1.本发明属于模式识别与计算机视觉中无监督图像嵌入学习领域,具体的说是涉及了一种基于最近邻与困难样本挖掘的无监督图像嵌入学习方法。
背景技术:
2.深度神经网络由于其强大的视觉特征学习能力,已经被用作许多计算机视觉任务的基本结构,如目标检测,人脸识别,图像检索,行人重识别等等。深度神经网络的性能在很大程度上取决于其自身能力和训练数据量。为了增加网络模型的容量,科研人员开发了不同种类的网络体系结构,同时,像imagenet等大规模数据集也已经被收集并用来训练非常深的神经网络。凭借复杂的体系结构和大规模数据集,深度卷积神经网络的性能不断地突破计算机视觉任务的最先进水平。
3.深度嵌入学习旨在利用深度神经网络从图像中学习一种具有判别性的低维嵌入特征,这种嵌入特征具有两种属性:1)正集中:属于同一类别的样本的嵌入特征应当彼此靠近;2)负分离:属于不同类别的样本的嵌入特征应当尽可能的彼此远离。深度嵌入学习具有许多广泛且重要的应用,如图像检索,人脸识别,目标跟踪,行人重识别等等。然而,为不同的任务收集和标注数据集是一项耗时且昂贵的工程。作为计算机视觉最广泛使用的数据集之一,imagenet包含覆盖1000个类别的大约130万个标记图像,而每个图像由人工用一个类标签标记。在对如此大规模数据集收集和标注时,耗费了许多工作人员的大量时间。尤其对于大规模细粒度数据集的标注,往往更需要领域内的专家才能完成。因此,以无监督的方式直接、自动地从图像中学习特征是一项非常重要而又富有挑战性的任务,且已经成为机器学习和计算机视觉领域的研究热点。
4.无监督嵌入学习要求学习到的嵌入特征之间的相似性与输入样本的视觉相似性或类别关系保持一致。相比之下,广泛研究的无监督特征学习旨在使用不同的监督信号来学习良好的“中间”特征表示,通过学习一个线性分类器或者目标检测器,将其学习到的特征推广到下游任务,其中目标任务仍然需要有标注的样本。然而,学习到的特征可能无法保持视觉相似性,因此对于基于视觉相似性的任务,其性能显著的下降,如最近邻搜索。
技术实现要素:
5.为了解决上述问题,本发明提出了一种记忆最近邻与困难样本挖掘的无监督图像嵌入学习方法,该方法利用深度神经网络对图像提取特征,然后根据特征之间的余弦相似性,挖掘样本的最近邻域,从而将图像分为若干个邻域,邻域内的样本图像共享伪类别信息,使得模型能够学习到图像的高判别性特征。
6.为了达到上述目的,本发明是通过以下技术方案实现的:
7.本发明是一种基于最近邻与困难样本挖掘的无监督图像嵌入学习方法,包括如下步骤:
8.步骤1:搭建基于pytorch的深度学习框架运行环境,包含numpy、scipy等第三方运
行库;
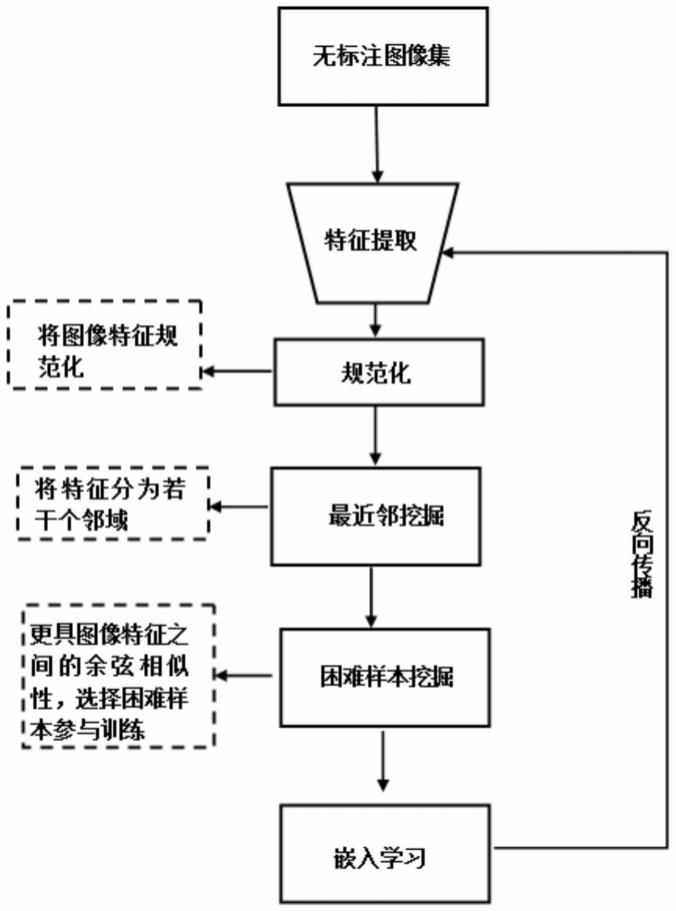
9.步骤2:在步骤1搭建好的深度学习框架运行环境下搭建执行无监督嵌入学习任务的网络模型,所述网络模型主要包含五个模块:特征提取模块,规范化模块,最近邻挖掘模块,困难样本挖掘模块,嵌入学习模块。
10.所述特征提取模块采用在imagenet上预训练过的googlenet网络作为特征提取器,在googlenet的第五个池化层之后增加一个128维到的全连接层作为特征嵌入层,在提取特征的过程中,将无监督嵌入学习任务给定的数据集里的训练图像随机裁剪为227
×
227来进行数据增强。
11.规范化模块连接在特征提取器末端,提取无监督嵌入学习任务给定的数据集里的图像特征,所述规范化模块将特征提取模块提取到的图像特征的深度特征向量的每个元素除以向量的模进行规范化,将深度特征规范成模为1的向量,便于优化网络参数。
12.将这些规范后的深度特征向量输入到最近邻挖掘模块,形成若干个邻域,邻域内的样本共享类别信息,并为每个样本分配一个类别标签。
13.根据挖掘到的样本特征,在嵌入学习模块,对每个样本特征,将其与同类样本特征拉近,并将其与其他类样本特征远离,也就是说嵌入学习模块将困难样本挖掘模块困难正负样本结合为一体进行优化,更新网络参数,使得模型学习到高判别性图像特征;
14.步骤3:使用数据集通过端到端的方式对步骤2的网络进行训练:将所有图像随机裁剪为227
×
227来进行数据增强,使用0.9动量的sgd优化器并将权重衰减设置为5*10^-4,直到网络参数达到最优状态停止训练。
15.步骤4:各项权重参数训练达到最优之后,要输入全新的图像对模型进行测试,即在测试阶段,将从未出现过的测试图像进行中心裁剪之后作为输入,根据特征的余弦相似性检索到与测试图像相似性最小的图像,检索到的图像若与输入的测试图像属于同一类,则为检索成功,反之失败。
16.本发明的进一步改进在于:训练所采用的数据集包括cub200和cars196。
17.cub200数据集是美国加州理工学院于2011年发布的一个包含200种鸟类照片的细粒度图像数据集,该数据集共有11788张鸟类图像,每张图像均提供了图像类标记信息。其中前100个类别的5864张图像用来训练,其余100个类别的5924张图像用来测试。因此,训练图像类别与测试图像类别是完全不同的。
18.cars196是美国斯坦福大学于2013年发布的一个包含196种汽车类,共计16185张图像的细粒度图像数据集,每张图像均提供了图像类标记信息。其中前98个类别的8054张图像用来训练,其余98个类别的8131张图像用来测试。同样,训练图像类别与测试图像类别也是完全不同的。
19.本发明的有益效果是:该方法利用深度神经网络对图像提取特征,然后根据特征之间的余弦相似性,挖掘样本的最近邻域,从而将图像分为若干个邻域,邻域内的样本图像共享伪类别信息,为了能够使模型快速收敛,使用困难样本挖掘策略来选择更有价值和意义的样本,为了达到正集中和负分离的目的,对每个样本,让其在特征空间中靠近同类样本的特征,并远离其他类样本特征,通过优化目标函数来调整网络模型,使得模型能够学习到图像的高判别性特征。
附图说明
20.图1是本发明无监督图像嵌入学习方法的流程图。
具体实施方式
21.以下将以图式揭露本发明的实施方式,为明确说明起见,许多实务上的细节将在以下叙述中一并说明。然而,应了解到,这些实务上的细节不应用以限制本发明。也就是说,在本发明的部分实施方式中,这些实务上的细节是非必要的。
22.如图1所示,进行基于最近邻挖掘与困难样本挖掘的无监督图像嵌入学习方法时,首先搭建基于pytorch的深度学习框架运行环境,包含numpy、scipy等第三方运行库,在搭建好的深度学习框架运行环境下搭建执行无监督嵌入学习任务的网络模型,所述网络模型主要包含五个模块:特征提取模块,规范化模块,最近邻挖掘模块,困难样本挖掘模块,嵌入学习模块。
23.所述特征提取模块采用在imagenet上预训练过的googlenet网络作为特征提取器,在googlenet的第五个池化层之后增加一个128维到的全连接层作为特征嵌入层,在提取特征的过程中,将无监督嵌入学习任务给定的数据集里的训练图像随机裁剪为227
×
227来进行数据增强。
24.规范化模块将网络提取的特征向量归一化,使得向量的模为1。具体来说,对于一组无标注图像集x={x1,x2,
…
,xn},神经网络f
θ
(.)输出每个图像的嵌入特征f
θ
(xi)∈r
l
,其中θ是网络参数,l是特征维度。因此,规范化后的特征记为:
[0025][0026]
得到规范化后的特征之后,将其输入到最近邻挖掘模块中。具体为:第一步,在嵌入空间r
l
中任选一个特征f作为目标特征,第二步,在其余样本特征中找到目标样本特征的最近邻样本特征集nk,其表示为:
[0027]
nk(f)={fi|s(fi,f)is ranked top-k in f}(2)
[0028]
其中f是模型提取的所有训练样本特征集合,s表示特征向量的余弦相似性函数,最近邻代表与目标样本有着相同语义信息的样本。但是,在没有标签的情况下目标样本中的最近邻很大程度上会有噪声样本,因此直接用最近邻nk进行监督训练,噪声会使模型发生不稳定。因此,利用图理论,本发明从一个随机特征点fr开始,基于边构造一个树状结构。然后采用深度优先搜索策略沿边遍历特征。利用深度优先搜索策略优先访问相似度大的特征。为了避免重复遍历特征,本发明限制每个特征只能访问一次。为了确保任意两个特征的可达性,本发明实施了循环约束,即在树状结构中,一个循环必须要回到起始特征。在搜索过程中,目标是找到互不相交的循环结构。因此,本发明从特征集中删除已找到的循环中的所有特征,以简化和加速搜索。此过程重复进行,直到不存在循环为止。值得注意的是,最后可能会留下一些孤立的特征。这些循环结构可以看成邻域,邻域内的样本共享类别信息,并分配伪标签。
[0029]
为了能够使模型加快收敛,本发明在又增加了困难样本挖掘模块来进一步提高性能。在困难样本挖掘模块中,根据伪标签,利用样本特征的余弦相似性来挖掘困难样本。对于目标样本xi,通过以下方式获得它的困难负样本,即:
[0030]sij
≥min{s
ik
|yk=yi}-∈,yj≠yi[0031]
其中,s
ij
是两个样本之间的余弦相似性,∈是一个给定的余量。将挖掘到的困难负样本放入到ni中;同样,通过以下公式来挖掘困难正样本,即:
[0032]sit
≤max{s
ik
|yk≠yi}-∈,y
t
=yi[0033]
将挖掘到的困难正样本放入到pi中。
[0034]
在嵌入学习模块中,为了能够达到样本特征在空间中正集中和负分离的目的,本发明引入了如下的损失函数,该损失函数将挖掘到的困难正负样本结合为一个整体,同时度量目标样本与困难正负样本之间的余弦相似性,并且利用超参数平衡了正负样本所占的权重,即:
[0035][0036]
其中,m是训练批次,参数p和q用来平衡正负样本的权重,μ是一个固定值。网络参数通过随机梯度下降法更新,即:
[0037][0038]
其中α为学习率或者步长。
[0039]
步骤3:使用数据集通过端到端的方式对步骤2的网络进行训练:将所有图像随机裁剪为227
×
227来进行数据增强,使用0.9动量的sgd优化器并将权重衰减设置为5*10^-4,直到网络参数达到最优状态停止训练。
[0040]
步骤4:当模型训练完毕后,要输入全新的图像对模型进行测试,即在测试阶段,将从未出现过的测试图像进行中心裁剪之后作为输入,根据特征的余弦相似性检索到与测试图像相似性最小的图像,检索到的图像若与输入的测试图像属于同一类,则为检索成功,反之失败。
[0041]
以上所述仅为本发明的实施方式而已,并不用于限制本发明。对于本领域技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原理的内所作的任何修改、等同替换、改进等,均应包括在本发明的权利要求范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
