一种基于bert模型的安全事故标签分类方法
技术领域
1.本发明属于自然语言处理领域,具体涉及对安全事故标签分类。
背景技术:
2.安全管理是一项复杂而极其重要的工作,对安全事故全面剖析和研究十分必要。安全中的事故伤害可分为事故类别、伤害方式、不安全行为和不安全状况,利用自然语言处理技术对安全事故及原因分类,为安全生产监管、事故隐患排查和分析奠定基础,对进一步强化安全管理指导具有重要意义。
3.以往文本分类通过利用稀疏词汇的特征来表示文本,再用线性模型进行分类。近年来,主要是采用深度学习得到文本的特征表示,如利用word2vec模型学习文本中词向量的表示,得到文本的语义表示实现文本分类。又如利用textrank算法把文本分割成若干组成单元,构建节点连接图,用句子之间的相似度作为边的权重,通过迭代计算句子textrank值,抽取排名高的句子组成文本摘要。
4.2018年google推出的基于转换器的双向编码表征(bidirectional encoder representationfrom transformers,bert)模型在multinli、squad、sst-2等11项自然语言处理任务中取得卓越的效果。bert模型在大规模语料库或特定领域的数据集上通过自监督学习,进行预训练以获得通用的语言表示,在下游任务中进行微调完成相应的任务。bert模型的缺点之一是使用词向量表示文本内容时,最大维度为512。当输入文本长度小于512时,模型性能良好。bert是句子级别的语言模型,该模型能获得整句的单一向量表示。bert预训练模型对输入文本进行向量化,能有效提高中文文本语义的捕捉效果。
5.安全事故报告或案例文本通常都有事故单位的情况、事故发生经过、应急处理情况、事故原因分析、事故责任认定、事故处理意见等内容,文本从几百字到数万字不等,内容长短不一,由于bert模型支持的最长序列字数为512,无法有效的进行标签分类。
技术实现要素:
6.本发明要解决的技术问题是:结合安全生产事故的文本特点,先对文本进行摘要处理,再利用bert模型进行多任务分类,实现安全生产事故分类水平的提升。
7.本发明所采用的技术方案为:一种基于bert模型的安全事故标签分类方法,包括以下步骤:
8.步骤1:输入事故案例,对文本进行预处理;
9.步骤2:使用基于bert预训练模型实现抽取式文本摘要;
10.步骤3:使用nezha预训练语言模型及pgn模型实现生成式文本摘要;
11.步骤4:通过albert训练模型,借助迁移学习的思想进行多标签多任务分类。
12.由于采用了上述技术方案,本发明的有益效果是:
13.(1)相比传统的标签分类方法,具有更好的泛化性能;
14.(2)实现了安全类中文长文本的多标签分类。
附图说明
15.图1为抽取式文本摘要模型;
16.图2生成式文本摘要模型;
17.图3多标签文本分类模型;
18.图4多标签分类准确率。
具体实施方式
19.为使本发明的目的、技术方案和优点更加清楚,下面结合实施方式和附图,对本发明作进一步地详细描述。
20.本具体实施方式中,针对提取目标为烤烟烟叶的图像的具体处理包括下述处理步骤:
21.步骤1:输入事故案例,对文本进行预处理
22.为提高处理效率,采用截断法,对原始文本首先按照头 尾截断,然后去停用词,进一步精简文本。
23.步骤2:使用基于bert预训练模型实现抽取式文本摘要
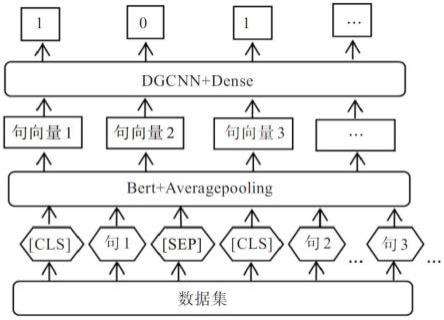
24.如图1所示,在第一个句子前面添加[cls]标识符,借助首句最前面的特殊符[cls],用来分类输入的两个句子间是否有上下文关系。每个句子的最后添加[sep]标识符,起到分割句子的作用。整个模型结构通过bert接一个average pooling层得到句子向量,即通过预训练获取一个句子的定长向量表示,将变长的句子编码成定长向量。average pooling主要对整体特征信息进行抽取,dense层将前面提取的特征,经dense层作非线性变化,再映射到输出空间。对于图1中的句子对,句子的特征值是1,则保留的摘要,句子的特征值是0,则该句舍弃,从而达到文本抽取式摘要的目的。
[0025]
步骤3:使用nezha预训练语言模型及pgn模型实现生成式文本摘要
[0026]
生成式摘要通过改进型bert来实现,模型如图2所示。bert使用的是训练出来的绝对位置编码,有长度限制,为便于处理长文本,采用基于华为的nezha预训练语言模型,利用改模型相对位置编码,通过对位置差做截断,使得待处理词、句相对位置在有限范围内,这样,输入序列的长度不再受限,处理后的语句再通过生产式指针网络(pointer generator networks,pgn)模型生产摘要。pgn模型可视为基于attention机制的seq2seq模型和pointer network的结合体,该模型既能从给定词汇表中生成新token,又能从原输入序列中拷贝旧 token,其框架如图2所示。图2中原文本中各token的wi经过单层双向lstm将依次得到编码器隐藏状态序列,各隐藏层状态表示为h
t
。对于每一个时间步长t,解码器根据上一个预测得到单词的embeding,经lstm得到解码器隐藏层状态s
t
,为了在输出中可以复制序列中的token,将根据h
t
,s
t
和和解码器输入x
t
计算生成概率:
[0027][0028]
式(1)中,b
ptr
均为模型要学习的参数。p
gen
的作用是判断生成的单词是来自于根据p
vocab
在输出序列的词典中采样,还是来自根据注意力权重a
i,t
在输入序列的 token中的采样,最终token分布表示如式(2):
[0029]
[0030]
其中i:wi=w表示输入序列中的token的w,模型会将在输入序列中多次出现的w 的注意力分布相加。当w未在输出序列词典中出现时,p
vocab
(w)=0;而w未出现在输入序列中时,
[0031][0032]
该模型基于上下文向量,解码器输入及解码器隐藏层状态来计算生成词的概率p,对应 copy词的概率为1-p,根据概率综合编码器注意力和解码器输出分布得到一个综合的基于 input和output的token分布,从而确定生成的语句。
[0033]
步骤4:通过albert训练模型,借助迁移学习的思想进行多标签多任务分类。
[0034]
将安全生产的事故案例标记为物体打击、车辆伤害等20类事故类别之一;碰撞、爆炸等15种伤害方式之一;防护、保险等装置缺乏或缺陷等4大类不安全状态之一;操作失误等13大类不安全行为之一,共有52个标签。
[0035]
本发明采用基于样本的迁移学习方法,模型如图3所示。模型主要通过自制的安全生产事故数据集对模型进行预训练,建立分类精度较高、特征提取能力强的学习模型。textcnn 模型能有效抓取文本的局部特征,经过不同的卷积核提取文本信息,再通过最大池化来突出各个卷积操作,从而提取特征信息,拼接后利用全连接层对特征信息进行组合,最后通过 binary crossentropy损失函数来训练模型,将标量数字转换到[0,1]之间,再对52个标量分组分类。设置textcnn参数字长为300,卷积核数目为256,卷积核尺寸为5,标签为52。再利用tf.argmax()对模型训练获得的52个标量,求得4组列表[0,19:1]、[20,34: 1]、[35,38:1]、[39,51:1]中最大数的索引,最后映射到相应标签即可。
[0036]
图4为本发明方法对对2 000个20种事故类别的案例集进行处理的结果图,从图中可以看出,本方法具有较高的准确率。
[0037]
以上所述,仅为本发明的具体实施方式,本说明中所公开的任一特征,除非特别叙述,均可被其他等效或者具有类似目的的替代特征加以替换;所公开的所有特征、或所有方法或过程中的步骤,除了互相排斥的特征和步骤外,均可以任何方式组合。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
