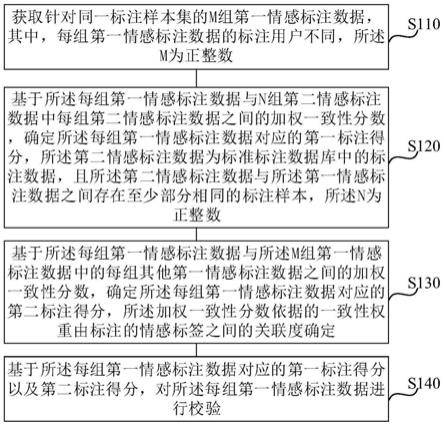
基于gpu端模糊c均值聚类算法的雷达信号分选方法
技术领域
1.本发明属于雷达通信技术领域,更进一步涉及电子侦察技术领域中的一种基于图像处理单元gpu(graphics processing unit)端模糊c均值聚类算法的雷达信号分选方法。本发明可用于侦察机分离不同雷达发射的雷达脉冲。
背景技术:
2.雷达脉冲分选是整个雷达侦察系统的重要组成部分。只有在复杂的电磁环境中正确地对各种类型的脉冲进行分选,才能对雷达辐射源进行后续的特征提取、识别和威胁评估。传统分选方法依赖于脉冲到达时间参数,但是这种方法仅适合于常规雷达信号的分选,对于复杂电磁环境下密集雷达信号的分选效果不佳,另外其运算量较大,导致运算效率较低。因此,当前研究方向趋向于通过对多维的雷达脉冲描述字pdw(pulse description word)进行分析,并使用聚类算法对雷达脉冲描述字进行聚类,以便快速、准确地分选雷达信号。
3.中国人民解放军空军研究院战略预警研究所在其申请的专利文献“一种电磁信号分选方法”(申请号:202110229049.4;申请公布号:cn 113051070 a)中提出了一种雷达信号分选方法。该方法的步骤包括进行基于嵌入式gpu的软硬件架构设计;搭建雷达脉冲流并行化数据处理的计算框架;实现k-means聚类算法在嵌入式gpu上运行;设计完成并行化数据算法从数学模型到软件代码的移植流程。该方法对接收的雷达脉冲流信号执行adc采样,根据数字化的雷达信号脉冲流的数据量及硬件资源的状况,运用上述的算法移植流程,对相应的参数测量算法进行算法建模和真实软硬件环境下的集成调试,解决了雷达脉冲流进行分选过程中核心步骤计算效率不高,硬件资源利用不足的问题。但是,该方法仍然存在的不足之处是,由于k-means聚类算法具有无法准确聚类非凸数据集的缺陷,所以该方法对于复杂雷达信号中非凸数据的分选准确率较低。
4.中南大学在其申请的专利文献“基于改进布谷鸟算法的雷达信号分选方法及装置”(申请号:202110256310.x;申请公布号:cn 113033629 a)中公开了一种基于改进布谷鸟算法的雷达信号分选方法。该方法的实现步骤为:获取数据对象集合,该数据对象集合由n个雷达信号的脉冲描述字组成,且每一个脉冲描述字由n维度的特征参数组成;对数据对象集合进行归一化处理,获得中间集合;对中间集合进行移除孤点处理,获得目标对象集合;通过改进布谷鸟算法和k均值聚类算法对目标对象集合进行聚类处理,并输出聚类结果。该方法将改进布谷鸟算法引入到k-means聚类分选算法中,利用改进布谷鸟算法高效地局部和全局搜索能力,解决传统的k-means聚类分选算法存在全局搜索能力不足,且容易陷入局部最优的问题,进而提高雷达信号分选稳定性。但是,该方法仍然存在的不足之处是,该方法在k-means聚类分选算法基础上增加了改进布谷鸟算法,这使得其运算量大大增加,同时该方法使用的是运算效率较低的串行运算方式,导致该方法的分选效率较低。
技术实现要素:
5.本发明的目的在于针对上述现有技术中存在的不足,提供一种基于gpu端模糊c均值聚类的雷达信号分选方法,用于解决由于k-means聚类算法具有无法准确聚类非凸数据集缺陷,导致的复杂雷达信号中非凸数据的分选准确率较低的问题,以及串行聚类处理运算带来的分选效率较低的问题。
6.实现本发明目的的技术思路是,本发明采用模糊c均值聚类算法进行雷达信号的分选,采用模糊聚类的思想计算每个pdw的隶属度,按照每个pdw的隶属度进行聚类划分,保证其更为准确地进行雷达信号的分选。本发明采用gpu设备以及并行化运算软件cuda,将模糊c均值聚类算法中运算量较大的步骤放在gpu端执行,在gpu端利用多线程并行化计算pdw的隶属度与聚类中心值,解决了串行聚类方法运算效率不理想的问题。
7.为实现上述目的,本发明采用如下技术方案:
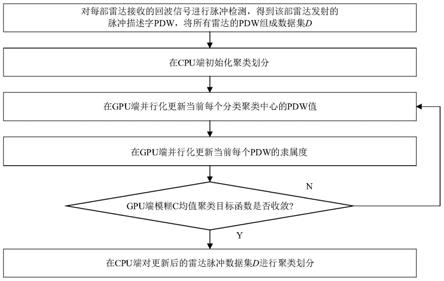
8.步骤1,对每部雷达接收的回波信号进行脉冲检测,得到该部雷达发射的脉冲描述字pdw,将所有雷达的pdw组成数据集d;
9.步骤2,在cpu端初始化聚类划分:
10.将数据集d平均分为k类,保证每一个类中的pdw数量相等,在每一个类中随机选取一个pdw作为该类的聚类中心,每一个类中只包含一个聚类中心,k的值为雷达部数;
11.步骤3,在gpu端并行化更新当前每个分类聚类中心的pdw值:
12.利用gpu端内存空间开辟好的线程,让每一个线程更新一次每个聚类中心的pdw值,多线程同时并行处理,得到数据集d中所有更新后的每个分类聚类中心的pdw值;
13.步骤4,在gpu端并行化更新当前每个pdw的隶属度:
14.利用开辟好的线程,更新每个线程对数据集d中当前迭代更新前的每个分类的聚类中心的隶属度,多线程同时并行处理,得到数据集d中所有当前迭代更新后的每个pdw在所有分类中更新后的隶属度;
15.步骤5,判断gpu端模糊c均值聚类目标函数是否收敛;若是,则将当前并行化更新后的所有聚类中心pdw值、隶属度矩阵u拷贝到cpu端后执行步骤6,否则,执行步骤3;
16.步骤6,在cpu端对更新后的雷达脉冲数据集d进行聚类划分:
17.在cpu端取出更新完成后隶属度矩阵中每一列的最大值,将该最大值所在行的序号作为该pdw的所属类别标签,将类别标签相同的pdw放在同一个数组中。
18.本发明与现有技术相比具有以下优点:
19.1)由于本发明将gpu并行计算与模糊c均值雷达信号聚类分选算法结合起来,使得算法中几个运算量较大的步骤在gpu中并行执行,从而大大缩短了算法的执行时长,相比现有技术的串行聚类算法更加高效,更好地满足了雷达信号分选的实时性需求。
20.2)由于模糊c均值聚类可以根据雷达pdw的空间特征判断这些数据属于哪个类的可能性更大,克服了现有技术k-means算法分选非凸数据时准确率低的问题,从而使雷达信号分选的准确率更高。
21.3)由于本发明采用纯软件化的处理流程,使得本发明方法不存在对硬件的依赖,具备更好的可移植性,另外其开发周期较短,更易于工程实现。
附图说明
22.图1是本发明的流程图;
23.图2是本发明的仿真图。
具体实施方式
24.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
25.以下将结合附图及实施例对本发明做进一步详细说明。
26.参照图1和本发明实施例对本发明的实现步骤作进一步的描述。
27.步骤1,对每部雷达接收的回波信号进行脉冲检测,得到该部雷达发射的脉冲描述字pdw,将所有雷达的pdw组成数据集d。
28.每一个脉冲雷达脉冲描述字pdw包括3个特征参数,分别是脉冲载频、脉冲宽度和脉冲幅度。
29.本发明实施例的数据集d由四部雷达的pdw构成,第一部雷达的脉冲参数为:载频在[3620,3636]mhz范围内捷变变化,脉宽在[3.75,4]μs范围内滑动变化,脉冲幅度在[2100,2490]μs范围内随机变化。第二部雷达的脉冲参数为:载频在[3725,3765]mhz范围内捷变变化,脉宽在[2.1,3]μs范围内滑动变化,脉冲幅度在[1400,1710]μs范围内随机变化。第三部雷达的脉冲参数为:载频在[3570,3580]mhz范围内捷变变化,脉宽在[1.5,2]μs范围内滑动变化,脉冲幅度在[740,1155]μs范围内随机变化。第四部雷达的脉冲参数为:载频在[3650,3670]mhz范围内捷变变化,脉宽在[4.1,5]μs范围内滑动变化,脉冲幅度在[2800,3142]μs范围内随机变化。
[0030]
本发明实施例中每部雷达均发射了1024个脉冲,则每部雷达发射的脉冲描述字pdw为1024个,四部雷达的脉冲描述字pdw共4096个,即本发明实施例的数据集d由4096个脉冲描述字pdw组成。
[0031]
步骤2,在cpu端初始化聚类划分。
[0032]
将数据集d平均分为k类,保证每一个类中的pdw数量相等,在每一个类中随机选取一个pdw作为该类的聚类中心,每一个类中只包含一个聚类中心。k的值为雷达部数。将每一个pdw隶属于该类的可能性用隶属度表述,隶属度的值越大反映pdw数据属于该类的可能性越大。用相关参数隶属度因子m反映聚类的不确定性程度,m越大聚类的不确定性越高。
[0033]
本发明实施例中,k=4,脉冲数n=4096,初始化后的隶属度矩阵u为一个4*4096的矩阵,定义的聚类中心矩阵为一个4*3的矩阵。
[0034]
步骤3,在gpu端并行化更新当前每个分类聚类中心的pdw值。
[0035]
本发明的实施例使用cuda编程体系中的cudamalloc()函数,开辟存放更新数据集d过程中各参数的gpu端内存空间,使用cudamemcpy()函数和cudamemcpyhosttodevice参数将pdw数据集、所有聚类中心数据拷贝到gpu开辟的内存空间中。
[0036]
利用gpu端内存空间开辟好的线程,让每一个线程按照下式进行一次更新每个聚类中心的pdw值,多线程同时并行处理,得到数据集d中所有更新后的每个分类聚类中心的
pdw值:
[0037][0038]
其中,ci表示数据集d中当前迭代更新后的第i个分类聚类中心的pdw值,i的取值范围为[1,k],n表示数据集d中pdw的总数,u
ij
表示数据集d中第j个pdw当前迭代更新前的第i个分类的聚类中心的隶属度,m表示设定好的隶属度因子,通常取2。x
p
表示数据集d中第p个pdw值,p表示数据集d中pdw的编号,p的取值与j的取值对应相等。
[0039]
在本发明实施例中本步骤包括以下3个子步骤:
[0040]
第一步,利用开辟好网格与线程块中的每个线程,对数据集d中每个pdw当前迭代更新前的每个分类的聚类中心的隶属度求m次幂,得到数据集d中当前迭代更新前该聚类中心的pdw隶属于其分类的隶属度u
ijm
。
[0041]
第二步,在gpu端利用归约求和算法求取
[0042]
归约求和算法就是将原有的串行求和运算变为两两一组的并行求和操作。每进行一组并行求和操作后数据集d中当前迭代更新前所有聚类中心隶属度的个数减少一半,对于数据集d中所有聚类中心隶属度需要n-1次的并行求和操作,进行log2n步,从而可以将求和算法的复杂度从原来串行执行的o(n)降低为o(logn)。
[0043]
第三步,在gpu端利用开辟好的网格与线程块,对u
ijm
与原始数据集d中的每个pdw进行相乘操作,每个线程负责一次相乘操作,即求得公式中部分,再用多线程完成k次除法操作,最终完成每个分类聚类中心的pdw值。
[0044]
本发明实施例中,对4096个pdw按照聚类中心更新公式,在gpu端采用多线程并行化运算,网格维度设置为grid(1,(n*n 16*16-1)/(16*16)),线程块维度设置为block(16,16),隶属度因子m设为2。利用开辟好的线程,在gpu端核函数中,让每一个线程按照聚类中心更新公式负责一次聚类中心更新的运算,多线程同时并行化计算求得所有聚类中心。
[0045]
步骤4,在gpu端并行化更新当前每个pdw的隶属度。
[0046]
利用开辟好的线程,按照下式,每个线程对数据集d中当前迭代更新前的每个分类的聚类中心的隶属度进行一次更新,多线程同时并行处理,得到数据集d中所有当前迭代更新后的每个pdw在所有分类中更新后的隶属度:
[0047][0048]
其中,u
ij
'表示数据集d中第j个pdw在当前迭代更新后的第i个分类中的隶属度,d
ip
表示第i个聚类中心ci与数据集d中第p个pdw的距离,d
hp
表示第h个聚类中心ch与第p个pdw的距离,p表示数据集d中pdw的编号,p的取值与j的取值对应相等。
[0049]
本发明实施例中,按照隶属度的计算公式,在gpu端采用多线程并行化更新隶属
度,网格维度设置为grid(n/16,n/16),块维度设置为block(16,16)。
[0050]
具体的,本发明实施例包括以下3个子步骤::
[0051]
第一步,在gpu端利用开辟好的网格与线程块,用多线程并行求得各聚类中心与每个pdw的距离d
ij
,每一个线程计算一个d
ij
。
[0052]
第二步,利用划分好的网格和线程块以及求得的d
ij
对k个d
hj
分别做除法,并对结果进行求幂操作,并将结果保存在gpu端的共享内存中。
[0053]
第三步,将对共享内存中的结果进行多线程归约求和操作,对求和结果再求倒数即可得到最终结果。
[0054]
步骤5,判断gpu端模糊c均值聚类目标函数是否收敛;若是,则将当前并行化更新后的所有聚类中心pdw值、隶属度矩阵u拷贝到cpu端后执行步骤6,否则,执行步骤3;
[0055]
所述目标函数是用于体现聚类效果是否有效,按照下式,计算当前循环中目标函数值:
[0056][0057]
其中,j表示当前的目标函数值,d
ij
表示第i个聚类中心ci与数据集d中第j个pdw的距离,ck表示第k个分类的聚类中心pdw值。
[0058]
若在多次迭代更新过程中,目标函数值连续5次未发生变化时则该目标函数视为收敛,之后将前面计算得到的聚类中心pdw值、隶属度矩阵u拷贝到cpu端,拷贝的方法是使用cuda编程体系中的cudamemcpy()函数和cudamemcpydevicetohost参数将gpu端的参数拷贝回cpu端。
[0059]
本发明实施例中,迭代次数小于15次时,算法未收敛,每次均返回步骤3;当迭代次数达到15次时,算法开始收敛,此时目标函数值为4.64
×
107;当迭代次数达到19次时,目标函数值依旧未发生改变,说明目标函数已收敛,此时将所有聚类中心pdw值、隶属度矩阵u拷贝到cpu端。
[0060]
步骤6,在cpu端对更新后的雷达脉冲数据集d进行聚类划分。
[0061]
在cpu端取出更新完成后隶属度矩阵中每一列的最大值,将该最大值所在行的序号作为该pdw的所属类别标签。将类别标签相同的pdw放在同一个数组中,从而完成了pdw数据集d的聚类划分。
[0062]
本发明实施例中,由于数据集d可分为4类,所以将4类标签分别设置为1、2、3、4来表示每个pdw的类别,将标签相同的pdw放在一个数组,从而完成了聚类划分。
[0063]
下面结合仿真实验对本发明的技术效果做进一步说明。
[0064]
1.仿真实验条件:
[0065]
本发明的仿真实验的硬件平台为:cpu型号是intel(r)core i5-9300h,主频2.40ghz,gpu型号是nvidia geforce gtx 1650,内存8gb。
[0066]
本发明的仿真实验的软件平台为:windows 10操作系统、cuda toolkit 10.1、matlab r2018b、microsoft visual studio 2012。
[0067]
本发明仿真实验利用matlab软件生成包含有五组数据的数据集,每一组数据包括四部雷达脉冲数据。第一组数据中的四部雷达均发射128个脉冲,第二组数据中的四部雷达均发射256个脉冲,第三组数据中的四部雷达均发射512个脉冲,第四组数据中的四部雷达
均发射1024个脉冲,第五组数据中的四部雷达均发射2048个脉冲。
[0068]
本发明仿真实验中所有原始雷达脉冲描述字分布图参见图2(a)。
[0069]
第一部雷达的脉冲参数为:载频在[3620,3636]mhz范围内捷变变化,脉宽在[3.75,4]μs范围内滑动变化,脉冲幅度在[2100,2490]μs范围内随机变化。第二部雷达的脉冲参数为:载频在[3725,3765]mhz范围内捷变变化,脉宽在[2.1,3]μs范围内滑动变化,脉冲幅度在[1400,1710]μs范围内随机变化。第三部雷达的脉冲参数为:载频在[3570,3580]mhz范围内捷变变化,脉宽在[1.5,2]μs范围内滑动变化,脉冲幅度在[740,1155]μs范围内随机变化。第四部雷达的脉冲参数为:载频在[3650,3670]mhz范围内捷变变化,脉宽在[4.1,5]μs范围内滑动变化,脉冲幅度在[2800,3142]μs范围内随机变化。
[0070]
2.仿真内容与结果分析:
[0071]
本发明仿真实验是采用本发明的方法和现有技术cpu串行算法,分别对五组雷达脉冲数据进行分选耗时测试,其结果如图2(b)本发明仿真实验中并行化算法与cpu串行算法运行时间的对比图所示。图2(b)的横坐标代表雷达样本集序号,纵坐标代表耗时时间,其单位为ms。图2(b)中以正方形点标示的曲线表示利用现有技术cpu串行算法分选五组数据的耗时曲线,以圆点形标示的曲线表示利用本发明的方法分选五组数据的耗时曲线。
[0072]
现有技术cpu串行算法是指,bezdek j c在“pattern recognition with fuzzy objective function algorithms[m].plenum press,1981”中提出的串行模糊c均值聚类算法。
[0073]
由图2(b)可以看出,现有技术cpu串行算法在对五组雷达样本进行聚类分选时随着样本点数的增加运行时间也增加得较为明显,而本发明的gpu方法一直维持在一个低耗时的水平上。
[0074]
图2(c)为本发明的gpu并行化测试与cpu串行化测试的加速比示意图,图2(c)的横坐标代表雷达样本集序号,纵坐标代表加速比。五条柱状图表示利用本发明的方法分选五组数据的耗时相比现有技术的耗时加速比。
[0075]
由图2(c)可以看出,本发明方法的加速比随着数据量的增加而增加,尤其是前三组雷达样本的加速比增长较为明显,当数据量继续增加后,加速比变化逐渐趋于稳定,对第五组雷达样本的gpu分选相比现有技术达到了近50倍的加速比。
[0076]
综上所述,本发明方法可以大大缩短聚类算法的执行时长,相比传统的串行聚类算法更加高效,更好地满足了雷达信号分选的实时性需求。
[0077]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。