1.本技术涉及视频处理技术领域,具体涉及一种作弊检测方法、装置、电子设备及存储介质。
背景技术:
2.目前,在视频考评系统中,由用户录制考核视频,然后对考核视频进行语音分析,从而得到用户的考评结果。然而,这种考评方式是通过用户回答理论知识,然后评判理论知识是否正确,但无法检测到用户是否存在作弊行为。因此,如何检测到在基于视频考评方式中宠物医师是否存在作弊行为是目前亟待解决的技术问题。
技术实现要素:
3.本技术实施例提供了一种基于视频考评的作弊检测方法、装置、电子设备及存储介质,检测宠物医师的作弊行为,保证线上考评的公正性。
4.第一方面,本技术实施例提供一种基于视频考评的作弊检测方法,该方法应用于作弊检测装置,该作弊检测装置用于管理与宠物医师相关的考核视频,方法包括:
5.获取宠物医师的待考核视频;
6.将待考核视频进行分段处理,得到第一视频段和第二视频段,其中,第一视频段用于理论知识考评,第二视频段用于临床操作考评;
7.对第一视频段中的多帧待识别图像进行识别,得到宠物医师的眼球的第一转动角度;
8.根据第一转动角度,确定第一作弊概率;
9.对第二视频段进行语音识别,确定眼球的第二转动角度;
10.根据第二转动角度,确定第二作弊概率;
11.根据第一作弊概率和第二作弊概率,确定宠物医师是否存在作弊行为。
12.第二方面,本技术实施例提供一种作弊检测装置,该作弊检测装置用于管理与宠物医师相关的考核视频,装置包括:获取单元和处理单元;
13.获取单元,用于获取宠物医师的待考核视频;
14.处理单元,用于将待考核视频进行分段处理,得到第一视频段和第二视频段,其中,第一视频段用于理论知识考评,第二视频段用于临床操作考评;
15.对第一视频段中的多帧待识别图像进行识别,得到宠物医师的眼球的第一转动角度;
16.根据第一转动角度,确定第一作弊概率;
17.对第二视频段进行语音识别确定眼球的第二转动角度;
18.根据第二转动角度,确定第二作弊概率;
19.根据第一作弊概率和第二作弊概率,确定宠物医师是否存在作弊行为。
20.第三方面,本技术实施例提供一种电子设备,包括:处理器,处理器与存储器相连,
等是用于区别不同对象,而不是用于描述特定顺序。此外,术语“包括”和“具有”以及它们任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可选地还包括没有列出的步骤或单元,或可选地还包括对于这些过程、方法、产品或设备固有的其它步骤或单元。
37.在本文中提及“实施例”意味着,结合实施例描述的特定特征、结果或特性可以包含在本技术的至少一个实施例中。在说明书中的各个位置出现该短语并不一定均是指相同的实施例,也不是与其它实施例互斥的独立的或备选的实施例。本领域技术人员显式地和隐式地理解的是,本文所描述的实施例可以与其它实施例相结合。
38.参阅图1,图1为本技术实施例提供的一种作弊检测系统的示意图。作弊检测系统包括宠物医院端10、作弊检测装置20。其中,作弊检测装置20用于管理与宠物医师相关的考核视频,比如,管理考核视频的发布,审核,下架,更新,版权保护,等其他管理操作。
39.示例性的,作弊检测装置20可以从宠物医院端10获取宠物医师的待考核视频,其中,待考核视频中包含了宠物医师的理论知识考评阶段和临床操作考评阶段,待考核视频可以是由宠物医师拍摄之后上传至宠物医院端10,也可以是宠物医院采取统一的摄像装置采集的,本技术在此处不作限定。
40.相应的,作弊检测装置20对待考核视频进行分段处理,得到第一视频段和第二视频段,其中,第一视频段用于理论知识考评,即第一视频段是由宠物医师的理论知识考评阶段构成,第二视频段用于临床操作考评,即第二视频段是由宠物医师的临床操作考评阶段构成。
41.然后,作弊检测装置20对第一视频段中的多帧待识别图像进行识别,得到宠物医师的眼球的第一转动角度;作弊检测装置20对第二视频段进行语音识别,确定眼球的第二转动角度。应说明,本技术中对第一视频段中的多帧待识别图像进行识别以及对第二视频段进行语音识别可以是同时进行的,或者,先执行对多帧待识别图像的识别过程,再执行对第二视频段语音识别的过程,也可以是先执行对第二视频段语音识别的过程,后执行对多帧待识别图像的识别过程,本技术并不对执行顺序进行限定。然后,根据第一转动角度,确定第一作弊概率;根据第二转动角度,确定第二作弊概率;最后,根据第一作弊概率和第二作弊概率,确定宠物医师是否存在作弊行为。
42.可以看出,在本技术实施例中,通过对宠物医师的待考核视频进行分段处理,得到用于理论知识考评的第一视频段和临床操作考评的第二视频段;再对第一视频段中的多帧待识别图像进行识别,得到宠物医师的眼球的第一转动角度,并基于第一转动角度确定第一作弊概率;对第二视频段进行语音识别,得到眼球的第二转动角度,并基于第二转动角度确定第二作弊概率;最后基于第一作弊概率和第二作弊概率,确定宠物医师是否存在作弊行为,通过对理论知识考评和临床操作考评过程中宠物医师的眼球转动角度计算作弊概率,基于上述双重计算作弊概率,提高了检测作弊行为的准确性,进而保证线上考评的公正性。
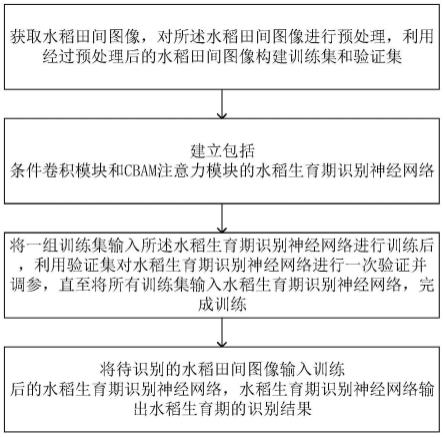
43.参阅图2,图2为本技术实施例提供的一种作弊检测方法的流程示意图。该方法应用于上述的作弊检测装置20。该方法包括但不限于以下步骤:
44.201:获取宠物医师的待考核视频。
45.其中,该待考核视频是对宠物医师的理论知识考评阶段,以及临床操作考评阶段
进行拍摄得到的。因此,该待考核视频包括宠物医师的理论知识考评阶段和临床操作考评阶段。
46.202:将待考核视频进行分段处理,得到第一视频段和第二视频段。
47.其中,第一视频段用于理论知识考评,即该第一视频段是对宠物医师的理论知识考评阶段进行拍摄得到的,第二视频段用于临床操作考评,即该第二视频段是对宠物医师临床操作考阶段评进行拍摄得到的。
48.203:对第一视频段中的多帧待识别图像进行识别,得到宠物医师的眼球的第一转动角度。
49.在本技术的实施例中,以多帧待识别图像中的任意一帧待识别图像得到第一转动角度为例进行阐述,即以第一待识别图像为例,对第一待识别图像进行识别,得到第一转动角度为例进行阐述。
50.示例性的,对第一待识别图像进行特征提取,得到与第一待识别图像对应的眼部轮廓特征图像,其中,眼部轮廓特征图像如图3a所示,第一待识别图像可以为多帧待识别图像中的任意一帧。
51.然后,根据眼部轮廓特征图像,建立第一空间直角坐标系。示例性的,根据眼部轮廓特征图像,建立第一空间直角坐标系的方法具体包括:从眼部轮廓特征图像中确定眼球在眼部轮廓图像中的外轮廓,需说明的是,眼球的外轮廓的形状为圆形;然后在外轮廓中标记出第一位置点和第二位置点,其中,眼部轮廓特征图像中第一位置点和第二位置点如图3b所示,第一位置点为外轮廓最左侧的点,第二位置点为外轮廓最右侧的点;将标记有第一位置点和第二位置点的眼部轮廓特征图像输入至预设的三维眼球模型库中,然后基于第一位置点和第二位置点在三维眼球模型库中模拟出眼球的三维模型,示例性的,计算第一位置点和第二位置点的第一直线距离,且标记出第一直线距离的中点,然后在中点的位置向正前方且平行于地面的方向延伸出第一位置点和中点的之间的距离长度值,得到一个端点,然后根据第一位置点、第二位置点以及端点的位置形成一个目标圆,此时圆形的外轮廓和目标圆围成的立体模型即为眼球的三维模型;最后基于眼球的三维模型建立第一空间直角坐标系,其中,第一空间直角坐标系如图3c所示,第一空间直角坐标系以三维模型中的眼球中心为第一坐标原点,以平行于地面,且以眼球的正前方为x轴,以垂直于地面,且指向正上方为z轴,以垂直于x轴,且水平指向左侧为y轴。
52.可选的,在实际应用中,在建立第一空间直角坐标系之前,可以对眼部轮廓特征图像进行预处理,比如去噪声、灰度化处理,然后基于预处理之后的眼部轮廓特征图像建立第一空间直角坐标系。
53.然后,获取眼球的第一瞳孔中心在第一空间直角坐标系中的坐标;根据第一瞳孔中心的坐标和第一坐标原点,确定眼球的方向,其中,眼球的方向如图 3d所示,眼球的方向为第一瞳孔中心和第一坐标原点之间的连线指向第一瞳孔中心的方向。
54.进一步的,根据眼球的方向确定第一待识别图像对应的第一候选夹角,其中,第一候选夹角如图3d所示,第一候选夹角为眼球的方向与x轴之间形成的夹角。
55.最后,根据基于第一待识别图像确定第一候选夹角的方法确定出多帧待识别图像对应的多个第一候选夹角,此处不再赘述,再对多个第一候选夹角求平均,得到第一转动角度。
56.204:根据第一转动角度,确定第一作弊概率。
57.在本技术的一种实施方式中,根据第一转动角度,确定第一作弊概率之前,作弊检测方法还包括:将第一视频段上传至语音识别模型,得到与第一视频段对应的语音流;对语音流进行端点检测,得到多个子语音流,其中,多个子语音流中每个子语音流与相邻子语音流之间的停顿时间间隔大于或等于时间阈值;将第一子语音流进行转化处理,得到第一语音文本;根据第一语音文本和第一子语音流对应的音频时长,确定第一子语音流对应的第一语速;对多个子语音流对应的多个第一语速求平均,得到第二语速。
58.示例性的,将第一视频段上传至语音识别模型,可以采用现有技术从第一视频段中提取出语音流,此处语音流可以理解为音频数据,正如图4所示,从第一视频段中得到语音流,当宠物医师在讲话时,语音流会随着宠物医师的音量大小和语速快慢,呈现出上下起伏的曲线,当宠物医师保持沉默时,语音流会呈现出平稳的直线;然后对语音流进行端点检测,即检测语音流的开始点、结束点以及中间的每段语音流的开始点和结束点,或者说,把语音流分割成多个子语音流,正如图4所示,每段语音流的开始点用h表示,结束点用y表示,然后基于开始点和结束点将语音流进行分割,得到多个子语音流,需要说明的是,此处多个子语音流中每个子语音流与它本身相邻的子语音流之间的停顿时间间隔大于或等于时间阈值,也就是说,宠物医师保持沉默的时间大于或等于时间阈值。需要说明的是,此处将以多个子语音流中的任意一个子语音流为例进行阐述,即以第一子语音流为例,对第一子语音流进行转化处理,得到第一语音文本,此处可以采用自然语言处理技术对第一子语音流进行识别。以第一子语音流得到第一语音文本为例,其中,第一子语音流为多个子语音流中的任意一个,如图4所示,将得到的多个子语音流都进行转化处理,得到对应的多个第一语音文本;进一步的,计算第一语音文本中的文字长度,然后根据文字长度和第一子语音流对应的音频时长计算出第一语音流对应的第一语速;然后,根据计算第一语音流对应的第一语速的方法来计算多个子语音流对应的多个第一语速,然后对多个第一语速求平均,得到第二语速。
59.基于此,在本技术一种实施方式中,提供了一种根据第一转动角度,确定第一作弊概率的方法,具体包括:
60.根据第一转动角度,确定第三作弊概率;
61.其中,第三作弊概率可以通过公式(1)得到:
[0062][0063]
其中,f1为第三作弊概率,α为第一转动角度,0<a<1,b为常数。
[0064]
然后,根据第二语速,确定第四作弊概率。示例性的,计算第一语速与第二语速的比值,得到语速比,将语速比与预设比值区间进行比较,比如可以将预设比值区间划分为语速缓慢区、语速较慢区、语速适当区、语速稍快区和语速较快区,其中,若语速比在语速适当区,则第三作弊概率为0,若语速比在语速缓慢区和语速稍快区,则第三作弊概率为m,若语速比在语速较慢区和语速较快区,则第三作弊概率为n,其中,m和n的取值在此处不作限定。
[0065]
最后,将第三作弊概率和第四作弊概率进行加权,得到第一作弊概率。示例性的,将第三作弊概率乘以预设权重和第四作弊概率乘以预设权重相加,作为第一作弊概率。
[0066]
205:对第二视频段进行语音识别,确定眼球的第二转动角度。
[0067]
示例性的,对第二视频段进行语音识别,确定待操作部位;从第二视频段中,获取与待操作部位对应的多帧候选图像;对多帧候选图像进行轮廓识别,得到多帧目标图像,其中,多帧目标图像中的任意一帧目标图像包括待操作部位轮廓和眼睛轮廓;根据第一目标图像建立第二空间直角坐标系,建立第二空间直角坐标系的方法与建立第一空间直角坐标系的方法类似,不再赘述,其中,第二空间直角坐标系以眼睛轮廓对应的眼球中心为第二坐标原点。
[0068]
然后,在第二空间直角坐标系中获取待操作部位轮廓中心的坐标和第二瞳孔中心的坐标;然后,根据第二坐标原点、待操作部位轮廓中心的坐标以及第二瞳孔中心的坐标,确定第二候选夹角,其中,第二候选夹角可以为第二坐标原点分别与待操作部位轮廓中心的坐标和第二瞳孔中心的坐标连接线之间所形成的夹角;最后,对多帧目标图像对应的多个第二候选夹角求平均,得到第二转动角度。
[0069]
206:根据第二转动角度,确定第二作弊概率。
[0070]
在本技术的一个实施方式中,第二作弊概率可以通过公式(2)得到:
[0071][0072]
其中,f2为第二作弊概率,β为第二转动角度,0<c<1,d为常数。
[0073]
207:根据第一作弊概率和第二作弊概率,确定宠物医师是否存在作弊行为。
[0074]
示例性的,根据第一作弊概率和第二作弊概率的权重,对第一作弊概率和第二作弊概率进行加权,得到目标作弊概率;若目标作弊概率大于或等于第二概率阈值,确定宠物医师存在作弊行为。
[0075]
可以看出,在本技术实施例中,通过对宠物医师的待考核视频进行分段处理,得到用于理论知识考评的第一视频段和用于临床操作考评的第二视频段;再对第一视频段中的多帧待识别图像进行识别,得到宠物医师的眼球的第一转动角度,并基于第一转动角度确定第一作弊概率;对第二视频段进行语音识别,得到眼球的第二转动角度,并基于第二转动角度确定第二作弊概率;最后基于第一作弊概率和第二作弊概率,确定宠物医师是否存在作弊行为,通过对理论知识考评和临床操作考评过程中宠物医师的眼球转动角度计算作弊概率,基于上述计算双重作弊概率,提高了检测作弊行为的准确性,进而保证线上考评的公正性。
[0076]
参阅图5,图5为本技术实施例提供的一种作弊检测装置的功能单元组成框图。作弊检测装置500包括:获取单元501和处理单元502;
[0077]
获取单元501,用于获取宠物医师的待考核视频;
[0078]
处理单元502,用于将待考核视频进行分段处理,得到第一视频段和第二视频段,其中,第一视频段用于理论知识考评,第二视频段用于临床操作考评;
[0079]
对第一视频段中的多帧待识别图像进行识别,得到宠物医师的眼球的第一转动角度;
[0080]
根据第一转动角度,确定第一作弊概率;
[0081]
对第二视频段进行语音识别,确定眼球的第二转动角度;
[0082]
根据第二转动角度,确定第二作弊概率;
[0083]
根据第一作弊概率和第二作弊概率,确定宠物医师是否存在作弊行为。
[0084]
在本技术的一个实施方式中,在对第一视频段中的多帧待识别图像进行识别,宠物医师的眼球的第一转动角度方面,处理单元502,具体用于:
[0085]
对第一待识别图像进行特征提取,得到与第一待识别图像对应的眼部轮廓特征图像,第一待识别图像为多帧待识别图像中的任意一帧;
[0086]
根据眼部轮廓特征图像,建立第一空间直角坐标系,其中,第一空间直角坐标系以眼部轮廓特征图像中的眼球中心为第一坐标原点,以平行于地面指向正前方为x轴,以垂直于地面指向正上方为z轴,以垂直于x轴水平指向左侧为y轴;
[0087]
获取第一空间直角坐标系中第一瞳孔中心的坐标;
[0088]
根据第一瞳孔中心的坐标和第一坐标原点,确定眼球的方向,眼球的方向为第一瞳孔中心和第一坐标原点之间的连线指向第一瞳孔中心的方向;
[0089]
根据眼球的方向,确定第一待识别图像对应的第一候选夹角,第一候选夹角为眼球的方向与x轴之间形成的夹角;
[0090]
对多帧待识别图像对应的多个第一候选夹角求平均,得到第一转动角度。
[0091]
在本技术的一个实施方式中,在对第二视频段进行语音识别,确定眼球的第二转动角度方面,处理单元502,具体用于:
[0092]
对第二视频段进行语音识别,确定待操作部位;
[0093]
从第二视频段中,获取与待操作部位对应的多帧候选图像;
[0094]
对多帧候选图像进行轮廓识别,得到多帧目标图像,其中,多帧目标图像中的任意一帧目标图像包括待操作部位轮廓和眼睛轮廓;
[0095]
根据第一目标图像建立第二空间直角坐标系,其中,第二空间直角坐标系以眼睛轮廓对应的眼球中心为第二坐标原点;
[0096]
在第二空间直角坐标系中获取待操作部位轮廓中心的坐标和第二瞳孔中心的坐标;
[0097]
根据第二坐标原点、待操作部位轮廓中心的坐标以及第二瞳孔中心的坐标,确定第二候选夹角,其中,第二候选夹角为第二坐标原点分别与待操作部位轮廓中心的坐标和第二瞳孔中心的坐标连接线之间所形成的夹角;
[0098]
对多帧目标图像对应的多个第二候选夹角求平均,得到第二转动角度。
[0099]
在本技术的一个实施方式中,在根据第一转动角度,确定第一作弊概率之前方面,处理单元502,具体用于:
[0100]
将第一视频段上传至语音识别模型,得到与第一视频段对应的语音流;
[0101]
对语音流进行端点检测,得到多个子语音流,其中,多个子语音流中每个子语音流与相邻子语音流之间的停顿时间间隔大于或等于时间阈值;
[0102]
将第一子语音流进行转化处理,得到第一语音文本,其中,第一子语音流为多个子语音流中的任意一个;
[0103]
根据第一语音文本和第一子语音流对应的音频时长,确定第一子语音流对应的第一语速;
[0104]
对多个子语音流对应的多个第一语速求平均,得到第二语速;
[0105]
根据第一转动角度,确定第一作弊概率,包括:
[0106]
根据第一转动角度,确定第三作弊概率;
[0107]
根据第二语速,确定第四作弊概率;
[0108]
将第三作弊概率和第四作弊概率进行加权,得到第一作弊概率。
[0109]
在本技术的一个实施方式中,在根据第一作弊概率和第二作弊概率,确定宠物医师有无作弊行为方面,处理单元502,具体用于:
[0110]
根据第一作弊概率和第二作弊概率的权重,对第一作弊概率和第二作弊概率进行加权,得到目标作弊概率;
[0111]
若目标作弊概率大于或等于第二概率阈值,确定宠物医师存在作弊行为。
[0112]
参阅图6,图6为本技术实施例提供的一种电子设备的结构示意图。如图6 所示,电子设备600包括收发器601、处理器602和存储器603。它们之间通过总线604连接。存储器603用于存储计算机程序和数据,并可以将存储器603 存储的数据传输给处理器602。
[0113]
处理器602用于读取存储器603中的计算机程序执行以下操作:
[0114]
控制收发器601获取宠物医师的待考核视频;
[0115]
将待考核视频进行分段处理,得到第一视频段和第二视频段,其中,第一视频段用于理论知识考评,第二视频段用于临床操作考评;
[0116]
对第一视频段中的多帧待识别图像进行识别,得到宠物医师的眼球的第一转动角度;
[0117]
根据第一转动角度,确定第一作弊概率;
[0118]
对第二视频段进行语音识别,确定眼球的第二转动角度;
[0119]
根据第二转动角度,确定第二作弊概率;
[0120]
根据第一作弊概率和第二作弊概率,确定宠物医师是否存在作弊行为。
[0121]
在本技术的一个实施方式中,在对第一视频段中的多帧待识别图像进行识别,得到宠物医师的眼球的第一转动角度方面,处理器602,具体用于执行以下步骤:
[0122]
对第一待识别图像进行特征提取,得到与第一待识别图像对应的眼部轮廓特征图像,第一待识别图像为多帧待识别图像中的任意一帧;
[0123]
根据眼部轮廓特征图像,建立第一空间直角坐标系,其中,第一空间直角坐标系以眼部轮廓特征图像中的眼球中心为第一坐标原点,以平行于地面指向正前方为x轴,以垂直于地面指向正上方为z轴,以垂直于x轴水平指向左侧为y轴;
[0124]
获取第一空间直角坐标系中第一瞳孔中心的坐标;
[0125]
根据第一瞳孔中心的坐标和第一坐标原点,确定眼球的方向,眼球的方向为第一瞳孔中心和第一坐标原点之间的连线指向第一瞳孔中心的方向;
[0126]
根据眼球的方向,确定第一待识别图像对应的第一候选夹角,第一候选夹角为眼球的方向与x轴之间形成的夹角;
[0127]
对多帧待识别图像对应的多个第一候选夹角求平均,得到第一转动角度。
[0128]
在本技术的一个实施方式中,在根据第一转动角度,确定第一作弊概率之前方面,处理器602,具体用于执行以下步骤:
[0129]
将第一视频段上传至语音识别模型,得到与第一视频段对应的语音流;
[0130]
对语音流进行端点检测,得到多个子语音流,其中,多个子语音流中每个子语音流与相邻子语音流之间的停顿时间间隔大于或等于时间阈值;
[0131]
将第一子语音流进行转化处理,得到第一语音文本,其中,第一子语音流为多个子
语音流中的任意一个;
[0132]
根据第一语音文本和第一子语音流对应的音频时长,确定第一子语音流对应的第一语速;
[0133]
对多个子语音流对应的多个第一语速求平均,得到第二语速;
[0134]
根据第一转动角度,确定第一作弊概率,包括:
[0135]
根据第一转动角度,确定第三作弊概率;
[0136]
根据第二语速,确定第四作弊概率;
[0137]
将第三作弊概率和第四作弊概率进行加权,得到第一作弊概率。
[0138]
在本技术的一个实施方式中,在根据第一作弊概率和第二作弊概率,确定宠物医师有无作弊行为方面,处理器602,具体用于执行以下步骤:
[0139]
根据第一作弊概率和第二作弊概率的权重,对第一作弊概率和第二作弊概率进行加权,得到目标作弊概率;
[0140]
若目标作弊概率大于或等于第二概率阈值,确定宠物医师存在作弊行为。
[0141]
具体地,上述收发器601可为图5的实施例的作弊检测装置500的获取单元501,上述处理器602可以为图5的实施例的作弊检测装置500的处理单元 502。
[0142]
应理解,本技术中的电子设备可以包括智能手机(如android手机、ios手机、windows phone手机等)、平板电脑、掌上电脑、笔记本电脑、移动互联网设备mid(mobile internet devices,简称:mid)或穿戴式设备等。上述电子设备仅是举例,而非穷举,包含但不限于上述电子设备。在实际应用中,上述电子设备还可以包括:智能车载终端、计算机设备等等。
[0143]
本技术实施例还提供一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序被处理器执行以实现如上述方法实施例中记载的任何一种作弊检测方法的部分或全部步骤。
[0144]
本技术实施例还提供一种计算机程序产品,计算机程序产品包括存储了计算机程序的非瞬时性计算机可读存储介质,计算机程序可操作来使计算机执行如上述方法实施例中记载的任何一种作弊检测方法的部分或全部步骤。
[0145]
需要说明的是,对于前述的各方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本技术并不受所描述的动作顺序的限制,因为依据本技术,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于可选实施例,所涉及的动作和模块并不一定是本技术所必须的。
[0146]
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。
[0147]
在本技术所提供的几个实施例中,应该理解到,所揭露的装置,可通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性或其它的形式。
[0148]
作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
[0149]
另外,在本技术各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件程序模块的形式实现。
[0150]
集成的单元如果以软件程序模块的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储器中。基于这样的理解,本技术的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储器中,包括若干指令用以使得一台计算机设备(可为个人计算机、服务器或者网络设备等) 执行本技术各个实施例方法的全部或部分步骤。而前述的存储器包括:u盘、只读存储器(rom,read-only memory)、随机存取存储器(ram,random accessmemory)、移动硬盘、磁碟或者光盘等各种可以存储程序代码的介质。
[0151]
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储器中,存储器可以包括:闪存盘、只读存储器(英文:read-only memory,简称:rom)、随机存取器(英文:random access memory,简称:ram)、磁盘或光盘等。
[0152]
以上对本技术实施例进行了详细介绍,本文中应用了具体个例对本技术的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本技术的方法及其核心思想;同时,对于本领域的一般技术人员,依据本技术的思想,在具体实施方式及应用范围上均会有改变之处,综上,本说明书内容不应理解为对本技术的限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。