基于半监督深度学习的新冠肺炎ct图像分析方法
技术领域
1.本发明涉及一种新冠肺炎ct图像分析方法,特别涉及一种基于半监督深度学习的新冠肺炎ct图像分析方法。
背景技术:
2.预防和对抗新冠肺炎的最关键的一个步骤就是对疑似感染的病人进行有效的筛查。在疫情的早期阶段,通常使用逆转录聚合酶链反应(rt-pcr)来判断患者是否患上新冠肺炎。然而由于疫情的迅速爆发,许多国家缺乏足够的试剂盒对疑似患者进行检测。而且rt-pcr检测需要数天才能得出结果,过长的检测时间会导致疫情控制和治疗的延误。此外rt-pcr检测灵敏性较低,一次检测可能无法做出准确判断,因此需要多次测试才能做出最终的判断。在临床实践中,研究人员发现covid-19患者的胸部计算机断层扫描(ct)图像中都出现了诸如毛玻璃阴影,多灶斑片状实变等影像学特征。而且与rt-pcr检测相比,医生可以更快地得到胸部ct扫描和相应的诊断结果。而且ct 扫描的设备在现代医疗保健系统十分普及,因此ct已经成为了早期筛查和诊断新冠肺炎的另一个有效办法。
3.近年来,随着深度学习在计算机视觉方面取得了突破性的进展,在图像分类,图像定位与检测,以及医疗图像分割等领域得到了大量的应用,极大减缓了海量的医疗图像数据给医生带来的负担。目前常用的医疗图像诊断方法大多是基于监督学习的,需要大量的有标记数据。但在很多实际工作中,可能只有很少的有标记样本可供使用,因为对数据进行标记的代价很高。新冠肺炎的ct采集和标记需要专业医生大量的时间和精力,这在疫情期间更加严重。训练深度学习模型需要大量的有标记数据来达到临床标准的表现。数据量不足会导致模型的过拟合,导致模型的性能不佳。其次,由于医疗图像数据涉及到病人的隐私问题,很多ct图像数据集并没有公开。用这些非公开的数据集训练的模型无法用于其他医院。
技术实现要素:
4.本发明的目的在于提供一种基于半监督学习与注意力机制的新冠肺炎ct图像分析方法。
5.本发明采用了如下技术方案:
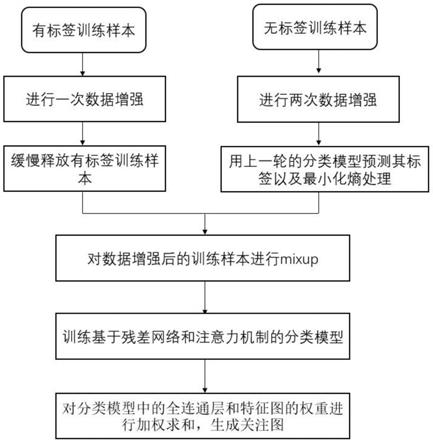
6.一种基于半监督深度学习的新冠肺炎ct图像分析方法,其特征在于,包括以下步骤:
7.(1)建立图像和类别标签的关系,即分类模型,分类模型基于深度学习中的残差神经网络,并加入注意力模块;
8.(2)对每一张无标签训练样本进行两次不同的数据增强得到两张新的图像;
9.(3)通过步骤(1)训练的分类模型对数据增强后得到的图像进行分类,得到其分类结果;
10.(4)对无标签样本增强后的图像的分类结果进行最小化熵处理,将处理后的结果
看作其伪标签;
11.(5)对每一张有标签训练样本进行一次数据增强得到其增强后的图像;
12.(6)将得到伪标签的数据增强后的无标签训练样本和数据增强后的有标签训练样本进行mixup,得到新的训练样本;
13.(7)将新的训练样本和对应的标签代入分类模型中进行训练,更新网络参数信息;
14.(8)在训练过程中,随着未标签训练样本的增加,逐渐去除有标签训练样本,逐步的释放有监督数据的训练信号;
15.(9)对分类模型中的全连通层和特征图的权重进行加权求和,生成关注图,突出与预测结果密切相关的重要区域;
16.(10)用训练好的分类模型对测试集中的样本图像进行分析,并对分析结果生成可视化图。
17.进一步,本发明的基于半监督深度学习的新冠肺炎ct图像分析方法,还具有这样的特征,步骤(1)具体过程为:分类模型采用经典图像分类模型中的残差神经网络模型,并在模型中加入注意力机制的模块,首先将残差神经网络提取的特征图分别经过基于width和height的全局最大池和全局平均池,得到两个经过卷积层的特征图。然后,添加卷积层的输出特征。最后的注意力地图a由sigmoid函数生成:
18.a=sigmoid(conv(avgpool(f)) conv(maxpool(f))),其中f 为残差神经网络提取到的特征,avgpool是平均池化函数,maxpool是最大池化函数,conv是卷积函数。
19.进一步,本发明的基于半监督深度学习的新冠肺炎ct图像分析方法,还具有这样的特征,步骤(2)具体过程为:将无标签图像进行两次数据增强,增强方法有:标准化、几何变换、随机调整亮度和随机调整对比度。
20.进一步,本发明的基于半监督深度学习的新冠肺炎ct图像分析方法,还具有这样的特征,步骤(4)具体过程为:将分类结果进行最小化熵处理,强迫分类器对未标记训练样本做出低熵预测,使用sharpening 函数来最小化未标记数据得熵,形式如下:其中p是概率类别,t是温度参数,用来调节分类熵。i是样本数,j表示从1到类别数,l是总类别数。
21.进一步,本发明的基于半监督深度学习的新冠肺炎ct图像分析方法,还具有这样的特征,步骤(6)具体过程为:将得到伪标签的数据增强后的无标签训练样本和数据增强后的有标签训练样本进行mixup,得到新的训练样本,增强分类模型的鲁棒性。其中mixup的公式如下:
22.x
′
=μ
′
x1 (1-μ
′
)x223.p
′
=μ
′
p1 (1-μ
′
)p224.μ~beta(α,α)
25.μ
′
=max(μ,1-μ)
26.其中x1,p1是有标签训练样本的图像和对应的标签,x2,p2是无标签训练样本的图像和对应的标签。α代表beta的分布参数,μ代表样本混合权重。
27.进一步,本发明的基于半监督深度学习的新冠肺炎ct图像分析方法,还具有这样的特征,步骤(8)具体过程为:在训练的t时刻,设置一个阈值ηt,且1/k≤η
t
≤1,其中,k是类别数。当一个标签例子的正确类别p的概率高于阈值η
t
时,模型从损失函数中删除这个例子,只训练这个minibatch下其他标记的例子。
28.本发明还提供一种基于半监督深度学习的新冠肺炎ct图像分析系统,其特征在于,包括:
29.深度学习模块,建立图像和类别标签的关系,形成分类模型模块,分类模型模块基于深度学习中的残差神经网络,并加入注意力模块;
30.深度学习模块对每一张无标签训练样本进行两次不同的数据增强得到两张新的图像;
31.分类模型模块对数据增强后得到的图像进行分类,得到其分类结果;
32.分类模型模块对无标签样本增强后的图像的分类结果进行最小化熵处理,将处理后的结果看作其伪标签;
33.数据增强模块,对每一张有标签训练样本进行一次数据增强得到其增强后的图像;
34.数据混合模块,将得到伪标签的数据增强后的无标签训练样本和数据增强后的有标签训练样本进行混合,得到新的训练样本;
35.分类模型模块对新的训练样本和对应的标签进行训练,更新网络参数信息;在训练过程中,随着未标签训练样本的增加,逐渐去除有标签训练样本,逐步的释放有监督数据的训练信号;
36.关注图生成模块,对分类模型模块中的全连通层和特征图的权重进行加权求和,生成关注图,突出与预测结果密切相关的重要区域。
37.发明的有益效果:本发明提出了一种通用的半监督深度学习方法,可以通过引入无标签样本,利用模型从中学习到的隐藏分布信息来促进分类器朝着正确的决策方向移动,从而获得更高的泛化性与准确性。在自然图像识别领域,半监督学习能够使用少量的有标签数据和大量的无标签数据来缓解数据不足的问题。
附图说明
38.图1是本发明提供的基于半监督学习和注意力机制的新冠肺炎ct图像诊断方法的流程图。
39.图2是开源的新冠肺炎ct图像数据集的图像示例。
40.图3是本发明提出的分类模型的结构图。
41.图4(a)是消融学习的分类指标直方图。
42.图4(b)是resnet50消融学习的分类指标混淆矩阵。
43.图4(c)是resnet50 attention ssl消融学习的分类指标混淆矩阵。
44.图4(d)是消融学习的分类指标roc曲线。
45.图5是为了更好地了解模型的决策,可视化病变区域的注意图。
具体实施方式
46.以下为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。本发明其流程如图1和图3所示意的,包括如下步骤:
47.(1)建立图像和类别标签的关系,即分类模型,分类模型基于深度学习中的残差神经网络,并在其基础上加入注意力模块。
48.分类模型采用经典图像分类模型中的残差神经网络模型,并在模型中加入注意力机制的模块,增强模型提取特征的能力。首先将残差神经网络提取的特征图分别经过基于width和height的全局最大池化和全局平均池化,得到两个经过卷积层的特征图。然后,添加卷积层的输出特征。最后注意力图a由sigmoid函数生成: a=sigmoid(conv(avgpool(f)) conv(maxpool(f))),其中f 为残差神经网络提取到的特征,avgpool是平均池化函数,maxpool是最大池化函数,conv是卷积函数。
49.(2)对每一张无标签训练样本进行两次不同的数据增强得到两张新的图像。图像中常采用的数据增强方法一般有:标准化,几何变换 (平移、翻转、旋转),随机调整亮度,随机调整对比度等。
50.(3)通过上一阶段训练的分类模型对数据增强后得到的图像进行分类,得到其分类结果。
51.(4)对无标签样本增强后的图像的分类结果进行最小化熵处理,将处理后的结果看作其伪标签。将分类结果进行最小化熵处理,强迫分类器对未标记训练样本做出低熵预测,本发明中使用sharpening函数来最小化未标记数据得熵,形式如下:其中p是概率类别,t是温度参数,用来调节分类熵。i是样本数,j表示从1到类别数,l是总类别数。
52.(5)对每一张有标签训练样本进行一次数据增强得到其增强后的图像。
53.(6)将得到伪标签的数据增强后的无标签训练样本和数据增强后的有标签训练样本进行mixup,得到新的训练样本。增强分类模型的鲁棒性。其中mixup的公式如下:
54.x
′
=μ
′
x1 (1-μ
′
)x255.p
′
=μ
′
p1 (1-μ
′
)p256.μ~beta(α,α)
57.μ
′
=max(μ,1-μ)
58.其中x1,p1是有标签训练样本的图像和对应的标签,x2,p2是无标签训练样本的图像和对应的标签。α代表beta的分布参数,μ代表样本混合权重。
59.(7)将新的训练样本和对应的标签代入分类模型中进行训练,更新网络参数信息。
60.(8)在训练过程中,随着未标签训练样本的增加,逐渐去除有标签训练样本,逐步的释放有监督数据的训练信号。在训练的t时刻,设置一个阈值ηt,且1/k≤η
t
≤1,其中,k是
类别数。当一个标签例子的正确类别p的概率高于阈值η
t
时,模型从损失函数中删除这个例子,只训练这个minibatch下其他标记的例子。阈值η
t
用于防止模型过拟合到标签数据。随着η
t
向1靠近,模型只能缓慢地从标注的实例中得到监督,大大缓解了过拟合问题。
61.(9)对分类模型中的全连通层和特征图的权重进行加权求和,生成关注图,突出与预测结果密切相关的重要区域。
62.(10)用训练好的分类模型对测试集中的样本图像进行分析,并对分析结果生成可视化图。
63.实施例采用本发明提供的基于半监督学习和注意力机制的新冠肺炎 ct诊断的方法,通过新冠肺炎ct图像公开数据集进行验证。
64.使用一个有标记的ct数据集和一个无标记的ct数据集来评估所提出的方法在新冠肺炎ct图像诊断中的应用。有标签的ct数据集是新冠肺炎公共数据集,包含349个阳性和397个阴性ct扫描。图3显示了新冠肺炎ct图像的示例。数据集的划分情况如表1所示。
65.表1:新冠肺炎ct图像数据集的划分情况
66.class训练集验证集测试集新冠肺炎1916098正常23458105总计425118203
67.阳性样本为来自medrxiv和biorxiv的760份covid-19预印本,阴性样本为正常人或其他类型疾病的ct扫描。无标签样本数据集来自 luna数据集,该数据集由低剂量肺ct图像组成,专为患者设计肺结节的检测与分割。我们选取其中500个样本作为无标签样本加入训练集,将这些图像作为无标签图像进行半监督学习。
68.为了充分了解本发明提供的方法的每个部分的效果,进行了以下消融研究,分为四种情况:(1)单独使用残差神经网络;(2)使用残差神经网络加上注意力机制;(3)使用残差神经网络加半监督学习;(4)使用残差神经网络加注意力机制加半监督学习。
69.首先从图4(a)至图4(d)中可以看出,有注意模块的模型比没有注意模块的模型性能更好。这说明所提出的注意模块能够保证模型的决策主要依赖于感染区域,并抑制图像中不相关部分的贡献,从而提高模型的性能。其次,从这个表可以明显看出,当使用半监督学习时,模型的性能得到了改善。这表明半监督学习可以通过扩展数据集来提高模型的泛化能力,降低模型在较小数据集上过度拟合的风险。当同时使用注意模块和半监督学习时,两种模型都取得了最好的性能。第三,当单独使用半监督学习和注意模块时,模型的特异性降低,这表明为了满足特定的需求,可能会牺牲模型的一些优点。
70.图5显示了基线和模型的分类结果可视化图。第一列代表原始的新冠肺炎ct图像。图中的第二三列显示了单独使用残差神经网络的结果。从深红到深蓝的颜色对应于像素的类别显著性从大到小的值。第四五列展示了所提出的模型的结果。通过比较基准结果和本发明的结果,我们观察到所提出的模型几乎可以捕捉到预测的所有显著区域。
71.本实施例还提供一种基于半监督深度学习的新冠肺炎ct图像分析系统,包括:
72.深度学习模块,建立图像和类别标签的关系,形成分类模型模块,分类模型模块基于深度学习中的残差神经网络,并加入注意力模块;
73.深度学习模块对每一张无标签训练样本进行两次不同的数据增强得到两张新的
图像;
74.分类模型模块对数据增强后得到的图像进行分类,得到其分类结果;
75.分类模型模块对无标签样本增强后的图像的分类结果进行最小化熵处理,将处理后的结果看作其伪标签;
76.数据增强模块,对每一张有标签训练样本进行一次数据增强得到其增强后的图像;
77.数据混合模块,将得到伪标签的数据增强后的无标签训练样本和数据增强后的有标签训练样本进行混合,得到新的训练样本;
78.分类模型模块对新的训练样本和对应的标签进行训练,更新网络参数信息;在训练过程中,随着未标签训练样本的增加,逐渐去除有标签训练样本,逐步的释放有监督数据的训练信号;
79.关注图生成模块,对分类模型模块中的全连通层和特征图的权重进行加权求和,生成关注图,突出与预测结果密切相关的重要区域。
80.本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
