1.本发明属于信息技术领域,涉及一种多模态发音数据采集方法和系统。
背景技术:
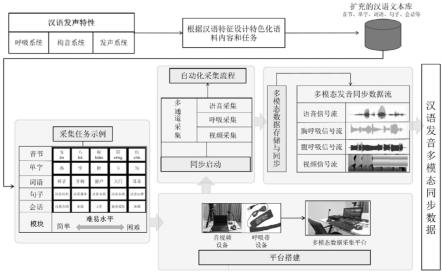
2.在汉语发音数据采集方面,相关研究十分匮乏。主要原因是大部分研究集中在语音数据的分析与识别上[1 2 3],忽略了对发音数据采集方法的更新与改进,从而导致缺少适用于正常人群和言语障碍等人群在内的可面向全体人群的专业的发音数据采集方法和系统。另外,大量研究只以语音数据为主,缺少多维度的数据采集平台和方法,虽然后期逐渐有研究开始借助多种设备,比如电磁发音仪、超声等,提取不同的言语信号特征,包括共振峰、音高(pitch)、能量(energy)、语速(speaking rate)等语音特征,发音器官的舌部、下颌、唇部等运动特征,采用深度学习、模式识别等高级算法,探究言语障碍患者等不同群体言语生成的发声机制[4 5 6]。但整体来说并没有适用于包括正常人群及言语障碍患者等在内的全体人群的发音数据采集方法与系统,且现有采集方法单调片面,不具备专业化的汉语文本、任务设计以及标准化的采集流程,进而造成“多模态发音数据采集方法与系统”这一研究空白与临床短板。
[0003]
尤其是考虑到言语障碍患者的语言症状与身体特征,其具体的发音数据采集和分析标准国内外尚未统一。一方面可能是因为患者的发音言语数据很难进行大规模采集,大部分研究的数据规模较小,各方面数据分散不全,采集内容、方法单一,缺乏标准化的多模态数据采集方法和系统[7]。国外相关研究较为成熟多样,且部分研究者已融合超声舌位[8 9]和呼吸训练[10]等多维度方法用于言语障碍患者发音数据的采集与治疗。我国缺少专门针对于汉语文化的特色化数据采集方法,且任务设计缺乏严谨性,不同研究之间数据采集与分析方法参差不齐[11 12]。另外,虽然国内外研究已结合多种设备,但目前只集中在治疗方面,极少有研究结合超声、呼吸等多维度信息,综合探索汉语发音数据采集方法的更新和改进,而这个问题又是科研和临床都急需解决的难题[13 14]。
[0004]
参考文献:
[0005]
[1].lansford kaitlin l,liss julie m.vowel acoustics in dysarthria:speech disorder diagnosis and classification.[j].journal of speech,language,and hearing research:jslhr,2014,57(1).
[0006]
[2].darley f l,aronson a e,brown j r.differential diagnostic patterns of dysarthria.[j].journal of speech and hearing research,1969,12(2).
[0007]
[3].kent r d,weismerg,kent j f,rosenbek j c.toward phonetic intelligibility testing in dysarthria.[j]. the journal of speech and hearing disorders,1989,54(4).
[0008]
[4].bruce e.murdoch,justine v.,e.ema analysis of tongue function in children with dysarthria following traumatic brain injury[j].brain injury,2003,17(1).
[0009]
[5].lee jimin,littlejohn meghan anne,simmons zachary.acoustic and tongue kinematic vowel space in speakers with and without dysarthria.[j].international journal of speech-language pathology,2017,19(2).
[0010]
[6].shawker t h,phd b c s.tongue movement during speech:a real-time ultrasound evaluation[j].journal of clinical ultrasound,2010,12(3).
[0011]
[7].rudziczf,namasivayam a k,wolff t.the torgo database of acoustic and articulatory speech from speakers with dysarthria[j].language resources and evaluation,2012,46(4):1-19.
[0012]
[8].barbara bernhardt,bryangick,penelopebacsfalvi,marcyadler&hyphen,bock.ultrasound in speech therapy with adolescents and adults[j].clinical linguistics&phonetics,2005,19(6-7).
[0013]
[9].intensive treatment with ultrasound visual feedback for speech sound errors in childhood apraxia[j].frontiers in human neuroscience,2016,10.
[0014]
[10].solomon n p,mckee a s,garcia-barry s.intensive voice treatment and respiration treatment for hypokinetic-spastic dysarthria after traumatic brain injury[j].american journal of speech language pathology,2001,10(1):51-64.
[0015]
[11].葛胜男,王勇丽,尹敏敏,万勤,钱红,黄昭鸣.脑卒中构音障碍患者元音产出特征与言语清晰度的相关性[j/ol].中国康复理论与实践:1-5[2020-11-12].
[0016]
[12].金倩倩.神经性言语障碍评估工具的开发及其应用[d].华东师范大学,2020.
[0017]
[13].preston jonathan l,bricknickole,landi nicole.ultrasound biofeedback treatment for persisting childhood apraxia of speech.[j].american journal of speech-language pathology,2013,22(4).
[0018]
[14].魏远.基于超声和mri图像融合的发音过程可视化系统[d].天津大学,2018.
[0019]
现有技术的不足之处:
[0020]
(1)现有对汉语发音的研究大部分只集中于语音数据的采集和分析,缺少其他维度信息的采集,因此数据单一、不全面;
[0021]
(2)在汉语发音文本材料方面,多数研究只关注元音和辅音的发声特性,没有去深入探究汉语其他方面,例如音节、词语、句子等内容的言语特征,文本材料设计比较片面。
[0022]
(3)在数据采集任务及流程方面,很多研究的数据采集设备、方法和模式参差不齐,不同研究之间具有极大差异性,因此容易造成数据不规范,研究的信度和效度低下;
[0023]
(4)多模态数据同步方面,现有技术只是在数据分析后期将语音或者发音运动数据进行强制算法同步,容易造成数据失真等各种问题,而没有致力于在数据采集初期就将多模态数据进行同步,以获得全面完整的高质量多维度原始数据信息。
[0024]
(5)在后期数据分析方面,暂时没有发现可以将发音时的语音、视频和呼吸数据进行精准同步的相关方法,缺少多模态发音数据的深入分析与挖掘。
技术实现要素:
[0025]
针对现有技术的不足,本发明的目的在于提供一种多模态发音数据采集方法和系统,同步整合汉语发音过程中多维度信息,提供适用于全体人群的多模态发音数据采集方法和系统。
[0026]
为实现上述目的,本发明所采用的技术方案是:
[0027]
一种多模态发音数据采集方法,包括以下步骤:
[0028]
步骤1)、建立汉语发声文本材料及任务,根据不同群体的语言症状及汉语发音特征设计包括音节、单字、词语、句子和会话内容的发声文本采集材料及任务;
[0029]
步骤2)、采集多维度信息,被采集人员根据发声文本采集材料发音时采用音频采集设备、视频采集设备和呼吸带设备同步采集人员的语音、视频和呼吸数据;
[0030]
步骤3)、多维度信息采集结果的同步处理,数据采集结束后进行自动存储命名,通过两个线程的语音数据为导向实现呼吸信号与音视频数据的精准同步;
[0031]
步骤4)、发音特征提取及分析,对同步后的多维度信息进行声学、运动、图像特征参数的提取,对不同群体的发声特性和言语症状进行深入计算和分析,得到采集人员到发音数据。
[0032]
优选的,所述步骤1)建立汉语发声文本材料及任务时,将音节、单字、词语、句子和会话设置为不同任务模块,每个任务模块设置具有不同难易程度的等级,不同群体根据实际语言症状特征和身体状态能够选择不同的任务模块组合及不同难易程度,不同群体还能够根据身体状态及语言症状调整每个任务模块的发音时间和休息时间。
[0033]
优选的,所述音节模块包括元音、辅音、高频音节、低频音节和易混音节内容,呈现方式为汉字加音节,根据不同群体的身体状态能够调节每个音节的呈现时间和发音时间,发音后自动切换到下一个音节。
[0034]
优选的,所述步骤3)呼吸信号与音视频数据的同步过程为:
[0035]
(3.1)音频与视频同步启动采集:采用音频和视频两个线程进行录制,在采集任务开始时,同步开启两个线程,只有在两个线程都开启时,开始数据的写入;
[0036]
(3.2)呼吸带与音视频同步启动采集:呼吸带采集设备同步多通道采集语音、胸腹呼吸信号,在确定音视频数据同步启动录入的同时,保证呼吸带采集设备的同步启动,实现呼吸信号和音视频信号在采集阶段的同步写入与录制。
[0037]
优选的,所述步骤2)采集多维度信息,数据采集得到的原始数据集包括 3个目录:视频数据avi、语音数据wav、呼吸数据wav,每位参与者的每份数据一一对应,自动匹配命名。
[0038]
优选的,所述步骤2)采集多维度信息时设置有自动化采集流程。
[0039]
一种多模态发音数据采集系统,包括:
[0040]
汉语发声文本材料及任务建立模块,用于根据不同群体的语言症状及汉语发音特征设计包括音节、单字、词语、句子和会话内容的发声文本采集材料及任务;
[0041]
多维度信息采集模块,用于采集被采集人员根据发声文本采集材料发音时的语音、视频和呼吸数据;
[0042]
多维度信息采集结果同步处理模块,用于实现采集的语音、视频和呼吸数据的精准同步;
[0043]
发音特征提取及分析模块,用于对同步后的多维度信息进行声学、运动、图像特征参数的提取,对不同群体的发声特性和言语症状进行深入计算和分析,得到采集人员到发音数据。
[0044]
优选的,所述多维度信息采集模块采用包括呼吸设备、语音设备、视频设备的多模态数据采集平台。
[0045]
优选的,所述呼吸设备为呼吸带设备、语音设备为麦克风、视频设备为摄像头。
[0046]
本发明具有以下优点:
[0047]
根据汉语言语过程中的呼吸系统、发声系统和构音系统的发音特性,设计标准化的汉语特色文本材料和采集任务,通过融合呼吸、语音、视频等多种设备,开发多设备多通道之间的数据同步采集方法,搭建可面向正常人群及言语障碍等特殊人群的多模态发音数据同步采集平台,扩充语料内容,结合音节、单字、词语、句子和会话等全面的汉语特色化材料,同时标准化同步采集方法和步骤,规范化数据存储与分析,同步整合汉语发音过程中的呼吸系统、发声系统和构音系统的多维度信息,建立一种专业化的适用于全体人群的多模态发音数据采集方法和系统。
[0048]
本发明还具有以下特点:
[0049]
(1)针对汉语的发音特性设计特色化文本材料和任务:根据汉语发音特点,设计特色化文本材料,不仅适用于汉语全体人群,而且综合言语障碍患者等特殊群体的身体状态及言语症状,可提供不同难度等级的语料内容,多样化、专业化的采集任务以及个体化的采集方法。
[0050]
(2)多设备多通道采集平台的搭建:利用多模态采集设备,包括呼吸带、语音和视频等,全方位同步采集发音时呼吸、语音和视频信息,建立完善的汉语发音的多维度采集平台。
[0051]
(3)多模态同步启动采集方法:设置多通道数据采集时的多线程同步启动方法,在呼吸、音视频等设备同步开启后,多线程同步进行数据的采集,以此实现多通道信息在采集阶段的同步。
[0052]
(4)自动化采集流程:设置简易明了的标准化采集步骤,为不同群体提供多模态自动化采集流程,减少参与难度及设备操作压力。
[0053]
(5)数据采集结果及后期同步处理:在获取呼吸、语音和视频等多模态数据流后,自动规范存储和保存,并对多维度信号进行精准同步和分析。
[0054]
本发明帮助解决不同群体的发音数据采集困难的科研瓶颈,并辅助缓解言语障碍患者等特殊群体的临床评估、医疗成本和诊疗压力过大的严峻现状。
附图说明
[0055]
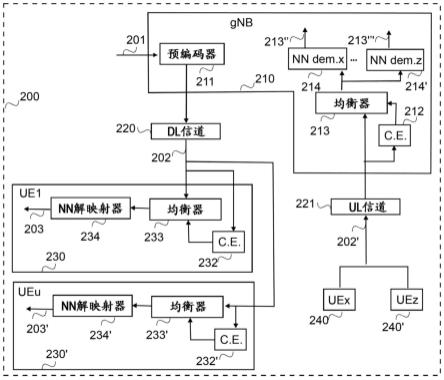
图1多模态发音数据采集方法和系统框架图
[0056]
图2汉语发音文本材料示例图
[0057]
图3汉语发音采集任务示例图
[0058]
图4多模态数据采集平台
[0059]
图5音视频和呼吸带同步启动录制方法
[0060]
图6自动化采集流程
[0061]
图7多模态数据同步处理方法
具体实施方式
[0062]
下面结合具体实施例对本发明作进一步详细描述,但不作为对本发明的限定。
[0063]
如图1所示,本发明的多模态发音数据采集方法:
[0064]
首先基于不同群体的汉语发声特征,分别设计合理的、契合其语言症状的专业采集材料及任务;
[0065]
然后根据发声系统、构音系统和呼吸系统的汉语发音过程,搭建包括呼吸设备、语音设备、视频设备等在内的多模态数据采集平台;
[0066]
接着,根据设备间的多线程同步启动信号,实现跨设备的多通道数据同步采集;
[0067]
之后,标准化采集步骤,为包括患者在内的不同群体提供易于理解和操作的自动化采集流程;
[0068]
最后,自动化写入存储多模态数据流,精准同步并提取多维度数据的声学、运动、图像等特征参数,对不同群体的发声特性和言语症状进行深入计算和分析。
[0069]
以下结合附图对各部分内容进行详细说明:
[0070]
如图2所示,构建结合汉语发音特性的汉语特色化文本材料和任务
[0071]
以往汉语发音数据采集大部分只集中于元音、辅音的发音数据分析,缺少全面性的汉语文本设计和系统性的采集任务,因此,本发明首先根据汉语发音特点和发声重建与言语障碍等不同人群特点来设计并补充了语料文本,不仅适用于正常人群,而且综合考虑了言语障碍患者等特殊群体的发音错误及特性,全面覆盖汉语的每个方面,共设计了包括音节、单字、词语、句子和会话等在内的不同任务模块,每个模块具有不同等级的难易水平。不同群体可根据实际语言症状特征和身体状态选择不同的模块组合及难易水平。
[0072]
语料文本分为不同的模块,包括音节、单字、词语、句子和会话等,基本覆盖汉语的每个方面,参与者观看文本材料根据要求发音。每个模块根据难易水平等分成几个部分进行采集,可根据参与者的身体状态及语言症状灵活调整发音时间和休息时间,并且可以自由选择不同的模块或者模块组合进行采集,也可灵活选择不同难易水平的文本材料。
[0073]
以音节模块为例进行介绍:音节模块包括元音、辅音、高频音节、低频音节和易混音节等内容,呈现方式为汉字加音节,根据不同群体的身体状态可调节每个音节的呈现时间和发音时间,发音后自动切换到下一个音节,可视实际情况控制连续发音的音节数量和调整设备时间。参与者位于电脑屏幕正前方,注视屏幕中间的文本材料按要求进行发音,在采集过程中如遇任何问题或紧急情况可随时停止采集。
[0074]
汉语发音采集任务具体流程如图3所示,鉴于正常人群、言语障碍患者等不同群体的语言症状及身体状态更新了一套更加简便专业的采集任务,可以根据实际情况合理安排采集时间、休息时间并灵活调控任务难度。
[0075]
如图4所示,多设备多通道采集平台的搭建
[0076]
为全面描述言语产生过程中各器官运动模式,本发明针对不同器官和系统,使用包括语音、视频和呼吸带等多种方法、多种设备采集多种通道的言语运动数据,搭建了一个可多通道采集的标准化汉语发音采集平台。传统采集方法中,只有音视频的同步采集,在本采集平台中加入了呼吸带设备,可以更加全面的了解发音过程中的生理特征和声学表现等
多维度信息,具体设备信息如下:
[0077]
(1)音频采集设备:
[0078]
戴尔笔记本电脑:显示指示语以及需要发音的文本材料;
[0079]
takstar ms400麦克风:采样率44.1khz,单声道,16bit,与嘴唇距离大约8-15cm,用于录入音频数据。
[0080]
(2)视频采集设备:
[0081]
罗技c1000e摄像头:1920
×
1080像素,60f/s帧速录入视频数据,放置于人的正前方(2-3米以内);
[0082]
闪光灯:保证视频光线充足,防止因光线不足产生聚焦问题。
[0083]
(3)呼吸带设备(以mlt1132呼吸带为例进行介绍):
[0084]
mlt1132呼吸带传感器与和powerlab十六通道采集器
[0085]
chart软件采集多通道信号(语音、胸部呼吸信号、腹部呼吸信号)。
[0086]
如图5所示,编写多模态数据采集同步启动方法
[0087]
本发明涉及音视频同步和呼吸带信号的同步启动录制方法:
[0088]
(1)音频与视频同步启动采集:采用音频和视频两个线程进行录制,在采集任务开始时,同步开启两个线程,只有在两个线程都开启时,才开始数据的写入;
[0089]
(2)呼吸带与音视频同步启动采集:呼吸带chart软件可同步多通道采集语音、胸腹呼吸等信号,在确定音视频数据同步启动录入的同时,保证呼吸带采集设备的同步启动,以初步实现呼吸信号和音视频信号在采集阶段的同步写入与录制;
[0090]
以音视频同步启动为例进行详细解释:首先多线程启动摄像头和麦克风设备,当摄像头启动完成后判断麦克风是否启动完成,如果麦克风启动未完成,则继续等待至麦克风启动是否完成;同理,当麦克风启动完成后判断摄像头是否启动完成,如果摄像头启动未完成则等待摄像头启动完成。当且仅当两种设备同时启动完成后,程序后台才同时读取两个设备中所采集到的数据,并分别向内存中写入数据。设置此环节的目的在于避免由于设备的启动时间不一致而导致的音视频不同步,确保两者同时开始录制。当录制结束后,以音频为基准计算录制总时间,并以该时间乘以视频帧率获得视频理论总帧数,然后计算录制视频的实际帧数,通过对比两者的差值,从而确定视频和音频的总长度一致,因此对音视频是否同步进行总体判断。如果音视频总帧数差值在可接受范围内,则以wav格式写入音频文件,以avi格式写入视频文件并保存,注意此时视频文件为不包含声音的视频。最后执行音视频合成操作,把音频和视频进行合并,最终以avi格式保存。
[0091]
因此,在数据采集过程中,音频、视频及呼吸数据同时被相应的设备录入并存储。
[0092]
如图6所示,设置自动化采集流程
[0093]
在被采集者的角度,鉴于正常人群及言语障碍患者等特殊群体的数据采集困难程度及身体状态的限制,专门设置了简易明了的标准化采集步骤和自动化采集流程,本套数据采集方法只需参与者舒适放松的坐在电脑屏幕前,注视电脑屏幕中的文本材料进行发音即可,采集时间和休息时间都可以灵活调节,因此可以大大减少患者的参与难度及疲劳状态。
[0094]
在设备操作方面,本套设备设置了简单明了且极少的操作步骤,操作员只需在采集前确定设备准备就绪,并控制开始采集与结束采集的电脑按键来控制采集时间与休息时
间,因此可以大大缓解采集员或临床医生的操作压力,解放临床人力和时间成本。
[0095]
如图7所示,多模态数据采集结果及同步处理
[0096]
数据采集结束后,自动存储命名,并对多模态数据流进行后期高级处理,通过两个线程的语音数据为导向来实现胸腹式呼吸信号与音视频数据的精准同步。数据采集得到的原始数据集包括3个目录:视频数据(avi)、语音数据(wav)、呼吸数据(wav),每位参与者的每份数据一一对应,自动匹配命名,方便后期多通道数据流的自动化分析与同步。
[0097]
(1)音频数据:在麦克风启动后开始采集写入音频信号,在麦克风关闭后自动存储音频数据(wav),统一命名规则,例如以参与者基本信息及任务信息等内容进行命名。
[0098]
(2)视频数据:在摄像头启动后开始采集写入视频信号,在摄像头关闭后自动存储视频数据(avi),命名规则同音频数据进行统一规范的自动命名,且与音频数据文件一一对应。
[0099]
(3)呼吸数据:将chart软件采集到的多通道信号保存成*.adcht格式,利用转换程序将录制的txt文件转换成多通道的wav文件,同音视频数据统一命名规则,并与音视频数据一一对应。
[0100]
因此,在数据采集结束后,音频、视频及呼吸数据同时被相应的设备录入并存储,并对多模态数据流进行同步处理,呼吸带chart软件可同步多通道采集语音、胸腹呼吸等信号,可通过两个线程的语音数据为导向来实现胸腹式呼吸信号与音视频数据的精准同步。
[0101]
本发明具有以下优点:
[0102]
(1)现有的汉语发音数据采集只集中在语音方面,缺少其他维度的发音信息的采集与分析,本发明首次结合了语音、视频和呼吸带设备,补充了多维度信息;
[0103]
(2)现有的汉语发音数据采集内容只关注元音、辅音,与其相比,本发明补充了音节、单字、词语、句子等不同内容,可全面深入探究汉语发音特性;
[0104]
(3)现有数据采集任务及方法参差不齐,不同研究之间差异较大,与此相比,本发明根据不同群体特性设计了专业化的采集任务,并设置了难易水平等多样化的选择;
[0105]
(4)现有的汉语发音相关研究的数据分析只是在数据分析后期将语音或者发音运动数据进行强制算法同步,与此相比,本发明致力于在数据采集初期就将多模态数据进行同步启动采集,开发语音、视频和呼吸带同步启动采集方法,以获得全面完整的高质量多维度原始数据信息。
[0106]
(5)现有的汉语发音数据采集缺少标准化的步骤及流程,与此相比,本研究能够切实考虑言语障碍等不同群体是真实状况,设置了简便易上手的专业化数据采集流程及规范;
[0107]
(6)暂时没有语音、视频和呼吸信号的多模态数据精确同步方法,本发明可通过比较两个线程音频信号的帧数及时间信息,寻找关键帧,以两个语音数据流的对齐实现多模态数据流的同步。
[0108]
参照上述实施例对本发明进行了详细说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本权利要求范围当中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。