1.本发明实施例涉及自然语言处理与图神经网络领域,具体涉及一种识别在线产品社区高价值用户创意的系统及方法。
背景技术:
2.作为连接企业与广大用户的互联网开放式创新渠道,企业主导的在线产品社区已成为汇聚产品创意,优化用户体验,实现价值共创的重要手段,其中,满足企业需求,且受到在线社区用户推崇的产品创意称为高价值用户创意。在线产品社区不仅包含大量的原创内容,也沉淀有海量的用户社交关系,创意引发用户互动,互动激发创意涌现。随着产品社区规模的不断扩大,如何基于数据 算法智能识别高价值用户创意成为企业关注且亟待解决的难题。传统的高价值用户创意识别,或者由社区管理员人工甄别,人力投入大、工作效率低且存在主观偏见;或者基于创意文本属性特征(如内容长度、评论分数等)构建算法模型,较少考虑创意之间的关系以及用户社交互动对创意迭代的影响,识别准确度不高。不同于其他类型的在线开放创新社区,发明人认为,企业主导的在线产品社区具有以下特点:(1)用户创意聚焦企业产品,且创意之间存在不同程度的联系;(2)用户针对创意产生的评论,相互间存在语义和情感的关联、同质效应;(3)在线产品社区因用户创意与用户社交的共生互动而不断演化。既有的用户创意发现算法大都沿着两条技术路线展开,一是从文本特征,如创意标题、内容长度,创意来源和可接受度等方面实施特征工程,构建多维评价指标体系,将用户创意的价值高低转化为文本质量分类问题;二是将文本特征与用户评论特征,如用户地位、评论分值等结合,应用浅层机器学习,如支持向量机、bp神经网络和深度学习,如cnn、lstm等构建算法模型进行分类和预测。既有的用户创意发现算法至少存在两方面不足:首先,高价值用户创意的形成与完善不单是创意提出者的个人行为,也是与社区用户和企业社区管理员广泛互动、价值共创的产物,既有算法将创意内容与用户评论视为孤立、静止的对象,忽视了多方互动对用户创意的迭代影响;其次,产品在线社区中,高价值用户创意与其他创意间,用户的创意评论之间都存在依赖关系,既有算法忽略了创意内容-用户关系-创意评论之间的紧密联系,构建的算法模型参数依赖场景、稳健性和适用性不高。乔少杰等提出基于中心性和pagerank的网页综合评分方法,其中记载了利用pagerank算法对网页进行评分。中国专利文献 cn106997383a记载了一种基于pagerank算法的问题推荐方法及系统,该方案基于传统的潜在狄利克雷分配(lda)算法,输出文档-主题分布矩阵θi,主题-词项分布矩阵
3.本发明背景技术中的内容,仅是为了便于理解本发明,并不是证明上述的技术内容以及由其尤其衍生的分析结果属于已经公开的现有技术。即背景技术中的内容,除所引用的文献外,不是现有技术的证明。
技术实现要素:
4.本发明所要解决的技术问题是提供一种识别在线产品社区高价值用户创意的系
统及方法,能够实现在线产品社区高价值用户创意的智能识别和预测,为企业打造用户创意智能生成服务提供重要技术支撑。以解决以潜在狄利克雷分配算法为代表的现有技术方案:(1)忽略创意内容和用户评论的关联关系,(2)未从企业需求视角考察创意价值,导致算法精准度、稳健性和适用性不高的技术问题。
5.为解决上述技术问题,本发明所采用的技术方案是:一种识别在线产品社区高价值用户创意的方法,包括以下步骤:
6.s1、从在线产品社区的创意文本和用户-创意关系提取表征创意和用户属性的8 个特征,包括创意语义熵、创意模态、创意情感倾向、用户等级、用户活跃时长、用户pagerank中心性、用户中介中心性、用户邻近中心性;
7.s2、构建创意节点邻接矩阵;
8.s3、引入图注意力神经网络,构造单个注意力机制,计算融合8个属性特征和邻接矩阵的注意力系数α
ij
;
9.s4、构造多层注意力机制,计算累加的融合8个特征和邻接矩阵的注意力系数α
′
ij
;
10.s5、构造卷积层,输出节点i的卷积层结果
11.s6、通过softmax函数(归一化指数函数)加权值输出节点i对应创意价值类别的概率p
i,n
,得到创意节点i隶属创意价值类别;
12.通过以上步骤,以用户提出的某创意文本为识别对象,输入算法模型参数,获得该创意文本所属创意价值类别及排序结果。
13.优选的方案中,在步骤s1中,从在线产品社区的创意文本和用户-创意关系中采集的文本数据,对文本标题和内容进行预处理,剔除标点符号,仅保留中文字符,将用户互动关系处理为图网络结构数据,构建用户互动关系网络。
14.优选的方案中,在用户-创意关系中,对企业回复的创意评论文本,应用纳入文本情感协变量的结构化主题模型(stm)算法确定创意价值标签。
15.优选的方案中,结构化主题模型算法的步骤为:
16.s01、步骤1:从基于文档情感协变量xd的广义线性模型(glm)中生成文档
–
主题分布先验概率θd;
17.(式中p表示协变量数量,k表示主题数量.γk的先验分布是均值为0且具有共享方差的正态分布,其中服从逆伽玛分布
18.θd~logisticnormal
k-1
(γ
′
x
′d,σ);(式中d表示文档的数量,θd服从对数正态分布,其中γ系数矩阵由p行k-1列的γk组成,协变量xd为p维行向量,每个文档的θd值受协变量xd影响)
19.s02、由基准词分布(m),主题偏差(kt),协变量偏差(kc)及其交互项偏差(ki)生成主题-词项分布先验概率β
d,k,v
;
[0020][0021]
式中m是基准词分布,kt是主题偏差,kc是协变量偏差,ki是交互项偏差;
[0022]
s03、对于文档ωi,逐一生成对应的主题和词语;
[0023]
从z
d,n
~multinomialk(θd),for n=1
…
nd中抽样生成文档
–
主题分布概率θd向量;
[0024]
从w
d,n
~multinomialv(bz
d,n
),for n=1
…
nd,中抽样生成主题-词项分布概率β
d,k,v
向量;
[0025]
输出纳入协变量xd影响的文档-主题分布矩阵θd,主题-词项分布矩阵β
d,k,v
。
[0026]
优选的方案中,创意节点邻接矩阵的节点属性和节点邻接矩阵作为图注意力神经网络的输入参数。
[0027]
优选的方案中,在步骤s6,softmax函数中,对不同类别赋值不同权重。
[0028]
一种识别在线产品社区高价值用户创意的系统,包括预处理模块、提取模块、训练模块、拼合模块、分类模块和控制处理模块;
[0029]
预处理模块,用于处理用户创意文本和用户评论文本,并构建用户互动关系网络,为提取模块参数的输入做准备;
[0030]
提取模块,用于提取并计算表征创意属性和用户属性的8个特征,表征创意语义关联性的节点邻接矩阵,为图注意力神经网络模型训练做输入准备;
[0031]
训练模块,基于图注意力神经网络训练,计算单个和多层注意力机制下的创意节点注意力系数,为池化卷积输出做输入准备;
[0032]
拼合模块,构造池化的卷积层,输出创意节点i的卷积结果;
[0033]
分类模块,通过softmax函数加权输出创意节点i对应创意价值类别的概率p
i,n
,划分创意节点i隶属创意价值的类别;
[0034]
控制处理模块,用于控制处理从用户创意文本、用户评论文本和用户互动关系的预处理、特征提取、模型训练、池化拼合、分类处理和降序输出。
[0035]
优选的方案中,基于图注意力神经网络训练模型参数,包括计算单个和多层注意力机制下的创意节点注意力系数,池化卷积和softmax函数加权输出创意价值隶属类别。
[0036]
一种电子设备,所述电子设备包括:至少一个处理器和至少一个存储器;
[0037]
所述存储器用于存储一个或多个如上述的系统的程序指令;
[0038]
所述处理器,用于运行一个或多个程序指令,用以执行上述的方法。
[0039]
一种计算机可读存储介质,所述计算机可读存储介质中包含一个或多个如上述的系统的程序指令;
[0040]
所述一个或多个程序指令用于执行如上述的方法。
[0041]
本发明提供的一种识别在线产品社区高价值用户创意的方法及系统,通过采用用户创意超图概念,将在线产品社区的高价值用户识别转换为映射创意内容-用户关系
‑ꢀ
创意评论异质网络图的求解问题,通过构建用户创意网络和用户互动网络,有效规避了既有技术方案不考虑创意内容与用户互动的静态分析缺陷;构建了用户创意和用户互动双网络架构,选择的创意节点、边属性和用户节点、社交边属性,最大程度提取了创意内容与用户关系的动态交互特征,显著提升高价值用户创意的识别精准度;引入注意力机制和多注意力层,应用图注意力网络模型,能够更好地学习高价值用户创意的内容属性和用户互动属性特征,摒弃多维网络节点和边特征向量引致的模型过拟合与迭代复杂度,提升了高价值用户创意的识别精度。本发明提出的识别在线产品社区高价值用户创意的方法及系统,以某手机制造企业的产品社区为场景,采集了数据,分别与支持向量机(svm)、随机森林(rf)以及bp神经网络、gcnn图神经网络等算法相比较,识别的准确率分别为:本发明的方法及系统90.3%;图神经网络(gcnn) 76.5%;bp神经网络36.2%;支持向量机(svm)35.8%;随机
森林(rf)35.3%。从以上结果可以看出,本发明的技术方案的算法模型具有准确率最高的特点,与其他四类基准模型相比,具有显著提升。
附图说明
[0042]
下面结合附图和实施例对本发明作进一步说明:
[0043]
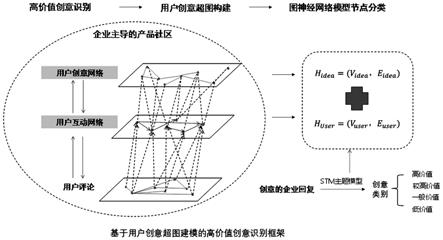
图1为本发明的用户创意超图概念框架示意图。
[0044]
图2为本发明的方法流程图。
[0045]
图3为本发明的系统结构框图。
[0046]
图4为本发明的算法原理图。
[0047]
图中,预处理模块100,提取模块200,训练模块300,拼合模块400,分类模块 500,控制处理模块600。
具体实施方式
[0048]
实施例1:
[0049]
如图1中,本发明的目的在于高效的识别在线产品社区高价值用户创意。
[0050]
图1为本发明提出的用户创意超图概念框架。该框架将在线产品社区的高价值用户识别转化为映射创意内容-用户关系-创意评论的三层异质网络图,进而应用图神经网络模型将高价值用户识别问题转换为创意节点的分类问题。
[0051]
即由用户创意内容节点和用户社交关系节点构成超边的超图(hypergraph)结构。通过构建用户创意网络和用户互动网络,选取表征双网络结构的节点属性和边属性特征,基于图注意力神经网络(graph attention network,gat)模型提出一种识别在线产品社区高价值用户创意的方法和系统,用以解决现有技术方案:(1)忽略创意内容和用户评论的关联关系,(2)未从企业需求视角考察创意价值,导致算法精准度、稳健性和适用性不高的问题。
[0052]
第一方面,本例提供了一种基于图注意力网络(gat)的在线产品社区高价值用户创意识别方法和系统,包括:提出了用户创意超图概念,用于映射创意内容-用户关系-创意评论异质网络图关系;构建用户创意网络,将创意作为节点,提取创意语义熵,即每条创意文本的关键词熵值;创意模态,即每条创意文本的模态类别值;创意情感倾向,即每条创意文本的情感倾向值作为节点属性;两两创意之间的语义关系,即用创意之间的语义关联性测度作为边;构建用户互动网络。将用户作为节点,提取用户等级;用户活跃时长;用户pagerank中心性;用户中介中心性;用户邻近中心性作为节点属性,互有评论的两两用户建立边连接;基于用户创意和用户互动网络,构造图注意力网络模型,对输入的双网络节点特征做线性变换,通过多注意力层的学习,通过softmax函数输出创意的价值类别标签;将创意价值类别标签按照降序输出识别的topn个高价值用户创意。
[0053]
进一步的优选的方案中,本发明以产品社区官方回复评论文本为数据源,应用纳入情感协变量的结构化主题模型(stm)训练回复评论文本。stm算法示例及与传统 lda算法的比较如下:
[0054]
文档语料的形式化表述:
[0055]
对于评论文本ω=(ω1,
…
,ωn)构成的语料d,从含有v个词项的词典中选取n个词
语构成,对于i=1,
…
,n,ωi∈{1,
…
,v};
[0056]
传统的潜在狄利克雷分配(lda)算法示例:
[0057]
输入:语料d,预定义主题数k
[0058]
步骤1:抽样生成文档ωi的主题概率先验分布θi,θi由超参数为α的dirichlet分布θ~dirichlet(α)生成;
[0059]
步骤2:抽样生成主题zi对应的词语先验概率分布由超参数为β的 dirichlet分布生成;
[0060]
步骤3:对于文档ωi,逐一生成对应的主题和词语;
[0061]
3.1从主题的多项式分布θi中抽样生成文档ωi的主题,zi~multinomial(θ);
[0062]
3.2在主题zi:p(ωi|zi,β)下,从词语的多项式分布中抽样生成词语ωi,
[0063]
输出:文档-主题分布矩阵θi,主题-词项分布矩阵
[0064]
而本发明的结构化主题模型(stm)算法如下:
[0065]
输入:语料d,预定义主题数k,创意文本情感协变量xd;
[0066]
步骤001:从基于文档协变量xd的广义线性模型(glm)中生成文档
–
主题分布先验概率θd;
[0067][0068]
式中p表示协变量数量,k表示主题数量.γk的先验分布是均值为0且具有共享方差的正态分布,其中服从逆伽玛分布;
[0069]
θd~logisticnormal
k-1
(γ
′
x
′d,σ);
[0070]
式中d表示文档的数量,θd服从对数正态分布,其中γ系数矩阵由p行k-1列的γk组成,协变量xd为p维行向量,每个文档的θd值受协变量xd影响;
[0071]
步骤002:由基准词分布(m),主题偏差(kt),协变量偏差(kc)及其交互项偏差(ki) 生成主题-词项分布先验概率β
d,k,v
;
[0072][0073]
式中m是基准词分布,kt是主题偏差,kc是协变量偏差,ki是交互项偏差;
[0074]
步骤3:对于文档ωi,逐一生成对应的主题和词语
[0075]
从z
d,n
~multinomialk(θd),forn=1
…
nd中抽样生成文档
–
主题分布概率θd向量
[0076]
从w
d,n
~multinomialv(bz
d,n
),for n=1
…
nd,中抽样生成主题-词项分布概率β
d,k,v
向量
[0077]
输出:纳入协变量xd影响的文档-主题分布矩阵θd,主题-词项分布矩阵β
d,k,v
[0078]
在完成上述模型拟合与参数估算中,需要选定回复评论文本的最优主题数,传统的文本主题数选择,多以困惑度指标(perplexity)为评价依据,困惑度值越低说明模型的泛化效果更佳。较新的研究表明,聚类较好的文本主题,多具有同一主题内语义较为一致,不同主题间语义区隔明显的特点。为此,本专利基于词共现统计方法,提出语义一致性指标衡量主题的收敛质量。对于主题k下概率最高的m个词,该主题的语义一致性指标ck计算公
式如下:
[0079][0080]
其中d(vi)表示词vi在主题k中出现的次数,d(vi,vj)表示vi和vj两个词同时在一个主题中出现的次数。语义一致性指标能够较好地评测不同主题语义的收敛程度且与人的主观判断保持一致。为避免常见词主导主题语义的情况,提出词语在主题中的独有性(exclusivity)指标测度不同主题间语义的区隔程度。对于第v个词项在第k个主题下的独有性指标frex
k,v
的计算公式为:
[0081][0082]
式中ω为权重,ecdf是词项在主题中独有性和频次的分布函数的调和平均。
[0083]
为筛选出具有独特性的词项,权重ω设定为0.7。结合主题的语义一致性和语义独有性指标,确定创意回复评论文本的最优主题数。根据确定的评论语义主题将创意价值划分为高、较高、一般、低四类,作为模型训练数据集表征创意价值的标签。
[0084]
图2为本发明的一种识别在线产品社区高价值用户创意的方法的流程图。该流程图展现的方法步骤包括:
[0085]
s1:预处理。分别对采集自在线产品社区的创意文本和用户-创意关系、用户评论文本进行预处理,剔除文本中的非中文字符、构建创意和用户网络的节点属性文件和边列表文件。
[0086]
s2:特征提取。分别对构建的创意网络和用户网络提取节点属性关键特征,构建创意节点语义关联的邻接矩阵。
[0087]
具体地,将每个创意文本作为网络节点,两两创意之间的语义关联作为边,构建创意邻接矩阵提取表征创意的属性特征,计算每条创意的语义熵值创意模态sent
idea
=∑ikeyword
sent
;
[0088]
提取表征与创意一一对应的每个用户属性特征,如用户等级、用户活跃时长,计算用户pagerank中心性
[0089]
用户中介中心性
[0090]
是除节点i外,任意节点j和节点r最短路径的数量,k
jr
(i)是节点j和
[0091]
r最短路径中经过节点i的数量;
[0092]
用户邻近中心性(k
ij
是节点i和节点j最短路径的数量)。
[0093]
优选的,预处理后的数据集包括8个创意和用户属性数据,记为以及创意邻接矩阵数据,记为a[
i,j
]。
[0094]
s3:模型训练。引入图注意力神经网络(graph attention network,gat)将在线产品社区高价值用户创意识别问题转化为用户创意节点分类问题。首先,构造注意力机制,线性变换6个节点特征线性变换权重参数ω,基于邻接矩阵a[
i,j
]计算创意邻居节点j对节点i的注意力系数α
ij
,公式如下:
[0095][0096]
公式中的leackyrelu是激活函数,ω是线性变换权重参数,是线性变换的6 个节点特征)
[0097]
进一步地,得到节点特征的注意力机制变换结果公式如下:
[0098][0099]
(公式中的α
ij
是邻居节点j对节点i的注意力系数,ω是线性变换权重参数,是线性变换的6个节点特征)
[0100]
s4:步骤s2构造的是单个注意力机制,为更好学习邻接节点ni对节点i的重要性,进一步构造m个注意力层,计算第m注意力层的线性变换注意力系数之后将m层结果累加,输出得到m个注意力层的注意力系数α
′
ij
,公式如下:
[0101][0102]
公式中的是第m注意力层的注意力系数,ωm是第m注意力层的线性变换权重参数,是线性变换的6个节点特征。
[0103]
s4:卷积拼合。构造卷积层,对于卷积核为ωc,输入索引为(i,j),偏置为biasc,指示函数是ζ(i,j),输出索引是(p,q),输出节点i的卷积层结果公式如下:
[0104][0105]
公式中的relu是激活函数,ωc是卷积核,(i,j)是输入索引,biasc是偏置,ζ(i,j) 是指示函数,(p,q)是输出索引。
[0106]
在本发明的一个实施例中,本专利申请针对在线产品社区用户创意及用户互动关系的复杂特点,8个特征值输入时,设置8个多头注意力层,每个注意力层8个输出到有64个节点的卷积层,之后完成卷积层池化输出。高价值用户创意识别的图注意力网络模型算法原理如图4所示。
[0107]
s5:对设置的创意价值四个类别(高价值、较高价值、一般价值、低价值),设 n为其
中一个类别,对卷积层输出而言,使用考虑类别权重的softmax函数加权值输出节点i对应创意价值类别的概率p
i,n
,公式如下:
[0108][0109]
公式中的是类别n的卷积层输出。
[0110]
由此得到每个创意的价值类别
[0111]
s6:将步骤s5中输出的类别按照高价值、较高价值、一般价值和低价值降序输出结果。
[0112]
具体地,以用户提出的某创意文本为识别对象,输入算法模型参数,将获得的该创意文本所属创意价值类别及排序结果。
[0113]
在本发明的一个实施例中,以在线产品社区中用户提交的创意为识别对象,以步骤s1-s6所述算法训练的模型为基础,将用户创意文本属性和用户属性特征输入该模型,输出得到创意文本所属价值类别;输入既可以针对单个用户创意,也可以针对批量用户创意,根据降序排列的topn(n可以根据需求自定义)输出结果即为识别的在线产品社区高价值用户创意。
[0114]
实施例2:
[0115]
如图3中所示,本发明还提供一种基于图注意力网络(gat)的在线产品社区高价值用户创意识别以及预测系统,包括:预处理模块,用于处理原始数据集中的创意文本和用户评论文本;提取模块,用于提取构建用户创意网络和用户互动网络所需的节点属性特征和边属性特征;训练模块,用于分别训练用户创意网络和用户互动网络节点和边属性特征,利用构造的注意力机制和多注意力层,获得节点i相对邻接节点 j对应的第m个注意力系数线性权重参数拼合模块,通过构建卷积层,设置该层卷积核为wc,输出1*n个类别;分类模块,用于对上述线性拼合后的创意价值类别结果进行sofmax函数转换,获得节点i隶属某个创意价值类别n的概率p
i,n
;控制处理模块,用于控制处理创意内容网络和用户互动网络的节点和边属性的数据预处理、转换、图注意力网络模型训练、线性拼合、分类处理和降序输出等。
[0116]
进一步优选的方案中,预处理模块在分别对用户创意和用户评论文本中的标题和内容进行预处理时,剔除标点符号,仅保留中文字符。
[0117]
进一步优选的方案中,提取模块在构建用户创意网络时,提取创意语义熵、创意模态、创意情感倾向作为节点属性值,创意语义关联性,优选的,关联系数大于0.5,作为二值边属性;在构建用户互动网络时,提取用户等级、用户活跃时长、用户 pagerank中心性、用户中介中心性、用户邻近中心性作为节点属性值,用户关注关系作为二值边属性。
[0118]
进一步优选的方案中,拼合模块,即拼合与分类模块对训练模块基于注意力机制的权重系数进行处理时,使用考虑类别权重的softmax函数加权值作为结果输出排序和预测的依据。
[0119]
实施例3:
[0120]
本发明还提供一种电子设备,包括:至少一个处理器和至少一个存储器;所述存储器用于存储一个或多个如上述实施例2的系统的程序指令;
[0121]
所述处理器,用于运行一个或多个程序指令,用以执行上述实施例1的方法。
[0122]
实施例4:
[0123]
本发明实施例还提供一种计算机可读存储介质,可读存储介质包括网络服务器存储介质、本地电脑硬盘、移动u盘或光盘等。计算机可读存储介质中包含一个或多个如上述实施例2的系统的程序指令;
[0124]
所述一个或多个程序指令用于执行如上述实施例1的方法。
[0125]
上述的实施例仅为本发明的优选技术方案,而不应视为对于本发明的限制,本技术中的实施例及实施例中的特征在不冲突的情况下,可以相互任意组合。本发明的保护范围应以权利要求记载的技术方案,包括权利要求记载的技术方案中技术特征的等同替换方案为保护范围。即在此范围内的等同替换改进,也在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
