1.本发明涉及一种基于随机森林的隧道混合流量分类方法及系统,属于计算机软件技术领域。
背景技术:
2.随着互联网的发展,加密网络流量正在迅速增长。由于隧道流量的封装和加密特性,使得它占据了加密流量的很大一部分。越来越多的用户使用隧道技术来保护通信的安全。虽然隧道技术保证了通信的安全,但它也给网络管理带来了挑战。一些恶意网络服务通过隧道和加密技术绕过防火墙和入侵检测系统。因此隧道流量识别在网络安全和网络管理领域是非常重要的。
3.之前的研究提出了一些加密流量识别的方法,主要分为基于机器学习和深度学习的方法。机器学习方法主要从加密的网络流量中提取以下流量特征,如前n个带方向的包长度序列、包长度统计特征和包到达时间间隔的统计特征,使用k近邻、支持向量机等模型作为分类器。深度学习方法使用包长序列和包到达时间间隔序列作为输入,利用卷积自编码和卷积神经网络用于加密流量分类。
4.由于网络行为在时间上存在交叉和重叠,使得网络流量存在混合的问题。混合的加密应用流量可以通过流分类来识别,因为每个应用流量都有不同的五元组信息(源ip、目的ip、源端口、目的端口、ip版本)。然而,准确有效地识别隧道流量是一项具有挑战性的任务。首先,应用流量被封装和加密在隧道中,原始特征细节发生了很大的改变。而且,隧道中的应用流量具有相同的五元组,很难获得每个应用的开始和结束时间。因此现有的加密流量分类方法不能直接用于隧道流量分类。其次,隧道流量的混合情况很多,而且存在很大差异。分类的结果也将受到重叠形式和重叠率的影响。因此隧道内流量的识别变得具有挑战性。已公开的中国发明专利cn110113338a公开了一种基于特征融合的加密流量特征提取方法,通过抽取一条加密流中加密数据包不同维度的特征值;计算特征贡献度并归一化,再基于特征贡献度进行特征选择,挑选出参与融合的最优特征数量n,并选择前n个特征作为参与融合的最优特征量;基于最优融合特征数量n对不同维度的特征进行归类、使用核函数对步骤2选出的参与融合的最优特征进行升维和融合,输出最终参与分类的特征集合。但该方法是针对加密应用流量分类,提取2维burst特征(burst size和burst length),直接连接起来用来表征整个加密应用的流量,是对加密应用流量进行分类,不能用于对隧道内混合流量的分类。
5.目前关于混合流量的识别主要集中在tor上,关于隧道内混合流量识别的研究较少。tor上混合流识别的方法按照分割的不同分为两种:基于寻找分割点的方法,基于均匀分割的方法。一些研究利用包时间间隔和包方向的统计特征,利用knn和隐马尔科夫模型寻找分割点。分割的结果在不重叠网络流量上识别效果较好,但当应用流量存在重叠时,识别效果急剧下降。关于均匀分割的方法主要有利用时间和数据包数目等进行分割,利用knn模型进行网络流量分类。这些方法在隧道内识别效果较差。因此需要开展隧道内混合流量识
别的研究。
技术实现要素:
6.本发明旨在针对隧道内流量分类存在混合的问题,提供一种基于随机森林的隧道混合流量分类方法及系统,使用机器学习算法,无须对模型进行多次训练,对硬件要求也不太高,可以实现隧道内混合流量的识别。
7.本发明采用的技术方案如下:
8.一种基于随机森林的隧道混合流量分类方法,包括以下步骤:
9.1)采集网络流量数据包,该网络流量数据包中包含待分类的隧道混合流量;
10.2)利用数据包长度对所述隧道混合流量进行首次分裂,再利用数据包长度和包方向的统计特征进行再次分裂,判断再次分裂结果是否为混合流量;
11.3)如果再次分裂结果不是混合流量,则对当中的单个网络行为流量提取包长度和包方向的统计特征,根据该统计特征利用随机森林分类器对流量进行分类,输出分类结果;
12.4)如果再次分裂结果是混合流量,则对混合流量按照数据包方向划分突发流量burst(即连续的同一方向的数据包构成的流量)并分裂,再对分裂的burst进行聚合;
13.5)对聚合的burst提取统计特征,根据该统计特征利用随机森林分类器对隧道流量进行分类,然后通过多数表决,输出分类结果。
14.进一步地,通过一噪声分裂模块实现步骤2),通过一burst聚合模块实现步骤4),通过一特征提取分类模块实现步骤3)和5);首先对步骤1)采集的网络流量数据包利用隧道回放的方法生成的隧道混合流量并进行标注,生成训练集,利用该训练集来训练噪声分裂模块、burst聚合模块和特征提取分类模块;训练完成后用来处理待分类的隧道混合流量,输出分类结果。
15.进一步地,步骤2)中的统计特征为54维统计特征。
16.进一步地,步骤3)中的统计特征为三个方向的统计特征:客户端到服务端、服务端到客户端、客户端与客户端双向。
17.一种基于随机森林的隧道混合流量分类系统,包括:
18.混合流生成模块,用于采集网络流量数据包,该数据包中包含待分类的隧道混合流量;
19.噪声分裂模块,包括数据包分裂子模块、分类器分裂子模块和分裂决策子模块,数据包分裂子模块用于利用数据包长度对隧道混合流量进行首次分裂,分类器分裂子模块用于利用数据包长度和包方向的统计特征进行再次分裂,分裂决策子模块用于判断再次分裂结果是否为混合流量;
20.burst聚合模块,包括burst分裂子模块和burst聚合子模块,burst分裂子模块用于对混合流量按照数据包方向划分burst并分裂,burst聚合子模块用于对分裂的burst进行聚合;
21.特征提取分类模块,包括两个特征提取子模块、两个分类器子模块和一个多数表决子模块,第一特征提取子模块用于对噪声分裂模块发来的非混合流量当中的单个网络行为流量,提取包长度和包方向的统计特征;第一分类器子模块用于根据该统计特征利用随机森林分类器对流量进行分类,输出分类结果;第二特征提取子模块用于对burst聚合模块
发来的聚合的burst提取统计特征;第二分类器子模块用于根据该统计特征利用随机森林分类器对隧道流量进行分类;多数表决子模块用于对第二分类器子模块的分类进行多数表决,输出分类结果。
22.进一步地,混合流生成模块用于采集网络流量数据包,利用隧道回放的方法生成隧道混合流量并进行标注,生成训练集;噪声分裂模块根据该训练集进行训练,输出分裂判断结果;burst聚合模块根据噪声分裂模块输出的分裂判断结果进行训练,输出聚合结果;特征提取分类模块根据噪声分裂模块输出的分裂判断结果和burst聚合模块输出的聚合结果进行训练,输出分类结果。
23.进一步地,噪声分裂模块根据分裂准确率来判断是否训练完成,burst聚合模块和特征提取分类模块根据判断的正确率来判断是否训练完成。
24.本发明采用基于数据包和基于分类器相结合的首次分裂方法,对隧道内正时间分离应用流量进行分裂,并利用分裂决策算法对隧道内多种类型的流量选择不同的处理,利用基于burst分裂和burst结合的二次分裂方法,对隧道内零时间和负时间分离应用流量进行分裂。本发明可以实现隧道内单人使用场多应用场景的混合流量识别,首次分裂框架利用基于数据包和分类器结合的方法,识别正时间分离应用之间的流量。基于数据包的方法利用包长度特征对正时间分离应用流量进行首次分裂,利用分类器方法使用统计特征对混合流量进行二次分裂。二次分裂框架利用burst分裂和burst结合的方法,识别零时间和负时间分离的应用。基于burst利用包方向特征对隧道内混合流量进行分裂,然后使用burst结合对隧道内流量再次分裂。
25.本发明的优点在于:提出隧道内混合流量分类的框架,使用数据包和分类器相结合的首次分割框架,使用决策模块判断后,利用burst分裂和burst结合的方法进行二次分割。基于随机森林算法,无须调节过多的参数,并且容易实现并行化。适合长流和短流的混合,利用burst分裂和burst结合的分裂方法,先使用burst分裂混合流量,然后对burst进行聚合,聚合后的burst提取54维统计特征来表征聚合后的burst,并对其进行预测,能够学习到短流的特征。可以处理隧道内多种类型的混合流量,训练速度快,能够得到变量重要性排序。
附图说明
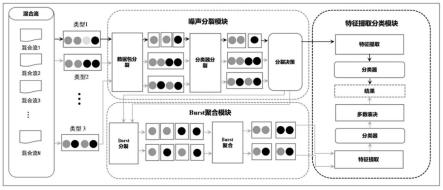
26.图1是本发明的一种基于随机森林的隧道混合流量分类系统结构图。
具体实施方式
27.为使本发明的上述特征和优点能更明显易懂,下文特举实施例,并配合所附图作详细说明如下。
28.本实施例公开一种基于随机森林的隧道混合流量分类系统,如图1所示,包含4个模块,左侧是混合流生成模块,中上部分是噪声分裂模块,中下部分是burst聚合模块,右侧是特征提取分类模块。其中噪声分裂模块包含数据包分裂子模块、分类器分裂子模块和分裂决策子模块。burst聚合模块包含burst分裂子模块和burst聚合子模块。特征提取分类模块包括2个特征提取子模块、2个分类器子模块、1个多数表决子模块。
29.利用上述各个模块可以实现一种基于随机森林的隧道混合流量分类方法,具体说
明如下:
30.1、混合流生成模块:
31.数据准备:采集当前任务场景下的网络流量数据包,利用隧道回放的方法生成隧道混合流量,在对其进行标注后,按照一定的比例划分数据集,比如训练集:测试集=7:3。训练集的作用是在训练阶段不断优化调整模型参数。测试集用于测试模型在实际网络流量中的分类性能。训练过程如下:
32.(1)利用所述训练集对噪声分裂模块进行训练,首选对其基于随机森林算法的分类器分裂子模块进行训练,调整数据包分裂部分的数据包长度阈值参数;然后对基于随机森林算法的分裂决策子模块进行训练,识别正确分裂的流量和没有分裂成功的流量。按照分裂准确率(sa)来衡量是否训练合格,当sa达到阈值(例如90%)之后则认为训练合格。
33.分裂准确率计算公式如下:
[0034][0035][0036]
其中,sa为分裂准确率,n为待预测分裂点的样本个数,pi为第i个待预测样本的预测分裂点位置,qi为第i个待预测样本的真实分裂点位置,diff为分裂函数,p为预测分裂点位置,q为真实分裂点位置,r为误差允许范围。
[0037]
(2)利用训练好的噪声分裂模块输出的结果训练burst聚合模模块,调整burst结合的参数;
[0038]
(3)利用训练好的噪声分裂模块和burst聚合模块输出结果对特征提取分类模块进行训练,训练第一分类器子模块和第二分类器子模块。
[0039]
训练噪声分裂模块和特征提取分类模块合格的标准为正确率达到一阈值,正确率计算公式如下:
[0040][0041]
其中,tp为正确预测为正样本的个数,tn为正确预测为负样本的个数,fp为错误预测为正样本的个数,fn为错误预测为负样本的个数。
[0042]
利用测试集对训练好的全部模块进行测试,对系统进行评价,测试过程如下:
[0043]
(1)输入测试集,通过分裂准确性指标评估数据包分裂子模块和分类器分裂子模块的分裂效果。
[0044]
(2)将分裂结果输入到分裂决策子模块,测试分裂决策子模块的识别结果。
[0045]
(3)分裂决策子模块识别为纯净的流量,输入特征提取分类模块的第一分类器子模块,测试结果
[0046]
(4)识别为混合的流量通过burst聚合子模块分裂后,输入特征提取分类模块的第二分类器子模块,测试结果。
[0047]
由于本系统主要基于随机森林算法,基尼指数是随机森林算法里用于进行特征选择的指标,因此使用基尼指数来选择划分属性。
[0048]
基尼值:
[0049][0050]
基尼指数:
[0051][0052]
其中,d为样本集合,dv为d中所有在属性a上取值为av的样本,pk为样本集合中第k类样本所占的比例,pk′
为为样本集合中第k’类样本所占的比例,y为样本中样本的类别总数目,v为属性a的可能取值的总数目,v为第v个取值。
[0053]
2、噪声分裂模块,其功能子模块包含三个:
[0054]
(1)数据包分裂:通过利用数据包长度对隧道混合流量进行首次分裂并将分裂结果送入(2);
[0055]
(2)分类器分裂:通过利用数据包长度和包方向的统计特征,对(1)中的首次分裂结果进行再次分裂,并将结果送入(3);
[0056]
(3)分裂决策:对(2)中的再次分裂结果进行判断,如果不是混合流量,将结果送入特征提取分类模块的(1)中,否则结果送入burst聚合模块的(1)中。
[0057]
3、burst聚合模块,其功能子模块包含两个:
[0058]
(1)burst分裂:对混合流按照数据包方向划分burst,对混合流量进行分裂并将结果送入(2);
[0059]
(2)burst聚合:对(1)中的burst进行聚合,实现对混合流量进行分裂后聚合并将结果送进特征提取分类模块的(3)中。
[0060]
4、特征提取分类模块,其功能子模块包含五个:
[0061]
(1)特征提取1:对噪声分裂模块的(3)送来的单个网络行为流量提取包长度和包方向的54维统计特征,并将结果送进(2);
[0062]
(2)分类器1:利用随机森林分类器对流量进行分类,输出最终结果。
[0063]
(3)特征提取2:对burst聚合模块的(3)送来的流量提取3个方向(客户端到服务端、服务端到客户端和双向)的统计特征并将结果送进(4);
[0064]
(4)分类器2:利用随机森林分类器对隧道流量进行分类,并将结果送进(5);
[0065]
(5)多数表决:对结果进行多数表决,输出最终结果。
[0066]
以下列举几个实例:
[0067]
实例1隧道内正时间分离应用流量分类场景
[0068]
2020年9月,主动收集7种大类30个应用流量,利用隧道回放方法回放进ipsec隧道内生成60类正时间分离的应用流量,共6k个流量样本。对其进行特征提取后进行数据集划分,划分比例为训练集:测试集=7:3。经过噪声分裂模块处理之后,本发明在测试集上获得了93%的分裂准确率。与没有经过该模块处理的相比,该模块处理后分类准确率提升了30%。
[0069]
实例2隧道内零时间分离应用流量分类场景
[0070]
2020年10月,主动收集七大类30个应用流量,利用隧道回放方法回放ipsec隧道内生成60类零时间分离应用流量,60类负时间分离应用流量。对其进行特征提取后进行数据及划分,划分比例为训练集:测试集=7:3.经过burst聚合模块处理之后,本发明在测试集达到首个应用的分类为76%的f1值和第二个应用的为56%的f1值。与最先进的方法相比,提升了25%-30%。
[0071]
实例3隧道内负时间分离应用流量分类场景
[0072]
2020年11月,主动收集七大类30个应用流量,利用隧道回放方法回放ipsec隧道内生成60类负时间分离应用流量(重叠率5%),60类负时间分离应用流量(重叠率10%)。对其进行特征提取后进行数据及划分,分别划分比例为训练集:测试集=7:3.经过burst聚合模块处理之后,本发明在5%重叠率的测试集达到首个应用的分类结果为73%的f1值和第二个应用的为47%的f1值。与最先进的方法相比,提升了20%-45%。本发明在10%重叠率的测试集上达到首个应用的72%f1值和第二个应用的27%f1值。与最先进的方法相比,提升了6%-42%。
[0073]
虽然本发明已以实施例公开如上,然其并非用以限定本发明,本领域的普通技术人员对本发明的技术方案进行的适当修改或者等同替换,均应涵盖于本发明的保护范围内,本发明的保护范围以权利要求所限定者为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。