1.本发明涉及视频问答领域,具体涉及一种上下文感知的渐进式注意的视频问答方法与系统。
背景技术:
2.视频问答(videoqa)是继视频描述之后的一种细粒度的视频理解任务,相对于视频描述任务中的概括性描述,视频问答不仅需要能够理解视觉内容、文本信息与语音信息,还需要建立三种模态数据之间的联系并进行推理,使得视频问答过程比视频描述过程需要更多的细节描述信息和复杂推理过程,因此研究如何从日益增长的大量视频中提取有效信息尤为重要。视频问答方法共分为基于规则的视频问答方法与基于深度学习的视频问答方法,其中基于规则的视频问答方法最早开始于2003年,早期的视频问答方法将其作为查询内容,问题作为查询子,以检索的方式去定位相关的视频内容信息,研究的对象主要集中在新闻视频领域,并采用视频内容结构化的方式来建模视频内容,并利用hmm来构建推理机制,视频问答从视频中获取信息是重要的和有价值的,特别是因为现在有大量的视频被制作。当前的视频问答方法最早开始于2016年,研究对象主要集中在相应的数据集上,而由于视频问答因其时空特性,使得构建视频问答数据集成为一项具有挑战的任务,从而延缓了视频问答领域的进展,主要的研究方法是采用深度学习的方法来主动学习与问题相关的视频内容。近些年随着数据集的逐步完善,视频问答研究也有了新的进展。有的工作在空间注意力和时间注意力上做了探索,有的则在静态特征和动态特征融合方面有了突破,还有的拓展了视觉问答中的动态记忆网络模型。这些网络能较好地提取有用的视频信息并进行交互,取得了不错的性能。但因为该任务的复杂性,总体的性能仍有大幅度提升的空间,目前视频问答领域更多的工作仍是集中在整合视频动态时序信息以及视频多模态特征融合上。
3.目前的现有技术之一pendurkar s等人构建了一个可扩展的基于注意力的多模态融合框架,为了获取视频帧中动态信息与问题中的词关系信息,分别利用密集的双向lstm来进行动态与问题信息的持续关注并进行多模态融合,然后添加额外的权重信息控制其相同的维度,最后再次利用lstm进行输出词的关注与过滤,并利用softmax进行答案的分类预测。该模型通过密集的双向lstm可以缓解视频信息中长时期建模不足的问题。其缺点为:由于其分别进行不同模态的注意特征的提取,增加了后期融合向量的噪声信息,影响最终的问答结果。
4.目前的现有技术之二是kim j构建了一个注意力转移网络(msan),由以下组件组成:(a)利用bert进行嵌入视频和文本的表示,(b)矩建议网络定位回答问题感兴趣的时间矩,(c)异构网络推理推断出正确答案基于定位的时间矩,(d)根据不同的重要性调制重要性权重的(b)和(c)的输出。该模型通过结合self-attention与co-attention的方式构建异构注意推理机制,缓解了模态内与模态间融合的问题,并利用重要性调制来动态的缓解问题类型不同对应的模型信息不同的问题。其缺点为:由于处理模态信息时都是采用向量点积或者相加的处理的方式,模态语义特征融合模糊的问题依然存在。
5.目前的现有技术之三是kim j,ma m,kim k等人构建了一个渐进式注意记忆网络(pamn),由以下组件组成:(a)首先将问题和候选答案嵌入到一个公共空间。将视频和字幕嵌入到双存储器中,方便对每种模态都有独立的记忆。(b)为了推断出答案,渐进注意机制确定与回答问题有关的时间部分。(c)动态模态融合机制通过考虑各模态的贡献自适应地集成每个存储器的输出。(d)置信纠正答案机制依次从等可能初始化的置信度中纠正每个答案的置信度。该模型利用问题与答案来进行视频与字幕模态信息的过滤,然后采用软注意机制来动态融合过滤后的模态信息,其中的渐进式注意就是利用答案与问题信息针对视频与字幕记忆进行置信度的纠正。该模型通过问题与答案来进行模态语义表征,极大的缓解了模态语义表征不准确的问题,并通过软注意机制设计动态融合模块与置信纠正模型组合成推理机制,极大的提高了模型的推理能力。其缺点为:利用问题与答案来进行渐进式注意会导致模型具有偏见,即模型的泛化能力较弱。
技术实现要素:
6.本发明的目的是克服现有方法的不足,提出了一种上下文感知的渐进式注意的视频问答方法。本发明解决的主要问题:一是现有模型存在偏见,泛化能力较弱的问题;二是模态语义特征融合模糊的问题;三是不同模态的注意特征的提取,增加了后期融合向量的噪声信息的问题。
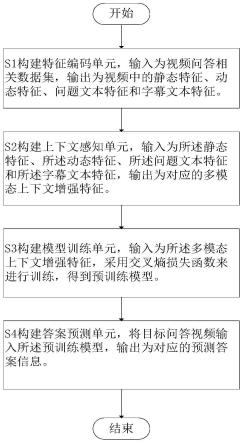
7.为了解决上述问题,本发明提出了一种上下文感知的渐进式注意的视频问答方法,所述方法包括:
8.构建特征编码单元,输入为视频问答相关数据集,输出为视频中的静态特征、动态特征、问题文本特征和字幕文本特征;
9.构建上下文感知单元,输入为所述静态特征、所述动态特征、所述问题文本特征和所述字幕文本特征,输出为对应的多模态上下文增强特征;
10.构建模型训练单元,输入为所述多模态上下文增强特征,采用交叉熵损失函数来进行训练,得到预训练模型;
11.构建答案预测单元,将目标问答视频输入所述预训练模型,输出为对应的预测答案信息。
12.优选地,所述构建特征编码单元,输入为视频问答相关数据集,输出为视频中的静态特征、动态特征、问题文本特征和字幕文本特征,具体为:
13.特征编码单元由视频动态特征提取模块、视频静态特征提取模块、字幕文本特征提取模块和问题文本特征提取模块组成,利用预训练的bert网络模型对文本特征进行词嵌入,并利用双向循环网络bilstm进行编码,同时利用预训练的vgg16网络模型来提取视频中的静态帧信息,并利用双向循环网络bilstm进行编码,采用预训练的c3d网络模型来提取视频中的动态信息,并利用双向循环网络bilstm进行编码;
14.其中,构建视频动态特征提取模块,首先定义视频为v,通过预训练的c3d网络来提取视频的动态特征,并从其最后一层的全连接层得到其动态特征mi,其中mi(i=1,2,...,n)是第i个视频动态特征,得到视频动态特征vm=[m1,m2,...,mn]∈r
4096
×n,其中n为视频的帧数,利用250维的双向循环网络bilstm对视频动态特征进行编码得到其
编码后的视频动态特征其中为第i个视频动态特征编码后的特征向量,n为视频的帧数,m表示视频动态特征;
[0015]
其中,构建视频静态特征提取模块,采用预训练的vgg16网络模型来提取视频中的静态特征,以1fps来进行视频静态帧特征提取,从vgg16网络模型的第七个全连接层fc7得到其静态特征ai,其中ai(i=1,2,...,n)是第i个视频静态特征,得到视频静态特征va=[a1,a2,...,an]∈r
4096
×n,其中n为视频的帧数,利用250维的双向循环网络bilstm对视频静态特征进行编码得到其编码后的视频静态特征其中为第i个视频静态特征编码后的特征向量,n为视频的帧数,a表示视频静态特征;
[0016]
其中,构建字幕文本特征提取模块,采用12层的预训练的bert网络模型提取字幕文本特征,从bert网络模型的倒数第二层得到字幕文本特征ci,其中ci(i=1,2,...,n)是第i个字幕文本特征,得到视频字幕文本特征vc=[c1,c2,...,cn]∈r
768
×n,其中n为视频的帧数,利用250维的双向循环网络bilstm对字幕文本特征进行编码得到其编码后的字幕文本特征其中为第i个字幕文本特征编码后的特征向量,n为视频的帧数,c表示视频字幕文本特征;
[0017]
其中,构建问题文本特征提取模块,首先将问题定义为q,选取12层的预训练的bert网络模型提取问题文本特征,从bert网络模型的倒数第二层得到问题文本特征qj,其中qj(i=1,2,...,n)是第j个问题对应的文本特征,n为数据集中每部视频对应的问题个数,得到视频问题文本特征vq=[q1,q2,...,qn]∈r
768
×n,其中n为不同数据集中每部视频对应的问题数量,利用250维的双向循环网络bilstm对问题文本特征进行编码得到其编码后的问题文本特征其中为第j个问题编码后的特征向量,其中n为不同数据集中每部视频对应的问题数量,q表示问题文本特征。
[0018]
优选地,所述构建上下文感知单元,输入为所述动态特征、所述字幕文本特征、所述静态特征和所述问题文本特征,输出为对应的多模态上下文增强特征,具体为:
[0019]
构建上下文感知单元,利用co-attention机制构建三个注意模块q2a-attention、qa2c-attention、qac2m-attention;
[0020]
其中,注意模块q2a-attention将所述问题文本特征向量与所述静态特征向量作为输入,其中j表示每部视频中对应的第j个问题,i表示每部视频中第i个静态特征,注意模型表示为co-attention注意机制对齐多模态信息注意采用软对齐矩阵来进行多模态融合与对齐,每一个软对齐矩阵s
r,c
是relu函数的乘积,其中r为矩阵的行,c为矩阵的列,然后对视频静态特征进行相关性注意,利用注意权重生成特征与最后将生成的特征进行连接其注意机制如下公式所示:
[0021][0022]
[0023][0024][0025]
其中s
r,c
是软对齐矩阵,r为矩阵的行,c为矩阵的列,wa,wq是联合学习的训练权重,与是输入的特征向量,与是对应特征向量的经过相关注意后的特征,[,]为连接操作,通过软对齐矩阵对特征向量进行相关性注意,得到注意之后的特征向量,然后利用连接操作将其进行连接;
[0026]
其中,注意模块qa2c-attention将上一注意层之后的特征与所述字幕文本特征向量作为输入,其中i表示每部视频中第i个第一层注意之后的特征与字幕文本特征,注意模型表示为然后对字幕文本特征进行相关性注意的学习,利用注意权重生成特征与最后将生成的特征进行连接公式可表示为:
[0027][0028]
其中,注意模块qac2m-attention将第二层的输出特征与所述动态特征向量作为注意模块qac2m_attention的输入,其中i表示每部视频中对应的第i个注意之后的输出特征与静态特征,注意模型表示为然后对视频动态特征进行相关性注意权重的学习,利用注意权重生成特征与最后将生成的特征进行连接公式可表示为:
[0029][0030]
通过对视频中多模态特征进行渐进式注意,得到其相关性特征,最后利用双向循环网络bilstm来建模多模态之间的上下文信息,得到多模态上下文增强特征;
[0031]
其中,利用双向循环网络bilstm来建模多模态之间的上下文信息为首先分别将不同模态的相关信息信息输入到对应的双向循环网络bilstm进行自相关性更新,然后将更新之后的信息作为双向循环网络bilstm的输入,进行多模态上下文信息的更新,公式可表示如下:
[0032]daq
=bilstm
aq
(u
aq
),d
aqc
=bilstm
aqc
(u
aqc
)
[0033]daqcm
=bilstm
aqcm
(u
aqcm
),d
aq;aqc
=bilstm
aqc
(d
aq
)
[0034]daq;aqcm
=bilstm
aqcm
(d
aq
),d
aqc;aq
=bilstm
aq
(d
aqc
)
[0035]daqc;aqcm
=bilstm
aqcm
(d
aqc
),d
aqcm;aq
=bilstm
aq
(d
aqcm
)
[0036]daqcm;aqc
=bilstm
aqc
(d
aqcm
)
[0037]
最后将利用连接操作将双向循环网络bilstm编码层输出进行连接,公式如下所示:
[0038]
h=concatenate([d
aq;aqc
,d
aq;aqcm
,d
aqc;aqcm
,d
aqc;aq
,d
aqcm;aqc
,d
aqcm;aq
])。
[0039]
优选地,所述构建模型训练单元,输入为所述多模态上下文增强特征,采用交叉熵损失函数来进行训练,得到预训练模型,具体为:
[0040]
构建模型训练单元,利用co-attention机制构建第四个注意模块,将所述问题特征向量与连接之后的特征hi作为所述注意模块q2a_attention的输入,其中j表示每部视频中对应的第j个问题,i表示经过上下文感知单元后的第i个输出特征,注意模型表示为然后对多模态上下文信息进行相关性注意权重的学习,利用注意权重生成特征与最后将生成的特征进行连接并利用双向循环网络bilstm进行记忆单元的更新,公式可表示为:
[0041][0042]bqh
=bilstm(u
qh
)
[0043]
最后通过全连接层之后得到最终的模态向量h
fc
=fc(b
qh
),利用softmax函数将模态向量h
fc
转换为答案预测分数,从最终的答案预测分数中选择最大的预测分数作为答案,通过计算公式:pro=softmax(h
fc
),得到候选答案的预测分数,最后采用交叉熵损失函数来进行训练得到预训练模型,其中表示第k个候选答案。
[0044]
相应地,本发明还提供了一种上下文感知的渐进式注意的视频问答系统,包括:
[0045]
特征编码单元,用于提取视频动态特征、视频静态特征、字幕文本特征和问题文本特征,并利用双向循环网络bilstm进行编码;
[0046]
上下文增强单元,用于将提取的特征进行多模态融合与对齐,得到多模态上下文增强特征;
[0047]
模型训练与预测单元,用于训练模型和预测答案。
[0048]
实施本发明,具有如下有益效果:
[0049]
第一,本发明提出一种上下文感知的渐进式注意的视频问答方法。通过对视频中多模态信息的渐进式注意,来捕获其中的相关性,并通过双向bilstm来建模多模态之间的上下文信息;第二,本发明利用多模态信息之间的相关性来提高视频问答模型的性能;第三,受启发于注意力机制与双向lstm网络,因此本发明采用注意力机制构建多模态之间的融合对齐模块,并利用双向lstm网络来建模模态之间的上下文信息。
附图说明
[0050]
图1是本发明实施例的一种上下文感知的渐进式注意的视频问答方法总体流程图;
[0051]
图2是本发明实施例的一种上下文感知的渐进式注意的视频问答模型图;
[0052]
图3是本发明实施例的一种上下文感知的渐进式注意的视频问答系统的结构图。
具体实施方式
[0053]
下面将结合本发明实施例中的附图,对本发明实施例中的技术发明进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0054]
图1是本发明实施例的一种上下文感知的渐进式注意的视频问答方法总体流程
图,如图1所示,该方法包括:
[0055]
s1,构建特征编码单元,输入为视频问答相关数据集,输出为视频中的静态特征、动态特征、问题文本特征和字幕文本特征;
[0056]
s2,构建上下文感知单元,输入为所述静态特征、所述动态特征、所述问题文本特征和所述字幕文本特征,输出为对应的多模态上下文增强特征;
[0057]
s3,构建模型训练单元,输入为所述多模态上下文增强特征,采用交叉熵损失函数来进行训练,得到预训练模型;
[0058]
s4,构建答案预测单元,将目标问答视频输入所述预训练模型,输出为对应的预测答案信息。
[0059]
步骤s1,具体如下:
[0060]
s1-1:如图2所示为一种上下文感知的渐进式注意的视频问答模型。首先输入为当前视频问答领域的视频问答数据集,如tvqa、lifeqa等,输出为不同模态的编码特征。本发明利用预训练的bert网络模型对文本信息进行词嵌入,并利用bilstm进行特征编码,并以此构建本发明的文本特征提取网络,同时利用预训练的vgg16与c3d网络模型分别提取视频中静态特征信息与动态特征信息,并利用bilstm进行特征编码,并以此构建本发明的视频静态特征提取网络与视频动态特征提取网络。
[0061]
s1-2:构建视频动态特征提取模块,首先定义视频为v,通过预训练的c3d网络来提取视频的动态特征,并从其最后一层的全连接层得到其动态特征mi,其中mi(i=1,2,...,n)是第i个视频动态特征,得到视频动态特征vm=[m1,m2,...,mn]∈r
4096
×n,其中n为视频的帧数,利用250维的双向循环网络bilstm对视频动态特征进行编码得到其编码后的视频动态特征其中为第i个视频动态特征编码后的特征向量,n为视频的帧数,m表示视频动态特征。
[0062]
s1-3:构建视频静态特征提取模块,采用预训练的vgg16网络模型来提取视频中的静态特征,以1fps来进行视频静态帧特征提取,从vgg16网络模型的第七个全连接层fc7得到其静态特征ai,其中ai(i=1,2,...,n)是第i个视频静态特征,得到视频静态特征va=[a1,a2,...,an]∈r
4096
×n,其中n为视频的帧数,利用250维的双向循环网络bilstm对视频静态特征进行编码得到其编码后的视频静态特征其中为第i个视频静态特征编码后的特征向量,n为视频的帧数,a表示视频静态特征。
[0063]
s1-4:构建字幕文本特征提取模块,采用12层的预训练的bert网络模型提取字幕文本特征,从bert网络模型的倒数第二层得到字幕文本特征ci,其中ci(i=1,2,...,n)是第i个字幕文本特征,得到视频字幕文本特征vc=[c1,c2,...,cn]∈r
768
×n,其中n为视频的帧数,利用250维的双向循环网络bilstm对字幕文本特征进行编码得到其编码后的字幕文本特征其中为第i个字幕文本特征编码后的特征向量,n为视频的帧数,c表示视频字幕文本特征。
[0064]
s1-5:构建问题文本特征提取模块,首先将问题定义为q,选取12层的预训练的bert网络模型提取问题文本特征,从bert网络模型的倒数第二层得到问题文本特征qj,其中qj(i=1,2,...,n)是第j个问题对应的文本特征,n为数据集中每部视频对应的问题个
数,得到视频问题文本特征vq=[q1,q2,...,qn]∈r
768
×n,其中n为不同数据集中每部视频对应的问题数量,利用250维的双向循环网络bilstm对问题文本特征进行编码得到其编码后的问题文本特征其中为第j个问题编码后的特征向量,其中n为不同数据集中每部视频对应的问题数量,q表示问题文本特征。
[0065]
步骤s2,具体如下:
[0066]
s2-1:上下文感知单元,输入为s1编码之后的特征,输出为上下文增强注意的特征。为了捕获视频中多模态的相关性,在该模块中,本发明利用co-attention机制设计了三个注意模块。为了对多模态特征进行渐进式注意,本发明首先将问题与视频静态特征进行相关性注意,对应模块q2f-attention,然后再利用注意之后的相关信息对视频字幕进行相关性注意,对应qf2c-attention,最后再利用注意之后的相关信息对视频动态特征进行相关性注意,对应qfc2m,以此得到模态间的相关性信息,然后构建双向bilstm层编码,来建模多模态信息之间的上下文信息,最后将所有的输出进行连接。
[0067]
s2-2:第一个注意模块q2a-attention,本发明将问题特征向量与视频静态特征作为注意模块q2a-attention的输入,其中j表示每部视频中对应的第j个问题,i表示每部视频中第i个静态特征,注意模型表示为co-attention注意机制对齐多模态信息注意采用软对齐矩阵来进行多模态融合与对齐,每一个软对齐矩阵s
r,c
是relu函数的乘积,其中r为矩阵的行,c为矩阵的列,然后对视频静态特征进行相关性注意,利用注意权重生成特征与最后将生成的特征进行连接其注意机制如下公式所示:
[0068][0069][0070][0071][0072]
其中s
r,c
是软对齐矩阵,r为矩阵的行,c为矩阵的列,wa,wq是联合学习的训练权重,与是输入的特征向量,与是对应特征向量的经过相关注意后的特征,[,]为连接操作,通过软对齐矩阵对特征向量进行相关性注意,得到注意之后的特征向量,然后利用连接操作将其进行连接,以保证其输出对齐。
[0073]
s2-3:本发明的第二个引导注意模块也采用同样的注意机制对字幕文本特征进行融合与对齐操作,首先将上一注意层之后的特征与字幕文本特征作为qa2c_attention输入,其中i表示每部视频中第i个第一层注意之后的特征与字幕文本特征,注意模型表示为然后对字幕文本特征进行相关性注意的学习,利用注意权重生成特征与最后将生成的特征进行连接公式可表示为:
[0074][0075]
s2-4:本发明采用同样的方法设计第三个注意模块,利用co-attention机制对视频的动态特征进行融合与对齐操作,首先将第二层的输出特征征与视频动态特征作为qac2m_attention输入,其中i表示每部视频中对应的第i个注意之后的输出特征与静态特征,注意模型表示为然后对视频动态特征进行相关性注意权重的学习,利用注意权重生成特征与最后将生成的特征进行连接公式可表示为:
[0076][0077]
s2-5:通过对视频中多模态特征进行渐进式注意,得到其相关性特征,最后本发明利用bilstm来建模多模态之间的上下文信息,首先分别将不同模态的相关信息信息输入到对应的bilstm进行自相关性更新,然后将更新之后的信息作为bilstm的输入,进行多模态上下文信息的更新,公式可表示如下:
[0078]daq
=bilstm
aq
(u
aq
),d
aqc
=bilstm
aqc
(u
aqc
)
[0079]daqcm
=bilstm
aqcm
(u
aqcm
),d
aq;aqc
=bilstm
aqc
(d
aq
)
[0080]daq;aqcm
=bilstm
aqcm
(d
aq
),d
aqc;aq
=bilstm
aq
(d
aqc
)
[0081]daqc;aqcm
=bilstm
aqcm
(d
aqc
),d
aqcm;aq
=bilstm
aq
(d
aqcm
)
[0082]daqcm;aqc
=bilstm
aqc
(d
aqcm
)
[0083]
最后将利用连接操作将bilstm编码层输出进行连接,公式如下所示:
[0084]
h=concatenate([d
aq;aqc
,d
aq;aqcm
,d
aqc;aqcm
,d
aqc;aq
,d
aqcm;aqc
,d
aqcm;aq
])
[0085]
步骤s3,具体如下:
[0086]
s3-1:模型训练单元,输入为s2注意增强之后的上下文特征,输出为对应的候选答案索引。为了得到与问题最相关的多模态上下文信息,在该模块中,本发明利用c
·
o-attention机制构建第四个注意模块,本发明将问题特征向量与连接之后的特征hi作为注意模块q2a_attention的输入,其中j表示每部视频中对应的第j个问题,i表示经过上下文感知单元后的第i个输出特征,注意模型表示为然后对多模态上下文信息进行相关性注意权重的学习,利用注意权重生成特征与最后将生成的特征进行连接并利用bilstm进行记忆单元的更新,公式可表示为:
[0087][0088]bqh
=bilstm(u
qh
)
[0089]
s3-2:最后通过全连接层之后得到最终的模态向量h
fc
=fc(b
qh
),利用softmax将特征向量h
fc
转换为答案预测分数,本发明从最终的答案预测分数中选择最大的预测分数作为答案,通过计算公式:pro=softmax(h
fc
),得到候选答案的预测分数,最后本发明采用交叉熵损失函数来进行训练其中表示第k个候选答案。
[0090]
步骤s4,具体如下:
[0091]
s4-1:答案预测单元,经过上述的训练,得到预训练模型,本发明利用argmax来预
测最终的答案索引信息。
[0092]
相应地,本发明还提供了一种上下文感知的渐进式注意的视频问答系统,如图3所示,包括:
[0093]
特征编码单元1,用于提取视频动态特征、视频静态特征、字幕文本特征和问题文本特征,并利用双向循环网络bilstm进行编码。
[0094]
具体地,由视频动态特征提取模块、视频静态特征提取模块、字幕文本特征提取模块和问题文本特征提取模块组成,利用预训练的bert网络模型对文本特征进行词嵌入,并利用双向循环网络bilstm进行编码,同时利用预训练的vgg16网络模型来提取视频中的静态帧信息,并利用双向循环网络bilstm进行编码,采用预训练的c3d网络模型来提取视频中的动态信息,并利用双向循环网络bilstm进行编码。
[0095]
上下文增强单元2,用于将提取的特征进行多模态融合与对齐,得到多模态上下文增强特征。
[0096]
具体地,构建上下文感知单元,利用co-attention机制构建三个注意模块q2a-attention、qa2c-attention、qac2m-attention,输入所述动态特征、所述字幕文本特征、所述静态特征和所述问题文本特征,输出为对应的多模态上下文增强特征。
[0097]
模型训练与预测单元3,用于训练模型和预测答案。
[0098]
具体地,构建模型训练单元,利用co-attention机制构建第四个注意模块,得到最终的模态向量,利用softmax函数将模态向量转换为答案预测分数,从最终的答案预测分数中选择最大的预测分数作为答案,通过计算公式:pro=softmax(h
fc
),得到候选答案的预测分数,最后采用交叉熵损失函数来进行训练,得到预训练模型,将目标问答视频输入所述预训练模型,输出为对应的预测答案信息。
[0099]
因此,本发明首先使用预训练的网络分别提取视频中的静态信息、动态信息特征,并利用bert网络来嵌入数据集中的字幕信息与问答对信息,再分别利用bilstm网络来编码多模态信息,然后利用co-attention机制来构建渐进式注意模块,并对多模态信息进行融合对齐操作,并利用双向bilstm网络构建上下文编码层,获取模态之间的相关性信息,再一次使用注意模态来获得与问题最相关的多模态信息,最后利用bilstm来更新记忆单元,并连接一个全连接层与softmax层来预测答案。
[0100]
以上对本发明实施例所提供的一种上下文感知的渐进式注意的视频问答方法与系统进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。