1.本发明涉及一种基于深度学习方法的手语识别模型,主要应用于手语翻译技术领域。
背景技术:
2.全球有数百万听障人士通常使用手语进行交流,我国听力、语言残障人士超过2000万人,而且每年还在以2万~3万名的速度递增。但聋哑人与健全人间的交流障碍现象屡见不鲜,聋哑人士始终存在着难以融入社会的问题。手语识别是多年来研究中已经解决的问题,早期主要是依据手套来对手部进行定位,识别手部关节位置,判断其代表的含义,或者利用手语翻译app进行特殊点定位识别,但是该方法存在着设备昂贵、受限于识别场景和类型、用户体验差等问题。
3.随着计算机性能的大幅度提升,深度学习技术逐渐兴起,在各种应用中表现出显著的性能。它能够避免人工经验特征提取的主观性及繁琐性,使得手语识别与翻译方向有了新的切入点,通过多层神经网络能够具有较高的准确性。
技术实现要素:
4.本发明的目的是为了解决传统的静态手势识别方法在复杂背景下识别准确率低和识别手势的问题类别不完整的问题,设计了基于深度学习方法的手语识别模型,以yolov5模型和pytorch框架为基础,利用pycharm软件进行程序的编写调试;该模型后对正常光照强度下的照片基本能准确的分割出人体肤色区域,该算法具有准确的分割效果以及良好的鲁棒性,最后,通过实验证明手势识别的准确率达到94.57%。
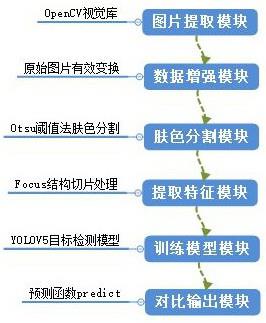
5.为实现上述目的,本发明是通过以下技术手段实现的:设计了一种基于深度学习方法的手语识别模型,包括图片读取模块、数据增强模块、肤色分割模块、提取特征模块、训练模型模块及对比输出模块六个部分。
6.所述的图片读取模块利用opencv动态手语识别系统来完成训练样本中手语的捕获、处理及转化;数据集是通过摄像机采集的600张图片,包括3种手势,分别定义为,,。(图片手势24字母)同时每一种手势有200张图片。对于采集到的原始图片,首先进行对图片尺寸大小、分辨率进行修正,并利用图像标记软件labelimg进行人工标记,为之后神经网络训练提供参考。
7.所述数据增强模块采取深度学习中的dropout来解决该问题,提高神经网络的鲁棒性。通过对原始图像进行翻转、缩放、平移、尺度变换、调整对比度、随机噪声扰动等方式进行变换,尽量增大数据集的实际样本量来提高模型的泛化能力;如图2所示,被处理后的图像在简易的神经网络中被认为是不同的样本即扩充了样本。
8.进一步地,所述肤色分割模块通过神经网络的特征提取功能和长短期记忆网络的时序建模能力,借助分割算法检测出手语比划过程中的过渡动作,采用otsu阈值法进行肤色分割;otsu阈值法即通过统计学的方法来选取一个阈值,使得这个阈值可以将前景色和
背景色尽可能的分开,更准确的说是在某种判据下最优;肤色分割处理后非肤色区域背景部分变为黑色,分割结果对比图如图3所示。
9.所述提取特征模块利用focus结构即在图像进入主干网络前对图片进行切片处理,提取关键点的位置,获得下采样特征图。
10.进一步地,所述的训练模型模块分为输入端、主干网络、检测层、预测网络四个部分,如图4所示,所述训练模型模块主要根据处理效果调整模型参数训练yolov5目标检测模型,相比于其他模型,yolov5更快、更轻便;通过层层神经网络学习,细化输入图片的关键信息,并与数据标签进行对比并不断修改纠正,得到训练后的权重文件。
11.所述的对比输出模块是指重新输入与训练数据集不同的测试图片,模型根据已有数据集,使用预测函数predict对获取图片的特征进行预测,找到逻辑最大值,判断手语图片代表的含义并输出识别文本结果;测试图片为重新采集的手势图片一共有90张,三种手势各150张。
12.与现有技术相比,本发明的优点在于充分利用了卷积神经网络的特征提取功能和长短期记忆网络的时序建模能力,借助分割算法检测出的过渡动作,降低了手语识别的复杂性,具有良好的稳定性及实时性,使得手语翻译更加方便快捷;利用深度学习算法能够较好的提高图像识别的准确率,经实验得到手语识别的识别率为94.57%,在一定程度上能够减小复杂背景对手势识别的干扰;本发明的实施能够帮助聋哑人士更好的融入社会,拥有更加方便的日常生活交流。
附图说明
13.下面结合附图和实施例对本发明做进一步说明:图1为本发明的算法整体框架图。
14.图2是数据增强效果示例图。
15.图3是基于otsu法的肤色分割手势对比图。
16.图4是yolov5算法结构图。
17.图5是手势识别测试结果图。
具体实施方式
18.为了更具体的阐述本发明的目的、技术方案及优点,下面通过借助实施例和附图,对本发明进行进一步详细说明;此处所描述的实施例仅是说明性,非限定性的,本发明的保护范围不受这些实施例的限制。
19.实施例:如图1所示,是本发明基于深度学习方法的手语识别模型实施例的总体框架图,利用pycharm软件进行程序的编写调试,包括图片读取模块、数据增强模块、肤色分割模块、提取特征模块、训练模型模块及对比输出模块六个部分;在某些实施例中,基于深度学习方法的手语识别模型可以用于环境识别,设置于摄像头中,在某些实施例中,也可用于计算机设备上。
20.在本发明实施例中,图片提取模块通过摄像头完成训练样本数据集的收集工作,数据集由不同的人在不同光源和背景下拍照获取,尽量增大数据集的实际样本量来提高模型的泛化能力;利用opencv动态手语识别系统来完成训练样本中手语的捕获、处理及转化;数据集是通过摄像机采集的600张图片,包括3种手势,分别定义为,,(图片手势24字
母),同时每一种手势有200张图片;对于采集到的原始图片,首先进行对图片尺寸大小、分辨率进行修正,并利用图像标记软件labelimg进行人工标记,为之后神经网络训练提供参考。
21.在本发明实施例中,所述数据增强模块采取深度学习中的dropout来解决该问题,提高神经网络的鲁棒性;通过对原始图像进行翻转、缩放、平移、尺度变换、调整对比度、随机噪声扰动等方式进行变换,增大样本数据;如图2所示,被处理后的图像在简易的神经网络中被认为是不同的样本即扩充了样本。
22.在本发明实施例中,所述肤色分割模块通过神经网络的特征提取功能和长短期记忆网络的时序建模能力,借助分割算法检测出手语比划过程中的过渡动作,采用otsu阈值法进行肤色分割,进行形态学运算并提取轮廓;otsu阈值法即通过统计学的方法来选取一个阈值,使得这个阈值可以将前景色和背景色尽可能的分开,更准确的说是在某种判据下最优;otsu法的核心在于类间方差最大化;假设较暗图像的大小为m
×
n像素,含有l个不同的灰度级从0到l-1级,用 n
i 表示灰度级为i 的像素数。则图像中总像素数n为,像素灰度级为i 的概率pi为,设某一阈值,。将该图像阈值化处理成c1和c
2 两类,c1表示图像中像素灰度值在范围内,c2表示图像中像素灰度值在范围内,则类间方差的定义为:令可分性度量,当求得最佳阈值时,使得最大,即: ;;令可分性度量,当求得最佳阈值时,使得最大,即;肤色分割处理后非肤色区域背景部分变为黑色,肤色检测得到的图像结果如图3所示。
23.所述提取特征模块利用focus结构即在图像进入主干网络前对图片进行切片处理,提取关键点的位置,获得下采样特征图。
24.在本发明实施例中,所述的训练模型模块分为输入端、主干网络、检测层、预测网络四个部分,如图4所示,所述训练模型模块主要根据处理效果调整模型参数训练yolov5目标检测模型,输入端采用mosaic数据增强、自适应anchor计算、自适应图片缩放等方式处理输入图像;检测层仍然采用fpn特征金字塔网络与pan路径聚合网络相结合的结构,后面卷积层经过上采样与前面的层进行特征融合,从而提升网络的多尺度检测能力;通过层层神经网络学习,细化输入图片的关键信息,并与数据标签进行对比并不断修改纠正,得到训练后的权重文件。
25.在本发明实施例中,所述的对比输出模块是指重新输入与训练数据集不同的测试图片,与训练样本进行对比,模型根据已有数据集判断手语图片代表的含义并输出识别文
本结果;测试图片为重新采集的手势图片一共有90张,三种手势各150张。
26.表1实验平台为windows系统,本模型手语识别的识别率为94.57%,相比于传统算法有较高的精度,且对光有一定的抗干扰能力,避免光照强度变化而对识别结果产生影响,产生误差。
27.以上所述为本发明的最佳实施例而已,但本发明不应该局限于该实施例和附图所公开的内容;所以凡是不脱离本发明所公开的精神下完成的等效或修改,都落入本发明保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。