1.本发明涉及行人重识别技术领域,具体而言,涉及基于自标签精炼深度学习模型的无监督行人重识别方法。
背景技术:
2.行人重识别是近年来计算机视觉领域比较热门的研究方向之一,它是一个图像检索中的问题,是利用计算机视觉技术判断图像或视频中是否存在特定行人的技术,即给定一个监控行人图像检索跨设备下的该行人图片。
3.随着科技的发展,行人重识别技术已经被广泛应用到智能安防、视频监控等领域。目前,行人重识别已经在有标注的监督领域取得了比较大的突破,并且展现出了优越的性能。但是,由于标注数据集需要较高的人工成本,而无标签的数据往往是十分廉价而且规模比较大的。如何扩展到大型未标注的数据集和新的数据域越来越受到人们的关注,无监督行人重识别应运而生。无监督行人重识别就是利用没有标记的数据集学习行人的特征表征,然而因为缺乏对图像数据的标注,这种基于无监督学习的行人重识别方法往往很难达到有监督学习方法所能够达到的检索准确率。
4.目前,比较流行的完全无监督行人重识别方法大多采用聚类算法对未标记样本生成伪标签,从而以有监督的方式训练模型。然而,由于不同相机视角拍摄下,同一个行人的图片存在较大差异,聚类算法不能保证同一个行人的图片样本会被分配到相同的伪标签,这就不可避免地引入了噪声标签。模型训练中容易受到标签噪声的影响,导致模型性能的下降。
技术实现要素:
5.本发明解决的问题是如何通过局部特征对伪标签进行更正,从而缓解因跨视角造成的同个行人的图片上的差异,如何优化损失函数,从而进一步提高网络对噪声标签的鲁棒性。
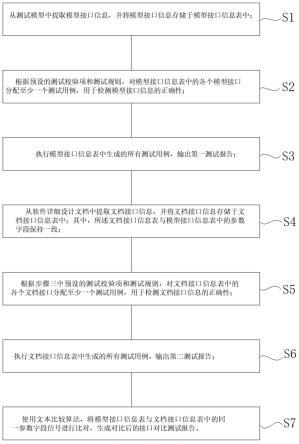
6.为解决上述问题,本发明提供基于自标签精炼深度学习模型的无监督行人重识别方法,包括步骤:
7.s1:获取不带标签的行人图片数据集其中n表示数据集中图片的数量,xi表示数据集中第i张行人图片,将每张图片的尺寸调整为相同高度和宽度,并进行预处理;
8.s2:构建自标签精炼深度学习模型,将预处理的训练数据输入网络,提取图片样本的多粒度特征;其中,多粒度特征包括全局特征、上半身特征和下半身特征;
9.s3:对提取的多粒度特征进行聚类,得到全局伪标签,上半身伪标签和下半身伪标签;
10.s4:根据聚类结果构建记忆模块,计算一致性矩阵并修正全局伪标签;
11.s5:通过计算总损失,梯度回传更新网络参数,动量更新记忆模块参数,保存网络
的最优参数。
12.在上述方法中,充分利用了局部信息,通过局部特征对伪标签进行修正。局部部分通常在整幅图片占据较小的区域,所以跨视角造成的同个行人的图片上的差异可以被缓解。通过对局部特征进行聚类,可以有效将来自不同相机的同一行人的样本聚到同一类中。从而基于局部的结果可以有效的矫正对全局特征进行聚类造成的伪标签噪声。无监督行人重识别中,常用到对比损失结合记忆模块的方式,为了更好的解决噪声标签对网络训练造成的精度损失,通过对称对比损失symmetric infonce loss,它将标签和分类的置信度进行调换,因为噪声伪标签不能代表真实的类别分布,而分类置信度能在一定程度上反映真实的类别分布,提高了网络对噪声标签的鲁棒性。
13.进一步地,所述预处理包括水平翻转、补零填充、标准化和随机擦除四种方式。
14.进一步地,所述自标签精炼深度学习模型由特征提取器,记忆模块和自标签精炼模块组成;
15.所述特征提取器结构包括两部分,所述特征提取器的第一部分采用resnet50架构的前四个阶段;所述特征提取器的第二部分在第一部分后分为两个分支,分别为全局分支和局部分支,对所述全局分支得到的特征图采用generalize-meanpooling进行池化,其中参数p=2,池化后特征图大小为2048
×1×
1;对所述局部分支得到的特征图采用generalize-meanpooling池化,参数p=2,池化后的特征图大小为2048
×2×
1,并对特征图进行水平条划分,得到两个大小均为2048
×1×
1的局部特征图;对所述局部分支得到的特征图通道进行缩减,采用256个1
×
1的卷积核对两个2048
×1×
1的局部特征图分别进行卷积,对得到结果进行batchnormalize和relu,所述局部分支得到两个局部特征图大小为256
×1×
1和256
×1×
1;对所述全局分支和所述局部分支得到的特征图进行维度剪裁,得到一个维度为2048
×
1的全局特征和两个256
×
1的局部特征。
16.进一步地,所述resnet50架构包括五个阶段,分别为:
17.第一阶段:卷积操作的卷积核数目为64,卷积核大小为7
×
7,补零参数的值为3,步长为2;batchnormalize和relu激活;最大池化操作的核大小为3
×
3,补零参数值为1,步长为2;
18.第二个阶段包括三个bottleneck;
19.第三个阶段包括四个bottleneck;
20.第四个阶段包括六个bottleneck;
21.第五个阶段包括三个bottleneck。
22.进一步地,所述全局分支的结构和所述resnet50架构的第五个阶段相同,包括三个bottleneck,不同的是第一个bottleneck的第二个卷积操作的步长为1;其中,下采样操作中卷积步长为1。
23.进一步地,所述局部分支的结构和所述resnet50架构的第五个阶段相同,包括三个bottleneck,不同的是第一个bottleneck中所有卷积步长均为1;其中,下采样操作中卷积步长为1,其他两个bottleneck中的所有卷积步长为1,且取消下采样操作。
24.进一步地,所述将预处理的训练数据输入网络为数据集中的所有行人图片均输入到所述特征提取器中,得到特征集
25.其中分别表示图片xi的全局特征,上半身特征和下半身特征。
26.进一步地,所述步骤s4包括:
27.s41:对所有图片的全局特征计算两两之间的jaccard距离,得到n
×
n维的距离矩阵;
28.s42:结合得到的距离矩阵,采用dbscan进行聚类,对一个簇中的样本赋予相同的伪标签,对聚类产生的离群点,赋予其最近的簇的伪标签;
29.s43:对局部特征,包括上半身特征和下半身特征,分别计算jaccard距离矩阵,并采用dbscan进行各自聚类操作,对离群点同样采取分配最近簇伪标签的方式,分别得到各自的伪标签。
30.进一步地,所述计算一致性矩阵为:将全局伪标签为i的样本集合记为ig(i),其中i∈[1,zg],将上半身伪标签为j,下半身伪标签为k的样本集合记为i
up
(j)和i
low
(k),其中j∈[1,z
up
],k∈[1,z
low
],z
up
和z
low
分别是上半身和下半身聚类得到的类别数;
[0031]
所述修正全局伪标签为给定一个样本xi,得到它的one-hot全局伪标签上半身特征和下半身特征结合得到的一致性矩阵和记忆模块,计算传递的局部标签置信度,更正全局伪标签;
[0032]
将训练样本数据随机平均分成多个batch,每个batch中包含p个类别,每个类别有k张图片,一个batch有p
×
k张图片样本;一个样本xi包括三个特征,分别为全局特征上半身特征和下半身特征还包括三个标签,分别为全局伪标签上半身伪标签和下半身伪标签对样本的全局伪标签进行修正,得到修正后的标签为
[0033]
进一步地,所述记忆模块更新方式为即对j类的代理由batch中属于j类的困难正样本特征进行更新,μ为动量更新系数,其中,μ=0.2;重复步骤4和步骤5,将数据集训练一次,即运行了一个epoch;一个epoch结束后,继续开始运行步骤2和步骤3;运行num_epoch次,其中,num_epoch=50。
[0034]
本发明采用上述技术方案至少包括以下有益效果:
[0035]
本发明通过对局部特征进行聚类,可以有效将来自不同相机的同一行人的样本聚到同一类中。从而基于局部的结果可以有效的矫正对全局特征进行聚类造成的伪标签噪声。通过对称对比损失,它将标签和分类的置信度进行调换,因为噪声伪标签不能代表真实的类别分布,而分类置信度能在一定程度上反映真实的类别分布,从而提高了网络对噪声标签的鲁棒性。
附图说明
[0036]
图1为本发明实施例提供的基于自标签精炼深度学习模型的无监督行人重识别方法流程图一;
[0037]
图2为本发明实施例提供的基于自标签精炼深度学习模型的无监督行人重识别方法流程图二;
[0038]
图3为本发明实施例提供的基于自标签精炼深度学习模型的无监督行人重识别方法的自标签精炼模型算法运行示意图。
具体实施方式
[0039]
为使本发明的上述目的、特征和优点能够更为明显易懂,下面结合附图对本发明的具体实施例做详细的说明。
[0040]
以下是本发明的具体实施例并结合附图,对本发明的技术方案作进一步的描述,但本发明并不限于这些实施例。
[0041]
实施例
[0042]
本实施例提供了基于自标签精炼深度学习模型的无监督行人重识别方法,如图1至图3所示,本方法包括步骤:
[0043]
s1:获取不带标签的行人图片数据集其中n表示数据集中图片的数量,xi表示数据集中第i张行人图片,将每张图片的尺寸调整为相同高度和宽度,并进行预处理;
[0044]
s2:构建自标签精炼深度学习模型,将预处理的训练数据输入网络,提取图片样本的多粒度特征;其中,多粒度特征包括全局特征、上半身特征和下半身特征;
[0045]
s3:对提取的多粒度特征进行聚类,得到全局伪标签,上半身伪标签和下半身伪标签;
[0046]
s4:根据聚类结果构建记忆模块,计算一致性矩阵并修正全局伪标签;
[0047]
s5:通过计算总损失,梯度回传更新网络参数,动量更新记忆模块参数,保存网络的最优参数。
[0048]
其中,预处理包括水平翻转、补零填充、标准化和随机擦除四种方式。
[0049]
其中,自标签精炼深度学习模型由特征提取器,记忆模块和自标签精炼模块组成;
[0050]
特征提取器结构包括两部分,特征提取器的第一部分采用resnet50架构的前四个阶段;特征提取器的第二部分在第一部分后分为两个分支,分别为全局分支和局部分支,对全局分支得到的特征图采用generalize-mean pooling进行池化,其中参数p=2,池化后特征图大小为2048
×1×
1;对局部分支得到的特征图采用generalize-mean pooling池化,参数p=2,池化后的特征图大小为2048
×2×
1,并对特征图进行水平条划分,得到两个大小均为2048
×1×
1的局部特征图;对局部分支得到的特征图通道进行缩减,采用256个1
×
1的卷积核对两个2048
×1×
1的局部特征图分别进行卷积,对得到结果进行batch normalize和relu,局部分支得到两个局部特征图大小为256
×1×
1和256
×1×
1;对全局分支和局部分支得到的特征图进行维度剪裁,得到一个维度为2048
×
1的全局特征和两个256
×
1的局部特征。
[0051]
其中,resnet50架构包括五个阶段,分别为:
[0052]
第一阶段:卷积操作的卷积核数目为64,卷积核大小为7
×
7,补零参数的值为3,步长为2;batch normalize和relu激活;最大池化操作的核大小为3
×
3,补零参数值为1,步长为2;
[0053]
第二个阶段包括三个bottleneck;
[0054]
第三个阶段包括四个bottleneck;
[0055]
第四个阶段包括六个bottleneck
[0056]
第五个阶段包括三个bottleneck。
[0057]
其中,全局分支的结构和所述resnet50架构的第五个阶段相同,包括三个bottleneck,不同的是第一个bottleneck的第二个卷积操作的步长为1;其中,下采样操作中卷积步长为1。
[0058]
其中,局部分支的结构和所述resnet50架构的第五个阶段相同,包括三个bottleneck,不同的是第一个bottleneck中所有卷积步长均为1;其中,下采样操作中卷积步长为1,其他两个bottleneck中的所有卷积步长为1,且取消下采样操作。
[0059]
其中,将预处理的训练数据输入网络为数据集中的所有行人图片均输入到所述特征提取器中,得到特征集
[0060]
其中分别表示图片xi的全局特征,上半身特征和下半身特征。
[0061]
参阅图2,其中,步骤s4包括:
[0062]
s41:对所有图片的全局特征计算两两之间的jaccard距离,得到n
×
n维的距离矩阵;
[0063]
s42:结合得到的距离矩阵,采用dbscan进行聚类,对一个簇中的样本赋予相同的伪标签,对聚类产生的离群点,赋予其最近的簇的伪标签;
[0064]
s43:对局部特征,包括上半身特征和下半身特征,分别计算jaccard距离矩阵,并采用dbscan进行各自聚类操作,对离群点同样采取分配最近簇伪标签的方式,分别得到各自的伪标签。
[0065]
值得注意的是,在计算局部距离矩阵的时候,我们使用局部特征和全局特征拼接后的特征进行相似度计算。经过上述过程,我们可以得到一个新的数据集即图片xi拥有三个伪标签,分别来自全局特征的聚类结果上半身特征的聚类结果和下半身特征的聚类结果针对全局特征的聚类结果,计算各个类别中样本特征的平均值,作为各类的特征中心,并开辟内存空间进行存储,得到其中zg表示全局特征聚类得到的类别数,2048表示平均特征向量的维度。同样的方式,我们可以得到和其中z
up
和z
low
分别表示上半身和下半身特征聚类得到的类别数,256表示上半身和下半身各类中心特征的维度。
[0066]
参阅图3,其中,计算一致性矩阵为:将全局伪标签为i的样本集合记为ig(i),其中i∈[1,zg],将上半身伪标签为j,下半身伪标签为k的样本集合记为i
up
(j)和i
low
(k),其中j∈[1,z
up
],k∈[1,z
low
],z
up
和z
low
分别是上半身和下半身聚类得到的类别数;
[0067]
修正全局伪标签为给定一个样本xi,得到它的one-hot全局伪标签上半身特征和下半身特征结合得到的一致性矩阵和记忆模块,计算传递的局部标签置信度,更正全局伪标签;
[0068]
将训练样本数据随机平均分成多个batch,每个batch中包含p个类别,每个类别有k张图片,一个batch有p
×
k张图片样本;一个样本xi包括三个特征,分别为全局特征上半身特征和下半身特征还包括三个标签,分别为全局伪标签上半身伪标签和下半身伪标签对样本的全局伪标签进行修正,得到修正后的标签为
[0069]
具体的,对于聚类一致性矩阵的计算方式,以为例,该矩阵中上半身类j和全局类i之间的一致性,我们通过iou来计算,公式为全局类i之间的一致性,我们通过iou来计算,公式为其中|
·
|表示集合中的样本数量。我们采用同样的方式计算对两个一致性矩阵进行行标准化,即矩阵中的每行值和为1,于是我们得到标准化后的矩阵和
[0070]
具体的,计算局部标签置信度,将局部特征和对应的记忆模块进行相乘,得到标签置信度和维度分别为z
up
×
1和z
low
×
1。由于局部标签和全局标签的类别不统一,无法直接将局部信息转移到全局标签上。利用一致性矩阵,我们可以巧妙的将局部标签置信度映射到对应的全局伪标签中,即得到传递的局部置信度置信度映射到对应的全局伪标签中,即得到传递的局部置信度和其中τ是温度系数超参,值为10,起到放缩作用,t表示矩阵的转置,softmax是归一化指数函数。最终样本xi的全局标签更正为的全局标签更正为其中α∈[0,1]是更新标签的动量系数,并以指数形式衰减α=α0*(1-now_epoch/num_epoch)
0.6
,其中now_epoch为训练的当前轮次数,num_epoch表示训练总轮次数,α0为初始的动量系数,值为0.2。
[0071]
具体的,计算总损失包括三种:
[0072]
对比损失infonce loss,公式为其中f为查询的特征,聚类结果表明属于第j类,是查询特征所对应的记忆模块,为查询特征在记忆模块中的正样本代理,τ是温度系数,《
·
,
·
》表示两个特征之间的内积操作,衡量两个特征的相似度,z是聚类得到的对应的类别数,exp(
·
)表示以自然常数e为底的指数函数。
[0073]
对称对比损失symmetric infonce loss,公式为loss,公式为其中y是f对应的one-hot伪标签,softmax(y)[t]表示伪标签经过归一化指数函数后的第t维的值。
[0074]
软三元组损失soft softmax-triplet loss,公式为
具体其中表示二值交叉熵损失,f
和f-分别表示batch中相对于f的困难正样本特征和困难负样本特征。y
表示困难正样本对应的标签,y-表示困难负样本对应的标签。∥
·
∥表示l2标准化。
[0075]
基于这三种损失,样本xi的损失分为全局损失的损失分为全局损失和局部损失总损失总损失其λ是平衡系数,在本发明中λ=0.5,值得注意的是在全局损失中,和使用的更正后的软标签,也就是最终batch的损失为其中b表示batch集合,i是batch中的一个样本。
[0076]
其中,记忆模块更新方式为即对j类的代理由batch中属于j类的困难正样本特征进行更新,μ为动量更新系数,其中,μ=0.2;重复步骤4和步骤5,将数据集训练一次,即运行了一个epoch;一个epoch结束后,继续开始运行步骤2和步骤3;运行num_epoch次,其中,num_epoch=50。
[0077]
本发明方法中的深度学习网络通过pytorch框架实现,在quadro p5000上运行,优化器采用adam,学习率为0.00035,训练迭代次数为num_epoch=50。训练前,图片大小被resize成256
×
128,批次大小为batch_size=64,其中包含16个伪类,每类4个样本。本发明通过两个指标map和rank-1衡量识别效果。
[0078]
消融实验:为了评估本发明的优越性,本发明对所提出的自标签精炼模块和对称信息损失函数进行评估。对三个公开的行人重识别数据集进行了验证,如表1所示:
[0079][0080]
表1
[0081]
其中表1的第一行为基础网络,即现有的无监督行人重识别的基础模型。第二行表示对基础网络加入自标签精炼模块(self-label refining module,slr)后的结果,可以发现模块的加入,网络模型效果提升了。第三行实验结果表示,在基础网络中加入对称对比损失,模型效果也实现了稳定的提升。最后一行,表示在基础网络的模型架构上,同时加入自标签精炼模块和对称信息损失后模型的实验效果,相比前面实验,该实验效果达到了最优。
[0082]
对比实验:为了评价本发明方法中自标签精炼网络的有效性,将其与其他几个现有的无监督行人重识别模型进行了比较,其中包含无监督域适应(uda)行人重识别方法和完全无监督(fu)行人重识别方法。对比实验结果如表2所示:
[0083][0084][0085]
表2
[0086]
由于无监督域适应(uda)的方法引入了有标签的源域,通常情况下效果要优于完全无监督(fu)的方法。本方法在没有使用到有标签的数据情况下,效果逼近域适应的方法。参阅表2可得,本方法在三个公开的行人重识别数据market-1501,dukemtmc-reid和msmt17上都取得了较好的效果。体现了本方法提出的自标签精炼策略和对称信息损失的优越性。
[0087]
本方法通过对局部特征进行聚类,可以有效将来自不同相机的同一行人的样本聚到同一类中。从而基于局部的结果可以有效的矫正对全局特征进行聚类造成的伪标签噪声。通过对称对比损失,它将标签和分类的置信度进行调换,因为噪声伪标签不能代表真实的类别分布,而分类置信度能在一定程度上反映真实的类别分布,从而提高了网络对噪声标签的鲁棒性。
[0088]
虽然本公开披露如上,但本公开的保护范围并非仅限于此。本领域技术人员,在不脱离本公开的精神和范围的前提下,可进行各种变更与修改,这些变更与修改均将落入本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。