1.本发明涉及加密流量检测技术领域,尤其涉及一种基于网关流量的数字货币币种检测方法。
背景技术:
2.当前虽然存在着对挖矿活动的检测,但是没有对数字货币币种的检测。
技术实现要素:
3.基于此,本发明提供一种基于网关流量的数字货币币种检测方法。
4.为了实现上述目的,本发明提供如下技术方案:
5.本发明提供的一种基于网关流量的数字货币币种检测方法,包括以下步骤:
6.s1、流量收集,获得流量文件;
7.s2、使用tstat工具对流量文件进行特征提取;
8.s3、基于机器学习的分类方法训练数据集,得到检测模型;
9.s4、对检测模型进行性能评估;
10.s5、采用检测模型进行数字货币币种检测。
11.进一步地,步骤s1中,在linux平台上,使用tcpdump抓取流量。
12.进一步地,步骤s1中,在windows平台上,使用wireshark抓取流量。
13.进一步地,步骤s1所述的流量文件为.pcap文件。
14.进一步地,步骤s2使用tstat工具分析流量文件时,生成从不同的角度描述这些流量的9个文件,这9个文件中包括描述所有完整tcp连接流量的文件。
15.进一步地,步骤s2通过tls加密stratum协议被tcp层封装。
16.进一步地,步骤s2选用描述所有完整tcp连接流量的文件中的51个数据特征,分别为从客户端到服务端方向的29个数据和从服务端到客户端方向的22个数据。
17.进一步地,步骤s3选用使用sklearn来构建id3、cart决策树、随机森林或logistic回归,其中,id3和cart决策树的最大层数max_depth都是4。
18.进一步地,步骤s3在数据集里随机分配数据到训练集和测试集,训练集和测试集的比例是7:3。
19.进一步地,步骤s4中性能评估包括离线评估和在线评估两个阶段。
20.与现有技术相比,本发明的有益效果为:
21.本发明的基于网关流量的数字货币币种检测方法,基于机器学习算法,通过局域网的网络流量,识别出该局域网是否存在挖矿行为,如果存在,将进一步识别出所挖掘的币种。
附图说明
22.为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例中所
需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他的附图。
23.图1为基尼系数和熵之半的曲线图。
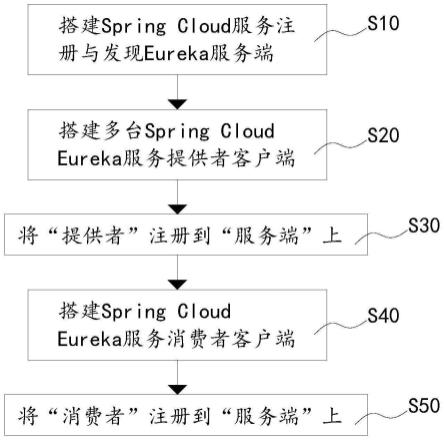
24.图2为本发明实施例提供的基于网关流量的数字货币币种检测方法流程图。
具体实施方式
25.下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
26.本发明的基于网关流量的数字货币币种检测方法,如图2所示,包括以下步骤:
27.s1、流量收集,获得流量文件。
28.具体地,在linux平台上,可以使用tcpdump抓取流量,在windows 平台上,可以使用wireshark抓取。只需运行流量抓取程序,即可获得.pcap 文件。
29.s2、使用tstat工具对流量文件进行特征提取。
30.tstat是一款网络流量分析工具,可以作用于.pcap等网络流量文件。该工具分析网络流量,生成9个文件从不同的角度描述这些流量,这9个文件中包括描述所有完整tcp连接流量的文件。
31.由于本发明针对的且也是被广泛使用的流量文件,通过tls来加密 stratum协议这一方式是被tcp层封装的,矿工和矿池是通过tcp连接来通信的,因此,本发明仅选用描述所有完整tcp连接流量的文件,该文件使用了130个特征,本发明选择51个特征,这些特征不包含应用层的数据信息以及ip、端口这类用户敏感信息,这些特征如表1所示。
32.表1
33.csscnamemetricdescription317packets-total number of packets observed from the client/server519ack sent-number of segments with the ack field set to 1620pure ack sent-number of segments with ack field set to 1 and no data721unique bytesbytesnumber of bytes sent in the payload822data pkts-number of segments with payload923data bytesbytesnumber of bytes transmitted in the payload,including re-transmissions31-completion timemsflow duration since first packet to last packet32-c first payloadmsclient first segment with payload sincethe first flow segment33-s first payloadmsserver first segment with payload since the first flow segment34-c last payloadmsclient last segnent with payload since the first flow segment35-s last payloadmsserver last segment with payload since the first fliw segment36-c first ackmsclient first ack segment(without syn)since the first flow segment37-s first ackmsserver first ack segment(without syn)since the first flow segment4552average rttmsaverage rtt computed measuring the time elapsed between the data segment and the corresponding ack4653rtt minmsminimum rtt observed during connection lifetime4754rtt maxmsmaximum rtt observed during connection lifetime4855stdev rttmsstandard deviation if the rtt4956rtt count-number of valid rtt observation5057ttl_min-minimum time to live5158ttl_max-maximum time to live6588rfc1323ws0/1window scale option sent6689rfc1323ts0/1timestamp option sent6790window scale-scaling values negotiated[scale factor]
6891sack req0/1sack option set7093mssbytesmss declared7194max seg size bytes-maximum segment size observed7295min seg sizebytesminimum segment size observed7396win maxbytesmaximum receiver window announced(already scale by the window scale factor)7497win minbytesmaximum receiver windows announced(already scale by the window scale factor)
[0034]
表1中,cs表示从客户端到服务端方向的数据,sc反之。
[0035]
s3、基于机器学习的分类方法训练数据集,得到检测模型。
[0036]
加密流量检测方法主要是通过基于机器学习的分类方法实现的,包括 id3决策树,cart决策时,随机森林,logistic回归,神经网络等。
[0037]
1、id3决策树
[0038]
id3算法是由quinlan首先提出的。该算法是以信息论为基础,以信息熵和信息增益度为衡量标准,从而实现对数据的归纳分类。以下是一些信息论的基本概念:
[0039]
定义1:若存在n个相同概率的消息,则每个消息的概率p是1/n,一个消息传递的信息量为-log2(1/n)。
[0040]
定义2:若有n个消息,其给定概率分布为p=(p1,p2…
pn),则由该分布传递的信息量称为p的熵。
[0041]
定义3:若一个记录集合t根据类别属性的值被分成互相独立的类 c1c2..ck,则识别t的一个元素所属哪个类所需要的信息量为info(t)=i(p),其中p为c1c2…ck
的概率分布,即p=(|c1|/|t|,
…
|ck|/|t|)
[0042]
定义4:若我们先根据非类别属性x的值将t分成集合t1,t2…
tn,则确定t中一个元素类的信息量可通过确定ti的加权平均值来得到,即 info(ti)的加权平均值为:
[0043]
info(x,t)=(i=1 to n求和)((|ti|/|t|)info(ti))
[0044]
定义5:信息增益度是两个信息量之间的差值,其中一个信息量是需确定t的一个元素的信息量,另一个信息量是在已得到的属性x的值后需确定的t一个元素的信息量,信息增益度公式为:
[0045]
gain(x,t)=info(t)-info(x,t)
[0046]
id3算法计算每个属性的信息增益,并选取具有最高增益的属性作为给定集合的测试属性。对被选取的测试属性创建一个节点,并以该节点的属性标记,对该属性的每个值创建一个分支据此划分样本。
[0047]
2、cart决策树
[0048]
在id3算法中使用信息增益来选择特征,信息增益大的优先选择。在 c4.5算法中,采用了信息增益比来选择特征,以减少信息增益容易选择特征值多的特征的问题。但是无论是id3还是c4.5,都是基于信息论的熵模型的,这里面会涉及大量的对数运算。能不能简化模型同时也不至于完全丢失熵模型的优点呢?有cart分类树算法使用基尼系数来代替信息增益比,基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好。这和信息增益(比)是相反的。
[0049]
具体的,在分类问题中,假设有k个类别,第k个类别的概率为pk,则基尼系数的表达式为:
[0050]
gini(p)=∑k=1kpk(1-pk)=1-∑k=1kp2k
[0051]
如果是二类分类问题,计算就更加简单了,如果属于第一个样本输出的概率是p,
则基尼系数的表达式为:
[0052]
gini(p)=2p(1-p)
[0053]
对于个给定的样本d,假设有k个类别,第k个类别的数量为ck,则样本d的基尼系数表达式为:
[0054]
gini(d)=1-∑k=1k(|ck||d|)2
[0055]
特别的,对于样本d,如果根据特征a的某个值a,把d分成d1和d2两部分,则在特征a的条件下,d的基尼系数表达式为:
[0056]
gini(d,a)=|d1||d|gini(d1) |d2||d|gini(d2)
[0057]
可以比较下基尼系数表达式和熵模型的表达式,二次运算是不是比对数简单很多?尤其是二类分类的计算,更加简单。但是简单归简单,和熵模型的度量方式比,基尼系数对应的误差有多大呢?对于二类分类,基尼系数和熵之半的曲线如图1所示。
[0058]
从图1可以看出,基尼系数和熵之半的曲线非常接近,仅仅在45度角附近误差稍大。因此,基尼系数可以做为熵模型的一个近似替代。而cart 分类树算法就是使用的基尼系数来选择决策树的特征。同时,为了进一步简化,cart分类树算法每次仅仅对某个特征的值进行二分,而不是多分,这样cart分类树算法建立起来的是二叉树,而不是多叉树。这样一可以进一步简化基尼系数的计算,二可以建立一个更加优雅的二叉树模型。
[0059]
3、logistic回归
[0060]
logistic回归是一种广义线性回归(generalized linear model),因此与多重线性回归分析有很多相同之处。它们的模型形式基本上相同,都具有 w
‘
x b,其中w和b是待求参数,其区别在于他们的因变量不同,多重线性回归直接将w
‘
x b作为因变量,即y=w
‘
x b,而logistic回归则通过函数l将w
‘
x b对应一个隐状态p,p=l(w
‘
x b),然后根据p与1-p 的大小决定因变量的值。如果l是logistic函数,就是logistic回归,如果l是多项式函数就是多项式回归。
[0061]
logistic回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释,多类可以使用softmax方法进行处理。实际中最为常用的就是二分类的logistic回归。
[0062]
logistic回归模型的适用条件
[0063]
a.因变量为二分类的分类变量或某事件的发生率,并且是数值型变量。但是需要注意,重复计数现象指标不适用于logistic回归。
[0064]
b.残差和因变量都要服从二项分布。二项分布对应的是分类变量,所以不是正态分布,进而不是用最小二乘法,而是最大似然法来解决方程估计和检验问题。
[0065]
c.自变量和logistic概率是线性关系
[0066]
d.各观测对象间相互独立。
[0067]
原理:如果直接将线性回归的模型扣到logistic回归中,会造成方程二边取值区间不同和普遍的非直线关系。因为logistic中因变量为二分类变量,某个概率作为方程的因变量估计值取值范围为0-1,但是,方程右边取值范围是无穷大或者无穷小。所以,才引入logistic回归。
[0068]
logistic回归实质:发生概率除以没有发生概率再取对数。就是这个不太繁琐的变换改变了取值区间的矛盾和因变量自变量间的曲线关系。究其原因,是发生和未发生的
概率成为了比值,这个比值就是一个缓冲,将取值范围扩大,再进行对数变换,整个因变量改变。不仅如此,这种变换往往使得因变量和自变量之间呈线性关系,这是根据大量实践而总结。所以, logistic回归从根本上解决因变量要不是连续变量怎么办的问题。还有, logistic应用广泛的原因是许多现实问题跟它的模型吻合。例如一件事情是否发生跟其他数值型自变量的关系。
[0069]
4、随机森林
[0070]
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。这个术语是1995年由贝尔实验室的tin kam ho所提出的随机决策森林(random decision forests)而来的。这个方法则是结合breimans的"bootstrap aggregating"想法和ho 的"random subspace method"以建造决策树的集合。
[0071]
根据下列算法而建造每棵树:
[0072]
a.用n来表示训练用例(样本)的个数,m表示特征数目。
[0073]
b.输入特征数目m,用于确定决策树上一个节点的决策结果;其中m 应远小于m。
[0074]
c.从n个训练用例(样本)中以有放回抽样的方式,取样n次,形成一个训练集(即bootstrap取样),并用未抽到的用例(样本)作预测,评估其误差。
[0075]
d.对于每一个节点,随机选择m个特征,决策树上每个节点的决定都是基于这些特征确定的。根据这m个特征,计算其最佳的分裂方式。
[0076]
每棵树都会完整成长而不会剪枝,这有可能在建完一棵正常树状分类器后会被采用。
[0077]
本发明实施例中:
[0078]
使用sklearn来构建id3和cart决策树,他们的最大层数max_depth 都是4。在数据集里随机分配数据到训练集和测试集,训练集和测试集的比例是7:3。
[0079]
使用sklearn来构建随机森林,在数据集里随机分配数据到训练集和测试集,训练集和测试集的比例是7:3。
[0080]
使用sklearn来构建logistic回归,在数据集里随机分配数据到训练集和测试集,训练集和测试集的比例是7:3。
[0081]
s4、对检测模型进行性能评估。
[0082]
在机器学习领域中,对模型的评估非常重要,只有选择和问题相匹配的评估方法,才能快速发现算法模型或者训练过程的问题,迭代地对模型进行优化。
[0083]
模型评估主要分为离线评估和在线评估两个阶段。并且针对分类、回归、排序、序列预测等不同类型的机器学习问题,评估指标的选择也有所不同。性能度量就是指对模型泛化能力衡量的评价标准。分类问题中最常用的性能度量标准
‑‑
准确率。准确率,指的是分类正确的样本数量占样本总数的比例,定义为预测正确的样本个数和样本总数的比例。这种评价标准是分类问题中最简单也是最直观的评价指标。
[0084]
在本发明实施例中,当前所选用的划分数据集的方式是每次运行程序都从数据集里按7:3的比例随机选取数据到训练集和测试集,因此每次运行程序所使用的训练集和测试集都可能不同,构建出的模型也可能是不同的,性能也不一样。
[0085]
s5、采用检测模型进行数字货币币种检测。
[0086]
目前存在非加密的情况下对币种进行检测的方案,如使用4种机器学习的算法对5
类币种做出识别,算法分别是svm、cart、c4.5、朴素贝叶斯。这一方案下,svm、cart、c4.5、朴素贝叶斯四种算法对币种识别的准确率分别是:0.912、0.963、0.967、0.973。
[0087]
然而,目前没有在加密流量下进行币种检测的方案,本发明使用的四种机器学习算法,id3决策树、cart决策树、逻辑斯蒂回归、随机森林对 4类币种进行识别的准确率分别是0.976、0.965、0.947、0.991。
[0088]
综上,本发明不但可以在加密的情况下进行币种识别,而且可以看出,本发明所选择的四种机器学习算法中,性能最好的算法—随机森林的准确率0.991,比其他方案性能最好的算法的准确率0.973要高,具有显著的进步。
[0089]
本说明书中的各个实施例均采用相关的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于装置实施例、电子设备实施例、计算机可读存储介质实施例和计算机程序产品实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
[0090]
以上所述实施例,仅为本技术的具体实施方式,用以说明本技术的技术方案,而非对其限制,本技术的保护范围并不局限于此,尽管参照前述实施例对本技术进行了详细的说明,本领域的普通技术人员应当理解:任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,其依然可以对前述实施例所记载的技术方案进行修改或可轻易想到变化,或者对其中部分技术特殊进行等同替换;而这些修改、变化或者替换,并不使相应技术方案的本质脱离本技术实施例技术方案的精神和范围。都应涵盖在本技术的保护范围之内。因此,本技术的保护范围应所述以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。