基于gcn和集成学习预测潜在关联的环状rna-疾病对的方法
技术领域
1.本发明涉及生物信息计算领域,特别是利用计算模型预测潜在环状rna-疾病对关联性的领域。
背景技术:
2.环状rna是一类闭环结构的rna分子,随着高通量测序技术的发展,人们通过实验发现了大量的环状rna,因此环状rna犹如rna界的一颗“新星”,受到越来越多的人关注。
3.环状rna的结构特点使环状rna具有稳定性以及在人的外泌体中富集的特点,此外其还具有进化保守性,半衰期长,组织特异性等特点。
4.已有的研究表明环状rna与疾病的发生发展关联密切,而环状rna的特点使得它成为疾病诊断过程中一种理想的标志物。
5.虽然目前的研究已经证实了部分环状rna-疾病关联对,但是由于环状rna和疾病种类均很庞大,以至于还有很多未被人们发现、但是对人们的健康至关重要的环状rna-疾病关联对。
6.目前通过生物实验去寻找并证实这些关联对是耗费人力物力的,因此有必要通过构建有效的计算模型预测潜在关联的环状rna-疾病对,从而促进相关生物实验的研究,帮助更多的患者和家庭。
7.目前预测环状rna-疾病关联对的方法大致可以分为两类。一类是基于半监督的方法,直接通过实验证实的环状rna-疾病关联对和其余的环状rna-疾病对以及相应的环状rna间的相似性信息和疾病的相似性信息对所有环状rna-疾病对做出关联性预测。
8.另一类是基于监督模型的方法,首先构建一个正负样本平衡的数据集,因为目前没有实验证实无关的环状rna-疾病对,所以大多通过随机抽取的方式从未验证的环状rna-疾病对中抽取一定数量的环状rna-疾病对作为负样本。其次,利用此数据集训练模型,并用训练好的模型对未验证的环状rna-疾病对做出关联性预测。
9.同时,对于已有的研究还存在以下一些不足:首先,部分模型不能对于新节点进行预测,如一种疾病没有一种实验证实与之相关联的环状rna;其次,通过随机抽取的方式获取负样本的方法,具有一定的随机性,可能对模型效果产生一定的偏差;最后,目前越来越多的人将深度学习的方法应用于此领域的研究,但是有关于环状rna-疾病对的数据却一直停留在最初研究的数据集上。
技术实现要素:
10.本发明的目的在于一种计算模型预测潜在关联的环状rna-疾病对,为相关生物实验提供最有可能的环状rna-疾病对,从而促进人们对疾病相关机制的理解。
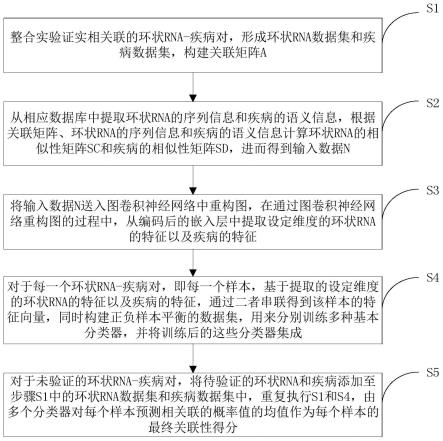
11.为此,本发明提供了一种基于图卷积神经网络和集成学习预测潜在关联的环状rna-疾病对的方法,包括:s1、整合实验证实相关联的环状rna-疾病对,形成环状rna数据集和疾病数据集,构建关联矩阵a;s2、从相应数据库中提取环状rna的序列信息和疾病的语义
信息,根据关联矩阵、环状rna的序列信息和疾病的语义信息计算环状rna的相似性矩阵sc和疾病的相似性矩阵sd,进而得到输入数据n,其中,s3、将输入数据n送入图卷积神经网络中重构图,在通过图卷积神经网络重构图的过程中,从编码后的嵌入层中提取设定维度的环状rna的特征以及疾病的特征;s4、对于每一个环状rna-疾病对,即每一个样本,基于提取的设定维度的环状rna的特征以及疾病的特征,通过二者串联得到该样本的特征向量,同时构建正负样本平衡的数据集,用来分别训练多种基本分类器,并将训练后的这些分类器利用集成学习中的平均法进行集成;s5、对于未验证的环状rna-疾病对,将待验证的环状rna和疾病添加至步骤s1中的环状rna数据集和疾病数据集中,重复执行s1和s4,进而更新关联矩阵、输入数据n和特征向量,最后由多个分类器对每个样本预测相关联的概率值的均值作为每个样本的最终关联性得分。
12.本发明的有益效果是:
13.(1)整合了更多的环状rna-疾病对相关数据用于模型的训练,为利用深度学习算法提供充分数据。
14.(2)基于环状rna-疾病对信息,环状rna的相似性信息以及疾病间的相似性信息,使用卷积神经网络从中提取环状rna间的特征以及疾病间的特征。
15.(3)使用集成学习的方法进一步提高预测潜在关联环状rna-疾病对模型的性能,为同类型的关联性预测如lncrna-疾病,mirna-疾病以及药物重定位等相关联性预测提供一定的指导意义。
16.(4)本模型对于新节点可以做出预测,且通过100次五折交叉验证消除随机抽取负样本对性能产生较大影响的可能性。
17.除了上面所描述的目的、特征和优点之外,本发明还有其它的目的、特征和优点。下面将参照图,对本发明作进一步详细的说明。
附图说明
18.构成本技术的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
19.图1是本发明基于图卷积神经网络和集成学习预测潜在关联的环状rna-疾病对的方法的流程图;以及
20.图2是本发明基于图卷积神经网络和集成学习预测潜在关联的环状rna-疾病对的方法的原理框图。
具体实施方式
21.下面将参考附图并结合实施例来详细说明本发明。
22.为了克服目前技术的缺点,本发明提出一种基于图卷积神经网络和集成学习预测环状rna-疾病对的方法,首先整合已有的环状rna-疾病关联对信息并构建相应的特征,为接下来的深度学习方法的使用构建充分的数据。其次,利用深度学习中图卷积神经网络算法提取特征,最终训练基本分类器,并利用集成的方法对这些分类器进行集成,最终用其预测所有的环状rna-疾病对的关联性。
23.请参阅图1,本发明的基于图卷积神经网络和集成学习预测潜在关联的环状rna-疾病对的方法,包括以下步骤:
24.s1、整合实验证实相关联的环状rna-疾病对,形成环状rna数据集和疾病数据集,构建关联矩阵a;
25.s2、从相应数据库中提取环状rna的序列信息和疾病的语义信息,根据关联矩阵、环状rna的序列信息和疾病的语义信息计算环状rna的相似性矩阵sc和疾病的相似性矩阵sd,进而得到输入数据n,其中,
26.s3、将输入数据n送入图卷积神经网络中重构图,在通过图卷积神经网络重构图的过程中,从编码后的嵌入层中提取设定维度的环状rna的特征以及疾病的特征;
27.s4、对于每一个环状rna-疾病对,即每一个样本,基于提取的设定维度的环状rna的特征以及疾病的特征,通过二者串联得到该样本的特征向量,同时构建正负样本平衡的数据集,用来分别训练多种基本分类器,并将训练后的这些分类器利用集成学习中的平均法进行集成;
28.s5、对于未验证的环状rna-疾病对,将待验证的环状rna和疾病添加至步骤s1中的环状rna数据集和疾病数据集中,重复执行s2和s4,进而更新关联矩阵、输入数据n和特征向量,最后由多个分类器对每个样本预测相关联的概率值的均值作为每个样本的最终关联性得分。
29.在步骤s1中,优选地,从数据库circr2disease,circ2disease以及circrnadisease中获取环状rna-疾病关联对数据,并从数据库circbase中获取环状rna的序列信息,从数据库disease ontology中获取相关疾病的语义信息。
30.根据整合后的关联信息构建关联矩阵a,n和m分别表示环状rna和疾病的个数。则关联性矩阵a由n行m列构成,分别表示n种环状rna和m种疾病,矩阵中的每一个值分别对应一个环状rna-疾病对的关联性,实验证实相关联的环状rna-疾病对对应于矩阵a中的值为1,其余为0。即如果实验已经证实第i种环状rna与第j种疾病相关联,则矩阵a中的第i行第j列的值为1。
31.在步骤s2中,分别使用以下方法得到环状rna间的相似性以及疾病间的相似性:
32.s201:根据关联矩阵分别计算相应的环状rna间的高斯相似性以及疾病间的高斯相似性。
33.s202:根据关联对中涉及的环状rna从数据库circbase中提取序列信息,并利用levenshtein距离算法计算任意两个环状rna间的序列相似性。
34.s203:根据关联对中涉及的疾病从数据库disease ontology中获取疾病的doid信息,并计算疾病间的语义相似性。
35.s204:分别对环状rna的序列相似性和高斯相似性,疾病的语义相似性和高斯相似性进行融合,并得到融合后的环状rna的相似性以及疾病的相似性。
36.在步骤s201中,关联矩阵、环状rna间的高斯相似性、疾病间的高斯相似性,并分别命名为a,kc,kd,其具体计算公式如下所示。
37.kc(ci,cj)=exp(-βc||ip(ci)-ip(cj)||2);
38.kd(di,dj)=exp(-βd||ip(di)-ip(dj)||2);
39.其中,ip(ci)表示关联矩阵a中第i行数据,即环状rna ci与所有疾病间的关联关系,ip(cj)同理。ip(di)表示关联矩阵a中第i列数据,即疾病di与所有环状rna间的关联关系,ip(dj)同理。而βc和βd分别表示内核带宽,计算公式如下所示。
[0040][0041][0042]
其中,n和m分别表示环状rna和疾病的个数。β
′c和β
′d分别表示初始带宽,其值均设置为1。
[0043]
在步骤s202中,任意两个环状rna间的序列相似性,并将其命名为cc,具有计算公式如下所示。
[0044][0045]
其中,ci和cj分别表示两种环状rna,len(ci)表示环状ci的序列长度,dis(ci,cj)表示环状rna ci转换成环状rna cj序列所需要的编辑距离,其主要基于levenshtein距离算法计算。
[0046]
在步骤s203中,根据关联对中涉及的疾病从数据库disease ontology中获取疾病的doid信息,并计算疾病间的语义相似性,并将其命名为dd。
[0047]
对于得到的疾病的doid信息,通过r包“dose”(参见余光创等人在《生物信息学期刊》(bioinformatics 2015,31(4):608-609)上发表的论文《用于疾病本体语义和富集分析的r包》(dose:an r/bioconductor package for disease ontology semantic and enrichment analysis)),利用其中的函数“dosim”和“wang”的方法计算疾病间的相似性,具体公式如下:
[0048][0049]
其中,t
di
表示第i种疾病所有的祖先节点,s
di
(t)表示t
di
中疾病对第i种疾病的贡献值,具体公式如下:
[0050][0051]
其中,we为语义贡献因子,值为1。
[0052]
在步骤s204中,分别对环状rna的序列相似性和高斯相似性,疾病的语义相似性和高斯相似性进行融合,并得到融合后的环状rna的相似性以及疾病的相似性,并将其命名为sc,sd,具体计算公式如下所示。
[0053]
sc=a*cc (1-a)*kc;
[0054]
sd=b*dd (1-b)*kd;
[0055]
其中,a,b分别相似性融合参数,此处均设置为0.8。
[0056]
根据处理好的环状rna间的相似性,疾病间的相似性以及环状rna-疾病关联对信
息便可构建相应的图,并利用图卷积网络从中提取环状rna的特征以及疾病的特征。
[0057]
所提取的新的特征的维度是基于整个模型的性能,在众多实验后选取维度值并将其设置为32。
[0058]
步骤s3包括以下步骤:
[0059]
s301:根据已知的环状rna-疾病对,环状rna间的相似性以及疾病间的相似性构建图。
[0060]
s302:利用图卷积神经网络重构图,并从其中的嵌入层获取环状rna的特征以及疾病的特征。
[0061]
在步骤s301中,根据已知的环状rna-疾病对,环状rna间的相似性以及疾病间的相似性构建图,构建方式如下所示。
[0062][0063]
其中,a
t
为关联矩阵a的倒置,将n作为输入数据送入图卷积神经网络中,其主要由编码器和解码器组成,其中编码器主要通过如下公式实现。
[0064][0065]
在步骤s302中,在通过图卷积神经网络重构图的过程中,选择二元交叉熵损失函数作为损失函数其公式如下所示,并最终从编码后的嵌入层中提取环状rna的特征以及疾病的特征。
[0066][0067]
在得到环状rna的特征以及疾病的特征后,便可根据构建的正负样本平衡的数据集以及相应的样本特征训练分类器,并集成这些分类器对所有未验证的样本预测关联性得分。
[0068]
具体地,步骤s4包括以下步骤:
[0069]
s401:通过随机抽取负样本的方式从未验证的环状rna-疾病对中抽取与正样本数量一致的样本作为负样本,从而构建正负样本平衡的数据集,并用其训练四个基本分类器。
[0070]
s402:通过集成学习中的平均法对此这些训练好的分类器集成,并对所有未验证的样本预测关联性得分。
[0071]
在步骤s401中,首先通过随机抽取的方式从所有未验证的样本中获取正样本数量一致的负样本,从而构建一个正负样本平衡的数据集。利用此数据集,分别训练随机森林(random forest,简称rf)分类器,梯度提升决策树(gradient boosting decision tree,简称gbdt)分类器,极限树(extra trees,简称et)分类器以及xgboost分类器。
[0072]
在步骤s402中,通过集成学习中的平均法对此写些训练好的分类器集成,具体集成方式如下所示。
[0073][0074]
其中w1,w2,w3,w4分别为每个分类器的权重,此处均为0.25,而对应四种分类器。
[0075]
此外,通过五折交叉验证(ffcv)评估模型的性能,为了消除随机抽取的负样本对模型性能的影响,所以对ffcv重复执行了100次,每一次均是随机抽取负样本,其100下auc
的均值为0.897,标准差为0.007。其中一次ffcv下在各评估指标下的结果如下表所示。
[0076]
表1 ffcv下模型在各评估指标下的值
[0077][0078]
其中,acc表示准确率,specificity表示特异性,precision表示查准率,recall表示查全率,auc表示ffcv下roc曲线下的面积,f1为查准率和查全率的调和平均数。
[0079]
在步骤s5中,对于一种疾病d,利用本模型预测最有可能与此疾病相关联的环状rna。如果疾病d不在整合的数据集中,首先在数据库disease ontology中查询相应的doid信息,并计算出此疾病与数据集中涉及的其余的所有疾病的语义相似性。并加入到疾病间的相似性矩阵中,并更新关联矩阵a。
[0080]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。