1.本发明实施例涉及机器学习技术领域,尤其涉及一种基于模型迁移的高效联邦训练方法和装置。
背景技术:
2.现有技术中,针对边缘计算网络中非独立同分布数据和资源受限带来的联邦模型训练性能下降问题已经提出了一些技术方案,主要包括以下几种:
3.(1)为了解决边缘计算网络中由于非独立同分布数据引起的模型训练性能下降的问题,一些工作提出通过转发全局的数据来让每个工作节点能够在逻辑上的大数据集上进行训练,也就是说每个节点上的模型能够在独立同分布的数据集上进行训练,以此来提高整体的训练性能。(2)为了减少网络中的通讯消耗,一些工作提出通过动态调节每个节点的本地训练轮数,当网络中资源比较丰富时,本地进行较少的训练轮数即可上传到远程服务器进行全局更新;而当网络中资源缺乏时,本地可以进行较多的训练轮数后再进行上传,这样能够节省网络资源的同时也能保证联邦模型训练的性能。另外一些工作通过提出异步的训练方式来节省网络资源,也就是说服务器端不需要等收到所有的本地模型再进行全局更新,而是收到一个或者部分时就可以进行聚合,这样的做法能够大大减少网络带宽消耗,同时也能缓解因为某些训练缓慢节点导致的全局等待问题。
4.然而上述现有技术方案,不能够同时解决边缘计算网络中非独立同分布数据和资源受限带来的问题,往往只能解决其中某一项。例如,通过服务器将全局共享数据分发给所有的客户端,往往造成非常大的网络资源消耗;而所提出的减少资源消耗的方法,又不能很好地解决非独立同分布数据带来的模型训练性能下降问题。
技术实现要素:
5.为了解决现有技术中的问题,本发明提供一种基于模型迁移的高效联邦训练方法和装置,通过将每个客户端的本地模型在其他更多的客户端节点上进行更新,从而实现在逻辑上的独立同分布数据集上训练,提高整体训练性能,并且做到快速收敛,减少训练轮数和网络资源消耗。
6.第一方面,本发明实施例提供了一种基于模型迁移的高效联邦训练方法,包括:
7.s110、服务器将目标任务的全局模型分发至各本地客户端;
8.s120、所述各本地客户端对接收到的全局模型进行训练,并在完成本地训练后向所述服务器发送训练完成信号;
9.s130、所述服务器基于预设算法确定本地模型迁移训练策略并将所述迁移训练策略下发给所述各本地客户端;
10.s140、所述各本地客户端根据所述迁移训练策略将自身更新好的本地模型迁移到其他本地客户端继续进行训练,并在执行完所述迁移训练策略后将本地模型参数上传至服务器。
11.可选的,所述服务器基于预设算法确定本地模型迁移训练策略,包括:
12.所述服务器采用强化学习训练drl代理的方法确定本地模型迁移策略。
13.可选的,所述服务器采用强化学习训练drl代理的方法确定本地模型迁移策略,包括:
14.将所述各本地客户端的数据分布、资源使用和训练状态作为输入,输出每一个动作的概率值,选取最高概率的动作以得到最优的本地模型迁移策略。
15.可选的,所述本地模型迁移策略中的参与迁移的本地客户端数量小于联邦训练系统中所有的本地客户端数量。
16.第二方面,本发明实施例还提供了一种基于模型迁移的高效联邦训练装置,包括:
17.全局模型分发模块,用于通过服务器将目标任务的全局模型分发至各本地客户端
18.本地模型训练模块,用于通过所述各本地客户端对接收到的全局模型进行训练,并在完成本地训练后向所述服务器发送训练完成信号
19.迁移策略确定模块,用于通过所述服务器基于预设算法确定本地模型迁移训练策略并将所述迁移训练策略下发给所述各本地客户端
20.迁移策略执行模块,用于通过所述各本地客户端根据所述迁移训练策略将自身更新好的本地模型迁移到其他本地客户端继续进行训练,并在执行完所述迁移训练策略后将本地模型参数上传至服务器。
21.本发明的有益效果:
22.1、本发明实施例通过在本地客户端进行模型迁移,解决了非独立同分布数据和资源受限带来的模型训练性能下降问题,通过模型迁移能够显著提升模型测试精度。
23.2、本发明提出使用强化学习的方法来对客户端的模型训练和网络资源状态进行实时监测,并计算出最优的模型迁移策略,让客户端的模型根据此策略来进行迁移,能够减少整体模型训练时间和网络资源(如带宽)的消耗。
附图说明
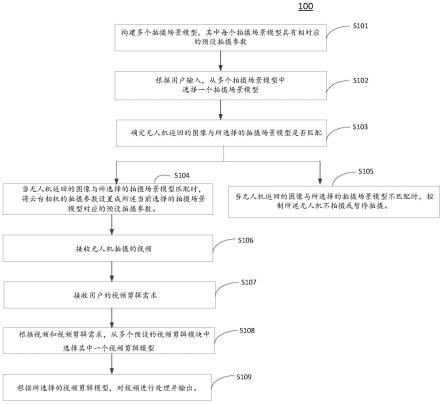
24.图1为本发明实施例提供的基于模型迁移的高效联邦训练方法的流程图。
具体实施方式
25.下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
26.实施例
27.图1为本发明实施例提供的基于模型迁移的高效联邦训练方法的流程图,具体包括以下步骤:
28.s110、服务器将目标任务的全局模型分发至各本地客户端;
29.s120、所述各本地客户端对接收到的全局模型进行训练,并在完成本地训练后向所述服务器发送训练完成信号;
30.s130、所述服务器基于预设算法确定本地模型迁移训练策略并将所述迁移训练策略下发给所述各本地客户端;
31.本实施例中,当服务器接收到本地客户端发送的训练完成信号后,随机利用强化学习方法对迁移策略进行计算,然后将迁移策略下发给客户端。
32.具体的,本实施例中采用强化学习(deep deterministic policy gradient,ddpg)方法来训练drl代理,结合网络资源和模型训练分别定义了状态空间、动作空间和奖励函数。在训练过程中,drl代理将客户端的数据分布、资源使用和训练状态作为输入,输出每一个动作的概率值,通过选取最高概率的动作来得到最优的模型迁移策略,因此本实施例所提供的智能迁移方法能使得本地模型在更大数据集上进行训练,与现有技术中的随机迁移策略相比,具备更好的模型训练性能。
33.进一步的,本实施例中本地模型迁移策略中的参与迁移的本地客户端数量小于联邦训练系统中所有的本地客户端数量,即在客户端间进行模型迁移时,本实施例中是绝大部分在客户端间进行模型迁移,当出现端到端链路非常慢时,会经过服务器端进行转发,能够有效的缓解现有技术中全部通过服务器进行转发而带来的高通信负载,容易产生拥塞等问题。
34.s140、所述各本地客户端根据所述迁移训练策略将自身更新好的本地模型迁移到其他本地客户端继续进行训练,并在执行完所述迁移训练策略后将本地模型参数上传至服务器。
35.本实施例中,在进行固定次数迁移后,所有客户端再将模型全都上传给参数服务器。
36.这样做的好处是每个客户端的本地模型可以在其他更多的客户节点上的数据进行更新,从而实现在逻辑上的独立同分布数据集上训练,提高整体训练性能,并且做到快速收敛,减少训练轮数和网络资源消耗。
37.实验验证
38.进一步的,通过一些仿真和真实测试床的实验来验证本发明技术方案的有益效果。
39.现有一些方案技术包括fedavg[6],fedswap[7],fedprox[8]和randmigr,其中fedavg是经典的方法,即收到有指定的客户端发送的模型才进行全局更新;fedswap是通过在服务器端对两个客户端的模型进行交换,以减少非独立同分布数据带来的影响;fedprox通过对异构数据和系统的感知,在fedavg的基础上进行细小的改动,从而能够改善模型训练性能;randmigr在客户端间进行随机迁移。
[0040]
在实验数据和模型方面,本实施例采用经典的cifar10数据集和卷积神经网络(cnn)模型。cifar10包含60000张32x32并且分为10类的彩色图片(其中50000张用来训练,10000张用来测试)。具体实验效果如下表所示:
[0041]
表1:五种方案在不同数据分布下的测试精度
[0042][0043]
从表中可以看出,在独立同分布数据(iid)中,每种方案的测试精度都差不多,主要是由于每个客户端上的数据都是相同的分布,迁移或者交换策略对整体的训练性能影响不大。然而在非独立同分布数据(non-iid)中,每一种方案的精度差异较大,并且整体都比iid数据差,这也是合理的。基础方案fedavg的性能最差(为28.3%),fedswap和fedprox通过模型交换和重参数化等操作对性能有所提升(分别为34.9%和31.7%),但与本实施例中所提方案(fedmigr),包括在客户端间随机交换模型方案(randmigr)相比,提升的幅度还不是很大。本发明实施例的技术方案通过强化学习方法能够对网络中每个客户端的模型训练和网络资源状态进行实时监测,从而动态决策出客户端间的模型迁移策略。因此,本发明所提方案的整体训练性能(也就是测试精度)是所有方案中最优的。
[0044]
进一步的,本发明实施例还提供了一种基于模型迁移的高效联邦训练装置,包括:
[0045]
全局模型分发模块,用于通过服务器将目标任务的全局模型分发至各本地客户端
[0046]
本地模型训练模块,用于通过所述各本地客户端对接收到的全局模型进行训练,并在完成本地训练后向所述服务器发送训练完成信号
[0047]
迁移策略确定模块,用于通过所述服务器基于预设算法确定本地模型迁移训练策略并将所述迁移训练策略下发给所述各本地客户端
[0048]
迁移策略执行模块,用于通过所述各本地客户端根据所述迁移训练策略将自身更新好的本地模型迁移到其他本地客户端继续进行训练,并在执行完所述迁移训练策略后将本地模型参数上传至服务器。
[0049]
其中,迁移策略确定模块具体用于:通过所述服务器采用强化学习训练drl代理的方法确定本地模型迁移策略。
[0050]
具体的,所述服务器采用强化学习训练drl代理的方法确定本地模型迁移策略,包括:
[0051]
将所述各客户端的数据分布、资源使用和训练状态作为输入,输出每一个动作的概率值,选取最高概率的动作来得到最优的本地模型迁移策略。
[0052]
可选的,所述本地模型迁移策略中的参与迁移的本地客户端数量小于联邦训练系统中所有的本地客户端数量。
[0053]
本发明实施例所提供的一种基于模型迁移的高效联邦训练装置可执行本发明任意实施例所提供的一种基于模型迁移的高效联邦训练方法,具备执行方法相应的功能模块和有益效果。
[0054]
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。