1.本技术涉及计算机技术领域,更具体的说,是涉及一种密码处理器的编译器代码生成方法及相关设备。
背景技术:
2.vliw(very long instruction word,超长指令字)架构密码处理器是指采用vliw架构的密码专用指令集处理器。vliw架构是根据程序并行性和资源可用性对多条指令编码,组成一条在一个周期内执行的超长指令。其核心思想是将指令调度从硬件转移到编译器上。
3.vliw架构密码处理器采用了特殊的超长指令字架构,和传统的超长指令字架构处理器相比,采用了任意读、固定写的寄存器访问方式,采用了可重构的运算单元,簇内包括通用寄存器、密钥寄存器和配置寄存器三类寄存器文件,采用了不同字长的指令和簇间运算单元级联的方式以适应灵活的密码运算位宽。传统的超长指令字架构处理器的密码处理器的编译器代码生成方法不适用于vliw架构密码处理器。
4.因此,如何提供一种适用于vliw架构密码处理器的密码处理器的编译器代码生成方法,成为本领域技术人员亟待解决的技术问题。
技术实现要素:
5.鉴于上述问题,本技术提出了一种密码处理器的编译器代码生成方法及相关设备。具体方案如下:
6.一种密码处理器的编译器代码生成方法,所述方法包括:
7.获取数据流图,所述数据流图对应多个指令;
8.从所述数据流图对应的各个指令中,筛选出可调度指令,并确定每个可调度指令的候选簇;
9.从所述可调度指令中确定预设数量的目标指令,并基于每个目标指令的候选簇确定所述目标指令所在簇;所述预设数量与一条超长指令内指令槽的数量一致;
10.基于所述目标指令内的操作数的候选寄存器类型以及所述目标指令所在簇,对所述目标指令内的操作数进行寄存器分配。
11.可选地,所述从所述数据流图对应的各个指令中,筛选出可调度指令,并确定每个可调度指令的候选簇,包括:
12.基于所述数据流图,确定无前驱结点的指令列表;
13.从所述无前驱结点的指令列表中,筛选出可调度指令,并确定每个可调度指令的候选簇。
14.可选地,所述从所述可调度指令中确定预设数量的目标指令,并基于每个目标指令的候选簇确定所述目标指令所在簇,包括:
15.确定各可调度指令的优先级;
16.基于所述各可调度指令的优先级,从所述可调度指令中确定预设数量的目标指令;
17.针对每个目标指令,确定所述目标指令的候选簇对应的寄存器文件间的最大压力差;基于所述目标指令的候选簇对应的寄存器文件间的最大压力差确定所述目标指令所在簇。
18.可选地,所述确定各可调度指令的优先级,包括:
19.针对每个可调度指令,确定所述可调度指令的可移动性、后继结点个数和字长;
20.基于所述可调度指令的可移动性、后继结点个数和字长,确定所述可调度指令的优先级。
21.可选地,所述确定所述可调度指令的可移动性,包括:
22.基于所述数据流图,确定所述可调度指令的最早执行时间和最晚执行时间;
23.基于所述可调度指令的最早执行时间和最晚执行时间,确定所述可调度指令的可移动性。
24.可选地,所述指令内的操作数的候选寄存器类型的确定方式,包括:
25.确定所述指令内的操作数的定值-引用链,以及,所述指令对操作数的寄存器类型约束信息;
26.基于所述指令内的操作数的定值-引用链,以及,所述指令对操作数的寄存器类型约束信息,确定所述指令内的操作数的候选寄存器类型。
27.可选地,所述基于所述目标指令内的操作数的候选寄存器类型以及所述目标指令所在簇,对所述目标指令内的操作数进行寄存器分配,包括:
28.确定目标寄存器文件,所述目标寄存器文件为所述目标指令所在簇内所述候选寄存器类型对应的寄存器文件;
29.获取所述目标寄存器文件对应的活跃变量列表,所述活跃变量列表用于表征当前存储在所述目标寄存器文件中的变量;
30.基于所述目标寄存器文件对应的活跃变量列表,确定所述目标寄存器文件是否存在可用寄存器;
31.如果存在,则为所述目标指令内的操作数分配所述目标寄存器文件中的可用寄存器。
32.一种密码处理器的编译器代码生成装置,所述装置包括:
33.获取单元,用于获取数据流图,所述数据流图对应多个指令;
34.指令筛选单元,用于从所述数据流图对应的各个指令中,筛选出可调度指令,并确定每个可调度指令的候选簇;
35.簇指派单元,用于从所述可调度指令中确定预设数量的目标指令,并基于每个目标指令的候选簇确定所述目标指令所在簇;所述预设数量与一条超长指令内指令槽的数量一致;
36.寄存器分配单元,用于基于所述目标指令内的操作数的候选寄存器类型以及所述目标指令所在簇,对所述目标指令内的操作数进行寄存器分配。
37.一种密码处理器的编译器代码生成设备,包括存储器和处理器;
38.所述存储器,用于存储程序;
39.所述处理器,用于执行所述程序,实现如上所述的密码处理器的编译器代码生成方法的各个步骤。
40.一种可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现如上所述的密码处理器的编译器代码生成方法的各个步骤。
41.借由上述技术方案,本技术公开了一种密码处理器的编译器代码生成方法及相关设备,该方案中,首先,获取数据流图,所述数据流图对应多个指令;然后,从所述数据流图对应的各个指令中,筛选出可调度指令,并确定每个可调度指令的候选簇;再从所述可调度指令中确定预设数量的目标指令,并基于每个目标指令的候选簇确定所述目标指令所在簇;所述预设数量与一条超长指令内指令槽的数量一致;最后,基于所述目标指令内的操作数的候选寄存器类型以及所述目标指令所在簇,对所述目标指令内的操作数进行寄存器分配,该方案适用于vliw架构密码处理器的编译器代码生成,且能够降低编译时间,提升生成程序的性能。
附图说明
42.通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本技术的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
43.图1为本技术实施例公开的一种vliw架构密码处理器的结构示意图;
44.图2为本技术实施例公开的一种vliw架构密码处理器的指令示意图;
45.图3为本技术实施例公开的一种密码处理器的编译器代码生成方法的流程示意图;
46.图4为本技术实施例公开的存在寄存器类型冲突的dfg示意图;
47.图5为本技术实施例公开的解决寄存器类型冲突的dfg示意图;
48.图6为本技术实施例公开的一种密码处理器的编译器代码生成装置结构示意图;
49.图7为本技术实施例公开的一种密码处理器的编译器代码生成设备的硬件结构框图。
具体实施方式
50.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
51.随着运算单元的增多,vliw架构处理器应当能够提供相应的寄存器文件,以满足数据的读写需求。所有运算单元访问同一个寄存器文件会降低架构的可扩展性,大量的读写端口也会增加数据的访问延迟。因此,vliw架构处理器通常采用分簇式结构,簇内运算单元可以访问簇内寄存器,簇间数据交互则需要额外的硬件资源、传输指令和时钟周期。分簇式结构一定程度上制约了指令级并行,并将原本的静态调度策略复杂化,以高性能为目标的指令调度,既要充分利用不同簇中的运算单元以提高并行性,又要减小簇间数据交互的时间开销,还要考虑寄存器端口对并行性的约束,以及簇间寄存器压力不均衡造成的不必
要的寄存器溢出。
52.vliw架构处理器的编译器代码生成主要分为三个阶段:簇指派、指令调度和寄存器分配。其中,簇指派是确定指令执行时所处的簇。指令调度是一种编译器优化,在不更改程序功能的情况下重排指令的执行顺序,用于提高指令级并行性,从而提高处理器的性能。寄存器分配是将变量分配给有限数量寄存器的过程。
53.传统的超长指令字架构处理器的密码处理器的编译器代码生成方法中,启发式算法编译时间过长,无法保证解的质量,非启发式算法又不适用于vliw架构密码处理器的编译器代码生成,有鉴于此,本案发明人进行了深入研究,最终提出了一种适用于vliw架构密码处理器的密码处理器的编译器代码生成方法。
54.下面先对vliw架构密码处理器的结构进行详细说明。
55.参照图1,图1为本技术实施例公开的一种vliw架构密码处理器的结构示意图。如图1所示,vliw架构密码处理器内部有四个簇cluster a,cluster b,cluster c和cluster d,簇间采用同构设计,簇内包含12个rce(reconfigurable computing element,可重构运算单元),datarf(data register files,数据寄存器文件),和keyrf(key register files,密钥寄存器文件),datarf的大小为32
×
32bit,keyrf的大小为64
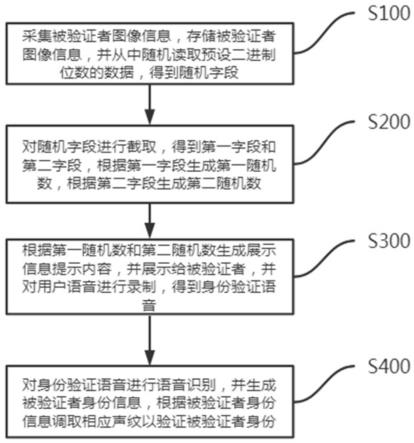
×
32bit。datarf有两个读端口和一个写端口,keyrf则有一个读端口和一个写端口。
56.需要说明的是,vliw架构密码处理器还有如下特殊约束需要遵守:
57.考虑到密码运算的混乱和扩散特性,会造成频繁的跨簇通信。因此,寄存器采用任意读和固定写的组织方式,即簇内rce可以读取其他簇的寄存器文件,但只能将数据写回到本簇的寄存器文件。
58.簇内12个rce可执行的运算各不相同,包括置换、替代、模运算等,通过写入相应的配置信息,能够实现运算单元重构,比如置换操作不同的位宽、不同的置换表等。簇内的配置信息和rce两者之间是紧耦合的,即簇内的配置信息只对该簇的运算单元有效。因此,为了使用相应的配置信息,必须将指令指派到对应簇上。
59.数据寄存器文件和密钥寄存器文件并不根据数据类型区分使用,而是根据指令格式。某些指令中的操作数既可以存储在数据寄存器,也可以存储在密钥寄存器。
60.vliw架构密码处理器的指令都是单周期的,并通过数据前推等方式解决了相邻超长指令之间的数据相关性。另外,参照图2,图2为本技术实施例公开的一种vliw架构密码处理器的指令示意图。如图2所示,在vliw架构密码处理器中,设计了不同字长的指令,以适应密码运算中不同的操作位宽,包括单字指令、双字指令和四字指令,分别处理32、64和128比特的数据,占据1个、2个和4个指令槽slot。占据多个指令槽的指令,可以将结果写回到相应的多个簇中。比如,占据slot1和slot2的双字指令,可以将数据写回到clustera或者clusterb的寄存器中。
61.基于上述vliw架构密码处理器,本案发明人提出了一种密码处理器的编译器代码生成方法。接下来,通过下述实施例对本技术提供的密码处理器的编译器代码生成方法进行介绍。
62.参照图3,图3为本技术实施例公开的一种密码处理器的编译器代码生成方法的流程示意图,该方法可以包括:
63.步骤s101:获取数据流图,所述数据流图对应多个指令。
64.在本技术中,所述数据流图dfg(dataflow gragh)中包括多个结点,每个结点对应一个指令。
65.需要说明的是,所述数据流图可以为初始数据流图,也可以为经过一次编译器代码生成流程之后对初始数据流图进行更新后的数据流图,数据流图的更新方式可以为将经过一次编译器代码生成流程确定的目标执行的后继结点的入度减1。
66.步骤s102:从所述数据流图对应的各个指令中,筛选出可调度指令,并确定每个可调度指令的候选簇。
67.步骤s103:从所述可调度指令中确定预设数量的目标指令,并基于每个目标指令的候选簇确定所述目标指令所在簇;所述预设数量与一条超长指令内指令槽的数量一致。
68.步骤s104:基于所述目标指令内的操作数的候选寄存器类型以及所述目标指令所在簇,对所述目标指令内的操作数进行寄存器分配。
69.在本技术中,上述步骤执行完毕后,即执行完毕一次编译器代码生成流程,生成一条超长指令,该超长指令中包括预设数量的目标指令。目标指令将得到相应的三元组{ci,ti,ri},其中ci表示目标指令所在簇,ti表示目标指令的执行时间,ri表示目标指令中操作数所在寄存器的有序集合。ri中的元素同样可以用三元组{ci,ti,si}表示,其中ci表示操作数所在簇,ti表示操作数的寄存器类型,si表示操作数的具体寄存器。比如,{cluster ab,4,{《cluster a,drfs,6》,《cluster b,krfs,8》}}表示双字指令在第4个时钟周期时在cluster ab上被调度,其两个目的操作数分别存储在cluster a中drfs的第6个寄存器和cluster b中krfs的第8个寄存器。
70.需要说明的是,本技术中需要执行至少一次的上述四个步骤,才能将数据流图中全部指令处理完毕。每执行一次上述四个步骤,均对数据流图进行更新一次,再以更新后的数据流图作为处理对象执行上述四个步骤。
71.本实施例公开了一种密码处理器的编译器代码生成方法,该方法中,首先,获取数据流图,所述数据流图对应多个指令;然后,从所述数据流图对应的各个指令中,筛选出可调度指令,并确定每个可调度指令的候选簇;再从所述可调度指令中确定预设数量的目标指令,并基于每个目标指令的候选簇确定所述目标指令所在簇;所述预设数量与一条超长指令内指令槽的数量一致;最后,基于所述目标指令内的操作数的候选寄存器类型以及所述目标指令所在簇,对所述目标指令内的操作数进行寄存器分配,该方法适用于vliw架构密码处理器的编译器代码生成,且能够降低编译时间,提升生成程序的性能。
72.在本技术的另一个实施例中,对所述从所述数据流图对应的各个指令中,筛选出可调度指令,并确定每个可调度指令的候选簇的具体实现方式进行说明,该方式可以包括如下步骤:
73.步骤s201:基于所述数据流图,确定无前驱结点的指令列表。
74.在本技术中,可以构造无前驱结点指令列表l,任意指令op∈l,满足pred(op)=null。
75.步骤s202:从所述无前驱结点的指令列表中,筛选出可调度指令,并确定每个可调度指令的候选簇。
76.具体的,对于无前驱结点的指令列表l中的每个指令,根据其指令类型(可重构指令或非可重构指令)、指令配置信息所在簇占用情况、端口约束、指令字长和初始候选簇占
用情况确定候选簇,候选簇集合为空的指令为不可调度指令。
77.对于可重构指令,比如置换指令、s盒替代指令等,先检查配置信息所在簇是否被占用。簇内rce采用可重构设计,预先将配置信息写入簇内,可以用同一指令实现不同参数的运算。但由于rce和配置信息的紧耦合性,簇一旦被其他指令占用,使用簇内配置信息的指令便不能在当前周期执行。
78.对于非可重构指令,不同字长指令的初始候选簇不同。四字指令的初始候选簇为{cluster abcd},双字指令的初始候选簇为{cluster ab,cluster cd},单字指令的初始候选簇为{cluster a,cluster b,cluster c,cluster d}。另外,还需要根据簇的占用情况,去除初始候选簇内不可用的簇。当cluster a被占用时,四字指令的候选簇为φ,双字指令的候选簇为{cluster cd},单字指令的初始候选簇为{cluster b,cluster c,cluster d}。
79.最后,指令要满足读端口约束。drfs和krfs有固定的读端口数,drfs有2个读端口,krfs有1个读端口。超长指令内已调度的指令会占用一部分读端口,因此新增的指令不能造成冲突。cluster a中drf的2个读端口已经被占用时,源操作数同样来自该寄存器文件的指令将不会被选择。
80.为便于理解,可参考如下代码:
81.1:foreach op in l
82.2:if(op是可重构指令)
83.3:if(op配置信息所在簇被占用)
84.4:op不可调度;
85.5:else if(op满足读端口约束)
86.6:op可调度,候选簇为配置信息所在簇;
87.7:else
88.8:op不可调度;
89.9:else
90.10:根据指令字长和簇占用情况,生成候选簇;
91.11:if(候选簇集合为空)
92.12:op不可调度;
93.13:else if(op满足读端口约束)
94.14:op可调度;
95.15:else
96.op不可调度,设候选簇集合为空;
97.在本技术的另一个实施例中,对所述从所述可调度指令中确定预设数量的目标指令,并基于每个目标指令的候选簇确定所述目标指令所在簇的具体实现方式进行说明,该方式可以包括以下步骤:
98.步骤s301:确定各可调度指令的优先级;
99.作为一种可实施方式,所述确定各可调度指令的优先级,包括:针对每个可调度指令,确定所述可调度指令的可移动性、后继结点个数和字长;基于所述可调度指令的可移动性、后继结点个数和字长,确定所述可调度指令的优先级。
100.在本技术中,为了保证对性能影响较大的指令先被执行,采用基于优先级的指令
选择方法,依次考虑指令的可移动性、后继结点个数和指令字长对调度结果的影响。
101.作为一种可实施方式,所述确定所述可调度指令的可移动性,包括:基于所述数据流图,确定所述可调度指令的最早执行时间和最晚执行时间;基于所述可调度指令的最早执行时间和最晚执行时间,确定所述可调度指令的可移动性。具体的,对dfg进行asap调度,得出指令op的最早执行时间为te(op);对dfg进行alap调度,得出指令op的最晚执行时间为tl(op);计算指令op的可移动性,mobility(op)=tl(op)-te(op)。
102.步骤s302:基于所述各可调度指令的优先级,从所述可调度指令中确定预设数量的目标指令;
103.可移动性小的指令比可移动性大的指令有更高优先级。可移动性越小,其对于指令的调度越关键。可移动性小的指令一旦被推迟,将会恶化程序整体的执行时间。因此,可移动性小的指令应当优先被处理。在可移动性相同的前提下,后继结点个数多的指令比后继结点少的指令有更高优先级。指令的后继结点个数越多,其被执行之后能够释放的指令也就越多,有利于接下来的调度;指令的后继结点个数越少,其被执行之后能够释放的指令也就越少,不利于接下来的调度。因此,后继结点个数多的指令应当优先被处理。在可移动性和后继结点个数相同的前提下,长字指令比短字指令有更高的优先级。一方面,单独对于四字长的指令来说,无论先执行还是后执行都不影响最终程序的执行时间;另一方面,从灵活性来看,短字指令比长字指令更加灵活,单字指令可以填充到指令槽的任一位置,双字指令必须有两个连续的指令槽slot 12或slot 34,四字指令则要求所有指令槽均为空。因此,相对于短字指令,长字指令应当优先被处理。
104.步骤s303:针对每个目标指令,确定所述目标指令的候选簇对应的寄存器文件间的最大压力差;基于所述目标指令的候选簇对应的寄存器文件间的最大压力差确定所述目标指令所在簇。
105.在硬件结构的约束下,指令所在簇直接决定了操作数的存储位置。因此,簇指派时要充分考虑平衡寄存器文件间的压力。一方面,变量溢出需要增加访存指令,进而影响程序的性能,相对平衡的寄存器压力可以降低变量溢出的概率;另外一方面,相对均衡的寄存器压力,使指令的源操作数来源相对均衡,进而降寄存器文件读端口冲突的概率,有利于接下来的调度。
106.在本技术中,可以针对每个目标指令,计算所述目标指令的候选簇对应的寄存器文件间的最大压力差寄存器文件间的最大压力差是指在当前周期下,寄存器文件的最大压力和最小压力的差值。计算最大压力差时需要将drfs和krfs分开考虑。比如,4个drfs的压力分别为2、3、1、2,单字指令xor32 rd,rs1,rs2中目的操作数rd的寄存器类型为drfs,该指令的3个候选簇分别为cluster b、cluster c、cluster d,可以计算得出三种簇选择方案下寄存器文件间的最大压力差分别为3、1、2。明显地,我们选择最大压力差更小的方案,即将指令指派到cluster c上。
107.在本技术的另一个实施例中,对所述指令内的操作数的候选寄存器类型的确定方式进行详细说明,该方式可以包括以下步骤:
108.步骤s401:确定所述指令内的操作数的定值-引用链,以及,所述指令对操作数的寄存器类型约束信息。
109.指令手册详细地约束了每条指令中操作数的寄存器类型,这类约束不仅出现在源
操作数位置,还出现在目的操作数位置。比如,perm_xor rd,rs1,rs2,rs3指令的源操作数rs3只能来自krf,而xor32rd,rs1,rs2指令的目的操作数rd只能写回到drf。这意味着每个操作数有两个及以上的寄存器类型约束。在指令调度时进行寄存器类型指派,无法评估后续引用对操作数寄存器类型的约束,导致出现冲突的可能性增大。在指令调度结束后再进行寄存器类型指派,解决冲突时需要插入新指令,从而产生不必要的重调度。因此,先为操作数指派寄存器类型。
110.步骤s402:基于所述指令内的操作数的定值-引用链,以及,所述指令对操作数的寄存器类型约束信息,确定所述指令内的操作数的候选寄存器类型。
111.寄存器类型指派阶段,根据操作数的“定值-引用”链和指令中对操作数的寄存器类型约束,为操作数指派寄存器类型,具体过程如下:
112.首先,根据dfg构造每个操作数的“定值-引用”链,其可以用一个三元组{x,d,u}来表示,其中x是操作数的符号名,d是定值所在的位置,u是该定值的引用集合。如图4(存在寄存器类型冲突的dfg)所示,{tmp,《op1,1》,{《op4,3》,《op6,2》}}表示操作数tmp在op1的第1个位置被定值,在op4的第3个位置和op6的第2个位置被引用。
113.其次,确定操作数的候选寄存器类型集合。用type(op,k)表示指令op第k个操作数的寄存器类型约束,type(op,k)的取值有三种情况:{drfs}、{krfs}、{drfs,krfs}。操作数的候选寄存器类型集合,是定值点寄存器类型约束和所有引用点寄存器类型约束的交集。如图4(存在寄存器类型冲突的dfg)所示,操作数tmp的候选寄存器类型集合为type(op1,1)∩type(op4,3)∩type(op6,2),其候选寄存器类型集合有四种可能的取值:{drfs}、{krfs}、{drfs,krfs}、φ:
114.当取值为{drfs}、{krfs}时,即集合中只有一个元素时,直接为操作数指派相应的寄存器类型;
115.当取值为{drfs,krfs},应当平衡不同类型寄存器文件之间的压力。但此时并未对指令进行调度,无法准确评估各个寄存器文件的压力。根据经验,可以直接为操作数指派drfs,这是由于密码运算中多数数据定值之后马上被引用,且只引用一次,drfs在整体上有更小的寄存器压力;
116.当取值为φ时,则出现了寄存器类型冲突,可以通过重命名所有冲突的引用、插入mov指令并更新dfg和“定值-引用”链的方式来解决冲突。假设type(op1,1)={drfs},type(op4,3)={drfs,krfs},type(op6,2)={krfs},计算type(op1,1)∩type(op4,3)={drfs},而type(op1,1)∩type(op4,3)∩type(op6,2)=φ,可以认为所有冲突的引用有《op6,2》。因此,在op6和op1之间插入一条mov tmp1,tmp指令op7,为操作数tmp指派为drfs类型,为操作数tmp1指派为krfs类型。在此基础上,dfg和“定值-引用”链需要进行更新,更新后的dfg如图5(解决寄存器类型冲突的dfg)所示。原本的1条“定值-引用”链也被转换成2条,{tmp,《op1,1》,{《op4,3》}}和{tmp1,《op7,1》,{《op6,2》}}。
117.在本技术的另一个实施例中,对所述基于所述目标指令内的操作数的候选寄存器类型以及所述目标指令所在簇,对所述目标指令内的操作数进行寄存器分配的具体实现方式进行了说明,该方式可以包括以下步骤:
118.步骤s501:确定目标寄存器文件,所述目标寄存器文件为所述目标指令所在簇内所述候选寄存器类型对应的寄存器文件;
119.寄存器分配可以被分为三个阶段:寄存器类型指派、寄存器簇指派和具体寄存器分配。所述目标指令所在簇的确定即完成了寄存器簇指派,候选寄存器类型的确定即完成了寄存器类型指派。
120.步骤s502:获取所述目标寄存器文件对应的活跃变量列表,所述活跃变量列表用于表征当前存储在所述目标寄存器文件中的变量;
121.算法采用边调度边寄存器分配的方式,即每调度完一条超长指令,就为当前指令中的目的操作数分配具体寄存器。该方式在寄存器分配前并未完成指令调度,也就无法构造完整的寄存器冲突图,不能直接采用图着色算法处理寄存器分配问题。而线性扫描算法恰好按照指令执行的顺序分配寄存器,符合本节中边调度边寄存器分配的特征。因此,本文提出了改进的线性扫描算法,将其扩展到可以并行执行多条指令的vliw架构上。
122.处理器内的多个寄存器文件维护各自的“活跃变量”列表,即当前存储在寄存器文件中的变量。另外,所有寄存器文件还需要共同维护一个变量“活跃周期”列表,用于表示各个变量的定值位置和最后一次引用位置。当变量定值时,将其存储到寄存器;当变量不再被引用时,释放其所处的寄存器。由于在寄存器分配时,并未完成指令调度,无法判断变量实际的“活跃周期”,因此用“待引用次数”列表l
active
替代“活跃周期”列表。
123.变量每被引用1次,需要将l
active
中相应的待引用次数减1。待引用次数为0表明变量不再被引用,即“活跃周期”结束,将变量从l
active
中删除,并释放其所在的寄存器,为接下来的分配匀出更多资源。变量一旦被定值,则被加入到l
active
中,并根据变量的“定值-引用”链,将待引用次数同时加入。
124.步骤s503:基于所述目标寄存器文件对应的活跃变量列表,确定所述目标寄存器文件是否存在可用寄存器;如果存在,则执行步骤s504,如果不存在,则对所述目标寄存器文件进行变量溢出。变量溢出时,可以选择“先进先出”的策略,即先被定值的变量先溢出,或者选择其他策略,比如“后进先出”、“少用先出”等。
125.步骤s504:为所述目标指令内的操作数分配所述目标寄存器文件中的可用寄存器。
126.下面对本技术实施例公开的密码处理器的编译器代码生成装置进行描述,下文描述的密码处理器的编译器代码生成装置与上文描述的密码处理器的编译器代码生成方法可相互对应参照。
127.参照图6,图6为本技术实施例公开的一种密码处理器的编译器代码生成装置结构示意图。如图6所示,该密码处理器的编译器代码生成装置可以包括:
128.获取单元11,用于获取数据流图,所述数据流图对应多个指令;
129.指令筛选单元12,用于从所述数据流图对应的各个指令中,筛选出可调度指令,并确定每个可调度指令的候选簇;
130.簇指派单元13,用于从所述可调度指令中确定预设数量的目标指令,并基于每个目标指令的候选簇确定所述目标指令所在簇;所述预设数量与一条超长指令内指令槽的数量一致;
131.寄存器分配单元14,用于基于所述目标指令内的操作数的候选寄存器类型以及所述目标指令所在簇,对所述目标指令内的操作数进行寄存器分配。
132.参照图7,图7为本技术实施例提供的密码处理器的编译器代码生成设备的硬件结
构框图,参照图7,密码处理器的编译器代码生成设备的硬件结构可以包括:至少一个处理器1,至少一个通信接口2,至少一个存储器3和至少一个通信总线4;
133.在本技术实施例中,处理器1、通信接口2、存储器3、通信总线4的数量为至少一个,且处理器1、通信接口2、存储器3通过通信总线4完成相互间的通信;
134.处理器1可能是一个中央处理器cpu,或者是特定集成电路asic(application specific integrated circuit),或者是被配置成实施本发明实施例的一个或多个集成电路等;
135.存储器3可能包含高速ram存储器,也可能还包括非易失性存储器(non-volatile memory)等,例如至少一个磁盘存储器;
136.其中,存储器存储有程序,处理器可调用存储器存储的程序,所述程序用于:
137.获取数据流图,所述数据流图对应多个指令;
138.从所述数据流图对应的各个指令中,筛选出可调度指令,并确定每个可调度指令的候选簇;
139.从所述可调度指令中确定预设数量的目标指令,并基于每个目标指令的候选簇确定所述目标指令所在簇;所述预设数量与一条超长指令内指令槽的数量一致;
140.基于所述目标指令内的操作数的候选寄存器类型以及所述目标指令所在簇,对所述目标指令内的操作数进行寄存器分配。
141.可选的,所述程序的细化功能和扩展功能可参照上文描述。
142.本技术实施例还提供一种可读存储介质,该可读存储介质可存储有适于处理器执行的程序,所述程序用于:
143.获取数据流图,所述数据流图对应多个指令;
144.从所述数据流图对应的各个指令中,筛选出可调度指令,并确定每个可调度指令的候选簇;
145.从所述可调度指令中确定预设数量的目标指令,并基于每个目标指令的候选簇确定所述目标指令所在簇;所述预设数量与一条超长指令内指令槽的数量一致;
146.基于所述目标指令内的操作数的候选寄存器类型以及所述目标指令所在簇,对所述目标指令内的操作数进行寄存器分配。
147.可选的,所述程序的细化功能和扩展功能可参照上文描述。
148.最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
149.本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
150.对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本技术。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的
一般原理可以在不脱离本技术的精神或范围的情况下,在其它实施例中实现。因此,本技术将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。