1.本发明涉及空间录制、分析、再现和感知方面,具体地,涉及双耳分析和合成。
背景技术:
2.选择性听觉(sh)是指听者将他们的注意力引导到其听觉场景中的某个声源或引导到多个声源的能力。进而,这意味着听者对不感兴趣源的关注减少。
3.因此,人类听者能够在嘈杂的环境中进行通信。这通常利用了不同的方面:在用两只耳朵倾听时,声音存在取决于方向的时间和级别差异以及取决于方向的不同频谱着色。这使听觉能够确定声源的方向并专注于声源的方向。
4.此外,在自然声源(特别是语音)的情况下,不同频率的信号部分在时间上耦合。通过这种方式,即使仅用一只耳朵倾听,听觉也能够区分不同的声源。在双耳听觉中,这两个方面一起被使用。此外,可以说,可以积极地忽略可很好定位的响亮的干扰源。
5.在文献中,选择性听觉的概念与诸如辅助聆听[1]、虚拟和放大的听觉环境[2]的其他术语有关。辅助聆听是包括虚拟、放大的和sh应用的更广泛术语。
[0006]
根据现有技术,经典的听觉设备以单声道方式工作,即用于左耳和右耳的信号处理关于频率响应和动态压缩完全独立。结果,丢失了人耳信号之间的时间、级别和频率差异。
[0007]
现代,所谓的双耳听觉设备将两个听觉设备的校正因子耦合。通常,它们具有若干个麦克风,然而,通常是仅具有所选择但不计算波束成形的“最像语音”信号的麦克风。在复杂的听觉情况下,期望和不期望的声音信号以相同的方式放大,因此不支持对期望的声音分量的关注。
[0008]
在免提设备领域,例如对于电话来说,当今已经使用了若干个麦克风,并且根据各个麦克风信号计算所谓的波束:放大来自波束方向的声音,降低来自其他方向的声音。当今的方法学习了背景中的恒定声音(例如,汽车中的引擎噪声和风噪声),学习通过另一波束可很好定位的响亮干扰,并从使用信号中减去这些干扰(例如:广义旁瓣消除器)。有时,电话系统使用检测语音的静态属性的检测器,以抑制不像语音那样结构化的所有内容。在免提设备中,最终仅传输单声道信号,在传输路径中丢失了会对捕获情况感兴趣的空间信息,具体地,提供了好像“一个人在那里”的错觉,特别是在若干讲话者相互通话的情况下。通过抑制非语音信号,丢失了关于对话伙伴的声学环境的重要信息,这可能会阻碍通信。
[0009]
从本质上讲,人类能够“选择性地倾听”并有意识地关注他们周围环境中的各个声源。通过人工智能(ai)进行选择性听觉的自动系统必须首先学习底层概念。声学场景的自动分解(场景分解)首先需要对所有活动声源进行检测和分类,然后进行分离,以便能够将它们作为单独的音频对象进行进一步处理、放大或衰减。
[0010]
听觉场景分析的研究领域尝试基于录制的音频信号对诸如脚步声、拍手声或喊叫声之类的在时间上定位的声音事件以及诸如音乐会、餐厅或超市之类的更全局的声学场景进行检测和分类。在这种情况下,当前方法专门使用人工智能(ai)和深度学习领域的方法。
这涉及深度神经网络的数据驱动学习,该数据驱动学习基于大量训练来学习以检测音频信号中的特性模式[70]。最重要的是,受图像处理(计算机视觉)和语音处理(自然语言处理)研究领域进步的启发,作为一般规则,使用用于频谱图表示中的二维模式检测的卷积神经网络和用于声音的时间建模的循环层(循环神经网络)的混合。
[0011]
对于音频分析,存在一系列要处理的特定挑战。由于它们的复杂性,深度学习模型非常需要数据。与图像处理和语音处理的研究领域相比,仅相对较小的数据集可用于音频处理。最大的数据集是谷歌的audioset数据集[83],其具有约200万个声音示例和632个不同的声音事件分类,其中,研究中使用的大多数数据集显著地更小。这种少量的训练数据可以通过例如迁移学习来解决,其中,在较大数据集上预训练的模型随后被微调为具有针对用例确定的新类别的较小数据集(微调)[77]。此外,使用半监督学习的方法,以便在训练中涉及通常大量可用的未注释音频数据。
[0012]
与图像处理相比,另一显著差异是:在同时可听到的声学事件的情况下,声音对象没有掩盖(如图像的情况),而是复杂的取决于相位的重叠。深度学习中的当前算法使用所谓的“关注”机制,例如,使模型能够专注于对某些时间段或频率范围的分类[23]。声音事件的检测由于其持续时间的高方差而更加复杂。算法应当能够稳健地检测诸如手枪射击之类的非常短的事件以及诸如正在经过的火车之类的长事件。
[0013]
由于模型在记录训练数据时对声学条件的强依赖性,它们经常在新的声学环境中表现出意想不到的行为,例如,它们在空间混响或麦克风的位置方面不同。已经开发了不同的解决方案来缓解这个问题。例如,数据增强方法尝试通过模拟不同的声学条件[68]和不同声源的人工重叠来实现模型的更高鲁棒性和不变性。此外,可以以不同的方式调节复杂神经网络中的参数,从而避免对训练数据的过度训练和专业化,同时实现对未见数据的更好的泛化。近年来,已经针对“域适配”[67]提出了不同的算法,以便使先前训练的模型适配新的应用条件。在本项目中计划的耳机内的使用场景中,声源检测算法的实时能力具有基本意义。这里,必须在神经网络的复杂性与底层计算平台上的计算操作的最大可能次数之间进行权衡。即使声音事件具有较长的持续时间,它仍然必须尽可能快地被检测到,以便开始对应的源分离。
[0014]
在弗劳恩霍夫idmt,近年来在自动声源检测领域已经开展了大量的研究工作。在研究项目中,已经开发了一种分布式传感器网络,其可以测量噪声级别并基于城市内不同位置处录制的音频信号在14种不同的声学场景与事件类别之间进行分类[69]。在这种情况下,在嵌入式平台树莓派3上实时地进行传感器中的处理。前期工作研究了基于自动编码器网络对频谱图进行数据压缩的新颖方法[71]。最近,通过在音乐信号处理(音乐信息检索)领域中使用深度学习的方法,在诸如音乐转录[76]、[77]、和音检测[78]以及乐器检测[79]的应用中已经取得了巨大的进展。在工业音频处理领域,已经建立了新的数据集,并已经使用了深度学习方法,例如,用于监测电动机的声学状态[75]。
[0015]
在该实施例中解决的场景假设其数量和类型最初未知的若干声源,并且它们的数量和类型可以不断改变。对于声源分离,具有相似特性的若干个源(例如若干个讲话者)是特别大的挑战[80]。
[0016]
为了实现高空间分辨率,必须以阵列的形式使用若干个麦克风[72]。与单声道(1声道)或立体声(2声道)的传统音频录制相比,这种录制场景能够精确定位听者周围的声
源。
[0017]
声源分离算法通常留下伪影,例如声源之间的失真和串扰[5],听者一般会感知这些伪影造成了干扰。通过重新混合音轨,可以部分地掩盖这种伪影,并因此减少这种伪影[10]。
[0018]
为了增强“盲”源分离,通常使用附加信息,例如检测到的源的数量和类型或者源的估计的空间位置(知情源分离[74])。对于有若干个讲话者活动的会议,当前的分析系统可以同时估计讲话者的数量,确定他们各自的时间活动,并随后通过源分离[66]将它们隔离。
[0019]
在弗劳恩霍夫idmt,近年来已经对声源分离算法的基于感知的评估执行了大量研究[73]。
[0020]
在音乐信号处理领域中,已经开发了一种实时能力的算法,用于利用独奏乐器的基频估计作为附加信息来分离独奏乐器以及伴奏乐器[81]。在[82]中提出了一种基于深度学习方法将歌声与复杂音乐作品分离的备选方法。也已经开发了专门的源分离算法,用于工业音频分析背景下的应用[7]。
[0021]
耳机显著影响周围环境的声学感知。取决于耳机的结构,朝向耳朵的声音入射被衰减到不同程度。入耳式耳机完全阻塞耳道[85]。围绕耳廓的封闭式耳机在声学上也强烈切断了听者与外界环境的联系。开放式和半开放式耳机允许声音完全或部分地通过[84]。在日常生活的许多应用中,期望耳机可以比其结构类型更强烈地隔离不期望的周围环境声音。
[0022]
来自外部的干扰影响还可以通过主动噪声控制(anc)来衰减。这通过以下来实现:通过耳机的麦克风来录制入射声音信号,然后通过扬声器再现它们,使得这些声音部分和穿透耳机的声音部分通过干扰彼此抵消。总体而言,这可以实现与周围环境的强声学隔离。然而,在许多日常情况下,这伴随着危险,这就是为什么期望能够根据需要智能地打开该功能的原因。
[0023]
首先,产品能够使麦克风信号传入耳机,以便减少被动隔离。因此,除了原型[86]之外,已经存在宣扬具有“透明聆听”的功能的产品。例如,sennheiser通过ambeo耳机[88]提供了该功能,而bragi通过产品“the dash pro”提供了该功能。然而,这种可能性仅是开始。将来,该功能将得到极大扩展,使得除了完全打开和关闭周围环境声音外,还可以使各个信号部分(例如,仅语音或警报信号)在需要时完全可听到。法国公司orosound使佩戴耳机“tilde earphones”[89]的人能够通过滑块调整anc的强度。此外,对话伙伴的声音在激活的anc期间也可以通过。然而,这仅适用于对话伙伴面对面位于60
°
锥体中的情况。与方向无关的调整是不可能的。
[0024]
专利申请公开us 2015 195641a1(参见[91])公开了一种为用户生成听觉环境而实施的方法。在这种情况下,该方法包括:接收表示用户的周围听觉环境的信号,通过使用微处理器处理该信号以便识别周围听觉环境中的多个声音类型中的至少一个声音类型。此外,该方法包括:接收用户对多个声音类型中的每一个的偏好,针对周围听觉环境中的每个声音类型修改信号,以及将经修改的信号输出到至少一个扬声器,以便为用户生成听觉环境。
技术实现要素:
[0025]
提供了根据权利要求1的系统、根据权利要求16的方法、根据权利要求17的计算机程序、根据权利要求18的装置、根据权利要求32的方法以及根据权利要求33的计算机程序。
[0026]
提供了一种用于辅助选择性听觉的系统。该系统包括检测器,用于通过使用听觉环境的至少两个接收到的麦克风信号来检测一个或多个音频源的音频源信号部分。此外,该系统包括位置确定器,用于将位置信息分派给一个或多个音频源中的每个音频源。此外,该系统包括音频类型分类器,用于将音频信号类型分配给一个或多个音频源中的每个音频源的音频源信号部分。此外,该系统包括信号部分修改器,用于根据一个或多个音频源中的至少一个音频源的音频源信号部分的音频信号类型来改变至少一个音频源的音频源信号部分,以便获得至少一个音频源的经修改的音频信号部分。此外,该系统包括信号发生器,用于针对一个或多个音频源中的每个音频源,根据该音频源的位置信息和用户头部的朝向,针对每个音频源产生多个双耳室内脉冲响应,以及用于根据多个双耳室内脉冲响应并且根据至少一个音频源的经修改的音频信号部分来产生至少两个扬声器信号。
[0027]
此外,提供了一种辅助选择性听觉的方法。该方法包括:
[0028]-通过使用听觉环境的至少两个接收到的麦克风信号来检测一个或多个音频源的音频源信号部分。
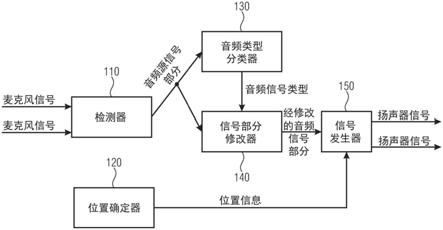
[0029]-将位置信息分派给一个或多个音频源中的每个音频源。
[0030]-将音频信号类型分配给一个或多个音频源中的每个音频源的音频源信号部分。
[0031]-根据一个或多个音频源中的至少一个音频源的音频源信号部分的音频信号类型来改变至少一个音频源的音频源信号部分,以便获得至少一个音频源的经修改的音频信号部分。以及:
[0032]-针对一个或多个音频源中的每个音频源,根据该音频源的位置信息和用户头部的朝向,针对每个音频源产生多个双耳室内脉冲响应,以及用于根据多个双耳室内脉冲响应并且根据至少一个音频源的经修改的音频信号部分产生至少两个扬声器信号。
[0033]
此外,提供了一种具有用于执行上述方法的程序代码的计算机程序。
[0034]
此外,提供了一种用于确定一个或多个室内声学参数的装置。该装置被配置为获得包括一个或多个麦克风信号的麦克风数据。此外,该装置被配置为获得关于用户的位置和/或朝向的跟踪数据。此外,该装置被配置为根据麦克风数据并且根据跟踪数据来确定一个或多个室内声学参数。
[0035]
此外,提供了一种用于确定一个或多个室内声学参数的方法。该方法包括:
[0036]-获得包括一个或多个麦克风信号的麦克风数据。
[0037]-获得关于用户的位置和/或朝向的跟踪数据。以及:
[0038]-根据麦克风数据并且根据跟踪数据来确定一个或多个室内声学参数。
[0039]
此外,提供了一种具有用于执行上述方法的程序代码的计算机程序。
[0040]
其中,实施例基于合并和组合技术系统中用于辅助听觉的不同技术,使得针对听觉正常的人和听觉受损的人实现声音质量和生活质量的增强(例如,期望的声音更响亮、期望的声音更安静、更好的语音可理解性)。
[0041]
随后,参考附图描述本发明的优选实施例。
附图说明
[0042]
在附图中:
[0043]
图1示出了根据实施例的用于辅助选择性听觉的系统。
[0044]
图2示出了根据实施例的还包括用户界面的系统。
[0045]
图3示出了根据实施例的包括具有两个对应扬声器的听觉设备的系统。
[0046]
图4示出了根据实施例的包括壳体结构和两个扬声器的系统。
[0047]
图5示出了根据实施例的包括具有两个扬声器的耳机的系统。
[0048]
图6示出了根据实施例的包括远程设备190的系统,远程设备190包括检测器和位置确定器和音频类型分类器和信号部分修改器和信号发生器。
[0049]
图7示出了根据实施例的包括五个子系统的系统。
[0050]
图8示出了根据实施例的对应场景。
[0051]
图9示出了根据实施例的具有四个外部声源的场景。
[0052]
图10示出了根据实施例的sh应用的处理工作流。
具体实施方式
[0053]
在现代生活中,眼镜帮助许多人更好地感知他们的环境。对于听觉,存在助听器,然而,即使是听觉正常的人在许多情况下也可以通过智能系统获得帮助:
[0054]
通常,周围区域过于嘈杂,仅某些声音造成了干扰,并且人们希望选择性地倾听。人脑在这方面已经擅长,但未来进一步的智能辅助可以显著改善这种选择性听觉。为了实现这种“智能可听设备”(听觉设备或助听器),技术系统必须分析(声学)环境并识别各个声源,以便能够分别处理它们。已有关于该主题的研究工作,然而,对整个声学环境进行实时(对于我们的耳朵是透明的)且高音质(为了使听到的内容不与正常的声学环境无法区分)的分析和处理在传统技术中尚未实现。
[0055]
下文提供了用于机器聆听的改进概念。
[0056]
图1示出了根据实施例的用于辅助选择性听觉的系统。
[0057]
该系统包括检测器110,用于通过使用听觉环境(或聆听环境)的至少两个接收到的麦克风信号来检测一个或多个音频源的音频源信号部分。
[0058]
此外,该系统包括位置确定器120,用于将位置信息分派给一个或多个音频源中的每个音频源。
[0059]
此外,该系统包括音频类型分类器130,用于将音频信号类型分配给一个或多个音频源中的每个音频源的音频源信号部分。
[0060]
此外,该系统包括信号部分修改器140,用于根据一个或多个音频源中的至少一个音频源的音频源信号部分的音频信号类型来改变至少一个音频源的音频源信号部分,以便获得至少一个音频源的经修改的音频信号部分。
[0061]
此外,该系统包括信号发生器150,用于针对一个或多个音频源中的每个音频源,根据音频源的位置信息和用户头部的朝向,针对每个音频源产生多个双耳室内脉冲响应,以及用于根据多个双耳室内脉冲响应并且根据至少一个音频源的经修改的音频信号部分产生至少两个扬声器信号。
[0062]
根据实施例,例如,检测器110可以被配置为通过使用深度学习模型来检测一个或
多个音频源的音频源信号部分。
[0063]
在实施例中,例如,位置确定器120可以被配置为:针对一个或多个音频源中的每个音频源,根据捕获的图像或录制的视频来确定位置信息。
[0064]
根据实施例,例如,位置确定器120可以被配置为:针对一个或多个音频源中的每个音频源,根据视频,通过以下方式来确定位置信息:检测视频中人的嘴唇运动,并且根据嘴唇运动将该嘴唇运动分配给一个或多个音频源中的一个音频源的音频源信号部分。
[0065]
在实施例中,例如,检测器110可以被配置为根据至少两个接收到的麦克风信号来确定听觉环境的一个或多个声学属性。
[0066]
根据实施例,例如,信号发生器150可以被配置为根据听觉环境的一个或多个声学属性来确定多个双耳室内脉冲响应。
[0067]
在实施例中,例如,信号部分修改器140可以被配置为:根据先前学习的用户场景来选择其音频源信号部分被修改的至少一个音频源,并且根据该先前学习的用户场景来修改该至少一个音频源。
[0068]
根据实施例,例如,系统可以包括用户界面160,用于从两个或更多个先前学习的用户场景的组中选择先前学习的用户场景。图2示出了根据实施例的还包括这样的用户界面160的这样的系统。
[0069]
在实施例中,例如,检测器110和/或位置确定器120和/或音频类型分类器130和/或信号修改器140和/或信号发生器150可以被配置为使用霍夫变换或采用多个vlsi芯片或通过采用多个忆阻器来执行并行信号处理。
[0070]
根据实施例,例如,该系统可以包括听觉设备170,听觉设备170用作听觉能力受限和/或听觉受损的用户的助听器,其中,听觉设备包括用于输出至少两个扬声器信号的至少两个扬声器171、172。图3示出了根据实施例的这样的系统,其包括具有两个对应扬声器171、172的这样的听觉设备170。
[0071]
在实施例中,例如,该系统可以包括用于输出至少两个扬声器信号的至少两个扬声器181、182,以及容纳至少两个扬声器的壳体结构183,其中,至少一个壳体结构183适于固定到用户的头部185或用户的任何其他身体部位。图4示出了包括这样的壳体结构183和两个扬声器181、182的对应系统。
[0072]
根据实施例,例如,该系统可以包括耳机180,耳机180包括用于输出至少两个扬声器信号的至少两个扬声器181、182。图5示出了根据实施例的具有两个扬声器181、182的对应耳机180。
[0073]
在实施例中,例如,检测器110和位置确定器120和音频类型分类器130和信号部分修改器140和信号发生器150可以集成到耳机180中。
[0074]
根据实施例,如图6所示,例如,该系统可以包括远程设备190,远程设备190包括检测器110和位置确定器120和音频类型分类器130和信号部分修改器140和信号发生器150。在这种情况下,例如,远程设备190可以与耳机180在空间上分离。
[0075]
在实施例中,例如,远程设备190可以是智能手机。
[0076]
其中,实施例不一定使用微处理器,而是使用诸如霍夫变换、vlsi芯片或忆阻器之类的并行信号处理步骤,以用于实现节能,也用于人工神经网络。
[0077]
在实施例中,听觉环境在空间上被捕获和再现,其一方面使用多于一个信号来表
示输入信号,并且另一方面也使用空间再现。
[0078]
在实施例中,通过深度学习(dl)模型(例如,cnn、rcnn、lstm、siamese网络)进行信号分离,并同时处理来自至少两个麦克风声道的信息,其中,每个可听设备中至少存在一个麦克风。根据本发明,通过相互分析一起确定若干个输出信号(根据各个声源)和它们各自的空间位置。如果录制装置(麦克风)连接到头部,则对象的位置随着头部的运动而变化。这使得能够例如通过转向声音对象自然地专注于重要/不重要的声音。
[0079]
在一些实施例中,例如,用于信号分析的算法基于深度学习架构。备选地,这使用具有分析器的变型或具有分离网络的变型,用于定位、检测和声音分离方面。广义互相关(相关与时间偏移)的备选使用适配头部的取决于频率的阴影/隔离,并改进了定位、检测和源分离。
[0080]
根据实施例,检测器在训练阶段学习不同的源类别(例如,语音、车辆、男性/女性/儿童的声音、警告音等)。这里,源分离网络也被训练为高信号质量,以及具有目标刺激的定位网络,以实现高精度的定位。
[0081]
例如,上述训练步骤使用多声道音频数据,其中,第一轮训练通常在实验室中使用模拟或录制的音频数据进行。随后在不同的自然环境(例如客厅、教室、火车站、(工业)生产环境等)中进行训练,即执行迁移学习和域适配。
[0082]
备选地或附加地,位置检测器可以耦接到一个或多个相机,以便也确定声源的视觉位置。对于语音,嘴唇运动和来自源分离器的音频信号是相关的,实现了更精确的定位。
[0083]
在训练之后,存在具有网络架构和相关参数的dl模型。
[0084]
在一些实施例中,通过双耳合成进行听觉化。双耳合成提供了另一优势:可以不完全删除不期望的分量,而是将它们减少到可感知但不干扰的程度。这具有另一优势:可以感知在完全关闭的情况下会错过的意想不到的另外的源(警告信号、喊叫声
…
)。
[0085]
根据一些实施例,听觉环境的分析不仅用于分离对象,还用于分析声学属性(例如,混响时间、初始时间间隙)。然后在双耳合成中采用这些属性,以便使预先存储的(也可能是个性化的)双耳室内脉冲响应(brir)适配实际的房间(或空间)。通过减少室内发散,听者在理解经优化信号时显著降低了聆听努力。最小化室内发散对听觉事件的外部化有影响,因此对监控室中的空间音频再现的合理性有影响。对于语音理解或者对于经优化信号的一般理解,传统技术中没有已知的解决方案。
[0086]
在实施例中,用户界面用于确定选择了哪些声源。根据本发明,这通过预先学习不同的用户场景来完成,用户场景例如“从正前方放大语音”(与一个人的对话)、“在 -60度的范围内放大语音”(群组对话)、“抑制音乐并放大音乐”(我不想听到音乐会观众的声音),“让一切安静”(我想一个人呆着)、“抑制所有叫喊声和警告音”等。
[0087]
一些实施例不依赖于所使用的硬件,即可以使用开放式和封闭式耳机。信号处理可以集成到耳机中,可以在外部设备中,或者可以集成到智能手机中。可选地,除了再现声学录制和处理的信号之外,还可以直接从智能手机再现信号(例如,音乐、电话)。
[0088]
在其他实施例中,提供了“具有ai辅助的选择性听觉”的生态系统。实施例是指“个性化听觉现实”(party)。在这种个性化环境中,听者能够放大、减小或修改所定义的声学对象。为了创建适于各个需求的声音体验,要执行一系列分析和合成过程。目标转换阶段的研究工作形成了这一点的必要成分。
[0089]
一些实施例实现了真实声音环境的分析和各个声学对象的检测,可用对象的分离、跟踪和可编辑性,以及经修改的声学场景的重建和再现。
[0090]
在实施例中,实现了声音事件的检测、声音事件的分离以及一些声音事件的抑制。
[0091]
在实施例中,使用了ai方法(特别是基于深度学习的方法)。
[0092]
本发明的实施例有助于对空间音频的录制、信号处理和再现的技术开发。
[0093]
例如,实施例在具有交互用户的多媒体系统中产生空间性和三维性。
[0094]
在这种情况下,实施例基于空间听觉/聆听的感知和认知过程的研究知识。
[0095]
一些实施例使用以下概念中的两个或更多个:
[0096]
场景分解:这包括对真实环境的空间声学检测和参数估计和/或取决于位置的声场分析。
[0097]
场景表示:这包括对象和/或环境的表示和识别、和/或有效的表示和存储。
[0098]
场景组合与再现:这包括对象和环境的适配和变化、和/或渲染和听觉化。
[0099]
质量评估:这包括技术和/或听觉质量测量。
[0100]
麦克风定位:这包括麦克风阵列的应用和适当的音频信号处理。
[0101]
信号调理:这包括特征提取以及用于ml(机器学习)的数据集生成。
[0102]
室内和环境声学的估计:这包括对室内声学参数的现场测量和估计,和/或针对源分离和ml提供室内声学特征。
[0103]
听觉化:这包括具有对环境和/或验证和评估和/或功能证明和质量估计的听觉适配的空间音频再现。
[0104]
图8示出了根据实施例的对应场景。
[0105]
实施例结合了用于声源的检测、分类、分离、定位和增强的概念,其中突出了每个领域的最新进展,并指示了它们之间的联系。
[0106]
下面提供了能够组合/检测/分类/定位和分离/增强声源的连贯概念,以便提供现实生活中sh所需的灵活性和鲁棒性。
[0107]
此外,当处理现实生活中听觉场景的动态时,实施例提供了具有适于实时性能的低迟延概念。
[0108]
一些实施例使用用于深度学习、机器聆听和智能耳机(智能可听设备)的概念,使听者能够选择性地修改他们的听觉场景。
[0109]
实施例向听者提供了通过诸如头戴式耳机、耳机等听觉设备选择性地增强、衰减、抑制或修改听觉场景中的声源的可能性。
[0110]
图9示出了根据实施例的具有四个外部声源的场景。
[0111]
在图9中,用户是听觉场景的中心。在这种情况下,用户周围有四个外部声源(s1至s4)处于活动状态。用户界面使听者能够影响听觉场景。源s1至s4可以通过其对应的滑块被衰减、提高或抑制。如图1可以看出,听者可以定义应当保留在听觉场景中或从听觉场景中抑制的声源或声音事件。在图1中,城市的背景噪声应被抑制,而警报或电话铃声应被保留。在任何时候,用户有可能经由听觉设备再现(或播放)诸如音乐或无线电之类的附加音频流。
[0112]
用户通常是系统的中心,并且通过控制单元控制听觉场景。用户可以使用如图9所示的用户界面或使用诸如语音控制、手势、视线方向等任何类型的交互来修改听觉场景。一
旦用户已向系统提供了反馈,下一步就由检测/分类/定位阶段组成。在一些情况下,例如如果用户希望保留听觉场景中发生的任何语音,则仅需要检测。在其他情况下,例如如果用户希望在听觉场景中保持火警警报,而不保持电话铃声或办公室噪声,则可能需要进行分类。在一些情况下,仅源的位置与系统相关。例如,图9中的四个源就是这种情况:用户可以决定移除或衰减来自某个方向的声源,而不管源的类型或特性如何。
[0113]
图10示出了根据实施例的sh应用的处理工作流。
[0114]
首先,在图10的分离/增强阶段中修改听觉场景。这可以通过抑制、衰减或增强某个声源(例如,或者某些声源)来实现。如图10所示,sh中的附加处理备选是噪声控制,其目标是移除或最小化听觉场景中的背景噪声。也许最流行和最广泛的噪声控制技术是主动噪声控制(anc)[11]。
[0115]
通过将选择性听觉限制在其中仅在听觉场景中修改真实音频源的那些应用中而不试图将任何虚拟源添加到场景中,选择性听觉与虚拟增强的听觉环境不同。
[0116]
从机器聆听的角度来看,选择性听觉应用需要自动检测、定位、分类、分离和增强声源的技术。为了进一步阐明关于选择性听觉的术语,我们定义了以下术语,强调它们的差异和关系。
[0117]
在实施例中,例如,使用声源定位是指在听觉场景中检测声源位置的能力。在音频处理的上下文中,源位置通常是指给定源的到达方向(doa),当它包括仰角时,可以以2d坐标(方位角)或3d坐标给出。一些系统还估计从源到麦克风的距离作为位置信息[3]。在音乐处理的上下文中,位置通常是指源在最终混音中的平移,并且通常以度数为单位作为角度给出[4]。
[0118]
根据实施例,例如,使用声源检测是指确定给定声源类型的任何实例是否存在于听觉场景中的能力。检测任务的示例是确定场景中是否存在任何讲话者。在该上下文中,确定场景中讲话者的数量或讲话者的身份超出了声源检测的范围。检测可以被理解为二元分类任务,其中类别对应于“源存在”和“源不存在”。
[0119]
在实施例中,例如,使用声源分类,将来自一组预定义类别的类别标签分配给给定声源或给定声音事件。分类任务的示例是确定给定声源是否对应于语音、音乐或环境噪声。声源分类和检测是密切相关的概念。在一些情况下,分类系统包含检测阶段,将“无类别”视为可能的标签之一。在这些情况下,系统隐式地学习检测声源的存在或不存在,并且在没有足够证据表明任何源处于活动状态时不强制分配类别标签。
[0120]
根据实施例,例如,使用声源分离是指从音频混合或听觉场景中提取给定声源。声源分离的示例是从音频混合中提取歌声,其中除了歌手之外,其他乐器也在同时演奏[5]。声源分离在选择性听觉场景中变得相关,因为它允许抑制听者不感兴趣的声源。一些声音分离系统在从混音中提取声源之前隐式地执行检测任务。然而,这不一定是规则,因此,我们强调这些任务之间的区别。此外,分离通常用作诸如源增强[6]或分类[7]之类的其他类型分析的预处理阶段。
[0121]
在实施例中,例如,使用声源识别,其更进一步并且旨在识别声源在音频信号中的特定实例。讲话者识别可能是当今源识别的最常见用途。该任务的目标是识别场景中是否存在特定讲话者。在图1的示例中,用户已经选择“扬声器x”作为要保留在听觉场景中的源之一。这需要语音检测和分类之外的技术,并需要允许这种精确识别的讲话者特定模型。
[0122]
根据实施例,例如,使用声源增强是指在听觉场景中增加给定声源的突出性的过程[8]。在语音信号的情况下,目标通常是提高它们的感知质量和可理解性。语音增强的常见场景是对被噪声破坏的语音进行去噪[9]。在音乐处理的上下文中,源增强与重混的概念相关,并且通常被执行以使一种乐器(声源)在混音中更加突出。重混应用通常使用声音分离前端来获得对各个声源的访问并改变混音的特性[10]。尽管源增强之前可以存在声源分离阶段,但情况并非总是如此,因此我们也强调这些术语之间的区别。
[0123]
在声源检测、分类和识别的领域中,例如,一些实施例使用以下概念之一,例如声学场景和事件的检测和分类[18]。在该上下文中,已经提出了在家庭环境中进行音频事件检测(aed)的方法,其中目标是在10秒录音内检测给定声音事件的时间边界[19]、[20]。在该特定情况下,考虑了10个声音事件类别,包括猫、狗、语音、警报和流水。文献[21]、[22]中也已经提出了多音声音事件(若干个同时事件)检测的方法。在[21]中,提出了一种多音声音事件检测的方法,其中使用基于双向长短期记忆(blstm)循环神经网络(rnn)的二元活动检测器来检测来自现实生活背景的总共61个声音事件。
[0124]
一些实施例,例如,为了处理弱标记的数据,结合时间注意机制来关注信号的某些区域以进行分类[23]。分类中的噪声标签的问题与选择性听觉应用尤其相关,其中类别标签可以非常多样化,使得高质量的注释非常昂贵[24]。在[25]中解决了声音事件分类任务中的噪声标签,其中提出了基于分类交叉熵的抗噪声损失函数,以及评估噪声和手动标记数据二者的方法。类似地,[26]提出了一种基于卷积神经网络(cnn)的音频事件分类系统,其结合了基于cnn在训练示例的多个片段上的预测共识的噪声标签的验证步骤。
[0125]
例如,一些实施例实现了声音事件的同时检测和定位。因此,一些实施例将检测作为多标签分类任务执行,例如在[27]中,并且位置作为每个声音事件的到达方向(doa)的3d坐标给出。
[0126]
一些实施例使用sh的声音活动检测和讲话者认出/识别的概念。声音活动检测已经在嘈杂环境中使用去噪自动编码器[28]、循环神经网络[29]或作为使用原始波形的端到端系统[30]得到解决。对于讲话者识别应用,文献[31]中已经提出了大量系统,大多数系统专注于例如通过数据增强或通过促进识别的改进嵌入来提高对不同条件的鲁棒性[32]~[34]。因此,一些实施例使用这些概念。
[0127]
另外的实施例使用用于声音事件检测的乐器分类的概念。在文献[35]、[36]中已经解决了在单音和复音二者的设置中的乐器分类。在[35]中,在3秒音频片段中占主导地位的乐器被分为11个乐器类别,提出了若干种聚合技术。类似地,[37]提出了一种乐器活动检测方法,该方法能够以1秒的较精细的时间分辨率检测乐器。在歌声分析领域中已经进行了大量的研究。具体地,已经提出了诸如[38]的方法,用于检测音频录制中歌声处于活动状态的片段。一些实施例使用这些概念。
[0128]
一些实施例使用下面讨论的概念之一用于声源定位。声源定位与源计数的问题密切相关,因为听觉场景中的声源数量在现实生活应用中通常是未知的。一些系统在假设场景中的源数量已知的情况下工作。例如,[39]中提出的模型就是这种情况,该模型使用活动强度向量的直方图来定位源。从监督的角度来看,[40]提出了一种基于cnn的算法,以使用相位图作为输入表示来估计听觉场景中多个讲话者的doa。相反,文献中的若干个作品共同估计了场景中的源数量及其位置信息。[41]中就是这种情况,其中提出了一种在嘈杂和混
响环境中进行多讲话者定位的系统。该系统使用复值高斯混合模型(gmm)来估计源的数量及其定位。其中描述的概念被一些实施例使用。
[0129]
声源定位算法的计算要求很高,因为它们通常涉及扫描听觉场景周围的大空间[42]。为了减少定位算法中的计算需求,一些实施例使用如下概念来减少搜索空间:通过使用聚类算法[43]或通过对诸如基于转向响应功率相位变换(srp-phat)的方法的成熟方法执行多分辨率搜索[42]。其他方法强加稀疏约束并假设在给定时频域中只有一个声源占主导地位[44]。最近,在[45]中已经提出了一种直接从原始波形进行方位角检测的端到端系统。一些实施例使用这些概念。
[0130]
一些实施例使用随后描述的用于声源分离(sss)的概念,具体是来自语音分离和音乐分离的领域的概念。
[0131]
具体地,一些实施例使用与讲话者无关的分离的概念。在没有任何关于场景中的讲话者的先验信息的情况下执行分离[46]。一些实施例还评估讲话者的空间位置以便执行分离[47]。
[0132]
鉴于计算性能在选择性听觉应用中的重要性,以实现低时延为特定目标的研究具有特别相关性。已经提出了一些工作来执行低时延语音分离(《10ms),其中可用的训练数据很少[48]。为了避免在频域中由成帧分析引起的延迟,一些系统通过仔细设计要应用在时域中的滤波器来解决分离问题[49]。其他系统通过使用编码器-解码器框架直接对时域信号进行建模来实现低时延分离[50]。相反,一些系统已经试图减少频域分离方法中的成帧延迟[51]。这些概念被一些实施例采用。
[0133]
一些实施例使用音乐声音分离(mss)的概念,例如用于主奏乐器-伴奏分离的概念[52],从音频混合中提取音乐源[5]。这些算法采用混音中最突出的声源,无论其类别标签如何,并试图将它与其余伴奏分离。一些实施例使用用于歌声分离的概念[53]。在大多数情况下,使用特定源模型[54]或数据驱动的模型[55]来捕获歌声的特征。尽管诸如[55]中提出的系统未显式地结合分类或检测阶段来实现分离,但这些方法的数据驱动性质允许这些系统在分离之前隐式地学习以一定准确度检测歌声。音乐域中的另一类算法试图仅使用源的位置来执行分离,而不试图在分离之前对源进行分类或检测[4]。
[0134]
一些实施例使用主动噪声控制(anc)概念,例如主动噪声消除(anc)。anc系统主要旨在通过引入抗噪声信号消除背景噪声来移除耳机用户的背景噪声[11]。anc可以被视为sh的特例,并且面临着同样严格的性能要求[14]。一些已经工作专注于诸如汽车驾驶室[56]或工业场景[57]之类的特定环境中的主动噪声控制。[56]中的工作分析了诸如道路噪声和引擎噪声之类的不同类型噪声的消除,并要求能够处理不同类型噪声的统一噪声控制系统。一些工作已经专注于开发anc系统以消除特定空间区域上的噪声。在[58]中,使用球面谐波作为基函数表示噪声场来解决空间域上的anc。一些实施例使用本文描述的概念。
[0135]
一些实施例使用声源增强的概念。
[0136]
在语音增强的上下文中,最常见的应用之一是增强已经被噪声破坏的语音。大量工作已经专注于单声道语音增强的相位处理[8]。从深度神经网络的角度来看,语音去噪问题已经在[59]中通过去噪自动编码器解决为在[60]中使用深度神经网络(dnn)的干净语音与嘈杂语音之间的非线性回归问题,以及在[61]中使用产生对抗网络(gan)的端到端系统。在许多情况下,语音增强被应用为自动语音识别(asr)系统的前端,如[62]中语音增强是通
过lstm rnn进行的情况。语音增强也经常与声源分离方法结合进行,在该结合中,想法是首先提取语音,然后对经隔离的语音信号应用增强技术[6]。本文描述的概念被一些实施例使用。
[0137]
在大多数情况下,与音乐相关的源增强是指用于创建音乐重混的应用。与通常假设语音仅被噪声源破坏的语音增强相比,音乐应用大多假设其他声源(乐器)同时与要增强的源一起播放。出于这个原因,总是提供音乐重混应用,使得在它们之前存在源分离阶段。在[10]中,例如,通过应用主音伴奏与和声打击乐分离技术对早期的爵士乐录音进行重混,以便实现混音中更好的声音平衡。同样,[63]研究了使用不同的歌声分离算法以便改变歌声与背景音轨的相对响度,表明通过在最终混音中引入轻微但可听得见的失真,可以增加6db。在[64]中,作者研究了通过应用声源分离技术实现新的混音来增强人工耳蜗用户的音乐感知的方法。其中描述的概念被一些实施例使用。
[0138]
选择性听觉应用的最大挑战之一是对处理时间的严格要求。完整的处理工作流需要以最小的延迟执行,以便保持用户的自然性和感知质量。系统的最大可接受迟延高度取决于应用并取决于听觉场景的复杂性。例如,麦克弗森等人提出了10毫秒作为交互式音乐界面的可接受迟延参考[12]。对于网络上的音乐性能,[13]中的作者报告说,延迟在20毫秒至25毫秒与50毫秒至60毫秒之间变得可感知。然而,主动噪声控制/消除(anc)技术需要超低迟延处理以获得更好的性能。在这些系统中,可接受的迟延量取决于频率和衰减二者,但对于低于200hz的频率的约5db衰减,可以低至1毫秒[14]。sh应用中的最终考虑是指经修改的听觉场景的感知质量。大量工作已经致力于在不同应用中可靠评估音频质量的方法[15]、[16]、[17]。然而,sh面临的挑战是管理处理复杂度与感知质量之间的明确折衷。一些实施例使用其中描述的概念。
[0139]
一些实施例使用以下概念:如[41]中描述的用于计数/计算和定位,如[27]中描述的用于定位和检测,如[65]中描述的用于分离和分类,以及如[66]中描述的用于分离和计数。
[0140]
一些实施例使用用于增强当前机器聆听方法的鲁棒性的概念,如[25]、[26]、[32]、[34]中所描述的,其中新兴方向包括域适配[67]和对使用多个设备录制的数据集进行训练[68]。
[0141]
一些实施例使用如[48]中描述的用于提高机器聆听方法的计算效率的概念,或[30]、[45]、[50]、[61]中描述的能够处理原始波形的概念。
[0142]
一些实施例实现了以组合方式检测/分类/定位和分离/增强以便能够选择性地修改场景中的声源的统一优化方案,其中,独立的检测、分离、定位、分类和增强方法是可靠的并提供了sh所需的鲁棒性和灵活性。
[0143]
一些实施例适于实时处理,其中,在算法复杂度与性能之间存在良好的折衷。
[0144]
一些实施例结合了anc和机器聆听。例如,首先对听觉场景进行分类,然后选择性地应用anc。
[0145]
下面提供了另外的实施例。
[0146]
为了利用虚拟音频对象增强真实听觉环境,必须充分了解从音频对象的位置中的每一个到房间中听者的位置中的每一个的转换函数。
[0147]
转换函数对声源的属性、对象与用户之间的直达声以及房间中发生的所有反射进
行映射。为了确保听者当前所在的真实房间的室内声学的正确空间音频再现,转换函数还必须以足够的精度对听者房间的室内声学属性进行映射。
[0148]
在适合于表示房间中不同位置处的各个音频对象的音频系统中,在存在大量音频对象时,面临的挑战是对各个音频对象进行适当的检测和分离。此外,对象的音频信号在房间的录制位置或聆听位置重叠。当房间中的对象和/或聆听位置改变时,室内声学以及音频信号的重叠改变。
[0149]
对于相对运动,室内声学参数的估计必须足够快地执行。这里,估计的低迟延比高精度更重要。如果源和接收器的位置不变(静态情况),则需要高精度。在所提出的系统中,从音频信号流中估计或提取室内声学参数以及房间几何形状和听者位置。音频信号在真实环境中进行录制,在该真实环境中,源和接收器能够沿任何方向移动,并且其中源和/或接收器能够任意改变它们的朝向。
[0150]
音频信号流可以是包括一个或多个麦克风的任何麦克风装置的结果。将这些流馈送到信号处理阶段,用于预处理和/或进一步分析。然后,将输出馈送到特征提取阶段。该阶段估计室内声学参数,例如t60(混响时间)、drr(直接混响比)等。
[0151]
第二数据流由捕获麦克风装置的朝向和位置的6dof传感器(“六自由度”:三个维度,每个维度用于房间中的位置和观看方向)生成。将位置数据流馈送到6dof信号处理阶段,以进行预处理或进一步分析。
[0152]
6dof信号处理、音频特征提取阶段的输出以及经预处理的麦克风流被馈送到机器学习块中,在该机器学习块中估计听觉空间或聆听房间(大小、几何形状、反射表面)和房间中的麦克风场的位置。此外,应用用户行为模型以便实现更稳健的估计。该模型考虑了人类运动的极限(例如,连续运动、速度等),以及不同类型运动的概率分布。
[0153]
实施例中的一些通过使用任何麦克风布置并通过添加用户的位置和姿势信息以及通过使用机器学习方法分析数据来实现对室内声学参数的盲估计。
[0154]
例如,根据实施例的系统可以用于声学增强现实(aar)。在这种情况下,必须根据所估计的参数来合成虚拟室内脉冲响应。
[0155]
一些实施例包含从录制的信号中移除混响。这种实施例的示例是用于听觉正常的人和听觉受损的人的助听器。在这种情况下,可以借助于所估计的参数从麦克风装置的输入信号中移除混响。
[0156]
另一应用是在除了当前听觉空间之外的房间中生成的音频场景的空间合成。为此,相对于听觉空间的室内声学参数,调整作为音频场景一部分的室内声学参数。
[0157]
在双耳合成的情况下,为此,可用的brir适于听觉空间的不同声学参数。
[0158]
在实施例中,提供了一种用于确定一个或多个室内声学参数的装置。
[0159]
该装置被配置为获得包括一个或多个麦克风信号的麦克风数据。
[0160]
此外,该装置被配置为获得关于用户的位置和/或朝向的跟踪数据。
[0161]
此外,该装置被配置为根据麦克风数据并且根据跟踪数据来确定一个或多个室内声学参数。
[0162]
根据实施例,例如,该装置可以被配置为采用机器学习以根据麦克风数据并且根据跟踪数据来确定一个或多个室内声学参数。
[0163]
在实施例中,例如,该装置可以被配置为采用机器学习,因为该装置可以被配置为
采用神经网络。
[0164]
根据实施例,例如,该装置可以被配置为采用基于云的处理来进行机器学习。
[0165]
在实施例中,例如,一个或多个室内声学参数可以包括混响时间。
[0166]
根据实施例,例如,一个或多个室内声学参数可以包括直接混响比。
[0167]
在实施例中,例如,跟踪数据可以包括用于标记用户的位置的x坐标、y坐标和z坐标。
[0168]
根据实施例,例如,跟踪数据可以包括用于标记用户的朝向的俯仰坐标、偏航坐标和横滚坐标。
[0169]
在实施例中,例如,该装置可以被配置为将一个或多个麦克风信号从时域变换到频域,例如,其中,该装置被配置为提取一个或多个麦克风信号在频域中的一个或多个特征,例如,并且其中,该装置可以被配置为根据一个或多个特征来确定一个或多个室内声学参数。
[0170]
根据实施例,例如,该装置可以被配置为采用基于云的处理来提取一个或多个特征。
[0171]
在实施例中,例如,该装置可以包括若干个麦克风的麦克风布置以录制若干个麦克风信号。
[0172]
根据实施例,例如,麦克风布置可以被配置为佩戴在用户的身体上。
[0173]
在实施例中,例如,图1的上述系统还可以包括用于确定一个或多个室内声学参数的上述装置。
[0174]
根据实施例,例如,信号部分修改器140可以被配置为根据一个或多个室内声学参数中的至少一个,来执行一个或多个音频源中的至少一个音频源的音频源信号部分的改变;和/或其中,信号发生器150可以被配置为根据一个或多个室内声学参数中的至少一个,来执行针对一个或多个音频源中的每个音频源产生多个双耳室内脉冲响应中的至少一个。
[0175]
图7示出了根据实施例的包括五个子系统(子系统1至5)的系统。
[0176]
子系统1包括一个、两个或若干个单独的麦克风的麦克风装置,如果多于一个麦克风可用,则这些麦克风可以组合为麦克风场。麦克风/多个麦克风相对于彼此的定位和相对布置可以是任意的。麦克风布置可以是用户佩戴的设备的一部分,或者它可以是位于感兴趣房间中的单独设备。
[0177]
此外,子系统1包括跟踪设备,用于获得关于用户的位置和/或朝向的跟踪数据。例如,关于用户的位置和/或朝向的跟踪数据可用于确定用户在房间中的平移位置和用户的头部姿势。可以测量高达6dof(六个自由度,例如,x坐标、y坐标、z坐标、俯仰角、偏航角、横滚角)。
[0178]
在这种情况下,例如,跟踪设备可以被配置为测量跟踪数据。跟踪设备可以定位在用户的头部,或者也可以将它划分为若干个子设备来测量所需的自由度,并且它可以放置在用户身上或者不放置在用户身上。
[0179]
因此,子系统1表示包括麦克风信号输入接口101和位置信息输入接口102的输入接口。
[0180]
子系统2包括对录制的麦克风信号的信号处理。这包括频率变换和/或基于时域的处理。此外,这包括组合不同麦克风信号以实现场处理的方法。来自系统4的反馈是可能的,
以便在子系统2中调整信号处理的参数。麦克风信号的信号处理块可以是麦克风被内置到的设备的一部分,或者它可以是单独设备的一部分。它也可以是基于云的处理的一部分。
[0181]
此外,子系统2包括对录制的跟踪数据的信号处理。这包括频率变换和/或基于时域的处理。此外,它还包括通过采用噪声抑制、平滑、插值和外推来增强信号的技术质量的方法。此外,它包括用于导出更高级别信息的方法。这包括速度、加速度、路径方向、空闲时间、移动范围和移动路径。此外,这包括对近期的移动路径和近期的速度的预测。跟踪信号的信号处理块可以是跟踪设备的一部分,或者它可以是单独设备的一部分。它也可能是基于云的处理的一部分。
[0182]
子系统3包括对经处理的麦克风的特征的提取。
[0183]
特征提取块可以是用户的可穿戴设备的一部分,或者它可以是单独设备的一部分。它也可以是基于云的处理的一部分。
[0184]
子系统2和3例如利用它们的模块111和121一起实现了检测器110、音频类型分类器130和信号部分修改器140。例如,子系统3的模块121可以将音频分类的结果输出到子系统2的模块111(反馈)。例如,子系统2的模块112实现了位置确定器120。此外,在实施例中,子系统2和3还可以例如通过子系统2的模块111产生双耳室内脉冲响应和扬声器信号来实现信号发生器150。
[0185]
子系统4包括通过使用经处理的麦克风信号、所提取的麦克风信号的特征和经处理的跟踪数据来估计室内声学参数的方法和算法。该块的输出是作为空闲数据的室内声学参数,以及对子系统2中麦克风信号处理的参数的控制和变化。机器学习块131可以是用户设备的一部分,或者它可以是单独设备的一部分。它也可以是基于云的处理的一部分。
[0186]
此外,子系统4包括对室内声学空闲数据参数的后处理(例如,在块132中)。这包括检测异常值、将各个参数组合为新参数、平滑、外推、插值和合理性验证。该块还从子系统2获得信息。这包括用户在房间中的近期位置,以便估计近期的声学参数。该块可以是用户设备的一部分,或者它可以是单独设备的一部分。它也可以是基于云的处理的一部分。
[0187]
子系统5包括针对下游系统(例如,在存储器141中)的室内声学参数的存储和分配。可以立即实现参数的分配,和/或可以存储时间响应。可以在位于用户身上或用户附近的设备中执行存储,或者可以在基于云的系统中执行存储。
[0188]
下面描述本发明的实施例的用例。
[0189]
实施例的用例是家庭娱乐,并且涉及家庭环境中的用户。例如,用户希望专注于诸如电视、收音机、pc、平板电脑之类的某些再现设备,并希望抑制其他干扰源(其他用户的设备、或儿童、建筑噪声、街道噪声)。在这种情况下,用户位于优选再现设备的附近并选择设备或其位置。无论用户的位置如何,所选择的设备或声源位置都在声学上得到强调,直到用户取消他/她的选择。
[0190]
例如,用户移动到目标声源附近。用户经由适当的界面选择目标声源,并且可听设备基于用户位置、用户观看方向和目标声源相应地调整音频再现,以便即使在干扰噪声的情况下也能够更好地听清目标声源。
[0191]
备选地,用户移动到特别干扰人的声源附近。用户经由适当的界面选择该干扰声源,可听设备(听觉设备)基于用户位置、用户观看方向和干扰声源相应地调整音频再现,以便显式地调出干扰声源。
[0192]
另一实施例的另一用例是其中用户位于若干个讲话者之间的鸡尾酒会。
[0193]
在存在许多讲话者的情况下,例如,用户希望专注于其中一个(或若干个),并希望调出或衰减其他干扰声源。在该用例中,对可听设备的控制应仅需要用户很少的交互。基于生物信号或对话中困难的可检测指示(常见问题、外语、强方言)来控制选择性的强度将是可选的。
[0194]
例如,讲话者是随机分布的,并且相对于听者移动。此外,存在周期性的语音暂停、添加新的讲话者或其他讲话者离开场景。可能地,诸如音乐之类的干扰声音相当响亮。所选择的讲话者在语音暂停、改变他/她的位置或姿势之后被再次识别。
[0195]
例如,可听设备识别用户附近的讲话者。通过适当的控制可能性(例如,观看方向、注意力控制),用户可以选择喜欢的讲话者。可听设备根据用户的观看方向和所选择的目标声源调整音频再现,以便即使在干扰噪声的情况下也能够很好地听清目标声源。
[0196]
备选地,如果(先前)不喜欢的讲话者直接与用户联系,则他/她必须至少是可听见的,以便确保自然交流。
[0197]
另一实施例的另一用例是在机动车辆中,其中用户位于他/她的机动车辆中(或在机动车辆中)。在驾驶期间,用户希望将他/她的听觉注意力主动引导到某些再现设备上,例如导航设备、收音机或对话伙伴上,以便能够在干扰噪声(风、电机、乘客)的旁边更好地听清它们。
[0198]
例如,用户和目标声源位于机动车辆内的固定位置处。用户相对于参考系统静止,然而,车辆本身正在运动。这需要调整的跟踪解决方案。所选择的声源位置在声学上被强调,直到用户取消选择或直到警告信号中断设备的功能。
[0199]
例如,用户进入机动车辆,并且设备检测周围环境。通过适当的控制可能性(例如,速度识别),用户可以在目标声源之间切换,并且可听设备根据用户的观看方向和所选择的目标声源调整音频再现,以便即使在干扰噪声的情况下也能够很好地听清目标声源。
[0200]
备选地,例如,与交通相关的警告信号中断正常流程并取消用户的选择。然后执行正常流程的重新启动。
[0201]
另一实施例的另一用例是现场音乐并且涉及现场音乐活动的客人。例如,音乐会或现场音乐表演的客人希望借助于可听设备来提高对表演的关注度,并希望调出行为干扰人的其他客人。此外,可以优化音频信号本身例如以便平衡不利的聆听位置或室内声学。
[0202]
例如,用户位于许多干扰声源之间;然而,在大多数情况下,表演都相对响亮。目标声源位于固定位置处或至少位于定义区域中,然而,用户可以非常灵活(例如,用户可以正在跳舞)。所选择的声源位置在声学上被强调,直到用户取消选择或直到警告信号中断设备的功能。
[0203]
例如,用户选择舞台区域或音乐人作为目标声源。通过适当的控制可能性,用户可以定义舞台/音乐人的位置,并且可听设备根据用户的观看方向和所选择的目标声源调整音频再现,以便即使在干扰噪声的情况下也能够很好地听清目标声源。
[0204]
备选地,例如,警告信息(例如,疏散、在露天活动的情况下雷暴即将到来)和警告信号可以中断正常流程并取消用户的选择。之后,将重新启动正常流程。
[0205]
另一实施例的另一用例是重大活动,并且涉及重大活动的客人。因此,在大型活动中(例如,足球场、冰球馆、大型音乐厅等),可听设备可用于强调家人和朋友的声音,否则这
些声音将被人群的噪声淹没。
[0206]
例如,在体育场或大型音乐厅举行的具有许多参加者的重大活动。一组人(家人、朋友、学校班级)参加活动,并位于活动位置外或活动位置内,该活动位置有一大群人四处走动。一个或若干个孩子失去了与这组人的目光接触,并且尽管噪声很大,但他们还是呼唤这组人。然后,用户关闭声音识别,并且可听设备不再放大声音。
[0207]
例如,该组人中的一个人在可听设备上选择失踪儿童的声音。可听设备定位该声音。然后,可听设备放大该声音,并且用户可以基于经放大的声音(更快地)找回失踪儿童。
[0208]
备选地,例如,失踪儿童也佩戴可听设备并选择他/她父母的声音。可听设备将父母的声音放大。通过放大,孩子然后可以找到他/她的父母。因此,孩子可以步行回到他/她的父母身边。备选地,例如,失踪儿童也佩戴可听设备并选择他/她父母的声音。可听设备定位父母的声音,并且可听设备通知声音的距离。这样,孩子可以更容易地找到他/她的父母。可选地,可以提供来自可听设备的人造声音的再现以用于距离的通知。
[0209]
例如,提供用于选择性放大声音的可听设备的耦接,并存储声音配置文件。
[0210]
另一实施例的另一用例是休闲运动并且涉及休闲运动员。在运动期间听音乐很流行;然而,它也带来危险。可能听不到警告信号或其他道路使用者。除了音乐的再现之外,可听设备还可以对警告信号或喊叫做出反应并暂时中断音乐再现。在这种上下文中,另一用例是小组的运动。可以连接运动组的可听设备,以确保运动期间的良好交流,同时抑制其他干扰噪声。
[0211]
例如,用户是移动的,并且可能的警告信号被许多干扰声源重叠。问题在于,并非所有警告信号都可能与用户有关(城市中的远程警报器、街道上的喇叭)。因此,可听设备自动停止音乐再现并在声音上强调通信伙伴的警告信号,直到用户取消选择。随后,音乐被正常再现。
[0212]
例如,用户正在从事体育运动并通过可听设备聆听音乐。自动检测与用户有关的警告信号或喊叫声,并且可听设备中断音乐的再现。可听设备调整音频再现能够很好地听清目标声源/声学环境。可听设备然后自动或根据用户的请求继续音乐的再现(例如,在警告信号结束之后)。
[0213]
备选地,例如,一组运动员可以连接他们的可听设备。优化了组成员之间的语音可理解性,并抑制了其他干扰噪声。
[0214]
另一实施例的另一用例是抑制打鼾,并且涉及所有希望入睡但被打鼾打扰的人。其伴侣打鼾的人在夜间休息时被打扰,并且出现睡眠问题。可听设备可以提供缓解,因为它可以抑制打鼾声,确保夜间休息,并提供家庭安宁。同时,可听设备让其他声音(婴儿哭声、警报声等)通过,从而使用户在声学上与外界不完全隔离。例如,提供打鼾检测。
[0215]
例如,用户因打鼾声而出现睡眠问题。通过使用可听设备,然后,用户可以再次睡得更好,这具有减轻压力的作用。
[0216]
例如,用户在睡眠期间佩戴可听设备。他/她将可听设备切换到睡眠模式,该睡眠模式抑制所有打鼾声。在睡着之后,他/她再次关闭可听设备。
[0217]
备选地,可以在睡眠期间抑制诸如建筑噪声、割草机噪声等其他声音。
[0218]
另一实施例的另一用例是日常生活中用户的诊断设备。可听设备录制偏好(例如,选择了哪些声源,选择了哪种衰减/放大)并经由使用持续时间创建具有趋势的配置文件。
该数据可以得出关于听觉能力改变的结论。其目的是尽早检测到听力损失。
[0219]
例如,用户在他/她的日常生活中或在所提到的用例中携带该设备若干月或若干年。可听设备基于所选的设置来创建分析,并向用户输出警告和建议。
[0220]
例如,用户长时间(数月至数年)佩戴可听设备。该设备基于听觉偏好进行分析,并在出现听觉损失的情况下输出建议和警告。
[0221]
另一实施例的另一用例是治疗设备并且涉及日常生活中听觉受损的用户。作为听觉设备的过渡设备,尽早帮助潜在患者,并且因此对痴呆症进行预防性治疗。其他可能性是用作注意力训练器(例如,用于adhs)、治疗耳鸣和减轻压力。
[0222]
例如,听者具有听觉问题或注意力缺陷,并暂时/临时使用可听设备作为听觉设备。取决于听觉问题,可以通过可听设备缓解它,例如通过:所有信号的放大(听觉困难)、对优选声源的高选择性(注意力缺陷)、治疗声音的再现(耳鸣治疗)。
[0223]
用户独立地或在医生的建议下选择治疗形式并进行优选的调整,并且可听设备执行所选择的治疗。
[0224]
备选地,可听设备根据uc-pro1检测听觉问题,并且可听设备基于检测到的问题自动调整再现并通知用户。
[0225]
另一实施例的另一用例是公共部门的工作,涉及公共部门的员工。公共部门(医院、儿科医生、机场柜台、教育工作者、餐饮业、服务柜台等)中在他们的工作期间受到高强度噪声影响的员工佩戴可听设备以强调一个人或仅少数人的语音,以例如通过减轻压力来更好地交流并提供更好的工作安全性。
[0226]
例如,员工在工作环境中受到高强度噪声的影响,并且尽管有背景噪声,但在不能切换到更安静环境的情况下,他们必须与客户、患者或同事交谈。医院员工因医疗设备的声音和哔哔声(或任何其他与工作相关的噪声)受到高强度噪声的影响,并且仍然必须能够与患者或同事交流。儿科医生和教育工作者在孩子们的噪声或叫喊声中工作,并且必须能够与父母交谈。在机场柜台,在机场大厅噪声很大的情况下,员工很难听清航空公司的乘客。在人来人往的餐厅里,服务员很难在噪声中听到顾客的命令。然后,例如,用户关闭声音选择,并且可听设备不再放大声音。
[0227]
例如,一个人打开已安装的可听设备。用户将可听设备设置为对附近语言的声音选择,并且可听设备对最近的声音或附近的若干声音进行放大,并且同时抑制背景噪声。用户然后更好地听清相关声音。
[0228]
备选地,一个人将可听设备设置为连续噪声抑制。用户打开该功能以检测可用的声音,然后将该声音放大。因此,用户可以继续在较低级别噪声下工作。在直接解决了附近x米时,可听设备然后对声音进行放大。因此,用户可以在低级别噪声下与其他人交谈。在交谈之后,可听设备切换回噪声抑制模式,并且在工作之后,用户再次关闭可听设备。
[0229]
另一实施例的另一用例是乘客的运输,并且涉及用于运输乘客的机动车辆中的用户。例如,乘客运输车的用户和驾驶员希望在驾驶期间尽可能少地被乘客分心。尽管乘客是主要的干扰声源,但不时与他们交流是必要的。
[0230]
例如,用户或驾驶员以及干扰源位于机动车辆内的固定位置。用户相对于参考系统静止,然而,车辆本身正在移动。这需要调整的跟踪解决方案。因此,除非要进行通信,否则乘客的声音和对话在默认情况下被声学抑制。
[0231]
例如,可听设备在默认情况下抑制乘客的干扰噪声。用户可以通过适当的控制可能性(语音识别、车辆中的按钮)手动取消抑制。这里,可听设备根据选择来调整音频再现。
[0232]
备选地,可听设备检测到乘客主动与驾驶员交谈,并暂时停用噪声抑制。
[0233]
另一实施例的另一用例是学校和教育,涉及课堂中的老师和学生。在示例中,可听设备具有两个角色,其中设备的功能部分地被耦合。老师/讲话者的设备抑制干扰噪声并放大来自学生的语音/问题。此外,听者的可听设备可以通过老师的设备进行控制。因此,可以强调特别重要的内容而不必大声说话。学生可以设置他们的可听设备,以便能够更好地听清老师并排除打扰的同学。
[0234]
例如,老师和学生位于封闭空间中的定义区域内(这是规则)。如果所有设备彼此耦接,则相对位置是可交换的,这继而简化了源分离。所选的声源在声学上被强调,直到用户(老师/学生)取消选择,或直到警告信号中断设备的功能。
[0235]
例如,老师或讲话者呈现内容,并且设备抑制干扰噪声。老师想听到学生的问题,并将可听设备的焦点改变为具有问题的人(自动或经由适当的控制可能性)。在交流之后,所有声音再次被抑制。此外,可以规定,例如,感觉被同学打扰的学生在声学上将这些同学调出。此外,例如,座位远离老师的学生可以放大老师的声音。
[0236]
备选地,例如,老师和学生的设备可以耦接。学生设备的选择性可以经由老师设备临时控制。在内容特别重要的情况下,老师改变学生设备的选择性以放大他/她的声音。
[0237]
另一实施例的另一用例是军队,并且涉及士兵。战场上士兵之间的口头交流一方面经由无线电进行,另一方面经由喊叫和直接接触进行。如果要在不同单元与子组之间进行通信,则大多使用无线电。通常使用预定的无线电礼仪。喊叫和直接接触大多发生在小队或组内的交流。在士兵执行任务期间,可能出现困难的声学条件(例如,尖叫的人、武器的噪声、恶劣的天气),这些声学条件可能损害两条通信路径。具有耳机的无线电装置通常是士兵装备的一部分。除了音频再现的目的之外,它们还提供保护功能以防止更大级别的声压。这些设备通常配备有麦克风,以便将环境信号传送到承运人的耳朵。主动噪声抑制也是这类系统的一部分。功能范围的增强/扩展通过干扰噪声的智能衰减和具有定向再现的语音的选择性强调,使士兵能够在噪声环境中进行喊叫和直接接触。为此,必须知道士兵在房间/场地中的相对位置。此外,语音信号和干扰噪声必须在空间上和内容上相互分离。该系统还必须能够处理从耳语到尖叫和爆炸声的高snr级别。这种系统的优点如下:士兵之间在噪声环境中的口头交流、维持听力保护、可放弃无线电礼仪、拦截安全(因为它不是无线电解决方案)。
[0238]
例如,执行任务的士兵之间的喊叫和直接接触可以因干扰噪声而变得复杂。这个问题目前通过近场和更大距离的无线电解决方案来解决。通过对各个讲话者的智能空间强调以及周围噪声的衰减,新系统实现了近场中的喊叫和直接接触。
[0239]
例如,士兵正在执行任务。自动检测喊叫声和语音,并且系统通过同时衰减背景噪声来放大它们。该系统调整空间音频再现,以便能够很好地听清目标声源。
[0240]
备选地,例如,系统可以知道一组的士兵。仅允许通过这些组成员的音频信号。
[0241]
另一实施例的另一用例涉及安保人员和保安。因此,例如,可听设备可以用于令人困惑的重大事件(庆祝活动、抗议活动)以抢先检测犯罪。可听设备的选择性由关键字(例如,呼救或诉诸暴力)控制。这以音频信号(例如,语音识别)的内容分析为前提。
[0242]
例如,保安被其中保安和所有声源可能在移动的许多响亮的声源包围。在正常听觉条件下,无法听到有人呼救的声音或仅听到其有限程度(恶劣的snr)的声音。手动或自动选择的声源在声学上被强调,直到用户取消选择。可选地,将虚拟声音对象放置在感兴趣声源的位置/方向,以便能够容易地找到位置(例如,对于一次性求助的情况)。
[0243]
例如,可听设备检测具有潜在危险源的声源。保安选择他/她希望跟随的声源或事件(例如,通过平板电脑上的选择)。随后,可听设备调整音频再现,以便即使在干扰噪声的情况下也能够很好地听清和定位声源。
[0244]
备选地,例如,如果目标声源是无声的,则可以向源/在源的距离内放置定位信号。
[0245]
另一实施例的另一用例是舞台上的交流,并且涉及音乐人。在舞台上,在排练或音乐会(例如,乐队、管弦乐队、合唱团、音乐剧)中,由于声学条件困难,可能无法听到单个乐器(团体)的声音,即使在其他环境中仍能听到它们。这损害了交互,因为不再可感知重要的(伴随的)声音。可听设备可以强调这些声音并使它们再次可听到,并且因此可以改善或确保各个音乐人的互动。通过使用,例如通过衰减鼓声可以减少各个音乐人的噪声暴露,并且可以防止听觉损失,以及音乐人可以同时听到所有重要的东西。
[0246]
例如,没有可听设备的音乐人在舞台上不再听到至少一个其他声音。在这种情况下,可以使用可听设备。在排练或音乐会之后,用户在关闭可听设备之后将它取下。
[0247]
在示例中,用户打开可听设备。用户选择一个或多个期望的要被放大的乐器。在一起制作音乐时,所选择的乐器被放大,并且因此被可听设备再次听到。在制作音乐之后,用户再次关闭可听设备。
[0248]
在另一示例中,用户打开可听设备。用户选择需要降低其音量的期望的乐器。在一起制作音乐时,可听设备可以降低所选择的乐器的音量,以便用户只能以适中的音量听到它。
[0249]
例如,乐器配置文件可以存储在可听设备中。
[0250]
另一实施例的另一用例是在生态系统意义上将源分离作为听力设备的软件模块,并且涉及听觉设备的制造商或听觉设备的用户。制造商可以使用源分离作为其听觉设备的附加工具,并可以将其提供给客户。因此,听觉设备也可以从开发中受益。其他市场/设备(耳机、手机等)的许可模式也是可以想象的。
[0251]
例如,听觉设备的用户很难在复杂的听觉情况下分离不同的源,例如以专注于某个讲话者。为了能够在没有外部附加系统的情况下进行选择性倾听(例如,经由蓝牙从移动无线电装置传输信号,经由fm设备或感应听觉设备在教室中进行选择性信号传输),用户使用具选择性听觉的附加功能的听觉设备。因此,即使没有外部努力,用户也可以通过源分离来关注各个源。最后,用户关闭附加功能,并继续使用听觉设备正常倾听。
[0252]
例如,听觉设备用户获取了具有集成的用于选择性听觉的附加功能的新听觉设备。用户在听觉设备上设置选择性听觉的功能。然后,用户选择配置文件(例如,放大最响亮/最近的源,放大个人周围环境的某些声音的语音识别(例如,在uc-ce5重大事件中))。听觉设备根据所设置的配置文件放大各个源,在需要时同时抑制背景噪声,并且听觉设备的用户从复杂听觉场景中听到各个源,而不仅仅是“噪声”/杂乱的声源。
[0253]
备选地,听觉设备用户获取用于选择性听觉的附加功能作为用于他/她自己的听觉设备的软件等。用户为他/她的听觉设备安装附加功能。然后,用户在听觉设备上设置选
择性听觉的功能。用户选择配置文件(放大最响亮/最近的源,放大来自个人周围环境的某些声音的语音识别(例如,在uc-ce5重大事件中)),并且听觉设备根据所设置的配置文件放大各个源,以及在需要时同时抑制背景噪声。在这种情况下,听觉设备用户听到来自复杂听觉场景的各个声源,而不仅仅是“噪声”/杂乱的声源。
[0254]
例如,可听设备可以提供可存储的声音配置文件。
[0255]
另一实施例的另一用例是职业运动,并且涉及比赛中的运动员。在诸如冬季两项、铁人三项、自行车、马拉松等运动中,职业运动员依靠他们教练的信息或与队友的交流。然而,也存在这些情况:他们希望保护自己免受响亮声音(冬季两项中的射击、大声欢呼、派对喇叭等)的影响以便能够集中注意力。可听设备可以针对各个运动/运动员进行调整,以便能够全自动选择相关声源(检测某些声音、典型干扰噪声的音量限制)。
[0256]
例如,用户可以非常灵活,并且干扰噪声的类型取决于运动。由于强烈的身体压力,运动员无法或仅在有限程度的范围内控制设备。然而,在大多数运动中,存在预定的程序(冬季两项:跑、射击),并且重要的交流伙伴(教练、队友)可以提前定义。噪声通常或在活动的某些阶段被抑制。始终强调运动员与队友和教练之间的交流。
[0257]
例如,运动员使用专门针对运动类型调整的可听设备。可听设备完全自动(预先被调整)地抑制干扰噪声,特别是在相应类型运动中需要高度关注的情况下。此外,当教练和团队成员在听觉范围内时,可听设备会全自动(预先被调整)地强调他们。
[0258]
另一实施例的另一用例是听觉训练并且涉及音乐学生、专业音乐人、爱好音乐人。对于音乐排练(例如,在管弦乐队、乐队、合奏团、音乐课中),选择性地使用可听设备以便能够以过滤的方式跟踪各个声音。尤其是在排练开始时,聆听乐曲的最终录音并跟踪自己的声音是很有帮助的。取决于组成,无法很好地听到背景中的声音,因为人们只能听到前景中的声音。通过可听设备,可以基于乐器等选择性地强调声音,以便能够更有针对性地进行练习。
[0259]
(有抱负的)音乐学生也可以使用可听设备来训练他们的听力能力,以便通过逐步最小化各个强调直到他们最终在没有帮助的情况下从复杂作品中提取各个声音,选择性地准备入学考试。
[0260]
例如,如果附近没有singstar等,另一可能的用例是卡拉ok。可以在需要时从一段音乐中抑制歌声,以便仅听到卡拉ok的乐器版本。
[0261]
例如,音乐人开始从音乐作品中学习声音。他/她通过cd播放器或任何其他再现介质聆听音乐片段的录音。如果用户完成练习,则他/她将再次关闭可听设备。
[0262]
在示例中,用户打开可听设备。他/她选择期望的要放大的乐器。在聆听音乐时,可听设备放大乐器的声音,降低其余乐器的音量,并且用户因此可以更好地跟踪他/她自己的声音。
[0263]
在另一示例中,用户打开可听设备。他/她选择期望的要抑制的乐器。在聆听音乐时,所选择的音乐的声音被抑制,使得只能听到其余的声音。用户然后可以用其他声音练习自己乐器上的声音,而不被录音中的声音分心。
[0264]
在示例中,可听设备可以提供存储的乐器配置文件。
[0265]
另一实施例的另一用例是工作安全,并且涉及响亮环境中的工人。在诸如机械车间或工地的响亮环境中的工人必须保护自己免受噪声影响,但他们还必须能够感知警告信
号并与同事进行交流。
[0266]
例如,用户位于非常响亮的环境中,并且目标声源(警告信号、同事)可能比干扰噪声显著柔和。用户可能是移动的;然而,干扰噪声通常是固定的。与听觉保护一样,噪声被永久降低,并且可听设备会全自动强调警告信号。讲话者声源的放大确保了与同事进行的交流。
[0267]
例如,用户在工作中并使用可听设备作为听觉保护装置。警告信号(例如,火警)在声学上被强调,并且在必要时,用户停止他/她的工作。
[0268]
备选地,例如,用户在工作中并使用可听设备作为听觉保护装置。如果需要与同事进行交流,则选择交流伙伴并借助适当的界面(这里例如:眼控)在声学上强调。
[0269]
另一实施例的另一用例是将源分离作为用于现场翻译器的软件模块,并且涉及现场翻译器的用户。现场翻译器实时翻译口语外语,并且可以从用于进行源分离的上游软件模块中受益。特别是在存在多个讲话者的情况下,软件模块可以提取目标讲话者并潜在地改进翻译。
[0270]
例如,软件模块是实时翻译器(智能手机上的专用设备或应用)的一部分。例如,用户可以通过设备的显示来选择目标讲话者。有利的是,用户和目标声源在翻译期间不移动或仅移动一点点。所选择的声源位置在声学上被强调,并且因此可以改进翻译。
[0271]
例如,用户希望用外语进行对话或希望聆听使用外语的讲话者。用户通过适当的界面(例如:显示屏上的gui)选择目标讲话者,并且软件模块优化音频录制以供翻译器进一步使用。
[0272]
另一实施例的另一用例是救援部队的工作安全,并且涉及消防员、民防、警察部队、紧急服务。对于救援部队来说,良好的交流对于成功执行任务至关重要。尽管周围噪声很响亮,但救援部队通常不可能进行听觉保护,因为这会使交流变得不可能。例如,消防员必须准确传达命令并能够听清它们,例如尽管经由收音机部分产生的电机声很响亮。因此,救援部队受到很大的噪声暴露,在该噪声暴露中无法遵守听觉保护条例。一方面,可听设备将为救援部队提供听觉保护,而另一方面,将仍然能够实现救援部队之间的交流。此外,在可听设备的帮助下,救援部队在携带头盔/防护设备时不会在声学上与环境分离,因此可以提供更好的支持。他们可以更好地进行交流,并且也能够更好地估计自己的危险(例如,听到正在发生的火灾的类型)。
[0273]
例如,用户受到强烈的周围噪声影响,因此无法佩戴听觉保护装置,但仍必须能够与其他人交流。他/她使用可听设备。在任务完成或危险结束之后,用户再次摘下可听设备。
[0274]
例如,用户在执行任务期间佩戴可听设备。他/她打开可听设备。可听设备抑制周围噪声并放大附近同事和其他讲话者(例如,火灾受害者)的讲话。
[0275]
备选地,用户在执行任务期间佩戴可听设备。他/她打开可听设备,并且可听设备抑制周围噪声并通过无线电放大同事的讲话。
[0276]
在适用的情况下,可听设备经过专门设计,以满足根据操作规范进行操作的结构适用性。可能地,可听设备包括到无线电设备的接口。
[0277]
即使已在设备的上下文中描述了一些方面,应当理解:所述方面还表示了对对应方法的描述,使得设备的块或结构部件还被理解为对应的方法步骤或方法步骤的特征。类似地,在方法步骤的上下文内描述或被描述为方法步骤的方面也表示对相应设备的相应块
或细节或特征的描述。可以在使用硬件设备(例如微处理器、可编程计算机或电子电路)时执行一些或全部方法步骤。在一些实施例中,最重要的方法步骤中的一些或若干可以由这种设备来执行。
[0278]
取决于具体实现要求,本发明的实施例可以用硬件或软件来实现。可以在使用如下数字存储介质的同时来实现各种实现方式,例如软盘、dvd、蓝光盘、cd、rom、prom、eprom、eeprom或闪存、硬盘或任何其他磁或光存储器,其上存储有电可读控制信号,该信号可以与可编程计算机系统协作或合作,使得执行相应方法。因此,数字存储介质可以是计算机可读的。
[0279]
因此,根据本发明的一些实施例包括数据载体,该数据载体包括能够与可编程计算机系统合作以执行本文描述的任何方法的电可读控制信号。
[0280]
一般而言,本发明的实施例可被实现为具有程序代码的计算机程序产品,该程序代码用于在计算机上运行计算机程序产品时执行任何方法。
[0281]
该程序代码还可以存储在例如机器可读载体上。
[0282]
其他实施例包括用于执行本文描述的任何方法的计算机程序,该计算机程序存储在机器可读载体上。换言之,本发明方法的实施例从而是具有程序代码的计算机程序,该程序代码用于在计算机上运行计算机程序时执行本文描述的任何方法。
[0283]
本发明方法的另一实施例因此是数据载体(或数字存储介质或计算机可读介质),其上记录有用于执行本文描述的任何方法的计算机程序。数据载体、数字存储介质或记录的介质通常是有形的和/或非易失性的。
[0284]
本发明方法的另一实施例因此是表示用于执行本文描述的任何方法的计算机程序的数据流或信号序列。数据流或信号序列可被配置为例如经由数据通信链路(例如,经由互联网)来发送。
[0285]
另一实施例包括例如计算机或可编程逻辑器件之类的处理单元,其被配置为或适于执行本文描述的任何方法。
[0286]
另一实施例包括其上安装有用于执行本文描述的任何方法的计算机程序的计算机。
[0287]
根据本发明的另一实施例包括被配置为用于向接收器发送用于执行本文描述的至少一个方法的计算机程序的设备或系统。例如,传输可以是电子的或光学的。例如,接收器可以是计算机、移动设备、存储器设备或类似设备。例如,该设备或系统可以包括用于向接收器发送计算机程序的文件服务器。
[0288]
在一些实施例中,可编程逻辑器件(例如,现场可编程门阵列fpga)可以用于执行本文描述的方法的一些或全部功能。在一些实施例中,现场可编程门阵列可以与微处理器协作,以执行本文描述的任何方法。一般而言,在一些实施例中,方法由任何硬件设备来执行。所述硬件设备可以是任何通用硬件,例如计算机处理器(cpu),或者可以是方法专用的硬件,例如asic。
[0289]
上述实施例仅表示对本发明的原理的说明。应理解,本领域其他技术人员将意识到对于本文描述的布置和细节的修改和变化。因此,本发明旨在仅由所附权利要求的范围来限定,而不由本文中通过对实施例的描述和讨论提出的具体细节来限定。
[0290]
参考文献
[0291]
[1]v.valimaki,a.franck,j.ramo,h.gamper,and l.savioja,“assisted listening using a headset:enhancing audio perception in real,augmented,and virtual environments,”ieee signal processing magazine,volume 32,no.2,pp.92
–
99,march 2015.
[0292]
[2]k.brandenburg,e.cano,f.klein,t.h.lukashevich,a.neidhardt,u.sloma,and s.werner,“plausible augmentation of auditory scenes using dynamic binaural synthesis for personalized auditory realities,”in proc.of aes international conference on audio for virtual and augmented reality,august 2018.
[0293]
[3]s.argentieri,p.dans,and p.soures,“a survey on sound source localization in robotics:from binaural to array processingmethods,”computer speech language,volume 34,no.1,pp.87
–
112,2015.
[0294]
[4]d.fitzgerald,a.liutkus,and r.badeau,“projection-based demixing of spatial audio,”ieee/acm trans.on audio,speech,and language processing,volume 24,no.9,pp.1560
–
1572,2016.
[0295]
[5]e.cano,d.fitzgerald,a.liutkus,m.d.plumbley,and f.“musical source separation:an introduction,”ieee signal processing magazine,volume 36,no.1,pp.31
–
40,january 2019.
[0296]
[6]s.gannot,e.vincent,s.markovich-golan,and a.ozerov,“a consolidated perspective on multimicrophone speech enhancement and source separation,”ieee/acm transactions on audio,speech,and language processing,volume 25,no.4,pp.692
–
730,april 2017.
[0297]
[7]e.cano,j.nowak,and s.grollmisch,“exploring sound source separation for acoustic condition monitoring in industrial scenarios,”in proc.of 25th european signal processing conference(eusipco),august 2017,pp.2264
–
2268.
[0298]
[8]t.gerkmann,m.krawczyk-becker,and j.le roux,“phase processing for single-channel speech enhancement:history and recent advances,”ieee signal processing magazine,volume 32,no.2,pp.55
–
66,march 2015.
[0299]
[9]e.vincent,t.virtanen,and s.gannot,audio source separation and speech enhancement.wiley,2018.
[0300]
[10]d.matz,e.cano,and j.abeβer,“new sonorities for early jazz recordings using sound source separation and automatic mixing tools,”in proc.of the 16th international society for music information retrieval conference.malaga,spain:ismir,october 2015,pp.749
–
755.
[0301]
[11]s.m.kuo and d.r.morgan,“active noise control:a tutorial review,”proceedings of the ieee,volume 87,no.6,pp.943
–
973,june 1999.
[0302]
[12]a.mcpherson,r.jack,and g.moro,“action-sound latency:are our tools fast enough?”in proceedings of the international conference on new interfaces for musical expression,july 2016.
[0303]
[13]c.rottondi,c.chafe,c.allocchio,and a.sarti,“an overview on networked music performance technologies,”ieee access,volume 4,pp.8823
–
8843,2016.
[0304]
[14]s.liebich,j.fabry,p.jax,and p.vary,“signal processing challenges for active noise cancellation headphones,”in speech communication;13th itg-symposium,october 2018,pp.1
–
5.
[0305]
[15]e.cano,j.liebetrau,d.fitzgerald,and k.brandenburg,“the dimensions of perceptual quality of sound source separation,”in proc.of ieee international conference on acoustics,speech and signal processing(icassp),april 2018,pp.601
–
605.
[0306]
[16]p.m.delgado and j.herre,“objective assessment of spatial audio quality using directional loudness maps,”in proc.of ieee international conference on acoustics,speech and signal processing(icassp),may 2019,pp.621
–
625.
[0307]
[17]c.h.taal,r.c.hendriks,r.heusdens,and j.jensen,“an algorithm for intelligibility prediction of time-frequency weighted noisy speech,”ieee transactions on audio,speech,and language processing,volume 19,no.7,pp.2125
–
2136,september 2011.
[0308]
[18]m.d.plumbley,c.kroos,j.p.bello,g.richard,d.p.ellis,and a.mesaros,proceedings of the detection and classification of acoustic scenes and events 2018 workshop(dcase2018).tampere university of technology.laboratory of signal processing,2018.
[0309]
[19]r.serizel,n.turpault,h.eghbal-zadeh,and a.parag shah,“large-scale weakly labeled semi-supervised sound event detection in domestic environments,”july 2018,submitted to dcase2018 workshop.
[0310]
[20]l.jiakai,“mean teacher convolution system for dcase 2018 task 4,”dcase2018 challenge,tech.rep.,september 2018.
[0311]
[21]g.parascandolo,h.huttunen,and t.virtanen,“recurrent neural networks for polyphonic sound event detection in real life recordings,”in proc.of ieee international conference on acoustics,speech and signal processing(icassp),march 2016,pp.6440
–
6444.
[0312]
[22]e.c,and t.virtanen,“end-to-end polyphonic sound event detection using convolutional recurrent neural networks with learned time-frequency representation input,”in proc.of international joint conference on neural networks(ijcnn),july 2018,pp.1
–
7.
[0313]
[23]y.xu,q.kong,w.wang,and m.d.plumbley,“large-scale weakly supervised audio classification using gated convolutional neural network,”in proceedings of the ieee international conference on acoustics,speech and signal processing(icassp),calgary,ab,canada,2018,pp.121
–
125.
on audio,speech,and language processing,volume 25,no.1,pp.208
–
221,january 2017.
[0326]
[36]v.lonstanlen and c.-e.cella,“deep convolutional networks on the pitch spiral for musical instrument recognition,”in proceedings of the 17th international society for music information retrieval conference.new york,usa:ismir,2016,pp.612
–
618.
[0327]
[37]s.gururani,c.summers,and a.lerch,“instrument activity detection in polyphonic music using deep neural networks,”in proceedings of the 19th international society for music information retrieval conference.paris,france:ismir,september 2018,pp.569
–
576.
[0328]
[38]j.schl
ü
tter and b.lehner,“zero mean convolutions for level-invariant singing voice detection,”in proceedings of the 19th international society for music information retrieval conference.paris,france:ismir,september 2018,pp.321
–
326.
[0329]
[39]s.delikaris-manias,d.pavlidi,a.mouchtaris,and v.pulkki,“doa estimation with histogram analysis of spatially constrained active intensity vectors,”in proc.of ieee international conference on acoustics,speech and signal processing(icassp),march 2017,pp.526
–
530.
[0330]
[40]s.chakrabarty and e.a.p.habets,“multi-speaker doa estimation using deep convolutional networks trained with noise signals,”ieee journal of selected topics in signal processing,volume 13,no.1,pp.8
–
21,march 2019.
[0331]
[41]x.li,l.girin,r.horaud,and s.gannot,“multiple-speaker localization based on direct-path features and likelihood maximization with spatial sparsity regularization,”ieee/acm transactions on audio,speech,and language processing,volume 25,no.10,pp.1997
–
2012,october 2017.
[0332]
[42]f.grondin and f.michaud,“lightweight and optimized sound source localization and tracking methods for open and closed microphone array configurations,”robotics and autonomous systems,volume 113,pp.63
–
80,2019.
[0333]
[43]d.yook,t.lee,and y.cho,“fast sound source localization using two-level search space clustering,”ieee transactions on cybernetics,volume 46,no.1,pp.20
–
26,january 2016.
[0334]
[44]d.pavlidi,a.griffin,m.puigt,and a.mouchtaris,“real-time multiple sound source localization and counting using a circular microphone array,”ieee transactions on audio,speech,and language processing,volume 21,no.10,pp.2193
–
2206,october 2013.
[0335]
[45]p.vecchiotti,n.ma,s.squartini,and g.j.brown,“end-to-end binaural sound localisation from the raw waveform,”in proc.of ieee international conference on acoustics,speech and signal processing(icassp),may 2019,pp.451
–
455.
[0336]
[46]y.luo,z.chen,and n.mesgarani,“speaker-independent speech separation with deep attractor network,”ieee/acm transactions on audio,speech,and language processing,volume 26,no.4,pp.787
–
796,april 2018.
[0337]
[47]z.wang,j.le roux,and j.r.hershey,“multi-channel deep clustering:discriminative spectral and spatial embeddings for speaker-independent speech separation,”in proc.of ieee international conference on acoustics,speech and signal processing(icassp),april 2018,pp.1
–
5.
[0338]
[48]g.naithani,t.barker,g.parascandolo,l.n.h.pontoppidan,and t.virtanen,“low latency sound source separation using convolutional recurrent neural networks,”in proc.of ieee workshop on applications of signal processing to audio and acoustics(waspaa),october 2017,pp.71
–
75.
[0339]
[49]m.sunohara,c.haruta,and n.ono,“low-latency real-time blind source separation for hearing aids based on time-domain implementation of online independent vector analysis with truncation of non-causal components,”in proc.of ieee international conference on acoustics,speech and signal processing(icassp),march 2017,pp.216
–
220.
[0340]
[50]y.luo and n.mesgarani,“tasnet:time-domain audio separation network for real-time,single-channel speech separation,”in proc.of ieee international conference on acoustics,speech and signal processing(icassp),april 2018,pp.696
–
700.
[0341]
[51]j.chua,g.wang,and w.b.kleijn,“convolutive blind source separation with low latency,”in proc.of ieee international workshop on acoustic signal enhancement(iwaenc),september 2016,pp.1
–
5.
[0342]
[52]z.rafii,a.liutkus,f.s.i.mimilakis,d.fitzgerald,and b.pardo,“an overview of lead and accompaniment separation in music,”ieee/acm transactions on audio,speech,and language processing,volume 26,no.8,pp.1307
–
1335,august 2018.
[0343]
[53]f.-r.a.liutkus,and n.ito,“the 2018 signal separation evaluation campaign,”in latent variable analysis and signal separation,y.deville,s.gannot,r.mason,m.d.plumbley,and d.ward,eds.cham:springer international publishing,2018,pp.293
–
305.
[0344]
[54]j.-l.durrieu,b.david,and g.richard,“a musically motivated midlevel representation for pitch estimation and musical audio source separation,”selected topics in signal processing,ieee journal of,volume 5,no.6,pp.1180
–
1191,october 2011.
[0345]
[55]s.uhlich,m.porcu,f.giron,m.enenkl,t.kemp,n.takahashi,and y.mitsufuji,“improving music source separation based on deep neural networks through data augmentation and network blending,”in proc.of ieee international conference on acoustics,speech and signal processing(icassp),2017.
international society for music information retrieval conference(ismir),paris,france,pp.306
–
312,2018.
[0368]
[78]c.-r.nagar,j.abeβer,s.grollmisch,"towards cnn-based acoustic modeling of seventh chords for recognition chord recognition,"in proceedings of the 16th sound&music computing conference(smc)(submitted),malaga,spain,2019.
[0369]
[79]j.s.g
ó
mez,j.abeβer,e.cano,"jazz solo instrument classification with convolutional neural networks,source separation,and transfer learning",in proceedings of the 19th international society for music information retrieval conference(ismir),paris,france,pp.577
–
584,2018.
[0370]
[80]j.r.hershey,z.chen,j.le roux,s.watanabe,"deep clustering:discriminative embeddings for segmentation and separation,"in proceedings of the ieee international conference on acoustics,speech and signal processing(icassp),pp.31-35,2016.
[0371]
[81]e.cano,g.schuller,c.dittmar,"pitch-informed solo and accompaniment separation towards its use in music education applications",eurasip journal on advances in signal processing,2014:23,pp.1-19.
[0372]
[82]s.i.mimilakis,k.drossos,j.f.santos,g.schuller,t.virtanen,y.bengio,"monaural singing voice separation with skip-filtering connections and recurrent inference of time-frequency mask,"in proceedings of the ieee international conference on acoustics,speech,and signal processing(icassp),calgary,canada,s.721-725,2018.
[0373]
[83]j.f.gemmeke,d.p.w.ellis,d.freedman,a.jansen,w.lawrence,r.c.moore,m.plakal,m.ritter,"audio set:an ontology and human-labeled dataset for audio events,"in proceedings of the ieee international conference on acoustics,speech and signal processing(icassp),new orleans,usa,2017.[84]kleiner,m.“acoustics and audio technology,”.3rd ed.usa:j.ross publishing,2012.
[0374]
[85]m.dickreiter,v.dittel,w.hoeg,m.m.,,handbuch der tonstudiotechnik,“a.medienakademie(eds).7th edition,vol.1.,munich:k.g.saur verlag,2008.
[0375]
[86]f.m
ü
ller,m.karau.,,transparant hearing,“in:chi,02 extended abstracts on human factors in computing systems(chi ea’02),minneapolis,usa,pp.730-731,april 2002.
[0376]
[87]l.vieira."super hearing:a study on virtual prototyping for hearables and hearing aids,"master thesis,aalborg university,2018.available:https://projekter.aau.dk/projekter/files/287515943/masterthesis_luis.pdf.
[0377]
[88]sennheiser,"ambeo smart headset,"[online].available:https://de-de.sennheiser.com/finalstop[accessed:march 1,2019].
[0378]
[89]orosound"tilde earphones"[online].available:https://
www.orosound.com/tilde-earphones/[accessed;march 1,2019].
[0379]
[90]brandenburg,k.,cano ceron,e.,klein,f.,t.,lukashevich,h.,neidhardt,a.,nowak,j.,sloma,u.,und werner,s.,,,personalized auditory reality,”in 44.jahrestagung f
ü
r akustik(daga),garching bei m
ü
nchen,deutsche gesellschaft f
ü
r akustik(dega),2018.
[0380]
[91]us 2015 195641 a1,申请日:2014年1月6日;公开于2015年7月9日。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
