技术特征:
1.一种三维脸部表情生成模型的训练方法,所述方法包括:获取音频信号样本中的帧信号样本对应的音频特征样本;获取所述帧信号样本对应的音素特征样本;通过所述三维脸部表情生成模型处理所述音频特征样本和所述音素特征样本,得到所述帧信号样本对应的脸部表情系数预测值;基于所述脸部表情系数预测值与所述帧信号样本对应的脸部表情系数标签的差异,调整所述三维脸部表情生成模型的参数。2.如权利要求1所述的方法,所述方法还包括:通过所述三维脸部表情生成模型处理所述音频特征样本和所述音素特征样本,得到所述帧信号样本对应的融合特征样本或者第一音频特征样本;通过身份识别网络处理所述融合特征样本或者所述第一音频特征样本,得到所述帧信号样本对应的身份预测值;基于所述身份预测值与所述帧信号样本对应的身份标签的差异,调整所述三维脸部表情生成模型的参数。3.如权利要求1所述的方法,所述三维脸部表情生成模型包括特征融合网络和表情系数生成网络;所述通过所述三维脸部表情生成模型处理所述音频特征样本和所述音素特征样本,得到所述帧信号样本对应的脸部表情系数预测值包括:通过所述特征融合网络处理所述音频特征样本和所述音素特征样本,得到所述帧信号样本对应的融合特征样本;通过所述表情系数生成网络处理所述融合特征样本,得到所述帧信号样本对应的脸部表情系数预测值。4.如权利要求2所述的方法,所述特征融合网络包括一个或多个第一特征提取单元和一个或多个第二特征提取单元;所述通过所述特征融合网络处理所述音频特征样本和所述音素特征样本,得到所述帧信号样本对应的所述融合特征样本包括:通过所述一个或多个第一特征提取单元处理所述音频特征样本,得到所述一个或多个第一特征提取单元对应的一个或多个第一音频特征样本;通过所述一个或多个第二特征提取单元处理所述音素特征样本和所述一个或多个第一音频特征样本,得到所述帧信号样本对应的所述融合特征样本。5.一种三维脸部表情生成模型的训练方法,所述方法包括:获取音频信号样本中的帧信号样本对应的音频特征样本;获取所述帧信号样本对应的音素特征样本;基于所述音频特征样本和所述音素特征样本,通过特征融合网络和表情系数生成网络得到所述帧信号样本对应的脸部表情系数预测值;所述三维脸部表情生成模型包括所述特征融合网络和所述表情系数生成网络;基于所述音频特征样本和所述音素特征样本,通过特征融合网络和身份识别网络得到所述帧信号样本对应的身份预测值;基于所述脸部表情系数预测值与所述帧信号样本对应的脸部表情系数标签的差异、所述身份预测值与所述帧信号样本对应的身份标签的差异,调整所述三维脸部表情生成模型
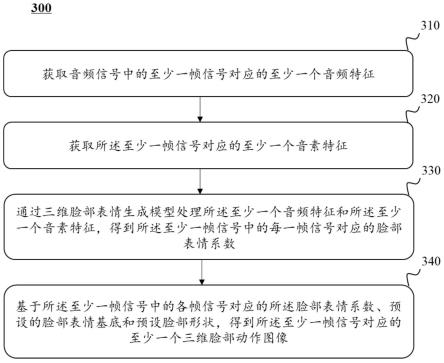
的参数。6.一种三维脸部动作生成方法,包括:获取音频信号中的至少一帧信号对应的至少一个音频特征;获取所述至少一帧信号对应的至少一个音素特征;通过三维脸部表情生成模型处理所述至少一个音频特征和所述至少一个音素特征,得到所述至少一帧信号中的每一帧信号对应的脸部表情系数;基于所述至少一帧信号中的各帧信号对应的所述脸部表情系数、预设的脸部表情基底和预设脸部形状,得到所述至少一帧信号对应的至少一个三维脸部动作图像。7.如权利要求6所述的方法,所述获取音频信号中至少一帧信号对应的至少一个音频特征包括:获取所述至少一帧信号对应的至少一个窗口信号,其中一帧信号对应的窗口信号包括所述一帧信号所在的预设长度的音频信号;基于所述至少一个窗口信号,获取所述至少一个音频特征。8.如权利要求6所述的方法,所述获取音频信号中至少一帧信号对应的至少一个音频特征包括:获取所述至少一帧信号对应的至少一个窗口信号,其中一帧信号对应的窗口信号包括所述一帧信号所在的预设长度的音频信号;基于所述至少一个窗口信号,获取所述至少一个音素特征。9.如权利要求6所述的方法,所述三维脸部表情生成模型包括卷积神经网络模型。10.如权利要求6所述的方法,所述三维脸部表情生成模型包括特征融合网络和表情系数生成网络,所述通过三维脸部表情生成模型处理所述至少一个音频特征和所述至少一个音素特征,得到所述至少一帧信号中的每一帧信号对应的脸部表情系数包括:通过所述特征融合网络处理所述至少一个音频特征和所述至少一个音素特征,得到所述至少一帧信号对应的至少一个融合特征;通过所述表情系数生成网络处理所述至少一帧信号对应的所述至少一个融合特征,得到所述至少一帧信号中的每一帧信号对应的脸部表情系数。11.如权利要求10所述的方法,所述特征融合网络包括一个或多个第一特征提取单元和一个或多个第二特征提取单元;所述通过所述特征融合网络处理所述至少一帧信号对应的所述至少一个音频特征和所述至少一个音素特征,得到所述至少一帧信号对应的至少一个融合特征包括:对于所述至少一帧信号中的每一帧信号:通过所述一个或多个第一特征提取单元处理所述每一帧信号对应的所述音频特征,得到所述一个或多个第一特征提取单元对应的一个或多个第一音频特征;通过所述一个或多个第二特征提取单元处理所述每一帧信号对应的所述音素特征和所述一个或多个第一音频特征,得到所述每一帧信号对应的所述融合特征。12.如权利要求11所述的方法,所述通过所述一个或多个第一特征提取单元处理所述每一帧信号对应的所述音频特征,得到所述一个或多个第一特征提取单元对应的一个或多个第一音频特征包括:所述一个或多个第一特征提取单元中的第一个特征提取单元处理所述每一帧信号对
应的所述音频特征,得到所述第一个特征提取单元对应的所述第一音频特征;所述多个第一特征提取单元中的其余第一特征提取单元处理前一个第一特征提取单元对应的所述第一音频特征,得到所述其余第一特征提取单元对应的所述第一音频特征。13.如权利要求11所述的方法,所述通过所述一个或多个第二特征提取单元处理所述每一帧信号对应的所述音素特征和所述一个或多个第一音频特征,得到所述每一帧信号对应的所述融合特征包括:所述一个或多个第二特征提取单元中的第一个第二特征提取单元处理所述每一帧信号对应的所述音素特征,得到所述第一个第二特征提取单元对应的第二音素特征;所述一个或多个第二特征提取单元中的其余第二特征提取单元处理前一个第二特征提取单元对应的拼接特征,得到所述其余第二特征提取单元对应的单元融合特征;所述一个或多个第二特征提取单元中的最后一个第二特征提取单元对应的所述单元融合特征或拼接特征作为所述每一帧信号对应的所述融合特征;其中,所述第一个第二特征提取单元对应的所述第二音素特征与对应的所述第一特征提取单元对应的所述第一音频特征拼接,得到所述第一个第二特征提取单元对应的所述拼接特征;所述其余第二特征提取单元对应的所述单元融合特征与对应的所述第一特征提取单元对应的所述第一音频特征拼接,得到所述其余第二特征提取单元对应的所述拼接特征。14.如权利要求11所述的方法,所述一个或多个第一特征提取单元和所述一个或多个第二特征提取单元对应。15.如权利要求6所述的方法,所述三维脸部表情生成模型的训练方法包括如权利要求1~5中任一项所述的方法。16.一种三维脸部动作生成系统,包括:第一获取模块,用于获取音频信号中的至少一帧信号对应的至少一个音频特征;第二获取模块,用于获取所述至少一帧信号对应的至少一个音素特征;表情系数生成模块,用于通过三维脸部表情生成模型处理所述至少一帧信号对应的所述至少一个音频特征和所述至少一个音素特征,得到所述至少一帧信号中的每一帧信号对应的脸部表情系数;三维脸部动作生成模块,用于基于所述至少一帧信号中的各帧信号对应的所述脸部表情系数、预设的脸部表情基底和预设脸部形状,得到所述至少一帧信号对应的至少一个三维脸部动作图像。17.一种计算机可读存储介质,所述存储介质存储计算机指令,当计算机读取存储介质中的计算机指令后,计算机执行如权利要求6~15中任一项所述的方法。
技术总结
本说明书涉及一种三维脸部表情生成方法和系统,方法包括:获取音频信号中的至少一帧信号对应的至少一个音频特征;获取所述至少一帧信号对应的至少一个音素特征;通过三维脸部表情生成模型处理所述至少一个音频特征和所述至少一个音素特征,得到所述至少一帧信号中的每一帧信号对应的脸部表情系数;基于所述至少一帧信号中的各帧信号对应的所述脸部表情系数、预设的脸部表情基底和预设脸部形状,得到所述至少一帧信号对应的至少一个三维脸部动作图像。动作图像。动作图像。
技术研发人员:王新文 陈珉 谌明
受保护的技术使用者:浙江同花顺智能科技有限公司
技术研发日:2022.03.01
技术公布日:2022/6/3
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。