1.本发明涉及人工智能语音识别领域,具体涉及一种基于深度学习的智慧校园语音识别方法。
背景技术:
2.随着计算机技术、声学技术的不发展,语音识别被运用到了各类场景中,使得人们的生活日益便利。各种智能终端设备,通过人机交互解放了人们的双手,使得对设备的操控用最初的按键,变成了语音、手势等方式。尤其有代表的智慧校园,运用了各类物联网设备,构建环境全面感知、智慧型、数据化、网络化、协作型一体化的教学、科研、管理和生活服务,并能对教育教学、教育管理进行洞察和预测的智慧学习环境。
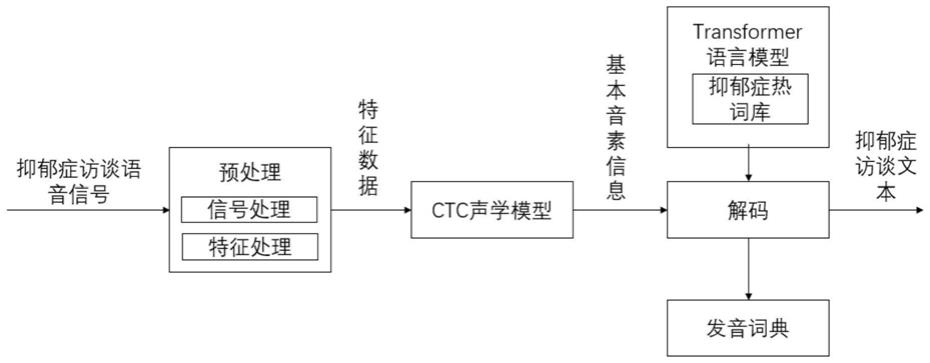
3.语音识别主要作用就是把一段语音信号转换成相对应的文本信息,系统主要由声学特征提取、语言模型、声学模型和解码器等组成。训练识别的过程是从原始波形语音数据中提取的声学特征经过训练得到声学模型,与发声词典、语言模型组成网络,对新来的语音提取特征,经过声学模型表示,通过维特比解码得出识别结果。
4.目前各类智慧校园设备中运用的到的语音识别,设计和研发均基于标准普通话,因用户个体发音习惯和方言口语,导致语音识别时准确率较低,存在错误识别、无法识别的情况,影响智慧校园设备运行,降低用户体验度。
技术实现要素:
5.针对现有技术的不足,本发明提供了一种基于深度学习的智慧校园语音识别方法,通过静音切除,降低对后续步骤造成的干扰,为了得到能够描述声音动态特性的参数,采用改进的梅尔频率倒谱系数,通过对梅尔频率倒谱系数进行二次提取,得到表示声音动态特性的参数,使用深层cnn代替原本的浅层cnn,减少语音信息的丢失。
6.为实现以上目的,本发明通过以下技术方案予以实现:
7.一种基于深度学习的智慧校园语音识别方法,该方法包括如下步骤:
8.s1.从语音库中,获取不同词汇语句运用不同人员口音读出的待识别的音频数据,具体包括:
9.s11.获取智慧校园中智能设备所使用到的控制词汇及语句的样本;
10.s12.获取控制词汇及语句的人声朗读语音;
11.s13.对样本数据库中的数据进行分类,按照训练的词汇建立单独的文件夹进行保存;
12.s2.对原始音频样本进行预处理,具体包括:
13.s21.将原始音频的首尾端的静音切除;
14.s22.对静音切除后的音频样本进行分帧;
15.s23.对帧音频进行加窗处理;
16.s24.对加窗后的音频各帧信号,采用快速傅里叶变换算法,得到音频各帧信号的
线性频谱x(k),再对线性频谱x(k)进行取模平方,得到声音信号的能量谱。
17.s3.对帧音频进行特征提取,采用梅尔频率倒谱系数特征提取,并对提取出来的参数进行优化,归一化处理;
18.s4.搭建cldnn语音识别模型并对模型进行优化
19.s41.搭建cldnn语音识别模型;
20.s42.对搭建好的cldnn语音模型进行优化,使用深层cnn代替原本的浅层cnn,深层cnn则减少了每层卷积核的数量以及卷积核的本身规模,并增加卷积层来提高cnn的参数,深层的cnn还增加了卷积次数;
21.s43.对优化后的模型进行训练和测试;
22.s5.采用解码器进行语音识别的解码,构成最终的控制语音识别模型;
23.s6.将音频特征样本输入到训练后的cldnn的语音识别模型中进行训练,得到控制语音识别模型。
24.进一步地,步骤s21中所述将原始音频的首尾端的静音切除的方法是,采用语言学软件praat无需标注自动切除音频首尾静音段,打开praat之后,设置音频的wav所在的目录,同样的方法设置保存目标wav所在的目录,设置需要对这个wav保存的时长,这里是对首尾,保留0.2秒,要求首尾时长必须大于0.1秒,如果不足0.1秒脚本则不会对音频进行切分,设置完成之后运行脚本,在保存目标wav的目录中,得到静音切除后的音频样本。
25.进一步地,步骤s22中所述对静音切除后的音频样本进行分帧,分为20ms一帧,帧移为10ms时长,得到帧音频数据。
26.进一步地,步骤s23中所述对帧音频进行加窗处理具体操作方法就是使用窗函数w(n)和s(n)相乘,得到加窗处理的音频信号sw(n)=s(n)*w(n);对音频信号进行加窗处理时,采用汉明窗函数:
[0027][0028]
式中,n为窗的序号,n为窗的个数,π是数学常数。
[0029]
进一步地,步骤s3具体包括如下步骤:
[0030]
s31.梅尔频率倒谱系数(mfcc)提取,在音频频谱范围内设置若干个hm(k)带通滤波器形成mel频率滤波器组,每个mel频率滤波器组输出对数能量计算,经过离散余弦变换变换得到mfcc语音特征参数;
[0031]
s32.对提取出来的参数进行加权、差分、筛选具体是在对音频信号进行mfcc参数的特征提取后,利用公式的差分特征参数提取方法,提取动态mel参数,得到每个帧音频数据对应的音频特征;
[0032]
s33.采用倒谱均值归一化的方式对音频进行归一化处理。
[0033]
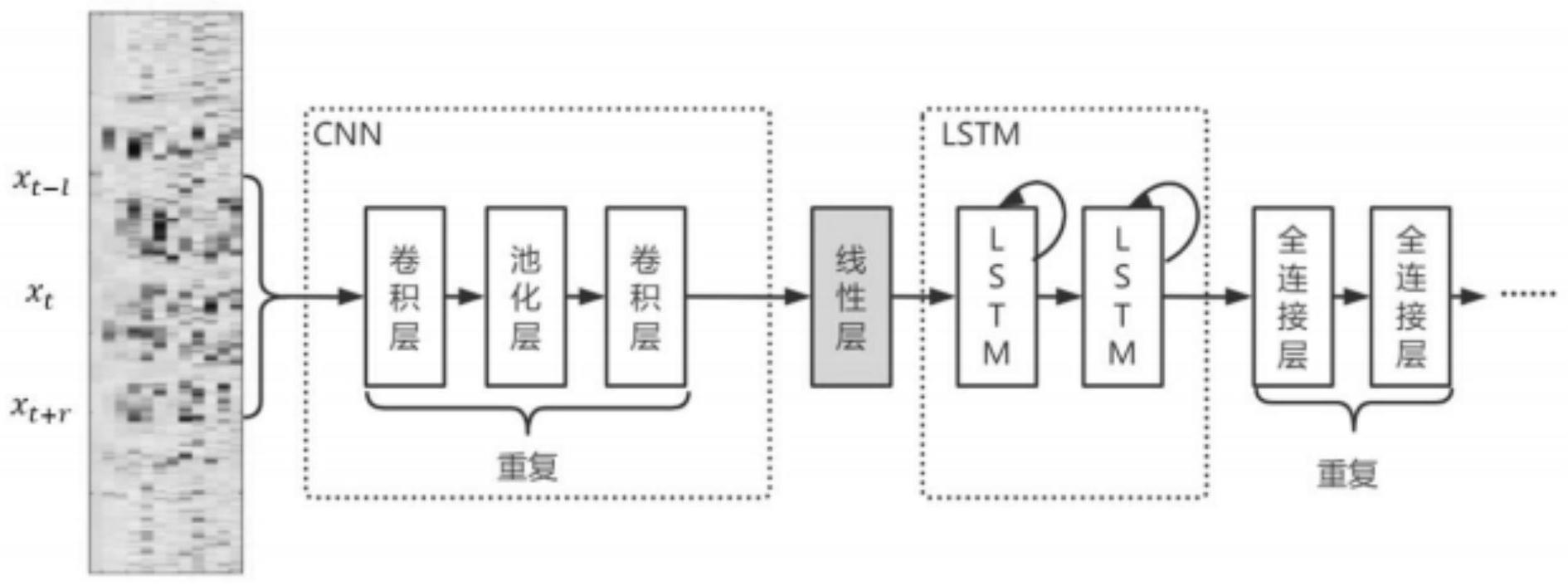
进一步地,步骤s41.搭建cldnn语音识别模型,具体是lstm结合原本的时序信息处理cnn输入的高级特征,最后dnn增加隐层和输出层之间的深度,并对cnn与lstm处理后的特征进行更深层次的处理,从而获得更强的预测能力,三者构成了cldnn的整体结构;由于lstm与两个前馈神经网络首尾相连,定长的前馈神经网络导致只能定长,即建立模型时需要指定输入x的长度;此外cldnn的两层lstm相互干涉,即第二lstm层接受的输入即为第一
lstm层的输出;cldnn中使用l或r决定整体模型的设计,l或r指的是若输入帧为x,则输入特征会同时包括x-l到x r的所有特征;将l或r设定为0,cldnn在输出后直接连接至softmax层,并以softmax层的输出为建模单元序列输出,输入到后续语言模型中。
[0034]
有益效果:
[0035]
1.本发明对原始音频样本进行静音切除,降低对后续步骤造成的干扰。
[0036]
2.普通的mel频率倒谱系数(mfcc)只能描述音频信号的静态特征,然而人的听觉系统对声音的动态特征的敏感度更高。为了得到能够描述声音动态特性的参数,采用改进的梅尔频率倒谱系数,通过对梅尔频率倒谱系数进行二次提取,得到表示声音动态特性的参数。
[0037]
3.本发明经过cldnn语音模型进行优化,使用深层cnn代替原本的浅层cnn
[0038]
更好的设计cnn层最终输出的规模、以及更加贴合中文语音识别任务的特性。
[0039]
第一,深层cnn可以通过设计各层的核大小以及核数量,更容易使首尾的矩阵元素数量相同。在本模型的改进方案中,由于同时输入策略,后续隐藏层需要同时接收到原始输入和cnn的输出,要求cnn层整体的输入与输出应保持规模相同。浅层cnn需要通过线性层,将结果矩阵进行叠加降维,深层cnn在图3(下)的输入和输出矩阵元素数量就正好相同,可以直接通过重新分配结果矩阵的位置(reshape)使两者规模完全相同,这也是cldnn中线性层的功能之一。
[0040]
第二,深层cnn在两次卷积后再池化,可以减少语音信息的丢失。信息量密集的语音识别任务中不宜采用一层卷积层和一层池化层交替连接的设计,这是因为卷积层带有平移不变性,提取出的高级特征仍然具有一定的连续性,且语音识别与图像识别不同,语音信息连续性较强,因此卷积后不宜立刻池化。cldnn使用这样的设计是因为cnn层数较浅不容易设计,且输入可以根据r产生重叠,大卷积核提取出的特征自身耦合性较强,减少了信息丢失的可能性;深层cnn则会使用较少的小型卷积核来提取特征,如此提取出的特征之间具有较大的关联性且特征信息更加密集,因此一般会在两次通过卷积核后才使用池化层进行提取。
附图说明
[0041]
图1为cldnn的整体结构;
[0042]
图2为cldnn的具体结构;
[0043]
图3为传统cldnn的浅层cnn与深层cnn的对比。
[0044]
图4为htk解码识别网络结构。
具体实施方式
[0045]
一种基于深度学习的智慧校园语音识别方法,该方法包括如下步骤:
[0046]
步骤s1,从语音库中,获取不同词汇语句运用不同人员口音读出的待识别的音频数据。
[0047]
(1)获取智慧校园中智能设备所使用到的控制词汇及语句的样本
[0048]
智慧校园中用到的设备包括课堂上和校园中各类设备,例如智能黑板、智能灯、智能音响、智能投影仪、智慧图书馆、智能门禁。这些设备的接入均可采用语音控制。控制这些
设备的运行预先设定好了命令词汇及语句库,通过语音识别装置对用户语音的识别,来达到控制设备运行的目的。在这些设备中,使用最多的词汇有:开机、关机、待机、连接网络、设置、返回等词语。获取智能设备所使用到的控制词汇及语句,将这些词汇进行保存,建立控制词汇及语句数据库。
[0049]
(2)获取控制词汇及语句的人声朗读语音
[0050]
获取控制词汇及语句的人声朗读语音的样本数据,不同的用户因为口音、语气的不同,同样的词汇朗读出来的效果都不同,大多数用户无法做到准确标准的朗读,因此就产生了差异。取1000个不同人员朗读的“开机、关机、待机、连接网络、设置、返回”等词语的音频,将音频保存在样本数据库中。
[0051]
对样本数据库中的数据进行分类
[0052]
对保存在样本数据库的音频进行分类,按照训练的词汇建立单独的文件夹进行保存。
[0053]
步骤s2,对原始音频样本进行预处理
[0054]
将原始音频的首尾端的静音切除
[0055]
这个静音切除的操作一般称为vad。采用语言学软件praat无需标注自动切除音频首尾静音段。打开praat之后,设置音频的wav所在的目录,同样的方法设置保存目标wav所在的目录,设置需要对这个wav保存的时长,这里是对首尾,保留0.2秒,要求首尾时长必须大于0.1秒,如果不足0.1秒脚本则不会对音频进行切分,设置完成之后运行脚本,在保存目标wav的目录中,得到静音切除后的音频样本。开始语音识别之前,有时需要把首尾端的静音切除,降低对后续步骤造成的干扰。
[0056]
对静音切除后的音频样本进行分帧
[0057]
要对声音进行分析,需要对声音分帧,也就是把声音切开成一小段一小段,每小段称为一帧。语音信号从整体来看其特性及表征其本质特征的参数均是随时间而变化的,所以它是一个非平稳态过程,不能用处理平稳信号的数字信号处理技术对其进行分析处理。但是,由于不同的语音是由人的口腔肌肉运动构成声道某种形状而产生的响应,而这种口腔肌肉运动相对于语音频率来说是非常缓慢的,所以从另一方面看,虽然语音信号具有时变特性,但在一个短时间范围内(认为在10-30ms的短时间内),其特性基本保持不变即相对稳定,因而可以将其看作是一个准稳态过程,即语音信号具有短时平稳性。所以任何语音信号的分析和处理必须建立在“短时”的基础上,即进行“短时分析”,将语音信号分为一段一段来分析其特征参数,其中每一段称为一“帧”,帧长一般即取为10-30ms。分析出的是由每一帧特征参数组成的特征参数时间序列。
[0058]
将音频样本进行分帧,分为20ms一帧,帧移为10ms时长,得到帧音频数据。
[0059]
帧移就是每次处理完一帧后向后移动的步长,一般设置与帧长有50%( /-10%)的重叠,设置帧移的情况,可以提取到更为细致而丰富的语音信息,因为其处理的粒度小很多,也可以更好地捕获到相邻两帧的边缘信息。(举个例子,未设置帧移,对20ms附近的语音信号特征,只在第二帧[20,40)中进行了提取;在设置帧移后,[0,20),[9,29),[19,39)这三帧都对其进行了特征提取,所以更为平滑准确。
[0060]
(3)对帧音频进行加窗处理
[0061]
加窗也就是对每一帧都使用一个窗函数来处理,消除了一帧两端的样本,从而能
够生成一段周期性的信号。对有限长度的滑动窗口进行加权处理可以实现。
[0062]
对音频信号的加窗处理,具体操作方法就是使用一定的窗函数w(n)和s(n)相乘,得到加窗处理的音频信号sw(n)=s(n)*w(n)。为了能够提取音频信号的参数,在预处理中加入了加窗的概念,加窗处理的目的是为了使信号的特征变化更突出。对音频信号进行加窗处理时,采用汉明窗函数:
[0063][0064]
式中,n为窗的序号,n为窗的个数,π是数学常数
[0065]
汉明窗的旁瓣峰值较低,能很好地克服信号泄漏的问题,它的低通特性也更平滑。
[0066]
对加窗后的音频各帧信号,采用快速傅里叶变换算法,得到音频各帧信号的频谱,再对频谱进行取模平方,得到声音信号的能量谱。
[0067]
由于信号在时域上的变换通常很难看出信号的特性,所以通常将它转换为频域上的能量分布来观察,不同的能量分布,就能代表不同语音的特性。所以在乘上汉明窗后,每帧还必须再经过快速傅里叶变换以得到在频谱上的能量分布。对分帧加窗后的各帧信号进行快速傅里叶变换得到各帧的线性频谱x(k)。
[0068]
步骤s3,对帧音频进行特征提取,采用梅尔频率倒谱系数(mfcc)特征提取,并对提取出来的参数进行优化,归一化处理。
[0069]
梅尔频率倒谱系数(mfcc)提取
[0070]
对线性频谱幅度x(k)进行平方运算,所得结果为能量谱。在频域内,为了对能量谱进行带通滤波,设置了一组mel尺度(人类对语音信号频率内容的感知遵循一种主观上定义的非线性尺度,该非线性标度可被称为“mel”标度)的三角形滤波器组。而mel频率滤波器组是指在音频频谱范围内所设置的若干个hm(k)带通滤波器.
[0071]
每个滤波器组所输出的对数能量计算.
[0072]
经过离散余弦变换(dct)变换可以得到mfcc语音特征参数。.
[0073]
(2)对提取出来的参数进行加权、差分、筛选
[0074]
对mfcc参数进行差分是为了获得音频信号特征向量的连续变化的动态轨迹,是以一段音频的特征向量序列为研究对象。对特征向量进行一阶差分处理,从而获得其变化速度,主要体现了声音韵律的变化,大多数情况下,韵律的变化是一个渐进的过程,表现在声音的高低起落方面。
[0075]
在对音频信号进行mfcc参数的特征提取后,利用公式的差分特征参数提取方法,提取动态mel参数,得到每个帧音频数据对应的音频特征.
[0076]
(3)对音频特征归一化处理
[0077]
采用倒谱均值归一化的方式对音频进行归一化处理。为了平衡频谱并改善信噪比(snr),我们可以简单地从所有帧中减去每个系数的平均值。由于倒频谱是对数频谱的线性变换,因此mfcc(将滤波器能量乘以固定矩阵即可),这称为倒谱均值归一化。处理好的数据保存到音频特征数据集中。
[0078]
步骤s4,搭建cldnn语音识别模型并对模型进行优化
[0079]
(1)搭建cldnn语音识别模型
[0080]
使用cnn来减小频域上的变化,并提取出自适应性更强的特征输入到lstm之中,lstm结合原本的时序信息处理cnn输入的高级特征,最后dnn增加隐层和输出层之间的深度,并对cnn与lstm处理后的特征进行更深层次的处理,从而获得更强的预测能力,三者构成了cldnn的整体结构。
[0081]
由于lstm与两个前馈神经网络首尾相连,定长的前馈神经网络导致只能定长,即建立模型时需要指定输入x的长度;此外cldnn的两层lstm相互干涉,即第二lstm层接受的输入即为第一lstm层的输出。cldnn中使用l或r决定整体模型的设计,l或r指的是若输入帧为x,则输入特征会同时包括x-l到x r的所有特征。将l或r设定为0,可以防止lstm获得下文(或上文)信息,避免两层相互干涉的单向lstm产生上下文混淆,cldnn的具体结构示意图:
[0082]
cnn层采用的是浅层cnn,大参数量只能通过增加卷积核数量实现,卷积核数量决定了cnn层输出的尺寸维度,上图中cnn层输出的总尺寸较大,因此引入了线性层,将卷积神经网络的最终输出进行叠加以减少输出尺寸。
[0083]
cldnn在输出后直接连接至softmax层,并以softmax层的输出为建模单元序列输出,输入到后续语言模型(如gmm)中。
[0084]
对搭建好的cldnn语音模型进行优化,使用深层cnn代替原本的浅层cnn。
[0085]
cldnn使用两层具有大量卷积核的卷积层和一层池化层提取特征,浅层的cnn与数量较多的卷积核能在保证参数量较高的情况下降低模型复杂度,可以提取出较低维的粗糙特征。深层网络会使得各层输入产生特征的复合,网络越深,从输入提取出的语义特征就越高级。
[0086]
图3表示了传统cldnn的浅层cnn与深层cnn的对比,其中激活函数均为relu。图3(上)表示了原本cldnn中浅层cnn的设计,cldnn使用了数量较多且本身较大的卷积核,cnn在有限的层数中容纳了更多的参数,这样做虽然能训练更多的参数,但减少了特征的提取次数,提取特征能力仍不足,卷积层提取的特征只停留在浅层特征之上。深层cnn则减少了每层卷积核的数量以及卷积核的本身规模,并增加卷积层来提高cnn的参数,保证参数足够拟合样本数据。深层的cnn还增加了卷积次数,使cnn提取出的特征为更高级、更精炼的结果,深层模型可能带来的过拟合可以使用dropout处理。图中并未表明省略处的卷积核数量,由于多次卷积后的特征十分复杂,顶层卷积层需要使用更多的参数来拟合高级特征,因此图3(下)的省略处卷积核的数量从32一直提高到了128(即cnn最后的矩阵维数)。
[0087]
采用深层至少还有两个好处:更好的设计cnn层最终输出的规模、以及更加贴合中文语音识别任务的特性。
[0088]
深层cnn可以通过设计各层的核大小以及核数量,更容易使首尾的矩阵元素数量相同。在本模型的改进方案中,由于同时输入策略,后续隐藏层需要同时接收到原始输入和cnn的输出,要求cnn层整体的输入与输出应保持规模相同。浅层cnn需要通过线性层,将结果矩阵进行叠加降维,深层cnn在图3(下)的输入和输出矩阵元素数量就正好相同,可以直接通过重新分配结果矩阵的位置(reshape)使两者规模完全相同,这也是cldnn中线性层的功能之一。
[0089]
深层cnn在两次卷积后再池化,可以减少语音信息的丢失。信息量密集的语音识别任务中不宜采用一层卷积层和一层池化层交替连接的设计,这是因为卷积层带有平移不变性,提取出的高级特征仍然具有一定的连续性,且语音识别与图像识别不同,语音信息连续
性较强,因此卷积后不宜立刻池化。cldnn使用这样的设计是因为cnn层数较浅不容易设计,且输入可以根据r产生重叠,大卷积核提取出的特征自身耦合性较强,减少了信息丢失的可能性;深层cnn则会使用较少的小型卷积核来提取特征,如此提取出的特征之间具有较大的关联性且特征信息更加密集,因此一般会在两次通过卷积核后才使用池化层进行提取。
[0090]
对优化后的模型进行训练
[0091]
优化完cldnn语音模型的网络结构后,在magicdata mandarin chinese read speech corpus中文语音数据集上进行了训练和测试。magic data技术有限公司的语料库,语料库包含755小时的语音数据,其主要是移动终端的录音数据。句子转录准确率高于98%。录音在安静的室内环境中进行。数据库分为训练集,验证集和测试集,比例为51:1:2。诸如语音数据编码和说话者信息的细节信息被保存在元数据文件中。录音文本领域多样化,包括互动问答,音乐搜索,sns信息,家庭指挥和控制等。还提供了分段的成绩单。该语料库旨在支持语音识别,机器翻译,说话人识别和其他语音相关领域的研究人员。
[0092]
步骤s5,采用解码器进行语音识别的解码,构成最终的控制语音识别模型。
[0093]
在完成上面的数据准备、特征提取和模型训练之后,便可以采用解码器进行语音识别的最后一步解码工作。在htk中,解码的网络结构为见图4。其中,hparse:将语法树文件转化为slf;hbuild是将二元语言模型(bigramlanguage model)转化为slf,或者将word网络分解成子网络;hdict用于网络加载词典文hne用于将词典、hmm set和word网络转化为hmm的网络,hrec用来加载hmm网络来识别语音输入。解码的工作主要是由函数库hvite完成。
[0094]
hvite函数的格式如下:hvite-h hmm15/macros-h hmm15/hmmdefs-s test.scp-l'*'-i recout.mlf-wwdnet-p 0.0-s 5.0dict tiedlist
[0095]
选项-p和-s分别用来设计单词插入惩罚和语言模型缩放因子。
[0096]
步骤s6,将音频特征样本输入到训练后的cldnn的语音识别模型中进行训练,得到控制语音识别模型。
[0097]
将音频特征数据库中的音频特征样本,按照比例分为7:3,划分成训练集和测试集。
[0098]
将音频特征样本训练集和测试集输入控制语音模型中进行训练,得到训练后的控制语音模型。此时控制语音识别模型经过不同人员口语读出的控制词汇的训练,不断矫正优化模型,使得模型识别不标准发音的识别率大幅提升。
[0099]
获取一段与之前所用样本完全无关的音频特征样本,输入到训练后的控制语音模型中进行测试,输出识别结果。
[0100]
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。