1.本发明涉及图像处理、计算机视觉及深度学习领域,特别涉及一种基于伪标签的人脸图像高光去除方法。
背景技术:
2.人脸上形成的镜面反射会产生面部高光,在大多数情况下,人脸高光会显著影响图像质量,降低人脸的美感。在影视制作,虚拟现实,人脸重光照等领域中,人脸图像去高光至关重要现有的人脸图像去高光算法主要包括以下几种:
3.1)基于先验假设的数值优化方法。该类算法依赖于对人脸高光的物理特性做出假设,并据此手动设计先验假设和约束。通过最小化优化函数来达到人脸高光分量和非高光分量分离的目的。
4.2)基于图像色度空间的图像处理类方法。该类方法往往通过对图像色品空间进行分析,在色品空间中将不同的像素划分为高光像素和非高光像素,并通过图像处理计算使高光像素转化为非高光像素。
5.3)基于数据驱动的深度学习类方法。该类算法借助于深度学习技术,将带高光图像作为模型输入,无高光图像作为模型输出。通过大规模的数据使模型学习到去除人脸高光的能力。
6.随着深度学习技术的不断发展,基于数据驱动的深度学习类方法成为人脸去高光的主流方向。因为很难获得带标签的人脸高光数据集,所以常常需要通过渲染引擎制作合成数据集。然而合成人脸图像和真实的人脸图像依然存在差异,将利用合成人脸训练的去高光神经网络作用在真实人脸去高光上,会产生色彩失真,图像过渡平滑等问题。
技术实现要素:
7.为了克服深度学习类人脸去高光算法的缺陷,本发明提出一种基于伪标签的人脸图像高光去除方法,具体包括以下步骤:
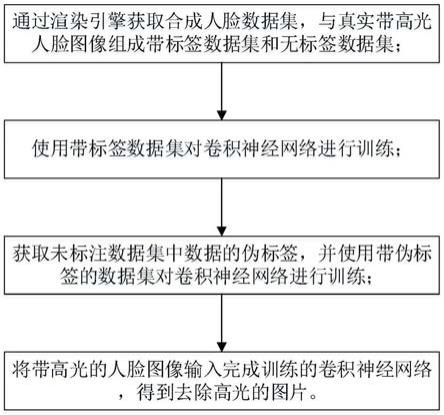
8.s1、通过渲染引擎获取合成人脸数据集,与真实带高光人脸图像组成带标签数据集和无标签数据集;
9.s2、使用带标签数据集对卷积神经网络进行训练;
10.s3、获取未标注数据集中数据的伪标签,并使用带伪标签的数据集对卷积神经网络进行训练;
11.s4、将带高光的人脸图像输入完成训练的卷积神经网络,得到去除高光的图片;
12.其中,对卷积神经网络进行训练时,将带标签数据集中数据与其标签之间的损失和未标注数据集中数据与其伪标签之间的损失之和作为卷积神经网络的损失函数,对卷积神经网络进行反向传播以训练卷积神经网络。
13.进一步的,带标签数据集和无标签数据集的获取方法包括:
14.选取若干张人脸3d模型图像加载入基于物理的渲染姻亲,并选择若干中hdr环境
光照,对人脸模型进行渲染;根据phong光照模型,分别渲染得到人脸的漫反射部分d和镜面反射部分s,则渲染得到的带高光的人脸图像表示为i=d s,将得到的带高光的人脸图像和其原图组成的带高光/去高光的合成人脸图像对,由带高光/去高光的合成人脸图像对构成带标签数据集;
15.从人脸数据集中选择若干张带高光的人脸图片作为无标签数据集。
16.进一步的,卷积神经网络包括编码器和解码器,将输入卷积神经网络的图像作为编码器的输入,编码器包括级联的5个卷积模块,每个卷积模块的输出进行最大池化后再输入下一级卷积模块;
17.将编码器的输出作为解码器的输入,解码器包括4个注意力模块、4个卷积模块、4个反卷积模块以及一个卷积层第一个反卷积模块以解码器的输入作为输入进行反卷积操作得到的输出为d1,第一个注意力模块将编码器中倒数第二个卷积模块的输出和d1作为输入进行融合得到的输出记为x1;
18.将d1和x1拼接在一起输入第一个卷积模块进行卷积并将第一个卷积模块的输出作为第二个反卷积模块的输入进行反卷积操作得到输出结果d2,第二个注意力模块根据d2以及编码器倒数第三个卷积模块的输出作为输入进行融合得到的输出记为x2;
19.将d2和x2拼接在一起输入拼接在一起输入第二个卷积模块进行卷积并将第二个卷积模块的输出作为第三个反卷积模块的输入进行反卷积操作得到输出结果d3,第三个注意力模块根据d3以及编码器倒数第四个卷积模块的输出作为输入进行融合得到的输出记为x3;
20.将d3和x3拼接在一起输入拼接在一起输入第三个卷积模块进行卷积并将第三个卷积模块的输出作为第四个反卷积模块的输入进行反卷积操作得到输出结果d4,第四个注意力模块根据d4以及编码器倒数第五个卷积模块的输出作为输入进行融合得到的输出记为x4;
21.将d4和x4拼接在一起输入拼接在一起输入第四个卷积模块进行卷积并将第三个卷积模块的输出作为编码器的卷积层的输入进行卷积,得到解码器的输出结果。
22.进一步的,卷积模块有两个级联的卷积层构成,每个卷积层依次进行卷积核个数为图像通道数、卷积窗口大小为3
×
3、步长为1
×
1的卷积操作,归一化操作以及使用relu函数进行激活;
23.注意力模块将来自解码器的输入作为主要部分、将来自编码器的输入作为次要部分,注意力模块对主要部分以及次要部分进行融合,主要部分以及次要部分分别依次使用卷积窗口大小为3
×
3、步长为1
×
1的卷积操以及归一化操作得到主要部分x以及次要部分s,并将主要部分x以及次要部分s相加后依次进行卷积窗口大小为3
×
3、步长为1
×
1的卷积操作、归一化操作以及使用sigmoid函数进行激活得到融合结果xs,将融合结果xs与主要部分x相乘作为注意力模块的输出;
24.反卷积模块包括上采样层和卷积层,上采样层对输入的图像进行上采样,将图片上采样为输入该模块图像的两倍大后,卷积层依次进行卷积核个数为输出通道数、卷积窗口大小为3
×
3、步长为1
×
1的卷积操、归一化操作以及使用relu函数进行激活。
25.进一步的,编码器中进行最大池化的卷积核大小为2、步长为2,编码器五个卷积模块的卷积核依次为64、128、256、512、1024;解码器中注意力模块的卷积核数目和反卷积模
块相同,4个反卷积模块的卷积核数目分别为512、256、128、64,解码器中卷积层的卷积核数目为3、卷积窗口大小为1
×
1、步长为1
×
1。
26.进一步的,使用伪标签的方法,提升卷积神经网络的泛化能力包括以下步骤:
27.s31、对于无标签数据集,通过高斯过程产生伪标签;
28.s32、根据产生的伪标签,计算无标签数据集的误差;
29.s33、根据无标签数据集的误差以及带标签数据集的误差计算卷积神经网络的损失函数,并通过反向传播对卷积神经网络进行训练,卷积神经网络的损失函数表示为:
30.l
total
=l
sup
λ
unsup
l
unsup
;
31.其中,l
total
为卷积神经网络的总损失;l
sup
为带标签数据集部分的损失;l
unsup
为未标注数据集部分的损失;λ
unsup
为未标注数据集部分损失的权重。
32.进一步的,对于无标签数据集,通过高斯过程产生伪标签的过程包括以下步骤:
33.在第一次使用带标签数据集时,将编码器中最后一个卷积模块的得到的特征向量保存入矩阵
34.对进行稀疏编码,学习得到带标签数据集特征向量的字典f;
35.将无标签数据集送入神经网络时,最后一个卷积块得到对应的特征向量并将特征向量投影到学习得到的特征向量空间f;
36.在已知带标签数据集和带标签数据集特征向量的情况下,将未标记数据集特征向量的分布等价于高斯分布,并将等价的高斯分布中的均值作为未标记数据集特征向量的伪标签。
37.进一步的,将未标记数据集特征向量的分布等价于高斯分布,等价的高斯分布的均值表示为:
[0038][0039]
等价的高斯分布的方差表示为:
[0040][0041]
其中,k(x,y)为核函数,表示为《x,y》表示向量x与向量y的内积,|x|表示向量x的模长;的值为1;i为单位矩阵。
[0042]
进一步的,未标注数据集的损失函数表示为:
[0043][0044]
其中,为编码器最后一个卷积模块输出的特征向量;为通过高斯过程得到的伪标签,其值为高斯分布的均值|| ||2为l2范数;λ1为稀疏系数;α为稀疏向量。
[0045]
进一步的,带标签数据集部分的损失l
sup
表示为:
[0046]
l
sup
=l
pixel
l
perception
;
[0047]
l
pixel
=||y
pred-y||1;
[0048][0049]
其中,y
pred
为神经网络的预测结果;y为真实标签,||
·
||1为图像之间的l1距离;λ2为权重;φ
vgg
表示vgg16网络;φ
vgg
(y
pred
)为神经网络的预测结果通过vgg16生成的特征值,φ
vgg
(y)为真实标签通过vgg16生成的特征值;为图像之间l2距离的平方。
[0050]
本发明提出的基于伪标签的人脸高光去除方法,利用高斯过程混合模型,制造了未标注人脸图片的“伪标签”,通过伪标签加强了神经网络在真实人脸图像上的泛化能力,提升对真实人脸高光去除的效果。
附图说明
[0051]
图1是本发明的基于伪标签的人脸图像去高光算法一实例的的简略流程图;
[0052]
图2是本发明去高光网络的结构示意图;
[0053]
图3是本发明去高光网络的训练示意图;
[0054]
图4是训练过后的神经网络在celeba数据集上的测试结果(第一行为原图,第二行为第一行图片对应的去高光结果)。
具体实施方式
[0055]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
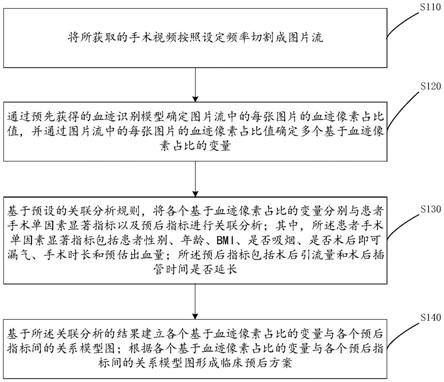
[0056]
本发明提出一种基于伪标签的人脸图像高光去除方法,具体包括以下步骤:
[0057]
s1、通过渲染引擎获取合成人脸数据集,与真实带高光人脸图像组成带标签数据集和无标签数据集;
[0058]
s2、使用带标签数据集对卷积神经网络进行训练;
[0059]
s3、获取未标注数据集中数据的伪标签,并使用带伪标签的数据集对卷积神经网络进行训练;
[0060]
s4、将带高光的人脸图像输入完成训练的卷积神经网络,得到去除高光的图片。
[0061]
在本实施例中,一种基于伪标签的人脸图像高光去除方法的流程如图1~4,具体包括以下步骤:
[0062]
s10:获取使用渲染引擎渲染地合成人脸数据集(同时包括包含镜面反射的带高光人脸和不带高光地漫反射人脸)与真实世界中的带高光图像,组成带标签数据集和无标签数据集,以训练神经网络。
[0063]
s101:选取若干的人脸3d模型(obj文件)加载入基于物理的渲染引擎,选择若干hdr环境光照,对人脸模型进行渲染。根据phong光照模型,分别渲染得到人脸的漫反射部分d,镜面反射部分s,并根据公式:
[0064]
i=d s
[0065]
得到图像i。将s视为人脸高光,i为带高光的人脸图像,d为去高光后的人脸图像。
重复上述操作,生成大批量的带高光/去高光的合成人脸图像对,作为带标签数据集。
[0066]
s102:从真实人脸数据集中手动挑选出若干张带高光的人脸图片,将这些图片作为无标签数据集。
[0067]
s20:使用带标签数据集首先卷积神经网络。具体包括:
[0068]
s201:卷积神经网络的结构。
[0069]
卷积神经网络具体可分为编码器(encoding)和解码器(decoding)两个部分,具体包括:
[0070]
1)编码器:编码器包括5个连续的卷积模块conv_block。第一个卷积模块将图像的作为输入,后四个卷积模块将前一个卷积层的输出作为输入,前4个卷积模块结束后需要进行最大池化,最大池化操作的卷积核大小为2、步长为2,五个卷积模块的卷积核数目分别是[64,128,256,512,1024]。
[0071]
2)解码器:解码器包括4个注意力模块,4个卷积模块,4个反卷积模块和一个卷积层组成。解码器的第一个反卷积模块接受编码器的最后一个编码器的输出作为输入,得到输出d1,第一个注意力模块接受d1和编码器倒数第二个卷积模块的输出e4作为输入,得到输出x1,将d1与x1连接在一起,送入第一个卷积模块。将卷积模块的输出送入第二个反卷积模块,得到输出d2。第二个注意力模块接受d2和编码器倒数第三个卷积模块的输出e3作为输入,得到输出x2,将d2和连接在一起,送入第二个卷积模块。以此类推,最后将最后一个卷积模块的输出d4送入卷积层。4个反卷积模块的卷积核数目分别为[512,256,128,64]。注意力模块的卷积核数目和反卷积模块相同。最后的卷积层卷积核数目为3,卷积窗口大小为1*1,步长为1*1。卷积神经网络的整体结构如图2所示。解码器中的卷积模块结构与编码器中的卷积模块结构一致,解码器的编码器的卷积核数量为[512,256,128,64,3],本发明中卷积核顺序等均按照从输入到输出的次数,越靠近输入端越靠前;其他卷积参数与编码器一致,此处不再赘述。
[0072]
卷积神经网络中的卷积模块、注意力模块、反卷积模块、卷积层,具体包括
[0073]
1)卷积模块conv_block:卷积模块包括两个卷积层组成。两个卷积层除输入不同,其余完全相同。卷积层卷积核个数为输出通道数ch,卷积窗口大小为3*3,步长为1*1,之后进行归一化,激活函数为relu函数。编码器和解码器中采用的卷积结构相同,仅卷积层的卷积核个数不同,其中编码器中5个卷积模块的卷积核数目依次为64、128、256、512、1024,解码器中4个卷积模块的卷积核数目依次为512、256、128、64。
[0074]
2)注意力模块attu_block:注意力模块将来自解码器的输入作为主要部分、将来自编码器的输入作为次要部分一起作为注意力模块的输入,对两个部分分别进行卷积操作,卷积操作的卷积窗口大小为3*3、步长为1*1,然后进行归一化,得到主要部分x和次要分布s;将x与s相加得到xs,之后对xs进行卷积操作,卷积操作的卷积窗口大小为3*3、步长为1*1,然后进行归一化,激活函数为sigmoid;将x与xs相乘,得到注意力模块的输出。
[0075]
3)反卷积模块up_block:反卷积模块首先将输入该模块的图像上采样为两倍原图像的两倍。然后使用卷积层进行卷积,卷积层卷积核个数为输出通道数ch,卷积窗口大小为3*3,步长为1*1,之后进行归一化,激活函数为relu函数;4个反卷积模块的卷积核数目分别为512、256、128、64。
[0076]
4)卷积层:解码器最后一级卷积模块的输出输入一个卷积层进行卷积,该卷积层
的卷积核数目为输入图像的通道数,卷积窗口大小为3
×
3、步长为1
×
1。
[0077]
s202:对于带标签数据集(合成图像),计算预测结果与标签之间的误差。标签和预测结果与之间的像素误差表示为:
[0078]
l
pixel
=||y
pred-y||1;
[0079]
同时,计算标签和预测结果之间的感知误差,表示为:
[0080][0081]
其中,y
pred
为神经网络的预测结果;y为真实标签,||
·
||1为图像之间的l1距离;λ2为权重,本领域技术人员可根据实际需要进行调节;φ
vgg
表示vgg16网络;φ
vgg
(y
pred
)为神经网络的预测结果通过vgg16生成的特征值,φ
vgg
(y)为真实标签通过vgg16生成的特征值;为图像之间l2距离的平方。
[0082]
以上两部分为神经网络有监督的损失函数:
[0083]
l
sup
=l
pixel
l
perception
。
[0084]
s30:使用伪标签的方法,提升神经网络的泛化能力。具体包括:
[0085]
s301:对于无标签数据集(真实图像),通过高斯过程产生伪标签,具体地:
[0086]
在第一次使用带标签数据集时,将编码器中最后一个卷积模块的得到的特征向量保存入矩阵即其中,n
l
代表标注图像的数量,i代表图像的标号。假设为一个1
×
m的特征向量,则是一个n
×
m的矩阵。
[0087]
由稀疏表示(sparse representation)理论,样本集x={x1,...,xn}可被一组基向量φ={φ1,...,φi}的线性表出,公式为:
[0088][0089]
由此,若通过样本集x={x1,...,xn}学习一组超完备的基向量d={φ1,...,φi},即可将其进行分解。
[0090]
x=dα;
[0091]
x为样本集,d为基向量组(字典),α为系数向量,这种分解方式即为稀疏编码。稀疏编码的目标是使分解结果重组后尽量接近原样本集,且α尽量稀疏,即:
[0092]
min|α
|
0 s.t.dα=x
[0093]
优选地,对进行稀疏编码,可学习得到带标签数据集特征向量的字典f:
[0094][0095]
其中,α
l
为带标签数据集对应的系数向量。
[0096]
同时,将无标签数据集送入神经网络时,最后一个卷积块也可得到对应的特征向量本方法假设无标签数据集的特征向量与带标签数据集的特征向量属于同一向量空间,因此,和可共用一本字典f。由此,当使用无标签数据集进行训练时,可将编码器中最后卷积模块的得到的特征向量投影到学习得到的的特征向量空间f当中。优选
地,可使用高斯过程(gaussian process,gp)对标注数据和未标注数据进行联合建模。
[0097]
高斯过程是一个函数,其的核心是使用无限多维变量高斯分布来对函数进行建模。一个高斯过程可以被均值函数(mean function)和协方差函数(covariance function)所确定。
[0098][0099][0100]
v与v’是随机变量,f是高斯过程,e为期望,m(v)是均值函数,k为核函数(协方差)。高斯过程可被定义为:
[0101][0102]
对一组随机变量v,表示为[v1,v2,...,vn]来说,其高斯过程的结果都符合多维高斯分布,即:
[0103][0104]
由此,可以将带标签数据集的特征向量和无标签数据集的特征向量的联合分布作为多元高斯建模:
[0105][0106]
其中,z
l
为带标签数据集的特征向量的高斯过程,zu为无标签数据集的特征向量的高斯过程,μ
l
为带标签数据集的特征向量的均值,μu为无标签数据集的特征向量的均值;借助高斯过程,在已知带标签数据集和带标签数据集特征向量的情况下,可计算未标记数据集特征向量的分布。对最后一个特征向量空间使用高斯过程(gaussian process,gp)建模。未标注样本特征向量的分布等价于高斯分布:
[0107][0108]
为标注数据,为多元变量的高斯分布,其中为高斯过程的均值:
[0109][0110]
为高斯过程的方差:
[0111][0112]
设为1。k(x,y)为核函数,定义为:
[0113][0114]
其中,《x,y》表示向量x与向量y的内积,|x|表示向量x的模长;的值为1;i为单位矩阵
[0115]
优选地,将高斯过程的均值作为伪标签特征向量
[0116]
s302:计算未标注数据的误差,具体地:
[0117]
对于未标注数据,采用公式:
[0118][0119]
计算编码器得到的空间向量和伪标签空间向量之间的误差。其中为最后一个卷积块预测特征向量,为通过高斯过程得到的伪标签,第j个卷积层对应高斯过程的方差。用来式经过稀疏表示后,分解结果尽可能接近带标签数据集的特征向量且稀疏向量α尽量稀疏,λ1为稀疏系数,该系数用户可以自行调节。
[0120]
s303:综合带标签数据集的和无标签数据集的损失函数,进一步训练网络。
[0121]
综合标注数据和未标注数据的损失函数,本发明提出的损失函数为:
[0122]
l
total
=l
sup
λ
unsup
l
unsup
;
[0123]
其中,λ
unsup
为未标注数据集部分损失的权重,该参数可以用户自行可调。
[0124]
s40:输入带高光的人脸图像进训练完成的卷积神经网路,得到去高光结果。
[0125]
在本发明实例中,合成及训练的流程图如图1所示。本发明基于人脸obj模型和hdr环境光照,通过给定镜面反射分量,漫反射分量和其组合,使用渲染引擎渲染得到合成人脸数据集;将给定光照参数的合成人脸数据集作为带标签数据集,同时收集带高光的真实人脸作为无标签数据集,将两种数据集输入神经网络模型,通过合成人脸的数据提取真实人脸的“伪标签”。
[0126]
在训练标注数据时,提取已标注图像在最后一层的特征向量,以提取的特征向量为基础,通过稀疏编码的方式,学习一个用来描述标注数据特征向量的字典,并用字典对特征向量进行编码成稀疏系数。输入未标注图像时,利用未标注图像的稀疏表示和未标注图像在最后一层的特征向量,计算高斯过程,并将高斯过程的均值作为未标注图像的“伪标签”。神经网络模型通过同时减小合成图像与标签,真实图像和“伪标签”的距离,来训练网络的去高光能力。训练结束以后可以得到神经网络ψ。将ψ应用于任意输入的人脸的图像,即可得到去高光后的结果。
[0127]
1)训练数据合成
[0128]
取任意3d人脸模型(可以使用人脸三维建模算法自动生成),模型包含性别,宽窄,胖瘦等不同类别。将模型放入基于物理的渲染器(如mitsuba)当中,选取不同的hdr环境光照,对这些模型进行渲染。通过对渲染器的光照模型的参数进行设置,得到人脸的镜面反射分量s和漫反射分量d,使用图像加法将s与d相加,得到带高光的人脸图像i。使用d和i构成数据集,d作为i的标签。重复此过程,得到充足的带标签数据集。
[0129]
2)神经网络训练
[0130]
除带标签数据集外,选取若干带高光的真实人脸(手动选取),作为无标签数据集,无论是标注数据还是未标注数据,可将图像作为漫反射图像与镜面反射的结合。
[0131]
i=d s;
[0132]
利用如图2所示的神经网络ψ,希望通过输出带高光图像x,得到去高光的结果
[0133]
[0134]
按照图3所示的网络训练结构训练网络。网络训练分为有监督和无监督两部分,有监督部分包括:
[0135]
对于带标签数据集(合成图像),采用
[0136]
l
pixel
=||y
pred-y||1;
[0137]
计算标签和预测结果与之间的像素误差,y
pred
为神经网络的预测结果,y为真实标签,||
•
||1为图像之间的l1距离。
[0138]
同时,采用:
[0139][0140]
计算标签和预测结果之间的感知误差。
[0141]
有监督的损失包括:
[0142]
l
sup
=l
pixel
l
perception
;
[0143]
无监督部分包括:
[0144]
对于未标注数据,采用:
[0145][0146]
计算编码器得到的空间向量和伪标签空间向量之间的误差。
[0147]
本发明提出的神经网络的损失函数为:
[0148]
l
total
=l
sup
λ
unsup
l
unsup
;
[0149]
神经网络的优化目标即为此损失函数。神经网络整体的训练过程如图3所示。
[0150]
部分训练配置如下所示:epoch为1000,batch size为4,使用优化器为adam。本发明所述的方法经过测试:实验平台为pc,gpu为nvidia geforce gtx 1080ti,显存为12g。软件配置包括:ubuntu18.04系统,cuda11.3,python3.8.0,pytorch框架。经测试,本发明提出的方法能有效去除高光。
[0151]
3)去高光网络应用
[0152]
将带高光的人脸图像输入训练好的神经网络ψ,可得到去高光后的人脸,如图4所示,图4中第一行为带高光的人脸图像,第二行为通过本发明去掉高光之后的图像,可以看出本发明可以有效去除高光的同时保留图像的大部分细节。
[0153]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。