1.本发明涉及图像检索方法领域,特别是基于无监督哈希的遥感图像检索方法。
背景技术:
2.近年来,遥感观测技术发展迅速,在全球范围内收获了大量未经处理的遥感图像。因此,如何在大规模的遥感影像数据库中准确、高效地检索出所需的影像,成为一个越来越值得关注的方向。尽管基于内容的图像检索(cbir)方法在医学图像、传统图像和视频图像领域取得了良好的研究进展,但关于基于内容的遥感图像检索(cbrsir)的技术较少。
3.基于哈希的近似最近邻搜索方法因其高查询效率和低存储成本而被广泛关注。图像检索中的哈希算法是将遥感图像的有用特征表示为一系列的二进制哈希代码,从而来降低搜索成本,本专利同样从该角度来实现无监督训练下的遥感图像检索应用。
4.在自然图像检索领域,deng等人(2019)根据图像特征的余弦距离,通过进行k-近邻搜索获得初始相似度矩阵;这种对语义相似度矩阵的监测被整合到一个对抗性学习框架中,来保留语义信息。tu等人(2020)采用局部流形结构建立了局部类型的相似性结构,并使用对数损失函数优化了网络。在遥感图像检索方面,li等人(2016)提出了一个协同亲和力合并来衡量遥感图像之间的相似度。zhang等人(2020)通过结合具有高置信度和正常置信度的图像对构建了一个混合相似性矩阵。sun等人(2021)提出了软伪标签来学习图像对的相似性。
5.现有技术一
6.大多数现有的无监督哈希算法只生成初始语义相似性矩阵作为伪标签。然而,在自然图像数据集上预训练的网络模型不能很好地生成遥感图像的特征表示。
7.现有技术二
8.xiong等人(2019)采用中心损失函数,通过类内压缩和类间分散来学习遥感图像的特征。cao等人(2020)提出了一个基于triplet loss的深度测量学习cnn模型,用于遥感图像检索。roy等人(2018)结合triplet损失、表示惩罚和平衡损失来挖掘包含语义信息的度量空间.然而,由于triplet损失存在局部优化的问题,用softmax函数代替铰链函数的全局最优结构损失,有效地解决了triplet损失的问题。为了应对标准cnn模型在部分遥感图像检索中的性能不足,引入了图神经网络来优化对比度损失,并用于更好地获取图像区域内的局部相互作用(chaudhuri等人,2019)。liu等人(2020)提出了一种新的结果排序损失,以控制损失减少方向与优化方向一致,实现端到端的哈希学习优化。大多数损失函数都对样本对使用相同的权重。其目的是为了扩大非相似样本之间的距离,同时拉近相似样本之间的距离。
9.现有技术二的缺点
10.每种类型的两个样本图像对都有各自的困难样本,如果在训练过程中,困难样本对被错误地确定(例如,靠近假的正样本对或远离假的负样本对),都会放大哈希学习误差。同时,许多方法的损失函数忽略了训练过程中数据的不平衡问题。在训练过程中的每一批
输入图像中,相似图像对的数量只占总数的一小部分,导致在训练过程中对负样本的过度关注,造成负样本的过度拟合。
技术实现要素:
11.为解决现有技术中存在的问题,本发明提供了基于无监督加权哈希的遥感图像检索方法;解决了现有模型无法在训练过程中优化伪标签、不同困难等级的训练样本对赋予相同权重的问题。
12.本发明的技术方案如下:
13.基于无监督加权哈希的遥感图像检索方法,包括以下步骤:
14.步骤s1:采用在imagenet-1k上预训练的swin transformer模型对遥感图像集进行特征提取,对提取的深度特征进行双层k-nn计算,按照图像间的余弦距离进行排序,选取前k1个作为相似图像;
15.步骤s2:按照两幅图像的相同近邻对象的数量进行排序,选择前k2个作为相似图像;
16.步骤s3:结合上述两组条件,生成后续无监督训练所需的初始相似矩阵;
17.步骤s4:当模型开始训练后,每一轮训练都会对模型参数进行微调,借此可以提取到更有效的深度特征表示,并生成新的相似矩阵;
18.步骤s5:矩阵的生成使用了图像对之间的相似度,没有考虑两幅图像的相邻图像信息,而相邻图像的信息也有利于描述两幅图像之间的相似关系;
19.步骤s6:通过结合加权相似性结构和初始相似性矩阵,进一步对新生成的相似性矩阵进行更新;
20.步骤s7:采用相似阈值对新矩阵中的相似对进行更新,阈值采用初始相似矩阵中所有相似图像对的加权相似度的均值;
21.步骤s8:在训练过程中,通过由自适应权重相似损失和量化损失组合的新损失函数,能够为多个不同困难程度的正负例样本对自动调节权重,以有效利用图像间的判别信息,来整体优化哈希网络以提高性能;
22.步骤s9:在两个广泛采用的公共遥感图像数据集上进行了实验。
23.优选地,步骤s6中加权相似矩阵是通过不同图像的相邻图像关系构成的。
24.优选地,步骤s8的自适应权重相似损失根据每一个图像对的困难程度为其分配不同权重。
25.优选地,步骤s9在eurosat数据集上,与spl-udh算法相比,duwh方法在16位、24位、32位和48位时分别实现了3.4%、2.4%、2.4%和4.3%的增量;在patternnet数据集上,duwh方法在48位也实现了3.3%的增量;
26.本发明基于无监督加权哈希的遥感图像检索方法的有益效果如下:
27.1.针对现有模型无法在训练过程中优化伪标签的缺陷,本发明提出基于加权相似结构的相似矩阵更新模块,该模块将使用遥感图像的加权相似结构计算更新阈值,结合初始相似矩阵和微调后生成的新相似矩阵,实现无监督训练过程中模型和伪标签的相互优化。因此很好地解决了现有模型存在的缺陷。
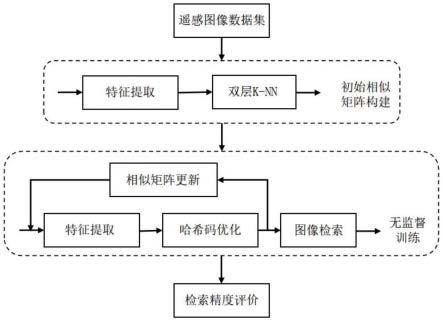
28.2.针对不同困难等级的训练样本对赋予相同权重的缺陷,本发明提出一种新的损
失函数。它可以针对不同难度的多个正负样本对自动调整权重,从而有效地利用更完整的相似语义结构信息,产生更加准确的哈希码来完成图像检索。
附图说明
29.图1为本发明深度无监督加权哈希框架图。
30.图2为本发明的流程图。
31.图3为本发明的eurosat数据集上top-k近邻域检索准确率曲线图。
32.图4为本发明的patternnet数据集上top-k近邻域检索准确率曲线图。
具体实施方式
33.下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
34.本专利通过现有的深度学习框架pytorch以及对应的编程库实现,主要包括numpy、pil、scipy。其中pytorch主要使用预训练的深度学习模型。
35.具体方案实现原理如下,其流程图如图2所示:
36.如图1所示首先,采用在imagenet-1k上预训练的swin transformer模型对遥感图像集进行特征提取,对提取的深度特征进行双层k-nn计算,按照图像间的余弦距离进行排序,选取前k1个作为相似图像。
37.按照两幅图像的相同近邻对象的数量进行排序,选择前k2个作为相似图像。
38.结合上述两组条件,生成后续无监督训练所需的初始相似矩阵。
39.当模型开始训练后,每一轮训练都会对模型参数进行微调,借此可以提取到更有效的深度特征表示,并生成新的相似矩阵。
40.然而矩阵的生成使用了图像对之间的相似度,没有考虑两幅图像的相邻图像信息,而相邻图像的信息也有利于描述两幅图像之间的相似关系。
41.通过结合加权相似性结构和初始相似性矩阵,进一步对新生成的相似性矩阵进行更新。
42.其中,图像的相似性是通过测量成对余弦相似度来表示的。
43.余弦相似性通过测量两个向量的内积空间的角度来衡量两个向量之间的相似性。
44.采用相似阈值对新矩阵中的相似对进行更新,阈值采用初始相似矩阵中所有相似图像对的加权相似度的均值。
45.同时,在训练过程中,通过由自适应权重相似损失和量化损失组合的新损失函数,能够为多个不同困难程度的正负例样本对自动调节权重,以有效利用图像间的判别信息,来整体优化哈希网络以提高性能。
46.最后,本专利在两个广泛采用的公共遥感图像数据集上进行了实验。
47.实验证明提出的duwh全面优于最先进的方法。
48.在eurosat数据集上,与spl-udh算法相比,duwh方法在16位、24位、32位和48位时分别实现了3.4%、2.4%、2.4%和4.3%的增量。
49.在patternnet数据集上,duwh方法在48位也实现了3.3%的增量。
50.eurosat数据集收集了27000张遥感图像,包括了遥感图像中的10中场景类别,每一种场景包含2000到3000张图像,每张图像尺寸大小为64
×
64;patternnet数据集包含38个不同类别,每类800张,每张图像的分辨率为256
×
256,共计30400张。
51.各数据集的top-k近邻域检索准确率曲线如下图3和图4所示。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
