1.本发明涉及音频处理技术领域,具体涉及一种音乐混响强度估计方法、装置及电子设备。
背景技术:
2.在狭小的空间内,播放音乐的效果会受到限制,尤其是混响较小的音乐,音乐效果不够自然。如果可以给歌曲加入混响,会为用户打造更好的听歌体验。为了区别需要加入混响的音乐种类,以及需要加入混响的强度,需要先准确估计出音乐自身的混响大小。
3.现有技术中通常采用滤波后的混合信号提供对混响感知水平的度量,但是这种方案除了需要输入原始信号分量,还需要把原始信号分量进行混响器处理,然后将原始信号分量和处理后的信号分量共同输入用于感知强度的度量装置,进而估计出需要多大的混响强度加入到原始信号分量上。所以这个技术的输出极大的依赖于混响器的混响强度。而现在的商业音乐是经过录音房录制并经过混响处理的,由于我们不知道是采用何种方式进行的混响,对音乐中的混响强度的估计值准确度较低。
技术实现要素:
4.有鉴于此,本发明实施例提供了一种音乐混响强度估计方法,以解决对音乐中的混响强度的估计值准确度较低的问题。
5.为达到上述目的,本发明提供如下技术方案:
6.本发明实施例提供了一种音乐混响强度估计方法,包括:
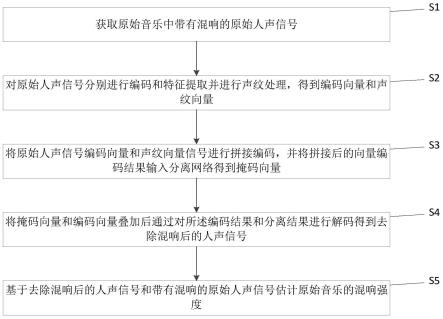
7.获取原始音乐中带有混响的原始人声信号;
8.对所述原始人声信号分别进行编码和声纹处理,得到编码向量和声纹向量;
9.将所述编码向量和所述声纹向量进行拼接,并将拼接后的向量输入分离网络得到掩码向量;
10.将所述掩码向量和所述编码向量叠加后进行解码得到去除混响后的人声信号;
11.基于所述去除混响后的人声信号和带有混响的原始人声信号估计所述原始音乐的混响强度。
12.可选的,所述对所述原始人声信号分别进行编码和声纹处理,得到编码向量和声纹向量,包括:
13.将所述原始人声信号按照预设的步长进行划分;
14.将划分后的原始人声信号进行编码得到编码向量;
15.通过预设算法从所述原始人声信号中提取频谱特征向量;
16.将所述频谱特征向量进行声纹处理得到声纹向量。
17.可选的,所述通过预设算法从所述原始人声信号中提取频谱特征向量,包括:
18.将所述原始人声信号进行傅里叶分析,得到第一频谱;
19.对所述第一频谱进行滤波得到第二频谱;
20.基于所述第一频谱和所述第二频谱计算得到所述频谱特征向量。
21.可选的,所述将所述频谱特征向量进行声纹处理得到声纹向量,包括:
22.将所述频谱特征向量通过帧表示层得到隐层向量;
23.将所述隐层向量输入统计池化层提取特征表达向量;
24.将所述特征表达向量输入全连接层进行降维得到声纹向量。
25.可选的,所述将拼接后的向量输入分离网络得到掩码向量,包括:
26.通过多头注意力机制对所述拼接后的向量进行识别得到多个局部特征向量;
27.通过多头注意力机制对所述局部特征向量进行识别得到掩码向量。
28.可选的,所述基于所述去除混响后的人声信号和带有混响的原始人声信号估计所述原始音乐的混响强度,包括:
29.从所述原始人声信号中提取第一强度和信号频率分布;
30.从所述去除混响后的人声信号提取第二强度;
31.计算所述第一强度和第二强度的比值;
32.基于所述第一强度、第二强度、信号频率分布和比值计算所述原始音乐的混响强度。
33.可选的,所述获取原始音乐中带有混响的原始人声信号,包括:
34.对所述原始音乐进行音轨分离;
35.从音轨分离后的原始音乐中提取带有混响的原始人声信号。
36.本发明实施例还提供了一种音乐混响强度估计装置,包括:
37.获取模块,用于获取原始音乐中带有混响的原始人声信号;
38.处理模块,用于对所述原始人声信号分别进行编码和声纹处理,得到编码向量和声纹向量;
39.分离模块,用于将所述编码向量和所述声纹向量进行拼接,并将拼接后的向量输入分离网络得到掩码向量;
40.解码模块,用于将所述掩码向量和所述编码向量叠加后进行解码得到去除混响后的人声信号;
41.估计模块,用于基于所述去除混响后的人声信号和带有混响的原始人声信号估计所述原始音乐的混响强度。
42.本发明实施例还提供了一种电子设备,包括:
43.存储器和处理器,所述存储器和所述处理器之间互相通信连接,所述存储器中存储有计算机指令,所述处理器通过执行所述计算机指令,从而执行本发明实施例提供的音乐混响强度估计方法。
44.本发明实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质存储计算机指令,所述计算机指令用于使所述计算机执行本发明实施例提供的音乐混响强度估计方法。
45.本发明技术方案,具有如下优点:
46.本发明提供了一种音乐混响强度估计方法,通过获取原始音乐中带有混响的原始人声信号;对原始人声信号分别进行编码和声纹处理,得到编码向量和声纹向量;将编码向量和声纹向量进行拼接,并将拼接后的向量输入分离网络得到掩码向量;将掩码向量和编
码向量叠加后进行解码得到去除混响后的人声信号;基于去除混响后的人声信号和带有混响的原始人声信号估计原始音乐的混响强度。本发明通过对原始人声信号进行处理,然后根据处理结果进行预测,不会存在相位缺失的情况,有效提高了预测结果的准确度;同时加入了声纹处理,利用了不同人嗓音不同的特点,使音乐混响强度的估计更加准确。
附图说明
47.为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
48.图1为本发明实施例中的音乐混响强度估计方法的流程图;
49.图2为根据本发明实施例中获取原始人声信号的流程图;
50.图3为根据本发明实施例中对原始人声信号进行处理的流程图;
51.图4为根据本发明实施例中从原始人声信号中提取频谱特征向量的流程图;
52.图5为根据本发明实施例中将频谱特征向量进行声纹处理得到声纹向量的流程图;
53.图6为根据本发明实施例中得到掩码向量的流程图;
54.图7为根据本发明实施例中得到去除混响后的人声信号的流程图;
55.图8为本发明实施例中的音乐混响强度估计装置的结构示意图;
56.图9为本发明实施例中的电子设备的结构示意图。
具体实施方式
57.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
58.根据本发明实施例,提供了一种音乐混响强度估计方法实施例,需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
59.在本实施例中提供了一种音乐混响强度估计方法,可用于需要对音乐混响进行估计的场合,如图1所示,该音乐混响强度估计方法包括如下步骤:
60.步骤s1:获取原始音乐中带有混响的原始人声信号。具体的,音乐分为伴奏部分和人声部分,本技术中主要考虑通过计算人声的混响对音乐混响进行估计,所以会首先通过音轨分离器(例如:spleeter)从一段音乐中分离出原始人声信号。
61.步骤s2:对原始人声信号分别进行编码和声纹处理,得到编码向量和声纹向量。具体的,可以通过声纹向量对编码向量进行补充,因为不同人的嗓音有所不同,会影响混响的结果,通过声纹向量可以增加后续的预测精度。
62.步骤s3:将编码向量和声纹向量进行拼接,并将拼接后的向量输入分离网络得到
掩码向量。
63.步骤s4:将掩码向量和编码向量叠加后进行解码得到去除混响后的人声信号。
64.步骤s5:基于去除混响后的人声信号和带有混响的原始人声信号估计原始音乐的混响强度。
65.通过上述步骤s1至步骤s5,本发明实施例提供的音乐混响强度估计方法,通过对原始人声信号进行处理,然后根据处理结果进行预测,不会存在相位缺失的情况,有效提高了预测结果的准确度;同时加入了声纹处理,利用了不同人嗓音不同的特点,使音乐混响强度的估计更加准确。
66.具体地,在一实施例中,上述的步骤s1,如图2所示,具体包括如下步骤:
67.步骤s11:对原始音乐进行音轨分离。具体的,通过音轨分离器可以将原始音乐中的人声信号完整分离出来,不破坏信号的完整性。
68.步骤s12:从音轨分离后的原始音乐中提取带有混响的原始人声信号。具体的,由于音轨分离得到的有人声信号和伴奏信号,需要从里面提取带有混响的原始人声信号,以便于提高混响的计算精度。
69.具体地,在一实施例中,上述的步骤s2,如图3所示,具体包括如下步骤:
70.步骤s21:将原始人声信号按照预设的步长进行划分;
71.步骤s22:将划分后的原始人声信号进行编码得到编码向量;
72.步骤s23:通过预设算法从原始人声信号中提取频谱特征向量;
73.步骤s24:将频谱特征向量进行声纹处理得到声纹向量。
74.具体的,人声信号经过预设算法(例如:mfc梅尔倒谱频率)提取特征,然后经过声纹处理得到声纹向量,通过声纹向量对原始人声信号进行补充,使音乐混响强度的估计更加准确。
75.具体地,在一实施例中,上述的步骤s23,如图4所示,具体包括如下步骤:
76.步骤s231:将原始人声信号进行傅里叶分析,得到第一频谱。具体的,原始人声信号经过短时傅里叶分析,得到fft对应的第一频谱。
77.步骤s232:对第一频谱进行滤波得到第二频谱。具体的,例如将第一频谱通过mel滤波器组得到mel频谱。
78.步骤s233:基于第一频谱和第二频谱计算得到频谱特征向量。具体的,将第一频谱和第二频谱点乘,再取对数,便可以得到mfc的频谱特征向量。
79.具体地,在一实施例中,上述的步骤s24,如图5所示,具体包括如下步骤:
80.步骤s241:将频谱特征向量通过帧表示层得到隐层向量。
81.步骤s242:将隐层向量输入统计池化层提取特征表达向量。
82.步骤s243:将特征表达向量输入全连接层进行降维得到声纹向量。
83.具体的,音频信号的mfc特征向量输入帧表示层,帧表示层由一组全连接构成,输出送入polling层用于提取全局特征信息,polling的输出最后送入embedding层,可以得到这个人的声纹表示。声纹向量可以对编码向量进行补充,因为不同人的嗓音有所不同,所以也会影响混响的结果,通过补充声纹向量可以有效提升预测精度。
84.具体地,在一实施例中,上述的步骤s3,如图6所示,具体包括如下步骤:
85.步骤s31:通过多头注意力机制对所述拼接后的向量进行识别得到多个局部特征
向量。
86.步骤s32:通过多头注意力机制对所述局部特征向量进行识别得到掩码向量。
87.具体的,将拼接后的向量输入分离网络,分离网络可采用例如transformer架构,把拼接后的向量按照步长p分为s块,这样就得到了s个维度的基本向量,针对每个基本向量,采用多头注意力机制,得到s个带有局部音频特征的局部特征向量,a1~as;再对a1~as采用多头注意力机制,得到最后的带有全局音频特征的掩码向量。此处通过采用多头注意力机制,相比与rnn等网络结构,训练速度更快,并行度更好。
88.具体地,在一实施例中,上述的步骤s4,如图7所示,具体包括如下步骤:
89.步骤s41:从原始人声信号中提取第一强度和信号频率分布。
90.步骤s42:从去除混响后的人声信号提取第二强度。
91.步骤s43:计算第一强度和第二强度的比值。
92.步骤s44:基于第一强度、第二强度、信号频率分布和比值计算原始音乐的混响强度。
93.具体的,通过采用线性回归拟合的方式,根据原始人声信号的第一强度,去混响后人声信号的第二强度,第一强度和第二强度的比值,原始人声信号的频率分布,预测原始人声信号中的混响强度。
94.现有技术中通常会对信号进行滤波,滤波可能会使相位产生损失,从而影响预测结果,本发明通过对原始人声信号进行处理,然后根据处理结果进行预测,不会存在相位缺失的情况,有效提高了预测结果的准确度;同时加入了声纹处理,利用了不同人嗓音不同的特点,使音乐混响强度的估计更加准确。
95.在本实施例中还提供了一种音乐混响强度估计装置,该装置用于实现上述实施例及优选实施方式,已经进行过说明的不再赘述。如以下所使用的,术语“模块”可以实现预定功能的软件和/或硬件的组合。尽管以下实施例所描述的装置较佳地以软件来实现,但是硬件,或者软件和硬件的组合的实现也是可能并被构想的。
96.本实施例提供一种音乐混响强度估计装置,如图8所示,包括:
97.获取模块101,用于获取原始音乐中带有混响的原始人声信号,详细内容参见上述方法实施例中步骤s1的相关描述,在此不再进行赘述。
98.处理模块102,用于对原始人声信号分别进行编码和声纹处理,得到编码向量和声纹向量,详细内容参见上述方法实施例中步骤s2的相关描述,在此不再进行赘述。
99.分离模块103,用于将编码向量和声纹向量进行拼接,并将拼接后的向量输入分离网络得到掩码向量,详细内容参见上述方法实施例中步骤s3的相关描述,在此不再进行赘述。
100.解码模块104,用于将掩码向量和编码向量叠加后进行解码得到去除混响后的人声信号,详细内容参见上述方法实施例中步骤s4的相关描述,在此不再进行赘述。
101.估计模块105,用于基于所述去除混响后的人声信号和带有混响的原始人声信号估计所述原始音乐的混响强度,详细内容参见上述方法实施例中步骤s5的相关描述,在此不再进行赘述。
102.本实施例中的音乐混响强度估计装置是以功能单元的形式来呈现,这里的单元是指asic电路,执行一个或多个软件或固定程序的处理器和存储器,和/或其他可以提供上述
功能的器件。
103.上述各个模块的更进一步的功能描述与上述对应实施例相同,在此不再赘述。
104.根据本发明实施例还提供了一种电子设备,如图9所示,该电子设备可以包括处理器901和存储器902,其中处理器901和存储器902可以通过总线或者其他方式连接,图9中以通过总线连接为例。
105.处理器901可以为中央处理器(central processing unit,cpu)。处理器901还可以为其他通用处理器、数字信号处理器(digital signal processor,dsp)、专用集成电路(application specific integrated circuit,asic)、现场可编程门阵列(field-programmable gate array,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等芯片,或者上述各类芯片的组合。
106.存储器902作为一种非暂态计算机可读存储介质,可用于存储非暂态软件程序、非暂态计算机可执行程序以及模块,如本发明方法实施例中的方法所对应的程序指令/模块。处理器901通过运行存储在存储器902中的非暂态软件程序、指令以及模块,从而执行处理器的各种功能应用以及数据处理,即实现上述方法实施例中的方法。
107.存储器902可以包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需要的应用程序;存储数据区可存储处理器901所创建的数据等。此外,存储器902可以包括高速随机存取存储器,还可以包括非暂态存储器,例如至少一个磁盘存储器件、闪存器件、或其他非暂态固态存储器件。在一些实施例中,存储器902可选包括相对于处理器901远程设置的存储器,这些远程存储器可以通过网络连接至处理器901。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
108.一个或者多个模块存储在存储器902中,当被处理器901执行时,执行上述方法实施例中的方法。
109.上述电子设备具体细节可以对应参阅上述方法实施例中对应的相关描述和效果进行理解,此处不再赘述。
110.本领域技术人员可以理解,实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,存储介质可为磁碟、光盘、只读存储记忆体(read-only memory,rom)、随机存储记忆体(random access memory,ram)、快闪存储器(flash memory)、硬盘(hard disk drive,缩写:hdd)或固态硬盘(solid-state drive,ssd)等;存储介质还可以包括上述种类的存储器的组合。
111.虽然结合附图描述了本发明的实施例,但是本领域技术人员可以在不脱离本发明的精神和范围的情况下做出各种修改和变型,这样的修改和变型均落入由所附权利要求所限定的范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
