参数数目,t_value是目标变迁ti谓词判断条件的to-be-true值,谓词判断条件采用(e
l
δer)的表达形式,e
l
和er分别是原子条件的左表达式和右表达式,而δ∈{》,≥,《,≤,=,≠}表示关系运算符,为了计算方便,首先需要将每个原子条件归一化为新的形式(e
l’δe
r’),e
l’标准化为仅包含输入参数的表达式,而e
r’标准化为由上下文变量和常量组成的表达式,所以ip(e
l’)是出现在原子条件表达式中的输入参数集合,|ip(e
l’)|
是该集合的大小;
[0022]
2)变迁ti的谓词判断条件由多个原子条件通过and和or组合起来,如果输入参数vi出现在其中一个原子条件中,其偏差值的计算方法与情况1)相同;否则,对于输入参数vi同时出现在由or组合的多个原子条件中的情况,使用原子条件中to_be_true值的绝对值最小的那个作为最终偏差值di,对于输入参数vi同时出现在由and组合的多个原子条件中的情况,分配原子条件中to_be_true值的绝对值最大的那个作为最终偏差值di。
[0023]
优选地,所述的to-be-true值描述了一个谓词判断条件被满足的难易程度,对谓词判断条件归一化为(e
l’δe
r’)形式后,根据表1中的建议规则计算其to-be-true值:
[0024]
表1to-be-true值
[0025][0026]
其中,函数eval(e)用来解析表达式e并计算表达式e在代入变量具体值后的结果,efsm抽象模型中布尔值类型的变量取值true和false分别被编码为1和0;按照上面的计算规则,可知to-be-true的绝对值越小,当前输入数据越容易满足这个谓词判断条件,具体来说,0表示该谓词判断条件已被满足,当值为正时,表明需要增大一些输入参数的值以满足所考虑的谓词判断条件,否则,需要减小一些输入参数的值。
[0027]
优选地,所述步骤(1)中动作空间的设计如下:
[0028][0029]
其中,n等于v
ip
的长度,动作空间的大小是输入变量长度的两倍,当第j个动作被选择时,j为奇数时智能体对第(j 1)/2个变量进行up操作,j为偶数时智能体对第j/2个变量进行down操作;重要的是,由于单步操作大大增加了试错步数,因此每个操作不限于' '或'-',up操作是' '和'
×
'的集成,down操作混合了'-'和'//',其中'//'表示整除,up和down的实现细节如下所示:
[0030][0031][0032]
其中vi是v
ip
中的第i个输入参数,表示t-1时刻vi的具体值,表示对t-1时刻的vi值进行2倍赋值所得值,表示t-1时刻的vi值对2进行整除所得值;对于t时刻的up操作,如果的适应度值小于或等于的适应度值,
则vi的值重新赋值为否则重新赋值为对于t时刻的down操作,如果的适应度值小于或等于的适应度值,则vi的值重新赋值为否则重新赋值为
[0033]
优选地,所述步骤(2)中每一个回合的目标训练变迁按照round-robin(轮询调度)模式循环地从目标训练集进行选择,将随机初始化的输入参数和当前回合训练变迁对象输入训练模型中,智能体根据步骤(1)中设计的状态空间得到对深度强化学习环境的观察信息,即当前状态,智能体根据训练经验(第一个训练回合中经验为0,随着训练回合的增加,智能体经验越丰富),从步骤(1)中的动作空间选择某个行为并执行,深度强化学习环境根据步骤(1)中的step()方法从当前状态转换到下一个新的状态,对于新的状态深度强化学习环境按照步骤(1)中的奖赏函数得到智能体此行为得到的奖励反馈。重复上述过程,通过不断的试错和交互,智能体便能够很好地指导生成合适的输入参数来触发目标训练集中的每一条变迁,最后得到决策模型。
[0034]
优选地,所述步骤(3)具体如下:从已有的可执行测试路径集中读取测试路径,对于需要生成输入数据的每个变迁使用已经训练好的智能体指导输入参数的改变以获取能够触发变迁的数据值,进而得到可执行测试路径集中每一条测试路径的输入序列,从而生成相应的输入序列集。
[0035]
与现有技术相比,本发明具有的有益效果是:
[0036]
本发明将深度强化学习首次应用在efsm模型的输入序列生成中,与经典的基于搜索的方法(如遗传算法)相比,所提出的方法不限于手动设计或选择某种元启发式算法。最重要的是,本发明可以自动从历史输入生成中推导出决策模型,并学习测试场景和输入推导行为之间的潜在关系。因此,基于决策模型,本发明可以根据各种客观测试路径有效地生成新的输入序列,可以有效地提高efsm模型输入序列生成的效率和成功率,并能够在进行回归测试和测试用例生成应用中有效地减少输入序列生成的时间开销。
附图说明
[0037]
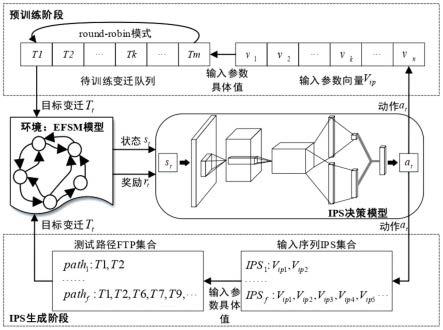
图1为本发明drl-ipsg整体框架示意图。
[0038]
图2为本发明drl-ipsg在预训练阶段中对五个efsm模型的训练情况示意图。
[0039]
图3为本发明drl-ipsg、遗传算法和随机算法对不同输入参数取值范围的敏感性比较示意图。
具体实施方式
[0040]
参阅图1,本发明一种基于深度强化学习的efsm输入序列生成方法(以下简称drl-ipsg)主要包括两个阶段:预训练阶段和ips(输入序列,input parameter sequences)生成阶段。预训练阶段的主要任务是构建基于被测efsm的决策模型。训练后的模型意味着从状态到动作的映射,基于此,智能体可以利用最优策略来有效地导出合适的输入参数值。由于drl-ipsg的目标是为变迁序列生成ips(ips为包含所有序列ipsi,i=1,2,
…
,f的集合,f为候选可行测试路径pathi的数目;每个序列ipsi中包含数目与候选可行测试路径pathi中变迁数目相同的输入参数向量v
ip
,图1中用v
ipi
,l=1,2,
…
来表达各不同的v
ip
),因此它只关
注带有包含输入参数的谓词判断条件的变迁。显然,任何输入都可以触发其他变迁。因此,给定一个efsm模型,它需要搜索合适的输入值的变迁tk,k=1,2,
…
,m被收集在一个队列中。对于模型训练过程中的每一回合,从队列中选择一个变迁作为训练目标t
t
。为了防止模型过度拟合,drl-ipsg应用round-robin模式来挑选队列中的每个变迁。在每一个回合中,输入参数和上下文变量的初始值都在一个值区间内随机重置。在某一回合的t时刻,智能体根据当前状态,从动作空间中选择动作a
t
(t时刻的当前动作)来调整输入参数的值。然后efsm模型检查当前目标变迁的可行性并给出相应的奖励。每个回合的终止条件是找到一组输入参数值来执行所考虑的变迁或达到最大预设时间步长。重复这些步骤并最终构建一个最优策略逼近器(训练有素的深度神经网络)以实现最大的预期回报。在本实施例中,每个efsm的训练回合设置为105。在ips生成阶段,一旦生成了候选可行测试路径pathi,i=1,2,
…
,f,智能体就可以依靠训练好的模型快速推导出ipsi。更具体地说,ips生成可以依次划分为每个变迁的一系列子任务。对于需要生成输入数据的每个变迁,drl-ipsg加载预训练模型并开始新一轮强化学习阶段,就像预训练过程一样。因此,当每个考虑的变迁找到一组合适的输入数据时,将生成pathi的ipsi。由于强化学习固有的随机特性,同一测试路径每次生成的ipsi可能不同。此外,基于训练模型的ips推导还涉及在线学习过程,决策模型将不断更新,进一步提高其泛化能力。
[0041]
为了验证所提出方法的有效性和可行性,针对五个经典的efsm模型进行了一系列实验,五个efsm模型的具体信息如表2所示,其中测试路径集的测试路径数最大有1327条,使用本发明方法对五个模型的测试路径集进行实验,并与随机算法、遗传算法进行比较。
[0042]
表2efsm模型具体信息
[0043][0044]
如图2中(a)-(e)所示,针对这5个模型,drl-ipsg预训练阶段智能体学习过程中每一回合获取的奖励在不断收敛,尽管有些模型后期的波动很小;所有模型在训练过程中的平均奖励都随着训练次数的增加而波动式上升,如图2中(f)所示。这说明本发明中提出的状态空间、动作空间的设计是合理且高效的。
[0045]
本发明从试错次数、成功率、运行成本(时间开销)、输入参数取值范围敏感性四个方面衡量输入序列生成算法的性能。
[0046]
表3试错次数统计结果
[0047][0048][0049]
表3记录了五个efsm模型分别采用随机算法(random)、遗传算法(ga)和本发明方法(drl-ipsg)的试错次数统计结果,其中,min表示最小值,max表示最大值,avg表示均值。可以看到,drl-ipsg方法在输入序列生成中的总体平均值(total)仅为随机算法在输入序列生成中总体平均值(记为vs.random)的32.950%,仅为遗传算法在输入序列生成中总体平均值(记为vs.ga)的45.402%。同时,由于给定范围内的变量不能满足某些变迁的执行条件,一些路径无法通过随机算法和遗传算法成功生成输入序列。因此,对于实际结果,本发明提出的方法比其他两种方法更加有效地减少迭代次数。其中在最简单的m2模型上,随机算法和遗传算法的效果差别不是很大,drl-ipsg的试错次数也仅是他们的95.349%。而在m4模型上,drl-ipsg与遗传算法相比,效果相差不大,经过不断观察与验证,这是由于m4模型中的变迁谓词判断条件中关系运算符大部分是容易满足的大于或小于条件,满足触发条件的输入参数值可取范围更广。
[0050]
表4为不同算法对五个模型测试路径集的输入序列生成成功率s,其中μ表示成功率平均值,σ表示成功率的标准差,在一定的迭代次数限制下,drl-ipsg能够为所有模型的测试集生成输入序列,而遗传算法和随机算法则做不到,除了m2,这是由于m2的变量都是布尔类型,比较容易找到合适的值。
[0051]
表4输入序列生成成功率
[0052]
[0053][0054]
表5显示了通过遗传算法和drl-ipsg分别为五个efsm模型生成输入序列的运行成本。就五个模型的总体平均数据而言,drl-ipsg平均需要花费6.076秒来生成输入序列,遗传算法平均需要12.438秒来生成输入序列,这大约是drl-ipsg的2倍。此外,在100次重复运行期间,遗传算法的运行成本在0.497范围内波动,而drl-ipsg的运行成本在0.361范围内波动,drl-ipsg的运行成本误差比遗传算法的小0.136。
[0055]
表5运行成本
[0056][0057]
图3中(a)-(e)显示了随机方法、遗传算法和本发明提出的方法对m1,m2,m3,m4,m5的测试集在不同输入参数取值范围内的成功率(关于输入参数取值范围敏感性的性能),如果成功率随输入范围的变化不大则表明算法对输入参数范围的敏感性不高,反之则对输入参数范围的敏感性较高。从图中可以看到,无论初始范围如何,drl-ipsg都可以100%成功地生成m1、m2和m3的输入序列。虽然m4和m5无法在其他输入范围内生成100%的输入序列,但变化程度非常小,除了[0,1000]之外,成功率都在95%以上。针对m5,即使输入范围为[0,1000],drl-ipsg生成输入序列的成功率仍然高于[0,200]范围内遗传算法和随机方法生成输入序列的成功率。在[0,1000]范围内,m5遗传算法的成功率为8.66%,随机方法的成功率为1.73%,均小于drl-ipsg的成功率(90.32%)。而在m4中,drl-ipsg随输入范围成功率减小而减小的平均幅度为0.5,遗传算法的减小幅度为1.43,因此从减小幅度来看,drl-ipsg应用在m4时仍然比遗传算法有优势。尽管如此,随机算法减小幅度比drl-ipsg更小,这是由于m4测试路径集包含的谓词判断条件中,关系运算符仅包含3.39%的“=”,当输入范围增大时,随机算法比drl-ipsg和遗传算法能更快的找到满足由“》”,“《”,“≥”或“≤”连接的谓词判断条件的输入参数值。
[0058]
综上所述,本发明可以有效地提高efsm模型输入序列生成的效率和成功率,比起广泛使用的遗传算法,本方法能够充分有效地利用历史经验,实现一次训练多次使用,在进行回归测试和测试用例生成应用中有效地减少输入序列的生成带来的时间开销。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。