1.本发明涉及人工智能领域,尤其涉及自然语言处理领域,具体来说是一种针对中文文本分类任务的字符级对抗样本生成方法。
技术背景
2.在文本领域中,大量的文本数据被用来进行各种分析。在利用文本数据进行相关任务时,都需要使用对抗样本进行模型鲁棒性检测或数据增强。同时为向训练数据中添加对抗样本,可以提高模型鲁棒性。
3.在目前的对抗样本生成方法中,都存在扰动幅度较大,容易被模型识别的问题,使得对抗样本没有发挥最好的性能。如何生成高质量的对抗样本,最大程度不被模型识别是至关重要的,也是本发明要解决的问题。
技术实现要素:
4.针对上述问题,本发明通过深入挖掘文本特征信息,利用汉字本身特点,生成高质量的对抗样本,为各类有对抗样本数据需求的任务提供技术支持。
5.本发明提供了一种针对中文文本分类任务的字符级对抗样本生成方法。
6.本发明所述的一种航空旅客付费选座意愿画像及分析的方法,其特征在于包含以下步骤:
7.a)数据获取及存储:从众多网络评论中获取原始数据,并进行存储。
8.b)多音字字典构建:根据所述原始数据,构建多音字字典。
9.所述多音字字典表示为同时包含字符和读音之间关系的字典,用四元组(w,x,y,i)描述。
10.其中,w是多音字的中文表示,x是w的拼音表述,y是w的具体含义,i表示w的第i个读音,i∈[1,7]。
[0011]
c)多音字字典标注:根据所述多音字字典格式,进行标注,确定所述多音字字典中每个字的四元组(w,x,y,i)具体值。
[0012]
d)对抗样本生成:将所述原始样本作为输入,利用构建的所述多音字字典中的数据,在所述原始数据中进行全局匹配,找到w相同的字,进行替换操作,得到与原文字形相同但字音不同的对抗样本。
[0013]
本发明所述的一种航空旅客付费选座意愿画像及分析的方法,其特征在于:
[0014]
在[0007]行中,所述原始数据包括结构化数据和非结构化数据。
[0015]
本发明所述的一种针对中文文本分类任务的字符级对抗样本生成方法,其特征在于:
[0016]
将所述对抗样本输入至目标判别模型,得到所述目标判别模型输出的所述样本的判断类别;
[0017]
根据所述判断类别,得到当前判断与所述原始数据类别之间的差异,得到扰动值,
并将所述扰动返回至所述对抗样本生成过程。其中,所述目标判断类别与所述原始类别为不同。
[0018]
由于采用上述技术方案,本发明通过深入挖掘文本特征信息,利用中文多音字信息,生成高质量的对抗样本。
[0019]
应当理解,本部分所描述的内容并非旨在标识本公开的实施例的关键或重要特征,也不用于限制本发明的范围。本发明的其它特征将通过以下的说明书而变得容易理解。
附图说明
[0020]
附图用于更好地理解本方案,不构成对本发明的限定。其中:
[0021]
图1是一种针对中文文本分类任务的字符级对抗样本生成方法的替换向量描述图
具体实施方式
[0022]
下面结合附图说明,帮助理解本发明的发明内容。
[0023]
本发明所述一种航空旅客付费选座意愿画像及分析的方法,包含以下步骤:
[0024]
a)数据获取及存储:从众多网络评论中获取原始数据,并进行存储。该步骤包括从各大网站平台抓取数据,包括但不限于,小红书中的观点评论、淘宝中的顾客评论、微博中的事件评论等结构化和非结构化数据信息,对获取的数据进行数据清洗,再进行存储。
[0025]
b)多音字字典构建:根据所述原始数据,构建多音字字典。
[0026]
所述多音字字典表示为同时包含字符和读音之间关系的字典,用四元组(w,x,y,i)描述。
[0027]
其中,w是多音字的中文表示,x是w的拼音表述,y是w的具体含义,i表示w的第i个读音,i∈[1,7]。
[0028]
c)多音字字典构建标注:根据所述多音字字典格式,进行构建标注,确定所述多音字字典中每个字的四元组(w,x,y,i)具体值。
[0029]
针对多音字字典,标注信息需要对拼音以及数据之间信息进行计算,计算方法如下:
[0030]
在读音与字义之间的联系,对应于归类任务,采用点互信息pmi算法来完成,pmi可以较为准确地衡量读音与字义的相关性,其计算如下所示:
[0031][0032]
其中,x表示多音字w的拼音表示,y表示多音字w的具体含义。若x与y无关,则p(x,y)=p(x)p(y),表示该读音没有此含义;若x与y相关,则p(x,y)和p(x)p(y)的比值就会越大,表示该读音有此含义。
[0033]
通过pmi算法,将多音字的拼音与具体含义进行归类联系。
[0034]
设多音字wi的含义集合为wi={w1,w2,w3,
…
,w
l
},则构建的《拼音-含义》集合w为:
[0035]
[0036]
其中,w
ij
表示单词wi的第i个读音与对应的含义组成的《拼音-含义》集合,其中i∈[1,7],n∈[1,7],并且每个多音字的不同读音可能有多个含义。
[0037]
根据得到的《拼音-含义》集合w,基于定义,可以得到所构建的多音字字典,其中包含的信息如前所述。
[0038]
所述多音字字典构建详细算法步骤如下所述:
[0039]
1.输入信息有包含多音字字符{wi}、读音{xi}和字义{yi}的多音字集合d,空字典di,阈值σ
[0040]
2.输出信息为目标多音字字典di
[0041]
3.初始化多音字字典d,di
[0042]
4.当{wi},{xi},{yi}都在d中时
[0043]
5.满足i∈[1,7]时
[0044]
6.计算x和y之间的pim值
[0045]
7.如果pim值大于阈值σ
[0046]
8.则将(xi,yi)加入到di中
[0047]
9.否则输出“x与y不匹配不能加入字典di中”[0048]
10.等待循环结束
[0049]
11.最终输出目标字典di
[0050]
d)对抗样本生成:对抗样本生成具体包括下述详细步骤。结合附图进行细节阐述。
[0051]
首先进行扰动定位,判断替换词位置。
[0052]
对输入样本w进行分词得到w=[w1,w2,w3,w4,
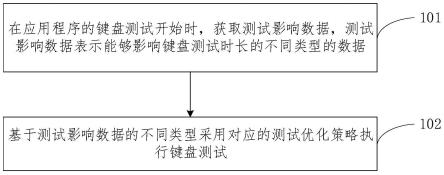
…
,wn],其中n表示输入样本的字符长度,再将输入样本进行拼音化处理,通过与构建的多音字字典中进行比对,找到输入样本中全部的多音字位置,对序列w中的第i个多音字,计算整个样本和删除该字之后样本的输入分数差值:
[0053]
tds(wi)=f(w1,
…
,w
i-1
,wi,w
i 1
,
…
,wn)-f(w1,
…
,w
i-1
,w
i 1
,
…
,wn)
[0054]
附图1详细描述了本发明通过矩阵变换得到不同含义且不同读音的同形字形式化流程,具体描述如下:
[0055]
句子由[x1,x2,
…
,x
t
]等t个汉字组成,对其进行汉克尔矩阵化操作,变形为[x1,x2,
…
,x
t
]
[0056]
其中,xi表示为汉字对应的矩阵形式。
[0057]
通过本发明内容,对含有多音字的汉字执行替换操作,即附图1中所述红色框处的0变为1,得到改变后的矩阵mi,即可得到更新后的x
new
。
[0058]
所述对抗样本生成详细算法步骤如下所述:
[0059]
输入信息为多音字字典di,文本x=[x1,x2,x3,
…
,xn],评分机制tds,转换函数t,阈值λ
[0060]
输出目标是对抗样本x'
[0061]
1.对文本进行分词向量化x=[x1,x2,x3,
…
,xn]
[0062]
2.对x在x中时
[0063]
3.同时i在1-n范围中时
[0064]
4.i的得分score=tds(xi)
[0065]
5.进行得分判断,若分数大于λ
[0066]
6.输出标签为yes
[0067]
7否则为no
[0068]
8.从di中选择合适的x
[0069]
9.将x'的索引值等价于t(x
indexi
)
[0070]
10.返回最终目标x'
[0071]
应该理解,可以使用上面所示的各种形式的流程,重新排序、增加或删除步骤。例如,本发公开中记载的各步骤可以并行地执行也可以顺序地执行也可以不同的次序执行,只要能够实现本公开公开的技术方案所期望的结果,本文在此不进行限制。
[0072]
上述具体实施方式,并不构成对本公开保护范围的限制。本领域技术人员应该明白的是,根据设计要求和其他因素,可以进行各种修改、组合、子组合和替代。任何在本公开的精神和原则之内所作的修改、等同替换和改进等,均应包含在本公开保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。