1.本发明涉及移动通信技术领域,具体涉及一种超密集网络下基于联邦学习的分簇协作缓存方法。
背景技术:
2.随着智能设备和无线通信的爆炸性增长,第五代(5g)蜂窝网络被提出来以应对无线流量的增长的挑战。为了应对未来网络的挑战,必须密集部署大量的小蜂窝,以实现无缝覆盖,使客户获得更好的体验。因此,超密集网络(ultra-dense network,udn)逐渐成为5g蜂窝网络的核心特征之一。超密集网络通过在购物商场、火车站或者机场等产生巨大流量的热点地区密集部署小基站,在终端用户发送请求时,可以更快链接接入节点,从而实现5g网络的高流量密度、高峰值速率性能。然而,在小基站密集部署的情况下,每个小基站网络中的所有流量都被传输到相应的网关或宏基站,这可能会导致回程因流量拥堵而成为网络瓶颈。为了解决移动数据流量激增带来的回传瓶颈,我们采用了内容中心的网络(content centric network,ccn)应用到udn中。ccn作为未来的互联网架构之一,与ip网络不同,侧重以内容为中心的传输,它的特征是内容请求包(称为“兴趣”)和内容响应包(称为“数据”)的基本交换,它要求用户直接采用内容名来请求和检索内容,而不关心内容的来源和目的地址。兴趣包和数据包是对应的,且都有作为标识符的名称。当用户请求一个内容时,他将发送一个包含所需内容名称的兴趣包。兴趣包将会一直被转发,直到它能够在其生存时间内到达一个可以提供数据包的节点。然后,数据包将通过相应兴趣包的反向路径被返回给请求节点。任何帮助转发数据包的节点都可以根据其缓存策略决定是否缓存内容。
3.ccn中的网内缓存机制可以在用户请求内容时降低内容到达用户的时延,减轻udn中回程链路流量拥堵的压力,从而提升网络性能。现有缓存方案可分为协作缓存方案和非协作缓存方案。然而,在非协作的缓存方案中,相同的内容可能会在距离较近的多个基站之间进行缓存,导致缓存冗余和低缓存利用率。在协作的缓存方案中,虽然相较于非协作缓存方案有一些进步,但是仍然存在一些问题。一些缓存方案为了在靠近用户的节点上尽可能的缓存高流行内容,从而会出现在多个节点缓存相同的高流行内容的情况,造成缓存冗余。
技术实现要素:
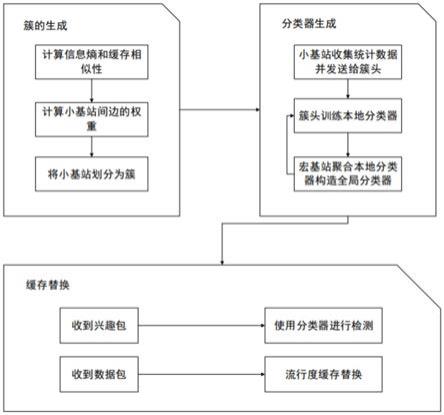
4.为了有效的提高超密集网络下的网络缓存性能,本发明提出了一种基于联邦学习的分簇协作缓存方法。该方案首先提出一个基于贪婪思想的分簇算法,根据小基站之间的缓存相似性和信息熵将小基站进行分簇,所有小基站形成簇进行协作缓存。然后,簇头收集需要的数据,训练本地分类器,宏基站聚合多个簇头上传的本地分类器构造一个改进的全局分类器。最后,为了提升缓存命中率,将每个小基站的缓存空间分为协作区和非协作区,小基站将收到的内容分类为协作内容和非协作内容,并且在缓存替换时基于流行度高低对协作内容和非协作内容进行缓存替换。
5.本发明的技术方案:
6.一种超密集网络下基于联邦学习的分簇协作缓存方法,步骤如下:
7.(1)首先根据小基站之间的缓存相似性和信息熵将小基站进行分簇;
8.(1.1)小基站收到兴趣包后,统计信息,包括相同内容的请求包数量以及收到的不同种类请求包的数量,
9.请求率为内容ci在两个小基站的请求概率,
[0010][0011]
其中,n(i)表示小基站sm和小基站sr中内容ci的请求数,n
(m,r)
表示小基站sm和小基站sr的所有请求数量;
[0012]
信息熵为根据请求率计算信息熵,
[0013][0014]
其中,nd表示小基站sm和小基站sr收到不同种类请求包的数量,通过计算两个小基站之间收到请求包的皮尔逊相关系数得到缓存相似性,请求平均数为小基站收到的请求包总数目除以所有请求数量,
[0015][0016]
其中,n
(m,i)
表示小基站sm收到内容ci的请求数,为小基站sm的请求平均数,
[0017][0018][0019][0020]
其中,c
(m,r)
表示小基站sm和小基站sr之间的缓存相似性;
[0021]
边的权重为小基站之间的信息熵乘以缓存相似性,
[0022]w(m,r)
=h
(m,r)
·c(m,r)
[0023]
其中,w
(m,r)
表示小基站sm和小基站sr之间的边的权重。
[0024]
(1.2)基于贪婪思想的分簇算法进行分簇,并保证簇内的小基站个数大于2,且是簇的直径不大于3,处于簇内网络拓扑中心的节点成为簇头,
[0025]
(2)分簇后,基于联邦学习在多个小基站的协助下构造一个全局分类器,每次迭代,簇头从宏基站下载最新共享分类器模型,利用从簇内成员收集的数据来训练本地分类
器模型,宏基站聚合各簇头分类器更新分类器模型参数,多次迭代,生成最终全局分类器模型;
[0026]
(2.1)簇头和簇成员定期统计收到的兴趣包,获得本地请求比率、簇内请求比率、本地请求比率方差和簇内请求比率方差;
[0027]
本地请求比率:在第k个时间片中,小基站sm收到请求内容ci的请求数量与小基站sm接收到的所有请求数量的比率,
[0028][0029]
其中,n
(k,m,i)
是小基站sm在第k个时间片收到的请求内容ci的兴趣包数量,是小基站sm在第k个时间片收到的所有请求的数量;
[0030]
簇内请求比率:在第k个时间片中,簇内所有小基站收到的请求内容ci的请求数量与簇内所有小基站接收到的所有请求的数量的比率,
[0031][0032]
其中,l为簇成员数目。
[0033]
本地请求比率方差:在过去的n
t
个时间片中,内容ci的本地请求比率的方差,
[0034][0035]
簇内请求比率方差:在第k个时间片中,簇内小基站对内容ci的簇内请求率的方差,
[0036][0037]
(2.2)采用gru模型学习请求模式和相应内容标签之间的关系,采用fedavg在本地分类器的基础上构建一个改进的全局分类器,每个小基站将收集到的统计数据发送给簇头,每个簇头将收到的每个时间片的四个统计数据构成四维特征向量,按时间顺序将四维特征向量构成时间序列,输入时间序列更新共享分类器,
[0038]
基于gru模型实现的分类器,其所有参数标记为ω,其损失函数如下,
[0039][0040]
其中,y是内容的标签,0表示非协作内容,1表示协作内容,表示内容被预测为协作内容的概率;
[0041]
(2.3)在簇头完成对本地分类器的训练之后,每个簇头将更新后的本地分类器发送给宏基站,在每n
t
个时间片后,宏基站收到更新的本地分类器,采用fedavg算法更新用于下一次迭代的新共享分类器,
[0042][0043]
其中,|dj|代表第j个簇头收集的样本数,ng代表簇的总数目,为第j个簇头的分类器,ω
t 1
为更新后的共享分类器,
[0044]
通过多次迭代产生最终的全局分类器,最终的全局分类器被广播给所有的小基站;
[0045]
(3)小基站收到全局分类器后,将收到的内容分类为协作内容和非协作内容,每个小基站的缓存空间分为协作部分和非协作部分,协作内容协作缓存在小基站的协作缓存空间,非协作内容缓存在小基站的非协作缓存空间;
[0046]
簇内的缓存替换策略具体过程如下:
[0047]
(3.1)所有小基站在收到兴趣包后进行数据统计并构造成时间序列,然后使用分类器预测内容的标签;
[0048]
(3.2)此外,为了提升缓存命中率,本方案采用基于流行度的缓存替换策略,小基站在收到兴趣包后进行流行度计算,
[0049][0050]
其中为内容ci在第k个时间片的请求数,n为第k个时间片所有内容的请求数,η
(k-1,i)
为上一个时间片内容ci的流行度;
[0051]
(3.3)小基站检查本地是否缓存对应数据包,如果有缓存,即缓存命中,将该数据包原路返回给用户节点,如果本地没有缓存对应数据包,则将兴趣包存在簇内路由,如果簇内其他小基站中存储着对应的数据包,即缓存命中,则将该数据包原路返回给用户节点,如果其他小基站中没有缓存对应数据包,则将该兴趣包向数据源节点进行转发;
[0052]
(3.4)当小基站接收到数据包时,如果该数据包内容标签为协作内容,则将数据包根据流行度缓存替换策略缓存至小基站的协作区;如果该数据包内容标签为非协作内容,则将数据包根据流行度缓存替换策略缓存至小基站的非协作区。
[0053]
本发明的有益效果:超密集网络(ultra-dense network)通过密集部署小基站从而实现5g网络的高流量密度、高峰值速率性能,在udn中应用内容中心网络(ccn)的网内缓存机制和以内容名称为中心的传输方式可以进一步加快内容的分发,减少回程链路上的流量拥堵。然而,当下的缓存机制大多在考虑的流行内容的同时忽略了缓存冗余的问题。并且,网内缓存可能会受到多种攻击,存在着各种隐私数据风险。因此,我们设计了一种超密集网络下基于联邦学习的分簇协作缓存方法,使用联邦学习在多个小基站的协作下得到一个高质量的分类器,在降低缓存冗余度的同时提升缓存多样性和缓存命中率。
附图说明
[0054]
图1为本发明所述的分簇协作缓存方法的组织结构图。
[0055]
图2为本发明所述的小基站分簇的流程图。
[0056]
图3为本发明所述的分类器生成的流程图。
[0057]
图4为本发明所述的缓存替换策略的流程图。
具体实施方式
[0058]
为了将本发明的目的,技术方案和优点表达的更清晰明了,接下来将通过实施例和附图,对本发明做进一步的详尽的说明。
[0059]
一种超密集网络下基于联邦学习的分簇协作缓存方法,本方法包括小基站分簇、收到兴趣包后进行数据统计并进行分类器训练、小基站使用分类器对内容进行分类并进行缓存替换。
[0060]
参照图2,小基站分簇的具体运行过程如下:
[0061]
步骤1.小基站收到兴趣包请求。
[0062]
步骤2.每个小基站统计信息:包括相同内容请求包的数量和不同种类请求包的数量。
[0063]
步骤3.首先根据统计信息计算请求率,
[0064][0065]
其中,n(i)表示小基站sm和小基站sr中内容ci的请求数,n
(m,r)
表示小基站sm和小基站sr的所有请求数量。
[0066]
然后根据信息熵的公式和请求率计算信息熵,
[0067][0068]
步骤4.首先根据统计信息计算请求平均数,
[0069][0070]
其中,n
(m,i)
表示小基站sm收到的内容ci的请求数,为小基站sm的请求平均数。然后根据协方差的公式计算小基站sm和小基站sr收到的请求的协方差,
[0071][0072]
之后使用标准差的公式计算收到的请求的标准差,
[0073][0074]
最后根据皮尔逊相关系数公式来计算缓存相似性,
[0075][0076]
其中,c
(m,r)
表示小基站sm和小基站sr之间的缓存相似性。
[0077]
步骤5.计算各个小基站之间边的权重,边的权重等于小基站之间的信息熵乘以缓存相似性,
[0078]w(m,r)
=h
(m,r)
·c(m,r)
[0079]
步骤6.通过基于贪婪思想的分簇算法把小基站划分成簇,其中,分簇时要保证每个簇的直径不大于3。
[0080]
分簇算法如下:
[0081]
(1)从计算出的边集e中抽出权重最大的边,并且记对应的节点为si,sj.
[0082]
(2)若si,sj还不是某个簇中的节点,则si,sj构成一个新的簇。若其中一个节点si属于某个簇gi,另一个节点sj没有归属簇,并且将sj加入到簇gi中不会使簇gi的直径大于3,那么就将sj加入到gi。若si,sj都已有归属簇,则不做任何操作。
[0083]
(3)重复步骤(1),(2)。直到遍历完所有的边。
[0084]
(4)若还有节点没有归属簇,则尝试将它添加到它的最大权重边的另一对应节点所在的簇中,如果此时簇的直径大于3,那么此节点与它的最大权重边的另一对应节点退出原来的簇,并与该对应节点形成新的簇。
[0085]
参照图3,收到兴趣包后进行数据统计并进行分类器训练的具体过程如下:
[0086]
步骤7.每个小基站和宏基站根据每个时间片收到的兴趣包统计以下信息:
[0087]
本地请求比率:在第k个时间片中,小基站sm收到请求内容ci的请求数量与小基站sm接收到的所有请求的数量的比率,
[0088][0089]
其中,n
(k,m,i)
是小基站sm在第k个时间片收到的请求内容ci的兴趣包数量,是小基站sm在第k个时间片收到的所有请求的数量。
[0090]
簇内请求比率:在第k个时间片中,簇内所有小基站收到的请求内容ci的请求数量与接收到的所有请求的数量的比率,
[0091][0092]
其中,l为簇成员数目。
[0093]
本地请求比率方差:在过去的n
t
个时间片中,内容ci的本地请求比率的方差,
[0094][0095]
簇内请求比率方差:在第k个时间片中,簇内小基站对内容ci的簇内请求率的方差,
[0096][0097]
步骤8.小基站周期性的将步骤7的统计信息发送给簇头。
[0098]
步骤9.簇头和宏基站将每个时间片的统计信息生成一个四维的特征向量其中k表示第k个时间片,在n
t
个时间片后,簇头将会获得一个输入时间序列
[0099]
步骤10.宏基站根据收集到的信息预训练一个初始的共享分类器ω0,使用的交叉熵损失函数如下,
[0100][0101]
其中y是内容的标签,0表示非协作内容,1表示协作内容,表示内容被预测为协作内容的概率。
[0102]
步骤11.所有簇头各自从宏基站处下载最新的共享分类器,并且使用步骤9得到的时间序列数据训练模型,更新当前的共享分类器ω
t
。所有簇头使用随机梯度下降(sgd)方法进行多次迭代运算来得到更新的本地分类器其中,t表示第t次迭代,k表示第k个簇头。
[0103]
步骤12.更新完成后,簇头将更新后的本地分类器模型上传给宏基站。
[0104]
步骤13.在每n
t
个时间片后,宏基站采用fedavg算法构造一个更优的用于下一次迭代的新的共享分类器,
[0105][0106]
其中,|dj|代表第j个簇头收集的样本数,ng代表簇的总数目,为第j个簇头的分类器,ω
t 1
为更新后的共享分类器。
[0107]
步骤14.判断更新后的共享分类器的准确度是否达到要求,如果达到,进行步骤15;否则,进行步骤11。
[0108]
步骤15.宏基站将迭代结束得到的全局分类器广播给所有小基站。
[0109]
参照图4,小基站使用分类器对内容进行分类并进行缓存替换的具体过程如下:
[0110]
步骤16.每个小基站收到兴趣包后根据每个时间片收集的信息得到步骤7的统计数据,并按照步骤9的方式生成时间序列。
[0111]
步骤17.小基站基于分类器预测内容的标签。
[0112]
步骤18.小基站计算兴趣包的流行度,
[0113][0114]
其中为内容ci在第k个时间片的请求数,n为第k个时间片所有内容的请求数,
η
(k-1,i)
为上一个时间片内容ci的流行度。
[0115]
步骤19.小基站检查本地缓存空间内是否缓存了对应的内容,如果缓存了对应内容进行步骤23;否则,进行步骤20。
[0116]
步骤20.如果小基站本地缓存空间内没有缓存对应内容,则将兴趣包发送给簇内其他小基站。
[0117]
步骤21.簇内其他小基站检查是否有缓存对应内容,如果有缓存对应内容,进行步骤23;否则,进行步骤22。
[0118]
步骤22.如果簇内其他小基站的缓存空间内没有缓存对应内容,则将兴趣包向核心网络进行转发从而获取数据包。
[0119]
步骤23.获取到对应数据包后,将数据包原路返回给用户节点。
[0120]
步骤24.数据包转发过程中,小基站收到返回的数据包。
[0121]
步骤25.小基站检查数据包的内容标签是否为协作内容,如果是,进行步骤26;否则,进行步骤27。
[0122]
步骤26.如果数据包的内容标签是协作内容,则对小基站的协作区按照流行度高低进行缓存替换。
[0123]
步骤27.如果数据包的内容标签是非协作内容,则对小基站的非协作区按照流行度高低进行缓存替换。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。