1.本揭露涉及一种文件语句概念标注系统及其训练方法与标注方法。
背景技术:
2.文件结构分析是深层文件理解和资讯抽取的重要技术,目的是由字词及专名(named entity)的层级更扩张为多语句等更大范围语境的层级,其应用非常广泛,包括将文件内容切割为更小单元的文件片段区块,并给予不同区块对应的类别标注,例如将许多效能竞赛测试标准是将生医领域科技论文摘要中的语句自动分析切割标注为背景、目的、方法、结论、贡献等不同的语句概念组合。
3.非结构化文件内容经过文件结构分析标注之后,除了可以得到多个语句组的语意类别(即语句概念)标注之外,更能够做为更上层应用分析的特征资讯。然而,在实务运用时除了正确率的提升之外,对文件结构的变异,亦需要足够的容忍度。
技术实现要素:
4.本揭露公开了一种文件语句概念标注系统及其训练方法与标注方法。
5.根据本揭露的一实施例,提供一种文件语句概念标注系统的训练方法。文件语句概念标注系统的训练方法包括以下步骤。提供数份已标注文件。各个已标注文件已标注一或多个语句概念的一或多个语句集。产生各个语句集于这些已标注文件的起始位置及结束位置。对这些已标注文件调整这一或多个语句集的顺序,并更新各个起始位置及各个结束位置,以获得数份生成文件。各个生成文件已标注这一或多个语句集。将这些生成文件输入预训练语言模型,以获得各个生成文件的词向量集合。将这些生成文件的词向量集合、各个起始位置及各个结束位置输入至文件分析模型,以对文件分析模型进行训练。文件分析模型用于对未标注文件进行这一或多个语句概念的标注。
6.根据本揭露的另一实施例,提出一种文件语句概念标注系统的标注方法。文件语句概念标注系统的标注方法包括以下步骤。输入未标注文件及一或多个语句概念至预训练语言模型,以获得未标注文件的词向量集合。将未标注文件的词向量集合输入至文件分析模型,以获得各个语句概念的语句集于未标注文件的起始位置及结束位置。依据各个起始位置及各个结束位置,获得各个语句集。
7.根据本揭露的再一实施例,提出一种文件语句概念标注系统。文件语句概念标注系统包括位置产生单元、增强资料产生单元、预训练语言模型及文件分析模型。位置产生单元用于接收数份已标注文件。各个已标注文件已标注一或多个语句概念之一或多个语句集。位置产生单元产生各个语句集于各个已标注文件的起始位置及结束位置。增强资料产生单元用于对这些已标注文件调整这一或多个语句集的顺序,并更新各个起始位置及各个结束位置,以获得数份生成文件。各个生成文件已标注这一或多个语句集。预训练语言模型用于依据这些生成文件获得各个生成文件的词向量集合。文件分析模型接收这些生成文件的词向量集合、各个起始位置及各个结束位置,以进行训练。文件分析模型用于对未标注文
件进行各个语句概念的标注。
8.为了对本揭露的上述及其他方面有更佳的了解,下文特举实施例,并配合所附附图详细说明如下:
附图说明
9.图1为根据一实施例对未标注文件进行文件语句概念标注的示意图;
10.图2a~图2e为根据一实施例的文件语句概念标注系统的执行标注方式;
11.图3为根据一实施例的文件语句概念标注系统的方块图;
12.图4为根据一实施例的文件语句概念标注系统之标注方法的流程图;
13.图5为根据一实施例的文件语句概念标注系统之训练方法的流程图;
14.图6为根据一实施例采用文件语句概念标注系统进行关系抽取的示意图;
15.图7为根据一实施例采用文件语句概念标注系统进行文件搜索的示意图;
16.图中:
17.100:文件语句概念标注系统;
18.110:预训练语言模型;
19.120:文件分析模型;
20.121:起始估测单元;
21.122:结束估测单元;
22.130:语句集选取单元;
23.140:位置产生单元;
24.150:增强资料产生单元;
25.200:关系抽取系统;
26.210:断句单元;
27.220:命名实体识别单元;
28.230:实体关系抽取单元;
29.300:文件搜索系统;
30.310:索引单元;
31.320:搜索条件处理单元;
32.330:排序单元;
33.340:搜索结果呈现单元;
34.cl1,cl2,cl3,cl4,cl5,cli,clj:语句概念;
35.dc0:已标注文件;
36.dc0’:生成文件;
37.dc1,dc2,dc3:未标注文件;
38.e01,
…
,e05,e01’,
…
,e05’,e12,e13,e14:结束位置;
39.nei:实体;
40.q:查询条件;
41.s01,
…
,s05,s01’,
…
,s05’,s12,s13,s14:起始位置;
42.s410,s420,s430,s510,s520,s530,s540,s550:步骤;
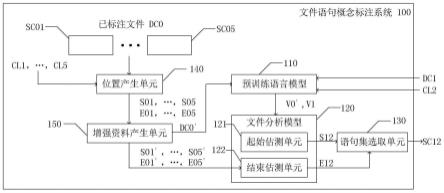
43.sc01,
…
,cs05,sc12,sc13,sc14,sci,scj:语句集;
44.si:语句;
45.v0’,v1:词向量集合。
具体实施方式
46.为使本揭露的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本揭露作进一步的详细说明。
47.请参照图1、图2a~图2e,图1为根据一实施例对未标注文件dc1进行文件语句概念标注的示意图,图2a~图2e为根据一实施例的文件语句概念标注系统100的执行标注方式。举例来说,对于未标注文件dc1,文件语句概念标注系统100可以针对「背景」的语句概念cl1(如图2a所示)、「目的」的语句概念cl2(如图2b所示)、「方法」的语句概念cl3(如2c所示)、「结论」的语句概念cl4(如图2d所示)、「贡献」的语句概念cl5(如图2e所示)等,进行文件结构分析。
48.如图1和图2a所示,未标注文件dc1与「背景」的语句概念cl1输入至文件语句概念标注系统100后,文件语句概念标注系统100没有发现任何关于「背景」的语句概念cl1,故无法标出「背景」的语句集。
49.接着,如图1和图2b所示,未标注文件dc1与「目的」的语句概念cl2输入至文件语句概念标注系统100后,文件语句概念标注系统100可以标注出「目的」的语句集sc12,即标注出语句集sc12于未标注文件dc1之一起始位置(start token)s12及一结束位置(end token)e12。
50.然后,如图1和图2c所示,未标注文件dc1与「方法」的语句概念cl3输入至文件语句概念标注系统100后,文件语句概念标注系统100可以标注出「方法」的语句集sc13,即标注出语句集sc13于未标注文件dc1的一起始位置s13及一结束位置e13。
51.接着,如图1和图2d所示,未标注文件dc1与「结论」的语句概念cl4输入至文件语句概念标注系统100后,文件语句概念标注系统100可以标注出「结论」的语句集sc14,即标注出语句集sc14于未标注文件dc1的一起始位置s14及一结束位置e14。
52.然后,如图1和图2e所示,未标注文件dc1与「贡献」之的语句概念cl5输入至文件语句概念标注系统100后,文件语句概念标注系统100没有发现任何关于「贡献」的语句概念cl5,故无法标出「贡献」的语句集。
53.在本实施例中,文件语句概念标注系统100所分析出的语句集sc12、sc13、sc14可以包含一个以上句子。并且,输入至文件语句概念标注系统100的内容不是单一句子,而是未标注文件dc1的全文。此外,文件语句概念标注系统100并非针对个别句子进行语句概念的分类,而是从整份未标注文件dc1中寻找出语句集sc12、sc13、sc14的起始位置s12、s13、s14与结束位置e12、e13、e14。
54.请参照图3,其绘示根据一实施例的文件语句概念标注系统100的方块图。文件语句概念标注系统100包括一预训练语言模型110、一文件分析模型120、一语句集选取单元130、一位置产生单元140及一增强资料产生单元150。预训练语言模型110、文件分析模型120、语句集选取单元130、位置产生单元140及增强资料产生单元150例如是一电路、一晶片、一电路板或储存程式码的储存装置。
55.文件语句概念标注系统100可以利用预训练语言模型110、文件分析模型120及语句集选取单元130对未标注文件dc1标注出语句概念cl2的语句集sc12(语句集sc13、sc14亦同)。在标注过程中,一次只针对一个语句概念进行标注,为清楚说明此点,图3仅以语句概念cl2的语句集sc12为例进行说明)。以下搭配一流程图详细说明上述元件在标注方法的运作方式。
56.请参照图3和图4,图4绘示根据一实施例的文件语句概念标注系统100的标注方法的流程图。在步骤s410中,输入未标注文件dc1及一或多个语句概念(例如是语句概念cl2)至预训练语言模型110,以获得未标注文件dc1的词向量集合v1。预训练语言模型110例如是bert模型、albert模型、xlnet模型、roberta模型、deberta模型、或以上模型之压缩或删减或简化型式。bert的全名为bidirectional encoder representations from transformers。预训练语言模型110可以从文本数据中提取高质量的语言特征。
57.以bert模型为例,一般对于bert模型的输入是一个句子,该句以[cls]和[sep]做为开始与结尾的特别标注,例如是[cls]sentence1[sep]或[cls]sentence1[sep]sentence2[sep]
…
[sep]。其中sentence1、sentence2分别是一个句子。
[0058]
在本实施例中,对于bert模型的输入则是未标注文件dc1的全文及语句概念cl2(语句概念cl3、cl4亦同。在标注过程中,一次只针对一个语句概念进行标注,为清楚说明此点,在此仅以语句概念cl2为例进行说明)。对于bert模型的输入例如是[cls]label[sep]text[sep]。其中label为语句概念cl1、cl2、
…
、cl5其中之一,text为未标注文件dc1的全文。
[0059]
接着,在步骤s420中,将未标注文件dc1的词向量集合v1输入至文件分析模型120,以获得各个语句概念(例如是语句概念cl2)之一或多个语句集(例如是语句集sc12)于未标注文件dc1的起始位置(例如是起始位置s12)及结束位置(例如是结束位置e12)。文件分析模型120包括一起始估测单元121及一结束估测单元122。起始估测单元121用估测出起始位置s12;结束估测单元122用于估测出结束位置e12。在此步骤中,文件分析模型120包含一致密层(dense layer)及一归一化指数函式(softmax)层。词向量集合v1输入至致密层及归一化指数函式层后产生起始位置分布机率及结束位置分布机率,并据以得到起始位置s12及结束位置e12。
[0060]
在本实施例中,文件分析模型120所接收的是未标注文件dc1的全文所产生的词向量集合v1。
[0061]
然后,在步骤s430中,语句集选取单元130依据各个起始位置(例如是起始位置s12)及各个结束位置(例如是结束位置e12)获得各个语句概念(例如是语句概念cl2)的各个语句集(例如是语句集sc12)。
[0062]
在本实施例中,文件语句概念标注系统100的标注方法是基于未标注文件dc1的全文进行分析,推测一个语句概念所包含的语句集范围而非单一语句的分类,故分析过程可以从所有语句中辨识出最符合语句概念cl2的语句集sc12。因此,文件语句概念标注系统100的标注准确率可以大幅提高。
[0063]
举例来说,请参照下表一,相较于hsln-cnn、hslin-rnn、ai2等标注方法,本揭露的标注方法在三种未标注文件都可以达到最高的准确率。
[0064]
表一
[0065][0066]
上述实施例是以语句概念cl2为例作说明。其余的语句概念cl1、cl3、cl4、cl5亦可按照上述步骤进行标注。
[0067]
以上所述为文件语句概念标注系统100的标注方法。在执行标注方法之前,文件语句概念标注系统100必须透过适当的训练。请参照第3图,文件语句概念标注系统100可以利用位置产生单元140及增强资料产生单元150及预训练语言模型110的协助,来对文件分析模型120进行训练。以下搭配一流程图详细说明上述元件在训练方法的运作方式。
[0068]
请参照图3和图5,图5绘示根据一实施例的文件语句概念标注系统100的训练方法的流程图。在步骤s510中,提供数份已标注文件dc0至位置产生单元140。各个已标注文件dc0已标注一或多个语句概念cl1、
…
、cl5的一或多个语句集sc01、
…
、sc05。
[0069]
接着,在步骤s520中,位置产生单元140产生各个语句集sc01、
…
、sc05在这些已标注文件dc0的起始位置s01、
…
、s05及结束位置e01、
…
、e05。
[0070]
然后,在步骤s530中,增强资料产生单元150对这些已标注文件dc0调整这一或多个语句集sc01、
…
、sc05的顺序,并更新起始位置s01、
…
、s05及结束位置e01、
…
、e05为起始位置s01’、
…
、s05’及结束位置e01’、
…
、e05’,以获得数份生成文件dc0’。各个生成文件dc0’已标注一或多个语句集sc01、
…
、sc05。生成文件dc0’已经不是原来的已标注文件dc0,但保有这些语句集sc01、
…
、sc05。
[0071]
接着,在步骤s540中,将这些生成文件dc0’输入预训练语言模型110,以获得各个生成文件dc0’的一词向量集合v0’。
[0072]
然后,在步骤s550中,将这些生成文件dc0’之词向量集合v0’、各个起始位置s01’、
…
、s05’及各个结束位置e01’、
…
、e05’输入至文件分析模型120,以对文件分析模型120进行训练。也就是说,这些已标注文件dc0并未输入至文件分析模型120进行训练,反而是生成文件dc0’输入至文件分析模型120进行训练。在生成文件dc0’中,语句集sc01、
…
、sc05的顺序已被打乱,而没有顺序的特征。因此,对于各种文件结构的变异,文件语句概念标注系统100具有相当高的容忍度与强健性。
[0073]
举例来说,请参照下表二,相较于ai2标注方法,本揭露之标注方法在打乱顺序的未标注文件仍可维持与未打乱顺序的未标注文件相当接近的准确率。反观ai2之标注方法,在打乱顺序的未标注文件会大幅降低准确率,对文件结构的变异不具有高容忍度与强健性。
[0074][0075]
表二
[0076]
根据上述实施例,文件语句概念标注系统100在文件结构分析上具有相当高的准确性与强健性,其应用于关系抽取(relation extraction)与文件搜索(document retrieval)能够获得相当好的效果。
[0077]
传统上进行关系抽取时,可以从某些文件的全文中搜索出a疾病、b基因与c药等字词,然后就认定a疾病、b基因与c药具有高度关联性。然而,当c药是存在这些文件之「背景」之语句概念的语句集,a疾病、b基因是存在这些文件之「贡献」之语句概念的语句集时,c药其实并非对a疾病、b基因有高度关联,而产生关联性的错误认定。
[0078]
按照本实施例的作法,可以限定对「贡献」之语句概念的语句集进行搜索,若能够发现a疾病、b基因与c药等字词经常存在数份文件之「贡献」之语句概念的语句集,即可真正确认a疾病、b基因与c药具有高度关联性。
[0079]
请参照图6,其绘示根据一实施例采用文件语句概念标注系统100进行关系抽取的示意图。关系抽取系统200包括一断句单元(sentence segmentationunit)210、一命名实体识别单元(named entity recognition unit)220及一实体关系抽取单元(entity relation extraction unit)230。断句单元210、命名实体识别单元220及实体关系抽取单元230例如是一电路、一晶片、一电路板或储存数组程式码之储存装置。
[0080]
未标注文件dc2与语句概念cli输入至文件语句概念标注系统100后,可以获得语句集sci。命名实体识别单元220产生未标注文件dc2的数个实体nei。断句单元210产生未标注文件dc2中的所有语句si。实体关系抽取单元230根据这些实体nei在语句概念cli之语句集sci中是否存在关系,产生实体关系配对。举例来说,医学研究人员希望得知a疾病、b基因与c药的实体关系配对。实体关系抽取单元230会从特定的语句概念cli的语句集sci去观察a疾病、b基因与c药等实体nei是否经常一起出现,来产生正确的实体关系配对。也就是說,关系抽取系统200可以识别在未标注文件dc2中,语句概念sli的语句集sci的语句,是否存在实体关系配对。
[0081]
此外,传统上进行文件搜索时,会从某些文件中搜索出d病毒的字词,然后就认定这些文件都是针对d病毒的研究论文。然而,当d病毒的字词是存在部分文件的「背景」的语句概念的语句集时,这些文件很可能不是针对d病毒的研究,而产生文件搜索的错误。
[0082]
按照本实施例的做法,可以限定对「贡献」的语句概念的语句集进行搜索,或者给予「贡献」之语句概念的语句集较高的搜索优先权重,这样即可正确找出针对d病毒的研究论文。
[0083]
请参照图7,其绘示根据一实施例采用文件语句概念标注系统100进行文件搜索的示意图。文件搜索系统300包括一索引单元(indexing unit)310、一搜索条件处理单元
(query processing unit)320、一排序单元(ranking unit)330及一搜索结果呈现单元(result representation unit)340。索引单元310、搜索条件处理单元320、排序单元330及搜索结果呈现单元340例如是一电路、一晶片、一电路板或储存数组程式码的储存装置。
[0084]
在索引阶段中,输入一个或多个未标注文件dc3至索引单元310。索引单元将这些未标注文件dc3建立一文件索引。
[0085]
文件语句概念标注系统100对每一个未标注文件dc3撷取出数个属于语句概念clj的语句集scj。索引单元310对这语句集scj建立一子文件及其一子文件索引。
[0086]
在搜索阶段中,搜索条件处理单元320接收一查询条件q及语句概念clj。搜索条件处理单元320产生搜索条件后,由索引单元310在子文件索引中搜索,符合条件之子文件经由排序单元330排序后,由搜索结果呈现单元340根据搜索条件在这些子文件给予加权分数后传回搜索结果。也就是說,文件搜索系统300可以识别在未标注文件dc3中,基于语句概念cli对应的语句集scj中,是否满足某一查询条件。
[0087]
根据上述实施例,文件语句概念标注系统100在文件结构分析上具有相当高的准确性与强健性,其应用于关系抽取与文件搜索能够获得相当好的效果。尤其是在技术文件分析、标案文件分析、学术文本分析、社群评论文本分析等领域更有相当大的助益。
[0088]
应理解的是,以上所述仅为本揭露的具体实施例而已,并不用于限制本揭露,凡在本揭露的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本揭露的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
