1.本发明属于计算机中数据感知与重构领域,涉及一种面向纵向联邦学习的多方多类数据生成方法及系统。
背景技术:
2.当今时代是大数据时代,但是数据间彼此孤立被不同的组织或机构所拥有,并且例如医院、银行等机构的数据涉及用户个人隐私,使得不同参与方想要将数据聚合在一起构建一个更高性能的机器学习模型十分困难。联邦学习可以为多个参与方训练共享高性能模型,同时也可以保护各个参与方的数据隐私,可以有效解决上述问题。联邦学习根据训练数据在不同参与方之间的数据特征空间和样本id空间的分布情况可划分为横向联邦学习,纵向联邦学习,联邦迁移学习。联邦学习包含参与方和协作方,参与方协作构建一个共享的机器学模型,协作方负责信息加密解密和判断全局训练是否终止。这发明应用场景主要涉及纵向联邦学习。
3.纵向联邦学习虽然可以有效解决数据孤岛问题但在实际应用场景中仍存在许多问题,数据是机器学习模型训练的“原料”当参与方a、b数据存在部分值缺失、数据不平衡问题、某一方数据量过少导致数据对齐后数据量很少非对齐数据浪费等问题将无法训练性能优良的机器学习模型。
4.近些年来生成对抗网络模型因其在不同领域的适用性而变得越来越重要和流行。针对表格类数据集,需联合多方进行数据生成,以扩充训练数据集中样本维度和样本数量。通过联合多方数据生成方法构建高质量表格类训练数据集,满足大数据应用场景中机器学习模型训练的需求。
技术实现要素:
5.有鉴于此,本发明的目的在于提供一种面向纵向联邦学习的多方多类数据生成方法及系统,构建面向纵向联邦学习的双重条件生成对抗网络(简称为dctgan),扩充训练数据集中样本维度和样本数量,联合多方构建高质量表格类训练数据集,满足大数据应用场景中机器学习模型训练的需求。
6.为达到上述目的,本发明提供如下技术方案:
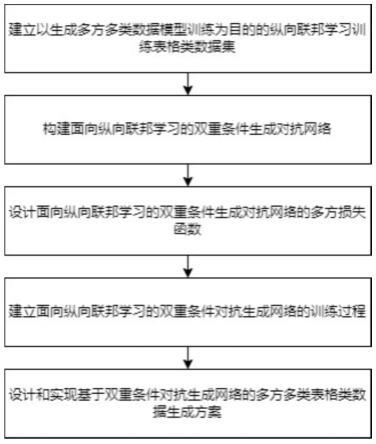
7.一种面向纵向联邦学习的多方多类数据生成方法,该方法包括以下步骤:
8.s1:建立以生成多方多类数据模型训练为目的纵向联邦学习训练数据集;
9.s2:构建面向纵向联邦学习的双重条件生成对抗网络;
10.s3:设计面向纵向联邦的双重条件生成对抗网络的多方损失函数;
11.s4:建立面向纵向联邦学习的双重条件生成对抗网络的训练过程;
12.s5:设计和实现基于双重条件生成对抗网络的多方多类数据生成方案。
13.可选的,所述s1具体为:
14.客户方a方和客户方b方用户群体所属不同系统,双方使用隐私保护集合求交技术
psi进行加密实体对齐,并对数据完全缺失方的样本id进行表示。
15.可选的,所述s2具体为:
16.客户方a方和客户方b方构建双重条件生成对抗网络,双方各有生成对抗子网络,其中分别包括:生成模型和判别模型。
17.s2-1:双方生成模型模型由两个resnet残差网络和一个全连接层组成,其输入包括输入数据和条件向量,且双方对输入数据做如下处理:
18.(1)客户方a方掩码向量客户方b方客户方a方和客户方b方md=0时,代表该位置的数据缺失;当md=1时,代表数据完整;各方m中元素值1的维度为‖m‖1,而元素值0的维度为‖1-m‖1,例如a方m,则元素值为1的维度为||ma||1,其他同理;两方m中所有元素都为0时表示只以样本类别作为条件;
19.真实样本在客户方a方的特征数据的编码向量xa,客户方a方模拟不同情况的缺失样本数据向量
[0020][0021]
即
[0022][0023]
客户方b方的特征数据的的编码向量xb,客户方b方模拟不同情况的缺失样本数据向量
[0024][0025]
即
[0026][0027]
其中,
“⊙”
表示向量间的元素级乘法;
[0028]
(2)客户方a和客户方b分别对噪声样本za和噪声样本zb进行编码,并用编码后的结果对缺失样本数据进行填充,得到za′
和zb′
,客户方a方过程表示为,客户方a方过程表示为客户方b方过程表示为
[0029]
(3)客户方a方将条件向量conda与za′
进行拼接得到客户方b方将条件向量condb与zb′
进行拼接得到作为双方生成模型的输入,表示向量拼接操作;
[0030]
s2-2:客户方a方和客户方b方判别模型模型由三个全连接网络构成,对生成模型的生成数据进行处理以满足判别模型的输入;
[0031]
s2-3:客户方a方将生成数据缺失数据与掩码向量ma做元素级乘法得到判别模型的输入数据,用进行表示,即且且客户方b方将生成数据缺失数据与掩码向量mb做元素级乘法
得到判别模型的输入数据,用进行表示,即且
[0032]
可选的,所述s3具体为:
[0033]
判别模型的目标优化函数设计步骤如下:
[0034]
s3-1:m表示样本个数,u表示编码后的样本维度,表示样本x
imp
满足给定的概率;客户方a方和客户方b方的判别模型进行训练时,判别模型不仅要判别生成数据是否符合双方真实样本的数据分布,也即各方在(1-m)作用下生成元素与真实元素的近似程度,还要判别双方联合生成样本是否满足类别标签;对于客户方a方的每一个样本,通过计算和真实样本xa在给定条件conda下的交叉熵损失来判断样本与类别是否匹配,对于客户方b方的每一个样本,通过计算和真实样本xb在给定条件condb下的交叉熵损失来判断样本与类别是否匹配,此时客户方a方损失计算为:
[0035][0036]
客户方b方损失计算为:
[0037][0038]
s3-2:客户方a方和客户方b方使用wasserstein gans中的wasserstein距离来计算x
imp
⊙
(1-m)与x
⊙
(1-m)之间缺失部分的相似度,客户方a方和分别表示集合和xa集合服从概率分布;客户方b方和分别表示集合和xb集合服从概率分布,“γ”、“∈”为的超参数;其损失用lw表示,此时a方wasserstein距离计算为:
[0039][0040]
b方wasserstein距离计算为:
[0041][0042]
其中表示wasserstein距离中的“梯度惩罚”机制;
[0043]
s3-3:此时客户方a方总判别模型损失表示为:
[0044][0045]
客户方b方总判别模型损失为:
[0046][0047]
其中“δ”为超参数;d(x|cond)表示将样本x与条件向量cond输入到判别模型;其中m表示样本个数,u表示编码后的样本维度,可具体到a方和b方,如ub表示编码后的样本在b方的数据维度;
[0048]
s3-4:对a、b双方判别模型损失进行聚和;双方总损失计算为作为双方判别模型的损失;
[0049]
生成模型的目标优化函数设计步骤如下:
[0050]
s3-5:客户方a方和客户方b生成模型判断生成数据是否可以骗过判别模型,以及在各方m的作用下的生成元素与真实样本的元素的数据分布拟合,客户方a方表示为其值越大说明越符合给定条件;客户方b方表示为其值越大说明越符合给定条件,其中i表示样本集中第i个样本,i=1...m;
[0051]
s3-6:客户方a方和客户方b方还需计算计算m
⊙
x
miss
与每个样本中每个元素的均方误差,其损失函数用表示,客户方a方均方误差损失计算为:
[0052][0053]
客户方b方均方误差损失计算为:
[0054][0055]
其中α为超参数
[0056]
s3-7:客户方a生成模型损失表示为:
[0057][0058]
客户方b方生成模型损失为:
[0059][0060]
s3-8:将两方生成模型损失进行聚和即
[0061]
可选的,所述s4具体为:
[0062]
s4:考虑到联邦学习中对客户方a方,b方的数据隐私保护采用同态加密的方式对中间信息进行加密,设计的面向纵向联邦学习dctgan的训练流程如下:
[0063]
s4-1:双方使用步骤s1中方法进行加密实体对齐;
[0064]
s4-2:由方初始化客户方a方和客户方b方的网络参数并发送给客户方a方和客户方b方;协作方p方生成同态加密的公钥pk,私钥sk,并将公钥pk发送给客户方a方和客户方b方;
[0065]
s4-3:客户方a方和客户方b方分别对噪声样本za和噪声样本zb进行编码,并用编码后的结果对缺失样本数据进行填充,得到za′
和zb′
,客户方a方过程表示为,客户方a方过程表示为客户方b方过程表示为客户方a方和客户方b方分别将za′
和zb′
中的每个输入数据与各自的条件向量conda,condb拼接,得到双方生成模型的输入,表示为
[0066]
s4-4:客户方a方和客户方b方首先固定己方生成模型,训练己方判别模型;双方采样m个真实样本中的xa、xb和作为判别模型的输入进行训练;a方得到损失:
[0067][0068]
同理,b方计算得到损失
[0069][0070]
双方将损失加密交换并聚合,得到b方将判别模型总损失发送给协作方p方;
[0071]
s4-5:a,b使用adam优化器进行优化并更新参数a方梯度计算为:
[0072][0073]
b方梯度计算为:
[0074][0075]
a方将判别模型梯度信息添加随机掩码得到b方将判别度信息添加
随机掩码得到双方将梯度信息发送给协作方p方进行解密;
[0076]
s4-6:协作方p方将a方和b方的梯度解密协作方p方将梯度信息进行解密,将结果发送回a方和b方,a方和b方消除梯度信息上的掩码,得到真实梯度信息更新各自判别模型网络;
[0077]
s4-7:客户方a方和客户方b方得到解密梯度信息进行反向传播反向传播过程为:
[0078]
客户方a方和客户方b方判别模型网络为ld层,则第l层的梯度更新过程为:
[0079][0080]
其中φd表示权重矩阵,kd表示偏置矩阵,表示对第l层的权重求微分,表示第ld 1层的输入,表示对第ld层的输出求微分,表示对leaykrelu激活函数求微分,表示第l层的输入,表示对第l
d-1层的输出求微分,表示第l 2层的输入,表示对第l 1层的输出求微分,表示第l 1层的输入;
[0081]
第l层的参数更新过程为:
[0082][0083]
其中其中和分别表示判别模型网络第l层的权重和偏置;
[0084]
a方和b方分别进行参照以上过程运算。
[0085]
s4-8:客户方a方,客户方b方固定己方判别模型,训练己方生成模型;a、b双方采样m个z
′
,z
′
表示用编码后的噪声样本对缺失样本数据填充后的结果,输入到双方生成模型得到m个生成数据,用表示;将生成数据缺失数据x
miss
与掩码向量m做元素级乘法得到判别模型的输入数据,结果用x
imp
进行表示,即得到x
impa
,x
impb
,输入到判别模型中判断x
imp
是否满足给定条件同时还要计算与x
miss
之间的均方误差损失客户方a方损失为:
[0086][0087]
b方损失为:
[0088][0089]
客户方a方和客户方b方对计算得到的生成模型损失进行加密得到双方交换均方误差损失并聚和得到b方将生成模型总损失发送给协作方p方;
[0090]
s4-9:客户方a方和客户方b方使用adam优化器进行优化并更新参数,lrg为生成模
型学习率;a方梯度计算公式为:
[0091][0092]
b方梯度计算公式为:
[0093][0094]
双方将加密损失添加随机掩码得到和双方将梯度信息发送给协作方p方进行解密;
[0095]
s4-10:协作方p方将梯度信息进行解密,将结果发送回客户方a方和客户方b方,客户方a方和客户方b方消除梯度信息上的掩码,得到真实梯度信息更新各自生成模型网络;
[0096]
s4-11:客户方a方和客户方b方得到解密后的生成模型梯度信息进行反向传播,反向传播过程为:
[0097]
反向传播过程中,客户方a方和客户方b方生别器网络为lg层,则第l层的梯度更新过程为:
[0098][0099]
其中φg表示权重矩阵,kg表示偏置矩阵,表示对第l层的权重求微分,表示lg 1层的输入,表示对第lg层的输出求微分,表示第l层的输入,表示对第l
g-1层的输出求微分,表示第l 2层的输入,表示对第l 1层的输出求微分,表示第l 1层的输入;
[0100]
第l层的参数更新过程为:
[0101][0102]
其中其中和分别表示生辰器网络第l层的权重和偏置。
[0103]
a方和b方分别进行参照以上过程运算。
[0104]
s4-12:协作方p方将双方生成模型总损失和判别模型总损失聚和,当损失小于某一值时全局训练终止,若损失仍未收敛则重复上述步骤直到双方损失收敛。
[0105]
可选的,所述s5具体为:
[0106]
客户方a方和客户方b方数据缺失情况不同分为三种情况:
[0107]
(1)样本在客户方a方和客户方b方中的特征数据都存在部分值缺失,参照s2中步骤对缺失部分数据使用随机噪声进行填充,参照s4中步骤进行纵向联邦学习dctgan的训练,双方训练结束后,输入随机噪声和已知数据以及对应的条件向量输入生成模型生成样本,将生成样本对应缺失部分的数据填充到真实数据中;
[0108]
(2)样本在客户方a方或客户方b方某一方中的数据特征存在全部数据缺失,创建由“0”完全填充的掩码向量,参照s2中步骤对缺失部分数据使用随机噪声进行填充,参照s4中步骤进行纵向联邦学习dctgan的训练,双方训练结束后,输入随机噪声对应的条件向量
输入生成模型生成样本,将生成样本对应缺失部分的数据填充到真实数据中;
[0109]
(3)联合多方对齐的样本存在样本类别不平衡的情况:将真实数据的掩码向量随机的用0填充,参照s2中步骤对缺失部分数据使用随机噪声进行填充,参照s4中步骤进行纵向联邦学习dctgan的训练,双方训练结束后,将随机噪声与少数类类别标签进行拼接输入到生成模型,生成少数类样本填充数据;或在各方本地用采用现有数据生成模型,生成部分已存在数据作为双重条件之一,然后再采用如前述方案,生成缺失部分数据,以此达到生成满足某个类别条件的少数类样本。
[0110]
一种计算机系统,包括存储器、处理器及储存在存储器上并能够在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现所述的方法。
[0111]
一种计算机可读存储介质,其上储存有计算机程序,所述计算机程序被处理器执行时实现所述的方法。
[0112]
本发明的有益效果在于:
[0113]
(1)本发明提出了一种面向纵向联邦学习的多方多类数据生成方法,允许多方在保护各自数据安全隐私的情况下,联合进行生成模型建模和训练模型。同时,本发明设计了面向纵向联邦学习双重条件生成对抗网络的模型结构和损失函数,最终通过训练好的模型实现针对表格类数据集的多方多类数据生成。
[0114]
(2)针对纵向联邦学习对齐后多方数据的不同缺失情况,本发明提出了基于纵向联邦学习双重条件生成对抗网络模型进行多方多类数据生成的方案。且本发明技术和方案,结构易扩展,可以拓展到三个及以上持有特征的客户方。能有效地解决多方数据中的缺失填补,以及样本类别间数据不平衡等问题,扩充训练数据集中样本维度和样本数量,联合多方构建高质量表格类训练数据集,满足大数据应用场景中机器学习模型训练的需求。
[0115]
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
[0116]
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
[0117]
图1为一种面向纵向联邦学习的多方多类数据生成方法的流程示意图;
[0118]
图2为纵向联邦学习多方数据对齐示意图。
[0119]
图3为纵向联邦学习双重生成对抗网络训练示意图。
[0120]
图4为纵向联邦学习的多方多类数据生成示意图。
具体实施方式
[0121]
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需要说明的是,以下实施例中所提供的图示仅以示
意方式说明本发明的基本构想,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
[0122]
其中,附图仅用于示例性说明,表示的仅是示意图,而非实物图,不能理解为对本发明的限制;为了更好地说明本发明的实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
[0123]
本发明实施例的附图中相同或相似的标号对应相同或相似的部件;在本发明的描述中,需要理解的是,若有术语“上”、“下”、“左”、“右”、“前”、“后”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此附图中描述位置关系的用语仅用于示例性说明,不能理解为对本发明的限制,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语的具体含义。
[0124]
以贷款风险评估应用场景为例,客户贷款风险评估相关的信息在多方,且各方都有数据安全隐私保护的要求。当多方数据进行纵向联邦学习,进行样本对齐后,往往很难保证获得海量高质量的样本数据进行学习。如图2所示,以两方的纵向联邦学习为例。联合a、b两方数据特征所对应的样本标签为
‘
a1’,
‘
a2’,
…
,
‘
am’等多个类别,
‘
a1’代表风险极大、
‘
a2’代表风险较大、
‘
a3’代表风险一般、
‘
a4’代表无风险等。a、b两方数据对齐后,会出现以下情况:
[0125]
①
在某个或多个类别中,a方和b方的数据特征都是完整(即无缺失)的;
[0126]
②
在某个或多个类别中,a方或b方的数据是完全缺失的,只有另一方的数据特征是完整的,如图1中数字“2”所标示的区域;
[0127]
③
在某个或多个类别中,a方或b方的数据有部分缺失,另一方的数据特征完整,如图1中数字“3”所标示的区域;
[0128]
④
在某个或多个类别中,a方和b方的数据同时有部分缺失,各方都无完整的数据特征,如图1中数字“4”所标示的区域;
[0129]
⑤
a方和b方纵向联合的样本在某个或多个类别样本较少,导致于各类别间出现了样本数据不平衡的情况,如图2中的
‘
a3’,
‘
a4’和
‘
a1’,
‘
a2’类别就存在样本数量不平衡的情况。
[0130]
在本实施例中:贷款风险评估的a方为某个拥有个人贷款、还款、违约、风险评估等级等相关信息的机构,b方为拥有个人年龄、收入、家庭收入、家庭负债、风险评估等级等相关信息的机构。当两方对齐后出现如上述的数据缺失或样本类别数量不平衡时,通过本发明提供的面向纵向联邦学习的多方多类数据生成方法可以在保护数据隐私的前提下生成a、b方数据,联合多方构建满足训练高性能贷款风险评估机器学习模型的高质量训练数据集。
[0131]
请参阅图1~图4,为一种面向纵向联邦学习的多方多类数据生成方法,该方法包含以下步骤:
[0132]
s1:建立以生成多方多类数据为目的纵向联邦学习样本集的具体步骤如下:
[0133]
s1-1:双方使用隐私保护集合求交技术进行加密实体对齐客户方a方和客户方b方用户群体所属不同系统,使用一种多方隐私集合求交的方式对双方加密用户的id进行对
齐,并对数据完全缺失方的样本id进行表示。可选的,可以使用基于rsa算法和散列函数来进行样本的对齐。
[0134]
s2:客户方a方和客户方b方构建双重条件生成对抗网络,双方各有生成对抗子网络,其中分别包括:生成模型和判别模型。客户方a方和客户方b方生成模型和判别模型网络结构如下:
[0135]
s2-1:双方生成模型模型由两个resnet残差网络和一个全连接层组成,其输入包括输入数据和条件向量,且双方对输入数据做如下处理:
[0136]
(1)客户方a方掩码向量客户方b方客户方a方和客户方b方md=0时,代表该位置的数据缺失;当md=1时,代表数据完整;各方m中元素值1的维度为‖m‖1,而元素值0的维度为‖1-m‖1,例如a方m,则元素值为1的维度为||ma||1,其他同理;两方m中所有元素都为0时表示只以样本类别作为条件;
[0137]
真实样本在客户方a方的特征数据的编码向量xa,客户方a方模拟不同情况的缺失样本数据向量
[0138][0139]
即
[0140][0141]
客户方b方的特征数据的的编码向量xb,客户方b方模拟不同情况的缺失样本数据向量
[0142][0143]
即
[0144][0145]
其中,
“⊙”
表示向量间的元素级乘法;
[0146]
(2)客户方a和客户方b分别对噪声样本za和噪声样本zb进行编码,并用编码后的结果对缺失样本数据进行填充,得到za′
和zb′
,客户方a方过程表示为,客户方a方过程表示为客户方b方过程表示为
[0147]
(3)客户方a方将条件向量conda与za′
进行拼接得到客户方b方将条件向量condb与zb′
进行拼接得到作为双方生成模型的输入,表示向量拼接操作;
[0148]
s2-2:客户方a方和客户方b方判别模型模型由三个全连接网络构成,对生成模型的生成数据进行处理以满足判别模型的输入;
[0149]
s2-3:客户方a方将生成数据缺失数据与掩码向量ma做元素级乘法得到判别模型的输入数据,用进行表示,即且
客户方b方将生成数据缺失数据与掩码向量mb做元素级乘法得到判别模型的输入数据,用进行表示,即且
[0150]
s3:针对纵向联邦学习学习场景设计了如下的损失函数。
[0151]
判别模型的目标优化函数设计步骤如下:
[0152]
s3-1:m表示样本个数,u表示编码后的样本维度,表示样本x
imp
满足给定的概率;客户方a方和客户方b方的判别模型进行训练时,判别模型不仅要判别生成数据是否符合双方真实样本的数据分布,也即各方在(1-m)作用下生成元素与真实元素的近似程度,还要判别双方联合生成样本是否满足类别标签;对于客户方a方的每一个样本,通过计算和真实样本xa在给定条件conda下的交叉熵损失来判断样本与类别是否匹配,对于客户方b方的每一个样本,通过计算和真实样本xb在给定条件condb下的交叉熵损失来判断样本与类别是否匹配,此时客户方a方损失计算为:
[0153][0154]
客户方b方损失计算为:
[0155][0156]
s3-2:客户方a方和客户方b方使用wasserstein gans中的wasserstein距离来计算x
imp
⊙
(1-m)与x
⊙
(1-m)之间缺失部分的相似度,客户方a方和分别表示集合和xa集合服从概率分布;客户方b方和分别表示集合和xb集合服从概率分布,“γ”、“∈”为的超参数;其损失用lw表示,此时a方wasserstein距离计算为:
[0157][0158]
b方wasserstein距离计算为:
[0159][0160]
其中表示wasserstein距离中的“梯度惩罚”机制;
[0161]
s3-3:此时客户方a方总判别模型损失表示为:
[0162][0163]
客户方b方总判别模型损失为:
[0164][0165]
其中“δ”为超参数;d(x|cond)表示将样本x与条件向量cond输入到判别模型;其中m表示样本个数,u表示编码后的样本维度,可具体到a方和b方,如ub表示编码后的样本在b方的数据维度;
[0166]
可选的δ设置为0.5;
[0167]
s3-4:此时考虑到客户方a方和客户方b方做纵向联邦学习,客户方a方和客户方b方数据特征并不相同但双方生成数据存在相关性,因此应对客户方a方和客户方b方判别模型损失进行聚和。双方总损失计算为作为双方判别模型的损失;
[0168]
生成模型的目标优化函数设计步骤如下:
[0169]
s3-5:客户方a方和客户方b生成模型判断生成数据是否可以骗过判别模型,以及在各方m的作用下的生成元素与真实样本的元素的数据分布拟合,客户方a方表示为其值越大说明越符合给定条件;客户方b方表示为其值越大说明越符合给定条件,其中i表示样本集中第i个样本,i=1...m;
[0170]
s3-6:客户方a方和客户方b方还需计算计算m
⊙
x
miss
与每个样本中每个元素的均方误差,其损失函数用表示,客户方a方均方误差损失计算为:
[0171][0172]
客户方b方均方误差损失计算为:
[0173]
[0174]
可选的,客户方a方和客户方b方α分别可以设置为0.5;
[0175]
s3-7:此时客户方a生成模型损失表示为:
[0176][0177]
客户方b方生成模型损失为:
[0178][0179]
s3-8:在此场景中,需要同时考虑两方数据缺失部分和非缺失部分的相关性,以及判断整条数据是否符合该类别所以要将两方生成模型损失进行聚和即
[0180]
s4:考虑到联邦学习中对客户方a方和客户方b方的数据隐私保护采用了同态加密的方式对中间信息进行加密,设计的面向纵向联邦学习dctgan的训练流程如下:
[0181]
s4-1:双方使用步骤s1中方法进行加密实体对齐。
[0182]
s4-2:由协作方p方初始化客户方a方和客户方b方的网络参数并发送给客户方a方和客户方b方;协作方p方生成同态加密的公钥pk,私钥sk,并将公钥pk发送给客户方a方和客户方b方;可选的,采用的同态加密方案为paillier同态加密。使用[[a]]表示对数据a进行了同态加密。
[0183]
s4-3:客户方a方和客户方b方分别对噪声样本za和噪声样本zb进行编码,并用编码后的结果对缺失样本数据进行填充,得到za′
和zb′
,客户方a方过程表示为,客户方a方过程表示为客户方b方过程表示为客户方a方和客户方b方分别将za′
和zb′
中的每个输入数据与各自的条件向量conda,condb拼接,得到双方生成模型的输入,表示为
[0184]
s4-4:客户方a方和客户方b方首先固定己方生成模型,训练己方判别模型;双方采样m个真实样本中的xa、xb和作为判别模型的输入进行训练;a方得到损失:
[0185][0186]
同理,b方计算得到损失
[0187][0188]
双方将损失加密交换并聚合,得到b方将判别模型总损失发送给协作方p方。
[0189]
可选的,δ=0.5,真实样本集以及噪声样本集中的样本总量可设置为3000,两方编码后总的样本维度为157。
[0190]
可选的,批处理的数量m可设置为10。
[0191]
s4-5:a,b使用adam优化器进行优化并更新参数a方梯度计算为:
[0192][0193]
b方梯度计算为:
[0194][0195]
a方将判别模型梯度信息添加随机掩码得到b方将判别度信息添加随机掩码得到双方将梯度信息发送给协作方p方进行解密。lrd为判别模型的学习率,可选的,客户方a和客户方b学习率设置为lrd=0.0002
[0196]
s4-6:协作方p方将客户方a方和客户方b方的梯度解密协作方p方将梯度信息进行解密,将结果发送回a方和b方,a方和b方消除梯度信息上的掩码,得到真实梯度信息更新各自判别模型网络。
[0197]
s4-7:客户方a方和客户方b方得到解密梯度信息进行反向传播反向传播过程为:
[0198]
客户方a方和客户方b方判别模型网络为ld层,则第l层的梯度更新过程为:
[0199][0200]
其中φd表示权重矩阵,kd表示偏置矩阵,表示对第l层的权重求微分,表示第ld 1层的输入,表示对第ld层的输出求微分,表示对leakyrelu激活函数求微分,表示第l层的输入,表示对第l
d-1层的输出求微分,表示第l 2层的输入,表示对第l 1层的输出求微分,表示第l 1层的输入;
[0201]
第l层的参数更新过程为:
[0202][0203]
其中其中和分别表示判别模型网络第l层的权重和偏置。
[0204]
a方和b方分别进行参照以上过程运算。
[0205]
s4-8:客户方a方,客户方b方固定己方判别模型,训练己方生成模型;a、b双方采样m个z
′
,z
′
表示用编码后的噪声样本对缺失样本数据填充后的结果,输入到双方生成模型得到m个生成数据,用表示;将生成数据缺失数据x
miss
与掩码向量m做元素级乘法得到判别模型的输入数据,结果用x
imp
进行表示,即得到输入到判别模型中判断x
imp
是否满足给定条件同时还要计算与x
miss
之间的均方误差损失客户方a方损失为:
[0206][0207]
b方损失为:
[0208][0209]
客户方a方和客户方b方对计算得到的生成模型损失进行加密得到双方交换均方误差损失并聚和得到b方将生成模型总损失发送给协作方p方;
[0210]
s4-9:客户方a方和客户方b方使用adam优化器进行优化并更新参数lrg为生成模型学习率;a方梯度计算公式为:
[0211][0212]
b方梯度计算公式为:
[0213][0214]
双方将加密损失添加随机掩码得到和双方将梯度信息发送给协作方p方进行解密;lrg为生成模型的学习率,可选的,客户方a方和客户方b方设置生成模型学习率为lrg=0.0002。
[0215]
s4-10:协作方p方将梯度信息进行解密,将结果发送回客户方a方和客户方b方,客户方a方和客户方b方消除梯度信息上的掩码,得到真实梯度信息更新各自生成模型网络。
[0216]
s4-11:客户方a方和客户方b方得到解密后的生成模型梯度信息进行反向传播,反向传播过程为:
[0217]
反向传播过程中,客户方a方和客户方b方生别器网络为lg层,则第l层的梯度更新过程为:
[0218][0219]
其中φg表示权重矩阵,bg表示偏置矩阵,表示对第l层的权重求微分,表示lg 1层的输入,表示对第lg层的输出求微分,表示第l层的输入,表示对第l
g-1层的输出求微分,表示第l 2层的输入,表示对第l 1层的输出求微分,表示第l 1层的输入;
[0220]
第1层的参数更新过程为:
[0221][0222]
其中其中和分别表示生辰器网络第l层的权重和偏置。
[0223]
a方和b方分别进行参照以上过程运算。
[0224]
s4-12:协作方p方将双方生成模型总损失和判别模型总损失聚和,迭代训练过程,直到模型收敛为止。。
[0225]
s5:多方多类数据生成在多方贷款风险评估应用方案有以下三种:
[0226]
方案一:通过训练好的纵向联邦学习双重条件生成对抗网络模型,进行贷款风险评估中多方缺失数据的生成填补;
[0227]
例如,在多方的贷款风险评估中,样本在两方编码前有128维数据以及其编码后有157维数据,其中a方有20维数据缺失,b方有30维数据是缺失的。则可由其中样本的类别条件,如:高风险[1,0,0]和两方总共已存在的107维数据,其中a方有67维,b方有40维;建立其对应的各方m向量,而a方的m向量中缺失的20维全部置0,b方的m向量中缺失的30维全部置0。通过训练好的纵向联邦学习双重条件生成对抗网络,去生成填补,本高风险样本在两方缺失的50维缺失数据。
[0228]
方案二:通过贷款风险评估中各方本地数据生成模型生成本地数据作为“双重条件生成对抗网络模型纵向联邦学习”中的已存在部分数据,再结合类别样本,生成双重条件下的样本数据;
[0229]
例如,在以上多方贷款风险评估中,采用各方本地数据生成模型,生成a方的20维数据,b方的30维数据,作为已存在部分数据,作为各方双重条件的一个条件。可选的,各方本地数据生成模型为基于表格数据的条件生成对抗网络(ctgan)或表格数据生成对抗网络(tgan)等模型。再根据不同的条别条件的样本生成需求,按“方案一”过程,去联合两方生成一个满足某类别条件下的样本。
[0230]
方案三:通过纵向联邦学习中各方双重条件生成对抗网络子模型中掩模向量的清零设置,只生成以贷款风险评估样本类别作为条件的样本数据。
[0231]
例如,在以上多方贷款风险评估中,两方总的157维数据全部用噪声样本代替,a方和b方的m合起来的157维全部置0。如需生成一个高风险[1,0,0]样本,通过训练好的纵向联邦学习双重条件生成对抗网络,在各方子网络上分别各方输入噪声样本和各方的m向量以及样本条件向量,去生成一个基于两方的全新的高风险样本数据。
[0232]
方案一是为了解决贷款风险评估中纵向联邦多方缺失数据生成填补的问题,期望获得对齐后高质量样本数据集,如图2例子所示的
②
、
③
、
④
三种情况;方案二和方案三是为了解决贷款风险评估中纵向联邦对齐后样本类别间数量不平衡的问题,如图2例子所示的第
⑤
种情况。
[0233]
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。