技术特征:
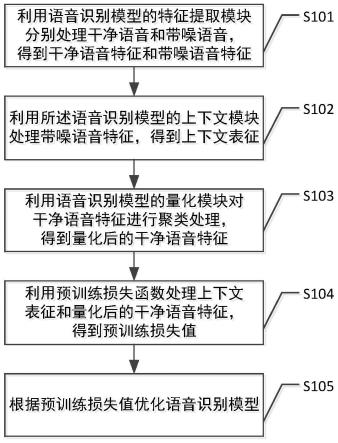
1.一种语音识别模型的训练方法,包括:利用所述语音识别模型的特征提取模块分别处理干净语音和带噪语音,得到干净语音特征和带噪语音特征;利用所述语音识别模型的上下文模块处理所述带噪语音特征,得到上下文表征;利用所述语音识别模型的量化模块对所述干净语音特征进行聚类处理,得到量化后的干净语音特征;利用预训练损失函数处理所述上下文表征和所述量化后的干净语音特征,得到预训练损失值;根据所述预训练损失值优化所述语音识别模型。2.根据权利要求1所述的方法,还包括:利用线性映射层对带标签的带噪语音进行预处理,得到预处理后的带标签的带噪语音;利用所述语音识别模型的特征提取模块处理所述预处理后的带标签的带噪语音,得到带标签的带噪语音特征;利用所述语音识别模型的上下文模块处理所述带标签的带噪语音特征,得到带标签的上下文表征;利用所述微调损失函数处理所述带标签的上下文表征,并根据微调损失值优化所述语音识别模型;迭代进行预训练损失优化和微调损失优化,直到所述预训练损失值和/或所述微调损失值满足预设条件,得到训练完成的语音识别模型。3.根据权利要求1所述的方法,其中,所述特征提取模块采用多层卷积神经网络或多层深度可分离卷积神经网络,所述多层深度可分离卷积神经网络的每一层包括逐通道卷积和逐点卷积;其中,所述上下文模块采用多层转换神经网络,所述多层转换神经网络的每一层包括多个自注意力层和前馈神经网络层;其中,所述量化模块采用乘积量化码本,并通过耿贝尔激活函数进行优化。4.根据权利要求1所述的方法,其中,所述预训练损失函数由对比损失函数、码本多样性损失函数、l2损失函数以及一致性损失函数的加权和确定。5.根据权利要求4所述的方法,其中,所述对比损失函数由公式(1)确定:其中,所述码本多样性损失函数由公式(2)确定:其中,p
g,v
由公式(3)确定:其中,所述一致性损失函数由公式(4)确定:
l
c
=‖z
noisy-z
clean
‖2ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4);其中,z
noisy
表示所述带噪语音特征,z
clean
表示干净语音特征,sim表示余弦相似度,p
g,v
表示选择第g组第v个码本的概率,n
v
和n
k
表示服从高斯分布的、具有不同均值和方差的随机噪声扰动,τ表示非负的温度系数。k表示非负的温度系数,g表示量化码本的个数,v表示量化之后码本向量维度,表示量化之后的、包括正样本特征和负样本特征的所有特征。6.根据权利要求1所述的方法,其中,所述微调损失函数采用连接时序分类损失函数或交叉熵损失函数。7.根据权利要求1所述的方法,其中,所述利用所述语音识别模型的上下文模块处理所述带标签的带噪语音特征,得到带标签的上下文表征包括:将线性映射层接入到所述上下文模块,用于处理所述带标签的带噪语音特征。8.一种语音识别方法,包括:获取待识别的语音;利用语音识别模型处理所述待识别的语音,获取语音识别结果,其中,所述语音识别模型根据权利要求1-7任一所述的方法训练得到。9.一种电子设备,包括:一个或多个处理器;存储装置,用于存储一个或多个程序,其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器执行根据权利要求1~8中任一项所述的方法。10.一种计算机可读存储介质,其上存储有可执行指令,该指令被处理器执行时使处理器执行根据权利要求1~8中任一项所述的方法。
技术总结
本发明公开了一种语音识别模型的训练方法,包括:利用语音识别模型的特征提取模块分别处理干净语音和带噪语音,得到干净语音特征和带噪语音特征;利用语音识别模型的上下文模块处理带噪语音特征,得到上下文表征;利用语音识别模型的量化模块对干净语音特征进行聚类处理,得到量化后的干净语音特征;利用预训练损失函数处理上下文表征和量化后的干净语音特征,得到预训练损失值;根据预训练损失值优化语音识别模型。本发明同时还公开了一种语音识别方法、电子设备以及存储介质。电子设备以及存储介质。电子设备以及存储介质。
技术研发人员:朱秋实 戴礼荣
受保护的技术使用者:中国科学技术大学
技术研发日:2022.03.11
技术公布日:2022/6/4
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。