本发明属于计算机网络领域,具体涉及一种基于深度学习和跨域协作的负载均衡方法及装置。
背景技术
当今数据中心网络的带宽需求日益提升,为了应对需求数据中心开始横向扩展,但硬件资源堆叠到一定程度后获取的收益并不理想,数据中心网络依然会出现传输时延增大、丢包率增大,链路出现拥塞等问题,因此数据中心的网络资源如何实现合理的分配是当前面临的一大挑战。
目前数据中心网络负载均衡的主要研究方法有:(1)传统式的负载均衡算法包括轮询算法、贪婪算法、哈希算法。采用较多的是基于哈希算法的等价多路径方案。它部署简单,可以在一定程度实现网络的负载均衡。但是随着网络的带宽增大,业务多变性增加,它可能产生哈希冲突,无法实现数据中心网络负载最优。(2)基于端的负载均衡方案,在终端中添加相应的硬件或者安装软件用于获取出入站的流量,用于平衡路径的利用率。但是由于是位于终端的测量,将无法获取网络链路准确的拥塞情况。(3)基于交换机的负载均衡方案,交换机在路由协议的规则下,为每个流随机的选择输出端口,每个流能够根据其路径上实时负载状况来自适应的改变传输包的粒度大小,在拥塞路径上流被切分的概率更大,在空闲路径上被切分的概率更小。这样可以实现持续的、高效的传输,也可以实现粒度的弹性调整,提高空闲链路的利用率。(4)集中式的复杂均衡方案,Hedera是采用集中式、动态的流量管理方案。它将超过链路带宽的10%的流量定义为大流。通过集中的控制器来采集边缘交换机的流量信息,进而计算整个网络的负载状况,再利用估计算法实现网络大流的检测,对检测到的大流进行评估,然后求出此流的最优转发路径。但没有考虑到从测量到下发流表的时滞性,最终得到的路由方案并不能是当前时刻的最优解。
技术实现要素:
由于数据中心网络流量特有的高动态性,使得对网络拥塞的感知具有时滞性,即当前感知到的拥塞信息为过时的状态。而控制平面的资源消耗主要来自于流量流表请求,在分布式控制器的情况下,跨域流会产生冗余的请求消息。为在保障数据平面负载均衡的同时,兼顾控制平面的资源消耗,针对以上网络特点和存在的问题,本发明提供了一种基于深度学习和跨域协作的负载均衡方法及装置,实现网络负载均衡。
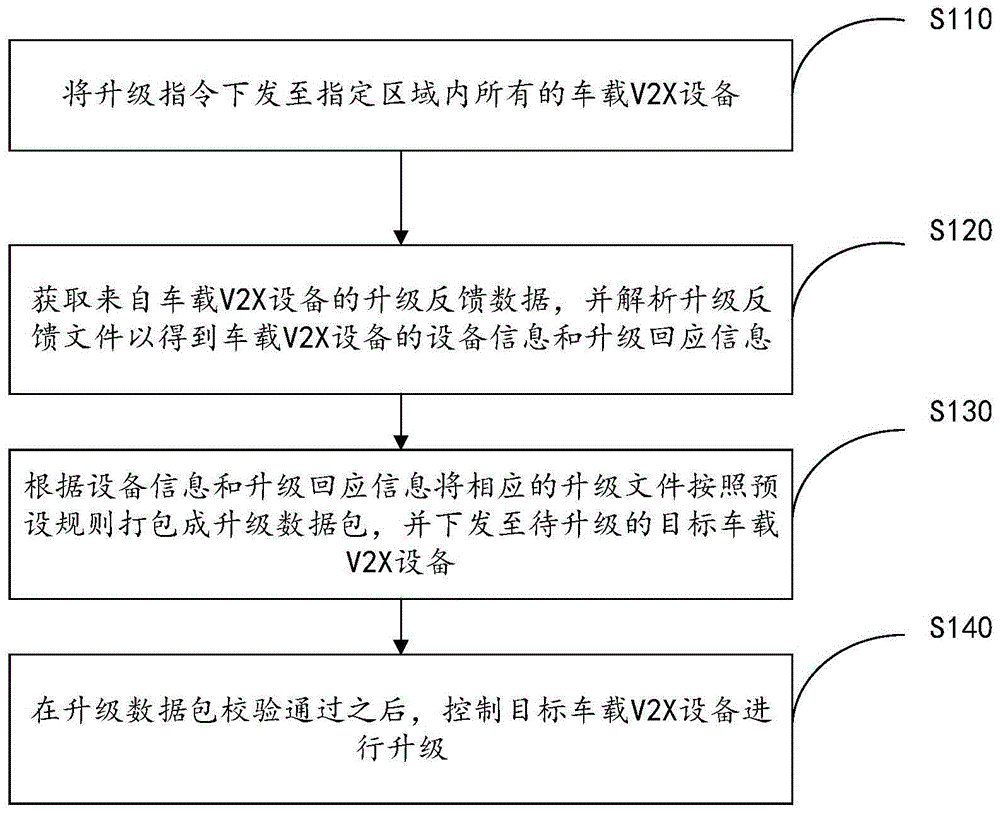
一种基于深度学习和跨域协作的负载均衡方法,包括以下步骤:
S1.获取数据中心网络数据层的流表参数和端口参数,并计算各链路带宽占用率;
S2.根据流表参数和端口参数,构建数据中心网络链路的特征向量矩阵和邻接矩阵;
S3.构建关联时空的链路负载状态预测模型,将特征向量矩阵和归一化的邻接矩阵作为输入预测下一周期的当前链路负载状态值;
S4.将步骤S3预测的当前链路负载状态值与步骤S1得到的对应链路带宽占用率融合,得到当前链路的最终可选度;
S5.结合步骤S4中得到的各个链路的最终可选度建立流量调度数学模型,流量调度数学模型采用改进人工蜂群算法来计算流量的传输路径并下发流表到各交换机;
S6.构建控制平面资源管理模块,通过控制平面资源管理模块控制流量跨域实现负载均衡。
进一步的,关联时空的链路负载状态预测模型包括两个图卷积层和一个循环层,通过该模型预测下一周期的当前链路负载状态值,包括:
S11.将特征向量矩阵和归一化的邻接矩阵输入第一图卷积层,第一图卷积层的输出输入第二图卷积层得到输出特征,其表示为:
S12.将第二图卷积层的输出特征送入循环层得到结果矩阵,其表示为Z=[z11,...,zij]T,行向量表示链路lij的五种概率,为链路lij的链路空闲概率,为链路lij的正常负载概率,为链路lij的可能拥塞概率,链路lij的一般拥塞概率,为链路lij的重度拥塞概率;
S13.选取链路lij五种概率中的最大概率,将最大概率对应的链路状态值作为下一周期的当前链路负载状态值;
其中,ξ~Benoulli(p)表示伯努利分布作为Dropout中间层表达式,H2表示第二图卷积层的输出特征,W0、W1分别表示第一图卷积层的线性变换矩阵和第二图卷积层的线性变换矩阵,表示归一化的邻接矩阵,E表示特征向量矩阵,ReLu表示激活函数。
进一步的,循环层包括两层堆叠的LSTM结构,在两层堆叠的LSTM结构之间应用Dropout进行正则化,循环层得到结果矩阵的过程为:
将图卷积层的输出特征按时间顺序分段后输入到第一层堆叠的LSTM结构,根据分段的输出特征计算初始重要度值表示为:
将初始重要度值经过softmax处理得到时间重要度表示为:
将时间重要度与分段的输出特征相乘得到图卷积层历史输出的重要度ct':
将第一层堆叠的LSTM结构得到的图卷积层历史输出的重要度ct'输入到第二层堆叠的LSTM结构进行计算,得到结果矩阵;
其中,Ud、Wd是需要学习的参数,dt'-1、s't'-1在第一层堆叠的LSTM结构中采用初始值,第二层堆叠的LSTM结构中采用第一层堆叠的LSTM结构的输出值和隐藏状态。
进一步的,链路的最终可选度表示为:
qij(t T)=μSij(t T) (1-μ)Sij(t) αTij(t) βιij(t);
其中,Sij(t T)为链路lij在t T时刻的预测状态值,Sij(t)为链路lij在t时刻的测量状态值,Tij(t)为链路lij在t时刻的时延,ιij(t)为链路lij在t时刻的丢包率,max(pij)和min(pij)分别表示链路lij的最大带宽占有率和最小带宽占用率,μ表示链路预测状态值的权重,α表示传输时延的权重,β表示网络丢包率的权重。
进一步的,改进人工蜂群算法实现步骤包括:
S21.在D维空间,给定蜜蜂总数S,蜜源最大开采次数genmax,观察蜂数量sizegc=S/2,最大连续更新失败次数limit;
S22.通过蜜源生成公式随机生成nPop个蜜源,第i个蜜源Xi的位置表示为根据适应度公式计算每个蜜源的适应度,其中:
蜜源随机生成公式为:
适应度公式为:
其中,和是第i个蜜源Xi在整个搜索空间第j维的上下界,rand(0,1)表示(0,1)范围内的一个随机数,fiti表示蜜源的适应度,F(Xi)表示当前蜜源Xi对应的函数值;
S23.每一只雇佣蜂对应一个蜜源,称该蜜源为原蜜源,雇佣蜂在原蜜源周围搜索获取新蜜源并计算新蜜源的适应度,判断新蜜源的适应度是否优于原蜜源的适应度,若是,则新蜜源成为原蜜源,并将连续更新失败计数器归零,若不是,则舍弃新蜜源,且连续更新失败计数器的值加1,所有雇佣蜂完成搜索后将搜索结果分享给观察蜂;其中,搜索范围表示为:
其中表示第i个蜜源Xi在j维产生的新值,表示第i个蜜源Xi在j维的值,表示第k个蜜源Xk在j维的值,k为{1,2,…,K}之间的随机数且k≠i,表示[-1,1]之间的一个随机实数;
S24.根据蜜源适应度计算每个蜜源被选择的概率,观察蜂通过轮盘赌的方式选择蜜源,观察蜂接收雇佣蜂分享的搜索结果后搜索最新蜜源并计算最新蜜源的适应度,判断最新蜜源的适应度是否优于雇佣蜂搜索后确定的原蜜源的适应度,若是,则最新蜜源成为原蜜源,并将连续更新失败计数器归零,若不是,则舍弃最新蜜源,且连续更新失败计数器的值加1;
S25.记录所有蜜源连续更新失败计数器的值,组成所有蜜源连续更新失败的次数集合counter,将counter中的最大值与最大连续更新失败次数limit进行比较,若最大值超过limit,则将该最大值所映射的蜜源的雇佣蜂或观察蜂转变为侦察蜂,通过蜜源随机生成公式生成第二蜜源,第二蜜源生成后将侦查蜂转变为雇佣蜂;
S26.判断是否满足搜索终止条件fesmax即最大迭代次数,若满足,则退出,否则返回步骤S23。
进一步的,将观察蜂通过轮盘赌的方式选择蜜源改进为观察蜂随机飞向前n个最优雇佣蜂对应的蜜源,且蜜源搜索范围改进为:
其中,表示从前n个最优雇佣蜂对应的蜜源中随机选出的一个不同于Xi的蜜源在j维的值。
一种基于深度学习和跨域协作的负载均衡装置,包括:
环境感知模块,用于获取交换机流表信息和端口参数,计算各链路的带宽占用率、传输速率、丢包率,周期性更新网络拓扑结构;
特征向量矩阵模块,用于根据环境感知模块的流表信息和端口信息构建数据中心网络各链路的特征向量矩阵;
邻接矩阵模块,用于构建表示网络拓扑结构的邻接矩阵;
链路负载预测模块,用于根据特征向量矩阵和归一化的邻接矩阵作为预测下一周期的当前链路负载状态值;
流路由计算模块,用于对链路负载预测模块的预测结果和链路带宽占用率进行融合,得到各链路的可选度,根据链路可选度计算流量的传输路径;
流表下发模块,用于将路由计算模块计算的流量的传输路径下发给交换机;
控制平面资源管理模块,用于通过跨域协作的方式控制跨域流量。
进一步的,控制平面资源管理模块通过交换机迁移方式实现跨域协作,控制平面资源管理模块中计算流的跨域次数的公式为:
其中,wk表示流的跨域次数,通过判断流的传输路径是否经过控制器cm管理的域,其表示为:
表示流的传输路径经过控制器cm管理的域,表示流的传输路径不经过控制器cm管理的域,表示流经过控制器cm域下的交换机次数,计算公式为:
xmn为控制器与交换机的关联关系即迁移结果,表示流经过的交换机,N为链路总数。
本发明的有益效果:
本发明通过数据中心网络拓扑的非欧氏几何空间结构以及流量时序数据的时间关联性,设计了一种融合图卷积神经网络和循环神经网络的链路负载状态预测模型周期性地预测各链路下一刻的负载状态,计算链路可选度,构建数学模型确定目标函数,将改进人工蜂群算法应用到路径的求解问题上求出最优解,达到网络的负载均衡。
相比于传统方法,在流量具有高动态性的数据中心中,本发明可以准确预测下一刻链路负载状态,及时准确地感知网络拥塞情况,结合链路可选度可以快速计算出流量传输路径,避免大流碰撞和减少流量跨域次数,通过跨域协作的方式降低控制平面资源消耗,进一步提高数据平面传输性能,达到网络整体的负载均衡。
附图说明
图1为本发明的基于深度学习和跨域协作的负载均衡方法流程图;
图2为本发明的系统框架示意图;
图3为本发明的核心层-聚合层网络拓扑结构图;
图4为本发明环境感知模块结构图
图5为本发明的负载状态预测模型结构图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
为了应对庞大的流量数据,数据中心网络的规模不断的扩张,由原来单纯增加数据中心数量演变为网络结构的横向扩展,研究者们提出了许多新型的网络拓扑结构,主要包括以交换机作为核心的Fat-Tree(胖树拓扑类型)和以服务器作为核心的DCell。如今大多数数据中心采用胖树拓扑结构,其包括核心层、聚合层和边缘层,不同层的链路往往具有不同的负载特征,同时源节点和目的节点之间又存在多条等价路径。因此在软件定义的胖树拓扑类型数据中心网络中,各个节点具有自己的结构信息和特征信息,但这些网络空间层面的复杂性是研究者所忽视的。
在此基础上,本发明提供了一种基于深度学习和跨域协作的负载均衡方法及装置,通过获取数据中心网络的时空特征,实现精准预测链路的负载状态,针对控制平面在分布式控制器的情况下,跨域流会产生冗余的请求消息的问题,通过跨域协作的方式来减少跨域流在控制平面的资源消耗,达到网络负载均衡。
在一实施例中,如图2所示,控制平面与数据平面之间的信息相互交流,数据平面采用OpenFlow交换机和胖树网络拓扑结构,控制平面分为环境感知模块、链路负载状态预测模块、控制平面资源管理模块、流路由计算模块和流表下发模块,针对数据中心网络非欧氏的网络拓扑结构以及流量时序数据的时间关联,在流量信息采集和处理的基础上,通过融合图卷积层和LSTM层的链路负载状态预测模型得到下一时刻的链路负载情况,再通过路由计算模块得到最佳流量调度方案并将流量下发至OpenFlow交换机,控制平面监测各域中跨域流的数量,通过协作迁移交换机的方法减少跨域流请求次数,降低控制平面资源的消耗,最终实现网络的负载均衡。
在一实施例中,一种基于深度学习和跨域协作的负载均衡方法,如图1所示,包括以下步骤:
S1.获取数据中心网络数据层的流表参数和端口参数,并计算各链路带宽占用率;
S2.根据流表参数和端口参数,构建数据中心网络链路的特征向量矩阵和邻接矩阵;
S3.构建关联时空的链路负载状态预测模型,将特征向量矩阵和归一化的邻接矩阵作为输入预测下一周期的当前链路负载状态值;
S4.将步骤S3预测的当前链路负载状态值与步骤S1得到的对应链路带宽占用率融合,得到当前链路的最终可选度;
S5.结合步骤S4中得到的各个链路的最终可选度建立流量调度数学模型,流量调度数学模型采用改进人工蜂群算法来计算流量的传输路径并下发流表到各交换机;
S6.构建控制平面资源管理模块,通过控制平面资源管理模块控制流量跨域实现负载均衡。
具体地,在基于深度学习和跨域协作的负载均衡方法中,步骤S1-S5是对数据平面的大流进行调度,大流调度完成后又考虑到多控制器情况下,流量会出现跨域情况,因此步骤S6又构建了控制平面资源管理模块对跨域流量进行控制,相当于减少了控制平面的负载压力。
在一实施例中,数据中心网络建模并表示为G=(V,L)。其中,V={v1,v2,...,vM}表示数据中心网络数据平面交换机节点集合,M表示交换机总数,L表示数据中心的网络链路集合,该集合中链路总数量为N,lij表示交换机vi与交换机vj之间连接的链路,lij∈L,i∈M,j∈M。
优选地,控制器通过周期性下发Status_request消息得到交换机的状态参数,包括流表参数和端口参数,根据得到的端口参数得到端口接收和转发的字节数,并计算两端口之间链路的带宽占用率。Fi(t)=[fi1(t),fi2(t),...,fiy]为流表参数,fiy表示某一流表参数,y表示流表参数类型,表示交换机vi的p端口的各类型参数集合,表示交换机vi的p端口的某一端口参数,n表示端口参数类型,表示交换机vj的q端口的各类型参数集合,交换机vi的p端口与交换机vj的q端口相连接的链路为lij,此时链路lij的带宽bij(t)表示为:
其中表示交换机vi的p端口在t时刻转发的字节数,表示交换机vj的q端口在t时刻转发的字节数,i、j表示交换机编号,p、q表示交换机对应端口编号,T表示采集的周期时间大小。若链路lij最大的带宽为max(Bij),则t时刻lij链路的带宽占用率可表示为:
时延主要包括链路的传输时延和交换机处理时延。通过统计LLDP和ECHO数据包中的时间戳来计算出链路传输时延。链路lij正反向平均传输时延Tij(t)可表示为:
表示LLDP数据包从控制器下发经过交换机vi和交换机vj并返回控制器的正向传输时延和反向传输时延,表示控制器到交换机vi和交换机vj的传输时延。
优选地,传统网络丢包率的测量方式往往为主动测算,在业务量较大、网络传输数据较多的时候,主动测算会影响业务的运行和测算结果的精准度。在基于OpenFlow协议的软件定义的数据中心网络中,可以通过统计南北通信数据中的Flow_removed消息体的丢包率来测算网络丢包率,计算丢包率的公式表示为:
其中,ιij(t)表示链路lij在t时刻的丢包率,ai表示交换机vi实际发送的数据包数量,bj表示交换机vj最终收到的数据包数量。
在以上主动测量的基础上,添加混合测量方法,通过带内网络遥感技术可以在间隙时刻依然保证网络监控的实时、包粒度、端到端的能力。同时可以减少网络测量包的数量,在保证数据时效性的同时,还能减少冗余数据,减轻控制平面和数据平面的负载。周期间隙内,在数据平面收集数据,通过交换机在数据包中夹带拓展头,直接通过数据平面收集处理消息,此时数据平面主动推送,控制平面被动信任接受,省去下发损耗的时间,在数据包每一跳的过程中,交换设备都会将状态信息压入到该数据包,在最后一跳时,整条路径的信息将一起上传给控制器。
本发明使用Ryu控制器,实现软件定义的数据中心网络拓扑结构和网络类型的感知用到了控制器中的topology.switches模块,在该模块下调用get_switch、get_host以及get_link来获取交换机列表、主机的信息和链路信息。
优选地,根据流表参数和端口参数,构建数据中心网络各链路的特征向量矩阵,交换机端口参数的特征值选取包含:接收到的数据包数,转发的数据包数,接收的字节数,转发的字节数,接收时丢弃的数据包数,转发时丢弃的数据包数;交换机流表参数的特征值选取包含:交换机流表容量,根据流表转发的数据包数,根据流表转发的字节数,数据流持续时间,数据流额外生存时间,流表项从交换机移除的相对时间,流表项从交换机移除的绝对时间。链路lij的特征向量由它所占用的两个OpenFlow交换机vi、vj的端口参数和交换机部分流表参数构成,链路lij的特征向量e(ij)表示为:
e(ij)=[Fi(t1),Fj(t1),Pi,p(t1),Pj,q(t1)];
Fi(t1),Fj(t1)表示交换机vi和交换机vj在t1时刻的流表参数,Pi,p(t1)为交换机vi在t1时刻的p端口参数,Pj,q(t1)为交换机vj在t1时刻的q端口参数,所有链路的特征向量组成特征向量矩阵E,表示为:
E=[e(11),e(12),...,e(ij)]T;
其中E的行数为m,表示数据中心网络中的链路数,列数为n表示特征类型。
采用A=EN×N表示数据中心网络的各个链路的连通关系矩阵,N表示数据中心网络的链路总数量。假设存在如图3所示的数据中心核心层和聚合层的网络拓扑关系,故其网络拓扑结构可用邻接矩阵A抽象的表示为:
图中记录了4个核心交换机和2个Pod下的聚合交换机及它们的连接关系,图中v1到v4表示的交换机为聚合交换机,v5到v8表示的交换机为核心交换机,图中v1和v5相连,则矩阵A中第1行第5列的数值为1,这里在程序实现的时候可以使用稀疏矩阵节省内存空间,为了较好处理数据中心网络结构中复杂庞大的数据量、获取空间特征信息,将邻接矩阵按如下公式处理成一个对称归一化拉普拉斯矩阵:
I表示单位矩阵,A表示网络链路的邻接矩阵,D表示度矩阵。
软件定义的数据中心网络中每个交换机节点都具有自己的结构信息和特征信息,目前最为常用的网络拓扑结构是胖树拓扑结构包括核心层、聚合层和边缘处。各层所处的链路功能性不同,不同分发点内的服务器进行通信时需要经过核心交换机,聚合层负责流量的汇聚和分发,边缘层是终端流量的入口,因此各层链路的负载情况也与其空间结构具有一定的关联,基于图谱理论的图卷积神经网络能够有效学习节点的空间特征信息,为了获取网络流量的空间关联性引入图卷积网络。在受到用户行为驱动产生的数据中心网络在线负载存在一定的时间序列特性,包括有流式计算、Web服务等业务,其负载大多以小时为周期,具有相似的变化趋势,大多数周期内数据的变化幅度高度相似。为了获取网络流量的时间关联性引入循环层,最大限度实现网络流量的精准预测。
优选地,构建关联时空的链路负载状态预测模型,将特征向量矩阵和归一化的邻接矩阵作为输入预测下一周期的当前链路负载状态值,关联时空的链路负载状态预测模型包括图卷积层和循环层,结构如图5所示,layer1和layer2神经网络分别为第一图卷积层和第二图卷积层,layer3为第一层堆叠的LSTM结构,layer4为第二层堆叠的LSTM结构,由两层堆叠的LSTM结构组成的循环层。
利用图卷积层可以处理非欧氏空间的网络拓扑结构,获取数据中心网络流量中的空间关联性。两层堆叠的图卷积层的传播规则可以表示为:
其中,ξ~Benoulli(p)表示伯努利分布作为Dropout中间层表达式,H2表示第二图卷积层的输出特征,W0、W1分别表示第一图卷积层的线性变换矩阵和第二图卷积层的线性变换矩阵,即第一图卷积层和第二图卷积层的网络权重,表示对称归一化的拉普拉斯矩阵即归一化的邻接矩阵,E表示特征向量矩阵,ReLu表示激活函数。
将图卷积层的输出特征送入循环层得到结果矩阵,表示为Z=[z11,...,zij]T,行向量表示链路lij的五种概率,为链路lij的链路空闲概率,为链路lij的正常负载概率,为链路lij的可能拥塞概率,链路lij的一般拥塞概率,为链路lij的重度拥塞概率,如表1所示:
表1链路负载状态表
选取链路lij五种概率中的最大概率,将最大概率对应的链路状态值sij(t T),sij(t T)∈{1,2,3,4,5},作为下一周期的当前链路负载状态值。
通过循环层来获取链路负载中的时间关联,使用长短期记忆实现循环层,通过两层堆叠的LSTM(长短期记忆)结构,在LSTM层之间应用Dropout进行正则化。具体地,循环层的操作过程包括:
将图卷积层的输出特征分段,按时间顺序输入到循环层,初始重要度数值的计算方式如下:
其中,Ud、Wd是需要学习的参数,dt'-1、s't'-1在第一层堆叠的LSTM结构中是初始值,第二层堆叠的LSTM结构中采用第一层堆叠的LSTM结构的输出值和隐藏状态。继续将初始重要度值经过如下softmax处理,得到时间重要度
再将得到的时间重要度与相乘即可得到图卷积层历史输出的重要度,并用上下文向量ct'表示:
第一层堆叠的LSTM结构中的所有LSTM单元依据上述操作得到图卷积层历史输出的重要度,并将其输入到第二层堆叠的LSTM结构中,依据上述三个公式得到输出特征矩阵作为循环层的输出即Z=EN×K,N为链路的总数量,K表示链路负载状态类别。
在一实施例中,步骤S4当前链路的最终可选度表示为:
qij(t T)=μSij(t T) (1-μ)Sij(t) αTij(t) βιij(t);
其中,Sij(t T)为链路lij在t T时刻的预测状态值,Sij(t)为链路lij在t时刻的测量状态值,Tij(t)为链路lij在t时刻的时延,ιij(t)为链路lij在t时刻的丢包率。
max(pij)和min(pij)分别表示链路lij的最大带宽占有率和最小带宽占用率。
数据中心网络中的流量用数据流来表征,每个流是由源节点到目标节点的数据包序列来进行标识,分组报头字段定义了源地址、目标地址、端口和传输协议等。数据中心网络的流量可以分为两个范畴:南北流量和东西流量。南北流量是关于源主机和目标主机之间的通信产生的流量,如用户对服务端请求所产生的流量。东西流量是关于数据中心网络内部通信产生的流量,如内部虚拟机同步、迁移所产生的流量。研究表明,南北流量占比25%左右,东西流量占比75%左右。从流量的对称性方面看,用户到服务的请求是丰富的,但是大部分的请求流量都是很小的。然后服务在处理这些请求后,通常返回的都是相对较大的流量。从流量的大小、数目来看,数据中心网络的流量可以分为大象流和老鼠流两类。老鼠流通常不到10KB并且持续时间只有几百毫秒,但数量占据数据中心网络的80%以上。大象流数量虽然在数据中心网络中占据的数量较少,但其占整个网络总流量的一半以上,大部分大象流持续时间较长,影响较大。由此可见,大象流和老鼠流符合重尾分布。
优选地,根据各个链路的最终可选度建立流量调度数学模型,流量调度数学模型采用改进人工蜂群算法来计算流量的传输路径并下发流表到各交换机;
具体地,流量调度数学模型包括:
在一个k叉的胖树拓扑数据中心网络中,核心层交换机的个数为(k/2)2,不同Pod下的源地址和目的地址之间的等价路径与路径经过核心交换机的次数有关,若在最短路径情况下即只经过一次核心交换机,那核心交换机到边缘交换机路径唯一确定。因此最小化大流路由过程中核心交换机的碰撞次数即可最大程度减少大流出现本地碰撞和下行链路碰撞。本发明调度问题可描述为:在拓扑结构为G=(V,L)的数据中心网络中,观察周期T内有K条大流F=(f1,f2,f3,...K,f需要调度。链路容量约束条件表示为:
不等式表示链路的可用带宽需大于路由到此链路的流的总带宽,Bij表示链路lij的总带宽,bij表示链路lij占用带宽,bk表示第条待调度大流所需的带宽,K表示待调度大流的数量,dij表示链路lij是否经过链路等于1表示经过,等于0表示不经过。满足容量约束情况下流fK的可选路径集合为M表示可选路径总数。
路径的可选度可以通过整合链路可选度求得,本发明为了避免链路资源碎片化,避免路径中出现单条链路资源过低问题,将通过计算标准差来表示路径可选度。由步骤S4求得链路lij的可选度为qij,路径的平均可选度表示为则路径的可选度可表示为:
流量调度数学模型的最终目标函数可以定义为:
其中hcore表示大象流在核心交换机的碰撞程度。流量调度数学模型通过控制降低大象流在核心交换机的碰撞程度,可以自然减少整个网络的大象流发生碰撞。
优选地,本实施例采用的改进人工蜂群算法进行流量调度的过程包括:
101、初始化参数设置:种群数量即蜜蜂总数S,蜜源最大开采次数genmax,搜索终止条件fesmax,蜜源个数nPop,雇佣蜂数量sizegy,sizegy=nPop,观察蜂数量sizegc=S/2,所有蜜源连续更新失败的次数集合counter,最大连续更新失败次数limit;
102、初始化种群阶段:设为种群第i个蜜源的位置,D表示可行解的维度。每个蜜源的位置通过蜜源随机生成公式随机生成,其表示为:
其中和是第i个蜜源Xi在整个搜索空间第j维的上下界,rand(0,1)表示(0,1)范围内的一个随机数。当个体初始化后,通过以下公式来确定适应度:
其中fiti表示蜜源的适应度,F(Xi)表示当前蜜源Xi对应的函数值,即优化问题的函数值,函数值越小,适应度fiti越好;
103、雇佣蜂阶段:雇佣蜂和蜜源(即食物源)是一一对应的,雇佣蜂尝试在其对应的当前蜜源周围找到更优的蜜源,其搜索范围可以定义为:
其中表示蜜源i在j维产生的新值,表示蜜源i在j维的值,表示蜜源k在j维的值,k表示{1,2,…,K}之间的随机数且k≠i,表示[-1,1]之间的一个随机实数。雇佣蜂在原蜜源周围搜索获取新蜜源并计算新蜜源的适应度,将新蜜源的适应度与原蜜源的适应度进行对比,如果新蜜源的适应度更好,则认为新蜜源相比于原蜜源更优秀,将新蜜源看做原蜜源并将连续更新失败计数器count(Xi)归零,如果新蜜源适应度不如原蜜源适应度,则舍弃新值,连续更新失败计数器count(Xi)增1,在所有雇佣蜂完成局部搜索任务后,它们会将搜索结果分享给观察蜂;
104、观察蜂阶段:首先根据蜜源适应度来计算每个蜜源被选择的概率,适应度越好则被选择的概率越大,观察蜂再通过轮盘赌的方式来选择蜜源,蜜源被选择概率可以表示为:
其中pi表示蜜源Xi被选中的概率,蜜源适应度越大被选中的概率也越大。观察蜂确定了选择的蜜源后会飞向该蜜源,并通过雇佣蜂阶段的搜索公式采集最新蜜源Vi,新蜜源Vi在j维的新值即为通过计算最新蜜源Vi的适应度并且与雇佣蜂阶段确定的原蜜源的适应度比较,如果最新蜜源Vi的适应度较好,则最新蜜源成为原蜜源,并将连续更新失败计数器count(Xi)归零;如果最新蜜源Vi的适应度不如雇佣蜂阶段确定的原蜜源Xi的适应度,则保留雇佣蜂阶段确定的原蜜源并将连续更新失败计数器count(Xi)增1;
105、侦察蜂阶段:记录所有蜜源连续更新失败计数器的值,组成所有蜜源连续更新失败的次数集合counter,从counter中选取最大值和最大连续更新失败次数limit比较,如果最大值超过最大连续更新失败次数limit,则将该最大值所映射的蜜源Xd对应的雇佣蜂或观察蜂转变为侦察蜂并通过蜜源随机生成公式生成新的蜜源,完成后侦察蜂再次转变为雇佣蜂,保证雇佣蜂和蜜源一一对应;
106、经过多次迭代符合终止条件退出后,最终留下的蜜源即为符合目标函数和多约束条件的最优解,将目标路径交由流表下发模块完成观察周期T内K条大流F=(f1,f2,f3,...,fK)的转发。
当在数据中心中引入SDN后,网络资源主要包括为数据平面资源和控制平面资源。随着数据中心的纵向扩展,为了实现网络高性能、低延迟,在控制平面往往是采用的分布式控制器,每个控制器管理自己的域,其中控制平面资源的消耗主要来自于响应新流的请求消息。在单控制器的情况下,一个新流仅需要一次响应即可将该流的流表下发至路由路径中的各个交换机,但在分布式控制器的情况下,存在流量跨域的场景即流量的路径经过两个或以上的控制器管理域,当流量跨域后,需要再次请求所经域的控制器下发流表,因此请求次数和跨域次数是一致的。因此流请求消息数量与控制平面的资源消耗呈正相关,但控制资源的需求不能仅从请求数量来衡量,应该以减少控制平面资源消耗为目标,结合数据平面的流量路径选择和控制平面的跨域协作这两种方法实现网络负载均衡:数据平面中流量路径选择时,考虑路径的跨域次数;控制平面分布式控制器的情况下,考虑通过域间交换机迁移的方式来减少流量跨域次数。
数据平面的路径选择已在上文阐述过,这里重点分析以交换机迁移方式实现的跨域协作负载均衡方法。控制平面控制器包括C={c1,c2,...,cM},数据平面交换机包括V={v1,v2,...,vN}。控制器与交换机的关联关系即迁移结果可以用矩阵X=[xmn]M×N表示,其中xmn=1表示cm与vn相连,xmn=0表示cm与vn不相连。在周期时间T内,存在流量集合F=(f1,f2,f3,...,fK),流fK的路径为pk,其经过交换机集合可用向量pk=[s1,s2,...,sN]表示,其中sn=1表示经过交换机vn,sn=0表示不经过交换机vn。流fK经过控制器cm域下的交换机次数表示为:
则流fK的所跨的域表示为:
其中表示流fK的传输路径经过控制器cm管理的域,同时,流fK的跨域次数可表示为:
控制器cm的负载可以表示为:
其中,μ表示请求消息资源消耗系数,因此控制平面在T周期内的资源消耗量可以表示为:
在交换机迁移过程中,需保证交换机vn与控制器的距离满足dmn<D;保证一个交换机只属于一个控制器下的域保证控制器当前负载不超过其最大值ωm<Wm;最终转化为对多约束目标函数最小化值的求解。
为了满足跨域协作的快速性要求,根据改进人工蜂群算法中观察蜂拥有全局视野的条件,将原本的观察蜂通过轮盘赌方法选择雇佣蜂进一步改进为观察蜂只需要飞向优秀的雇佣蜂进行搜索,一方面可以减少选择时间,另一方面可以增强全局性的信息交互。但是如果仅选择种群最优的雇佣蜂,最终解容易陷入局部最优,因此观察蜂将随机飞向前个最优雇佣蜂对应的蜜源,可将搜索范围改进为:
通过对前n个最优雇佣蜂的限定,可以充分利用全局信息交换,避免陷入局部最优的前提下加快搜索速度,通过多次迭代搜索,可以得到最优的控制平面与交换机的关联关系矩阵,改变控制器与交换机之间的关联关系,迁移交换机,较少数据平面的跨域流量数量。
一种基于深度学习和跨域协作的负载均衡装置,包括:
环境感知模块,用于获取交换机流表信息和端口参数,计算各链路的带宽占用率、传输速率、丢包率,周期性更新网络拓扑结构;
特征向量矩阵模块,用于根据环境感知模块的流表信息和端口信息构建数据中心网络各链路的特征向量矩阵;
邻接矩阵模块,用于构建表示网络拓扑结构的邻接矩阵;
链路负载预测模块,用于根据特征向量矩阵和归一化的邻接矩阵作为预测下一周期的当前链路负载状态值;
流路由计算模块,用于对链路负载预测模块的预测结果和链路带宽占用率进行融合,得到各链路的可选度,根据链路可选度计算流量的传输路径;
流表下发模块,用于将路由计算模块计算的流量的传输路径下发给交换机;
控制平面资源管理模块,用于通过跨域协作的方式控制跨域流量。
优选地,环境感知模块的流程如图4所示,包括:
S101.基于OpenFlow协议的主循环函数,同时监测间隔时间和link;
S102.判断间隔是否超过周期,若是,则进入步骤S104,否则,返回步骤S101;
S103.判断link是否变化,若是,则执行步骤S104,否则,返回步骤S101;
S104.获取交换机列表信息和链路信息,并根据交换机列表信息和链路信息得到交换机端口列表、以及交换机端口与链路的对应关系,然后返回步骤101。
具体地,主循环函数执行拓扑更新时间间隔判断,如果未超过预设时间重新进入主循环函数,如果间隔时间超过预设时间则开始更新拓扑信息:调用get_switch函数获取交换机列表信息,调用get_link函数获取链路信息,根据获取到的信息构建网络拓扑关系。如果监听到发生link事件,则开始更新拓扑信息和记录拓扑更新时间。更新完毕,重新进入主循环函数,循环操作。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。