1.本公开的实施例涉及计算机技术领域,具体涉及基于虚拟场景和用户语义信息的虚拟导游的控制方法。
背景技术:
2.虚拟导游是虚拟现实领域非常重要的辅助助手,能够帮助用户快速了解场景内容和场景信息。随着虚拟现实的不断普及,人们对于虚拟导游已经不仅仅局限于场景信息的讲解,同时也要保持一定的专业技巧以及交互礼仪,以保持用户体验的沉浸感和舒适感。2012年best等人提出making museum tours better的相关建议,他提出有关在真实世界中导游应该注意的问题和交互技巧。然而,对于虚拟场景中这却是一个挑战,其原因在于:首先,对于虚拟场景中,有关用户信息的获取需要我们分析和筛选有用的信息作为判断依据;其次虚拟导游如何根据这些信息保持合适的交互姿态。因此本发明提出一种目标物体推算方法,保证了语义信息的充分利用,并且根据这些信息为虚拟导游选择自然合理的交互姿态。
3.虚拟人物的交互位置、朝向问题已经有很多前人进行研究,2006年elber研究了虚拟人物的摆放位置和展现形式对于用户体验的影响,2019年techasarntikul探究了虚拟角色的不同位置和移动方式对于用户参观体验的影响。2019年lang提出了在混合现实场景中利用预实验的结果,对于给定场景下的虚拟导游位置和朝向的摆放。虽然目前对于虚拟人物的交互问题研究范围广泛,但是,对于这种实时通用的虚拟导游交互方法,已有工作鲜有研究,且本发明致力于如何为虚拟导游快速有效的找出最优的交互位置和朝向。
4.针对该领域研究中现有方法的不足。本发明公开了一种基于虚拟场景和用户语义信息的虚拟导游的实时优化位置的计算方法。该方法通过推算出用户感兴趣的目标物体,计算出虚拟导游最佳讲解位置和朝向。为了避免过于巨大的计算代价,该方法通过缩小解空间进行快速实时搜索。本方法在虚拟导游的位置、朝向优化方面能够得到优于已有方法的结果。
技术实现要素:
5.(一)所要解决的技术问题
6.本发明要解决的技术问题是:如何推测出当前虚拟场景下用户感兴趣的虚拟物体,如何在虚拟场景下为虚拟导游实时高效地计算出合理的讲解位置和朝向,以及如何实现虚拟导游的位置移动。
7.(二)技术方案
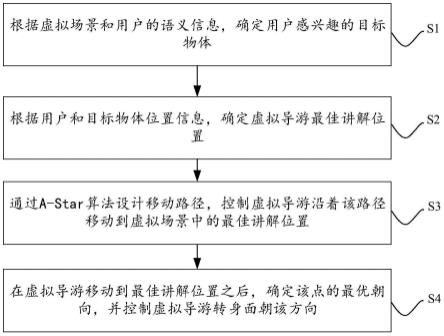
8.为了解决上述技术问题,本发明提出了一种基于虚拟场景和用户语义信息的虚拟导游的实时优化位置的计算方法,包括以下步骤:
9.s1、根据虚拟场景和用户的语义信息,确定用户感兴趣的目标物体;
10.s2、根据用户和目标物体位置信息,确定虚拟导游最佳讲解位置;
11.s3、通过a-star算法设计移动路径,控制虚拟导游沿着该路径移动到虚拟场景中的最佳讲解位置;
12.s4、在虚拟导游移动到最佳讲解位置之后,确定该点的最优朝向,并控制虚拟导游转身面朝该方向。
13.可选地,上述根据虚拟场景和用户的语义信息,确定用户感兴趣的目标物体包括:根据虚拟场景和用户的语义信息,确定用户感兴趣的目标物体。
14.可选地,上述根据用户和目标物体位置信息,确定虚拟导游最佳讲解位置包括:根据用户和目标物体位置信息,确定虚拟导游最佳讲解位置。
15.可选地,上述通过a-star算法设计移动路径,控制虚拟导游沿着该路径移动到虚拟场景中的最佳讲解位置包括:通过a-star算法设计移动路径,控制虚拟导游沿着该路径移动到虚拟场景中的最佳讲解位置。
16.可选地,上述在虚拟导游移动到最佳讲解位置之后,确定该点的最优朝向,并控制虚拟导游转身面朝该方向包括:在虚拟导游移动到最佳讲解位置之后,确定该点的最优朝向,并控制虚拟导游转身面朝该方向。
17.(三)有益效果
18.上述技术方案具有如下优点:本发明所提出的用于推测用户感兴趣目标物体的方法能够充分利用虚拟场景的物体属性信息以及用户自身语义信息,该语义信息有效表达了用户的兴趣点,有利于精准推测出目标物体。本发明通过缩小搜索空间,能够快速高效地搜索出虚拟导游的最佳讲解位置,做到实时计算更新虚拟导游的位置,让导游的位置和朝向能时刻保持最优解,有利于改善用户交互体验。
附图说明
19.图1是根据本公开的基于虚拟场景和用户语义信息的虚拟导游的控制方法的一些实施例的流程图。
具体实施方式
20.下面将参照附图更详细地描述本公开的实施例。虽然附图中显示了本公开的某些实施例,然而应当理解的是,本公开可以通过各种形式来实现,而且不应该被解释为限于这里阐述的实施例。相反,提供这些实施例是为了更加透彻和完整地理解本公开。应当理解的是,本公开的附图及实施例仅用于示例性作用,并非用于限制本公开的保护范围。
21.另外还需要说明的是,为了便于描述,附图中仅示出了与有关发明相关的部分。在不冲突的情况下,本公开中的实施例及实施例中的特征可以相互组合。
22.参考图1,示出了根据本公开的基于虚拟场景和用户语义信息的虚拟导游的控制方法的一些实施例的流程。该基于虚拟场景和用户语义信息的虚拟导游的控制方法,包括以下步骤:
23.步骤s1,根据虚拟场景和用户的语义信息,确定用户感兴趣的目标物体。
24.在一些实施例中,基于虚拟场景和用户语义信息的虚拟导游的控制方法的执行主体(例如计算设备)可以根据虚拟场景和用户的语义信息,确定用户感兴趣的目标物体。
25.作为示例,本步骤可以包括以下子步骤:
26.第一子步骤,获取虚拟场景的语义信息和用户的语义信息。
27.其中,上述执行主体可以通过有线连接或无线连接的方式,获取虚拟场景的语义信息和用户的语义信息。其中,虚拟场景的语义信息可以是在虚拟场景下的物体信息。虚拟场景的语义信息可以包括用户周围三米范围内所有场景物体的位置信息po和物体的朝向信息θo。用户的语义信息可以是在虚拟场景下的用户信息。用户的语义信息可以包括用户的位置信息和朝向信息用户可以是使用虚拟导游系统游览虚拟场景的人。用户的位置信息可以表征用户在虚拟场景下的坐标。虚拟场景可以是计算机渲染生成的3d场景环境,可以是在vr环境下的用户活动场景,比如vr下的博物馆,商城等3d场景。用户的朝向信息可以表征用户视线方向与虚拟场景正北方向的以弧度制度量的夹角。物体的位置信息po可以表征物体在虚拟场景下的坐标。物体的朝向信息θo可以表征物体与虚拟场景正北方向的以弧度制度量的夹角。在虚拟场景下的坐标,所在的坐标系可以是右手坐标系。在虚拟场景下的坐标,所在的坐标系可以是如下构建的:以虚拟场景的中心为原点,以与虚拟场景的南北方向平行的轴为横轴,以与虚拟场景的东西方向平行的轴为纵轴,以与虚拟场景上下方向平行的轴为竖轴。其中,在虚拟场景下的坐标中的竖坐标可以是一个定值。例如,虚拟场景下的坐标中的竖坐标可以是地板所在楼层的高度。
28.第二子步骤,根据用户的位置信息和物体的位置信息,确定用户与物体之间的距离关系。
29.例如,上述执行主体根据用户的位置信息和物体的位置信息,通过以下公式,确定用户与物体之间的距离关系:
[0030][0031]
其中,可以表征用户与物体之间的距离关系的得分函数。用户与物体之间的距离越近,的值越大。是用户的位置信息,例如坐标(x
t
,z
t
。其中,x
t
是用户在虚拟场景下的坐标(x
t
,z
t
)中的横坐标。z
t
是用户在虚拟场景下的坐标(x
t
,z
t
)中的纵坐标。po是物体的位置信息,例如坐标(xo,zo)。其中,xo是物体在虚拟场景下的坐标(xo,zo)中的横坐标。zo是物体在虚拟场景下的坐标(xo,zo)中的纵坐标。exp()是以自然常数为底的幂指数。是以自然常数为底的幂指数函数。是用户位置与物体位置之间的的欧式距离。是用户位置与物体位置之间的欧式距离的平方,例如(x
t-xo)2 (z
t-zo)2。
[0032]
第三子步骤,根据用户的朝向信息和物体的朝向,确定用户与物体之间的朝向关系。
[0033]
例如,上述执行主体根据用户的朝向信息和物体的朝向,通过以下公式,确定用户与物体之间的朝向关系:
[0034][0035]
其中,可以表征用户与物体之间的朝向关系的得分函数。是用户的朝向信息。θo是物体的朝向信息。π表示180
°
的弧度制。cos()是余弦函数。
[0036]
第四子步骤,根据用户与物体之间的距离关系和用户与物体之间的朝向关系,确定物体的总得分函数,得到物体的总得分函数值。
[0037]
其中,物体的总得分函数值可以表征用户对物体感兴趣的程度。物体的总得分函数值越高,用户对该物体越感兴趣。
[0038]
例如,上述执行主体根据用户与物体之间的距离关系和用户与物体之间的朝向关系,通过以下公式,确定物体的总得分函数:
[0039][0040]
其中,f(u
t
,o)是物体的总得分函数。a
p
和a
θ
是f(u
t
,o)的参数。通过调参,a
p
和a
θ
的取值可以是0.5。可以表征用户与物体之间的朝向关系的得分函数。可以表征用户与物体之间的距离关系的得分函数。用户与物体之间的距离越近,的值越大。是用户的位置信息。po是物体的位置信息。是用户的朝向信息。θo是物体的朝向信息。
[0041]
第五子步骤,根据每个物体的得分函数值,将得分函数值最高的物体作为用户感兴趣的目标物体。
[0042]
其中,用户感兴趣的目标物体是得分函数值最高的物体。
[0043]
步骤s2,根据用户和目标物体位置信息,确定虚拟导游最佳讲解位置。
[0044]
在一些实施例中,上述执行主体可以根据用户和目标物体位置信息,确定虚拟导游最佳讲解位置。
[0045]
作为示例,本步骤可以包括以下子步骤:
[0046]
第一子步骤,根据虚拟导游移动开始的位置信息和虚拟导游移动结束的位置信息,确定虚拟导游移动距离关系。
[0047]
其中,虚拟导游移动开始的位置信息可以表征虚拟导游未移动之前的坐标。虚拟导游移动结束的位置信息可以表征虚拟导游移动到每一个可能到达的点的坐标。
[0048]
例如,上述执行主体根据虚拟导游移动开始的位置信息和虚拟导游移动结束的位置信息,通过以下公式,确定虚拟导游移动距离关系:
[0049][0050]
其中,是虚拟导游移动开始的位置到虚拟导游移动结束的位置之间的移动距离关系的函数。是虚拟导游移动开始的位置信息,例如坐标(x1,z1)。其中,x1是虚拟导游移动开始时,在虚拟场景下的坐标(x1,z1)中的横坐标。z1是虚拟导游移动开始时,在虚
拟场景下的坐标(x1,z1)中的纵坐标。是虚拟导游移动结束,可能站立位置对应的位置信息,例如可以是坐标(x2,z2)。其中,x2是虚拟导游移动结束时,在虚拟场景下的坐标(x2,z2)中的横坐标。z2是虚拟导游移动结束时,在虚拟场景下的坐标(x2,z2)中的纵坐标。σ是超参数,通过调参σ可以取值为1。exp()是以自然常数为底的幂指数。是虚拟导游移动开始的位置,和虚拟导游移动结束的位置的欧式距离。是虚拟导游移动开始的位置和虚拟导游移动结束的位置的欧式距离的平方。
[0051]
例如,可以是(x
1-x2)2 (z
1-z2)2。
[0052]
第二子步骤,根据虚拟导游的位置信息,确定虚拟导游可能站立的位置与用户左右两侧最优位置之间的位置关系。其中,虚拟导游可以是由计算机控制的为用户讲解的3d人物模型。虚拟导游包括的移动和讲解等行为模式可以由相关编写程序定义。虚拟导游可能的位置信息可以用于表征虚拟导游可能站立在虚拟场景下的坐标。
[0053]
例如,可以表征虚拟导游可能站立的位置与用户左侧最优位置之间的位置得分函数。可以表征虚拟导游可能站立的位置与用户右侧最优位置之间的位置得分函数。其中,和分别代表着虚拟导游在用户左右两侧的最优位置的坐标。是虚拟导游移动结束,可能站立的位置对应的位置信息。σ是超参数。σ通过调参可以设置为1。虚拟导游在用户左右两侧的最优位置的坐标和的求解的计算公式相同,都是由用户实验结果拟合的函数曲线x(d)=λ1·
d2 λ2·
d λ3和z(d)=λ4·
d2 λ5·
d λ6计算得出。其中,通过实验数据中的虚拟导游的坐标(x,z),利用最小二乘法进行一元二次函数曲线拟合。其中,实验数据中的虚拟导游的坐标(x,z)可以是在一个简易的虚拟场景下,若干个用户根据自己喜好,在距自己不同距离,选择的若干个虚拟导游位置的坐标。其中,x是虚拟导游在虚拟场景下的坐标(x,z)中的横坐标。z是虚拟导游在虚拟场景下的坐标(x,z)中的纵坐标。λ1、λ2、λ3、λ4、λ5和λ6分别是拟合函数的求解参数。x(d)可以是求解坐标和坐标的横坐标的函数。z(d)可以是求解坐标和坐标的纵坐标的函数。的参数λ1、λ2、λ3、λ4、λ5和λ6可以分别是[0.0472,-0.3242,-0.7462,-0.1452,1.2666,-1.0927]中的数值。的参数λ1、λ2、λ3、λ4、λ5和λ6可以分别是[-0.1104,0.5739,0.6276,-0.1556,1.3632,-1.2280]中的数值。d是x(d)和z(d)函数的自变量。d可以是用户和目标物体的距
离。通过和这两个函数,可以选择尽可能离用户实验结果靠近的点作为讲解位置。exp()是以自然常数为底的幂指数。是虚拟导游可能站立的点的位置与虚拟导游在用户左侧的最优位置之间的欧式距离。是虚拟导游可能站立的点的位置与虚拟导游在用户右两侧的最优位置之间的欧式距离。
[0054]
第三子步骤,根据左右两边的位置得分函数与移动距离函数,确定虚拟导游最佳讲解位置。
[0055]
例如,上述执行主体根据左右两边的位置得分函数与移动距离函数,通过以下公式,确定虚拟导游最佳讲解位置:
[0056][0057]
其中,是可以表征虚拟导游最佳讲解位置的函数。是虚拟导游移动结束,可能站立的位置的位置信息。是虚拟导游移动开始的位置到虚拟导游移动结束的位置之间的移动距离关系的函数。可以表征虚拟导游可能站立的位置与用户左侧最优位置之间的位置得分函数。可以表征虚拟导游可能站立的位置与用户右侧最优位置之间的位置得分函数。max{}是取最大值操作。sa()是模拟退火函数。其中,对于求解最大值问题,由于解空间(虚拟导游可以站立的空间)为连续空间,无法通过遍历直接求解最大值。所以可以通过模拟退火算法(simulated anneaing)近似求解最大值。和传统模拟退火类似,具体求解方式可以包括:(1)令t=t0表示开始退火的初始温度,初始解y0可以设置为求解的虚拟导游最优位置,并计算对应的目标函数值e(y0)。其中,目标函数可以是或(2)令t=kt。其中,k取值在0到1之间。k是温度下降速率,比如可以取值为0.85。对当前解y
t
施加随机扰动(将y坐标位置随机移动2/n米,n为迭代次数),在其邻域内产生一个新解y
t 1
,并计算对应的目标函数值e(y
t 1
),可以以p表征接受新的解的概率。其中,可以根据实验数据,例如,迭代进行200次。最后的y
t
作为可以接受的最优解。
[0058]
步骤s3,通过a-star算法设计移动路径,控制虚拟导游沿着该路径移动到虚拟场景中的最佳讲解位置。
[0059]
在一些实施例中,上述执行主体可以通过a-star算法设计移动路径,控制虚拟导游沿着该路径移动到虚拟场景中的最佳讲解位置。其中,移动路径是虚拟导游到最佳讲解位置,所需要移动的路径。
[0060]
作为示例,上述执行主体可以通过以下a-star算法,确定移动路径:
[0061]f*
(n)=g
*
(n) h
*
(n)。
[0062]
其中,f
*
(n)是上述执行主体控制虚拟导游,从虚拟导游的初始位置经由编号为n的位置,到虚拟场景中的最佳讲解位置的最小距离的估计。g
*
(n)是上述执行主体控制虚拟导游,从虚拟导游的初始位置,到编号为n的位置的最小的欧式距离。h
*
(n)是上述执行主体控制虚拟导游,从编号为n的位置到虚拟场景中的最佳讲解位置的最小的曼哈顿距离的估计。
[0063]
步骤s4,在虚拟导游移动到最佳讲解位置之后,确定该点的最优朝向,并控制虚拟导游转身面朝该方向。
[0064]
在一些实施例中,上述执行主体可以在虚拟导游移动到最佳讲解位置之后,确定该点的最优朝向,并控制虚拟导游转身面朝该方向。其中,上述执行主体可以根据最优朝向公式,确定虚拟导游在最佳讲解位置的最优朝向,并控制虚拟导游转身面朝该方向。
[0065]
作为示例,上述执行主体可以通过以下公式,确定虚拟导游的最优朝向:
[0066]
θ(x,z)=w1·
x2 w2·
z2 w3·
x
·
z w4·
x w5·
z w6。
[0067]
其中,θ(x,z)是表征虚拟导游在最佳讲解位置的以弧度制度量的朝向函数。x是虚拟导游在虚拟场景下的横坐标。z是虚拟导游在虚拟场景下的竖坐标。w1、w2、w3、w4、w5和w6分别是函数θ(x,z)的6个参数。其中,w1、w2、w3、w4、w5和w6可以是根据用户实验结果中的虚拟导游的坐标和朝向,利用最小二乘法拟合出二元二次方程作为虚拟导游的用户朝向计算函数,以生成的用户朝向计算函数的参数结果值。w1、w2、w3、w4、w5和w6分别可以取值为[0.1254,-0.0511,0.0010,-0.4685,-0.2975,0.5856]。
[0068]
以上描述仅为本公开的一些较佳实施例以及对所运用技术原理的说明。本领域技术人员应当理解,本公开的实施例中所涉及的发明范围,并不限于上述技术特征的特定组合而成的技术方案,同时也应涵盖在不脱离上述发明构思的情况下,由上述技术特征或其等同特征进行任意组合而形成的其它技术方案。例如上述特征与本公开的实施例中公开的(但不限于)具有类似功能的技术特征进行互相替换而形成的技术方案。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。