1.本发明涉及油气开采技术领域,尤其是一种基于误分类代价的钻井早期溢流智能监测方法。
背景技术:
2.作为井控安全的第一道屏障,早期溢流监测技术应用与发展对预防井喷具有重要理论及实践意义。随着机器学习技术的高速发展,根据溢流发生时井口各参数响应时间,优选特征参数结合智能算法实现快速发现溢流,是早期溢流监测技术发展的趋势。目前众多学者通过选取不同的特征参数搭配各类机器学习算法,训练出多种智能模型应用于早期溢流监测中。
3.可将早期溢流监测视为一个二元分类的问题,我们将发生溢流的样本称为正类样本,未发生溢流的样本称为负类样本。在现实中,我们用于训练模型的数据集中,负类样本数量远大于正类样本,这是显而易见的。因此,早期溢流监测属于典型的不平衡小样本数据集二元分类问题。传统的机器学习是在特定的、拥有大量数据的数据集中,假定各类样本数目是均衡的,以误分率最小或预测准确率最高作为优化目标,学习出一个分类模型,使得模型对于测试数据集上的数据的分类准确率最高。因此,传统的机器学习算法应用于早期溢流监测领域中存在以下问题:1)需要大量的数据才能够保障传统的机器学习算法获得一个高性能的模型,而在现实中难以提供足够的正类样本数据,尤其是在区块的早期开发中;2)不平衡样本会导致训练模型侧重样本数目较多的类别,而“轻视”样本数目较少类别,模型在测试数据上的泛化能力受到极大的限制。针对不平衡的小样本数据集分类问题,已有很多学者提出了不同的解决方案。现有的方法可以分为采样方法、集成学习方法及代价敏感学习方法。采样方法包括欠采样(liu,wu,and zhou 2009;zheng et al.2021;)和过采样(chawla et al.2002;barua et al.2014;li and xiong 2020)。欠采样方法通过删除负类样本实现正负类样本的平衡,但可能会将一些重要的样本从多数类中删除。过采样方法多次复制少数样本,容易造成模型过拟合;集成学习方法(seiffert et al.2010;alam et al.2018;fang et al.2019;niu andzhang 2020)通常采用多数投票,但可能会因为“不稳定样本”的存在而导致结果有偏差。
技术实现要素:
4.本发明的目的是针对传统的机器学习算法在早期溢流监测领域中难以克服数据量不足带来的分类精度低、泛化能力差的问题,提供一种基于误分类代价的钻井早期溢流智能监测方法。
5.本发明提供的基于误分类代价的钻井早期溢流智能监测方法,选择选择立管压力差、总池体积差、进出口流量差、进出口钻井液密度差、进出口钻井液温度差、进出口钻井液电导率、钻时这7个参数作为溢流预警的特征参数,以误分类代价最低为模型的优化目标,将代价敏感引入到早期溢流监测中,构建基于代价敏感的早期溢流监测模型,用于监测早
期溢流。该模型由依次进行的特征转换模块、代价敏感数据集构建模块、集成学习模块这三个模块构成。其中,所述特征转换模块,用于将输入数据集进行归一化处理及转换原始的特征空间;所述代价敏感数据集构建模块,用于构建包含代价信息的训练数据集;所述集成学习模块,用于集成多个弱分类器以得到强分类器。
6.本发明的钻井早期溢流智能监测方法,步骤如下:
7.s1、选择立管压力差、总池体积差、进出口流量差、进出口钻井液密度差、进出口钻井液温度差、进出口钻井液电导率、钻时这7个参数作为溢流预警的特征参数。
8.s2、建立基于代价敏感的早期溢流监测模型,其中,
9.所述特征转换模块,将各特征参数下一时刻相对于上一时刻的累积变化量作为输入参数输入到特征转换模块进行预处理,获得归一化及特征降维处理后的数据集。
10.所述代价敏感数据集构建模块,将预处理后的数据集送入代价敏感数据集构建模块中,正类样本得到扩增,扩增后的正类样本与负类样本构成代价敏感的训练集。
11.所述集成学习模块,用于集成多个弱分类器以得到强分类器。
12.s3、以某区块真实的钻井数据对基于代价敏感的早期溢流监测模型进行训练及测试。该步骤中使用误分类总代价、准确率、召回率、精确率、f-measure及auc这六个指标评估基于代价敏感的早期溢流监测模型性能。
13.上述方法中,所述特征转换模块,对原始数据进行线性变换,转换函数如下:
[0014][0015]
式中,max和min分别为原始数据的最大值和最小值,一个原始值x通过min-max标准化映射成区间[0,1]中的值x’。
[0016]
采用kpca算法转换特征,通过非线性映射φ,将低维输入空间每一个x=(x1,x2,
…
,x
p
)(xi∈rn,i=1,2,
…
,p)中不可分的数据映射到高维特征空间y,即:
[0017][0018]
式中,rn—原始低维空间,y—映射后的高维空间;φ是一个非线性映射,φ将x中所有样本都映射到特征空间y中,得到一个新矩阵φ(x)。
[0019]
在高维特征空间中进行数据处理,使输入空间中不可分的数据在高维特征空间中变得可分,再在这个更高的维度空间中利用特征的协方差矩阵判断变量间的方差一致性,寻找出变量之间的最佳的线性组合,来代替特征,从而达到降维的目的。
[0020]
kpca算法中,采用的多项式核函数如下:
[0021]
k(x,y)=(ax
t
y c)dꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0022]
式中,d—多项式函数的最高此项次数,a—用来设置核函数中的gamma参数设置,c—系数。
[0023]
所述代价敏感数据集构建模块包括以下操作:
[0024]
(1)代价敏感采用代价矩阵表示分类器错分时需要付出的代价,c0为正类样本,c1为负类样本,c(i,j)表示将i错分为j要付出的代价;
[0025]
(2)通过代价矩阵获取代价信息后,根据代价嵌入过程的不同,将代价敏感学习分为三类方法:数据前处理方法、直接的代价敏感学习方法与结果后处理方法;
[0026]
(3)通过扩增数据集中正类样本的数量,改变数据集不平衡比,将代价信息嵌入到数据集中。扩增正类样本数量采用gan模型,具体方法如下:
[0027]
gan模型由生成器g与判别器d构成;gan模型的目标函数定义为:
[0028][0029]
式中,e—数学期望;logd(x)—判别器d的损失;z—随机输入;g(z)—新生成的样本;p
data(x)
—真实样本的分布;p
z(z)
—生成样本的分布。
[0030]
在每一轮的训练中,g随机从噪声分布pz(z)中采集m个向量作为输入,生成m个假数据g(zi)(i=1,2
…
m),其概率分布为pg;d接受g生成的m个假数据作为输入的同时,随机在真实数据中选取m个样本作为输入,真实数据的概率分布为p
data
;d通过pg与p
data
之间的差异判断输入数据是来自真实数据还是生成器,并输出d认定输入是真实分布的概率,并将输出反馈给g,用于指导g的训练;e
x~pdata(x)
[logd(x)]代表判别器对真实样本判断结果的期望,e
z~pz(z)
[log(1-d(g(z)))]代表判别器对虚假样本判断结果的期望;经过多轮对抗训练,直至,d对真实样本判断结果d(x)为1,logd(x)为0,即e
x~pdata(x)
[logd(x)]越大越好;对虚假样本判断结果d(g(z))为0,1-d(g(z))为1,log(1-d(g(z)))为0,即e
z~pz(z)
[log(1-d(g(z)))]越大越好;最终d无法判别输入数据是来自真实数据x还是生成数据g(zi)(i=1,2
…
m),即d每次的输出概率值都为1/2,此时模型达到最优。
[0031]
所述集成学习模块中,采用stacking方法首先根据原始训练集训练出若干个基分类器后,再将多个基分类器的预测结果作为新的训练集,来训练出一个新的分类器,作为最终分类器。
[0032]
与现有技术相比,本发明的有益之处在于:
[0033]
本发明将代价敏感学习引入到早期溢流监测中,选择了立管压力、总池体积、进出口流量、进出口钻井液密度差等7个参数作为特征,以误分类代价最低为模型的优化目标,构建了一种全新的智能模型用于早期溢流监测。该模型在各种规模的数据集上均有极好的表现,由此可以证明我们的模型可靠、分类性能强、泛化能力高,能够为现场施工提供指导。本发明的方法避免了传统机器学习在早期溢流监测中存在的难以克服数据量不足带来的精度低、泛化能力差的问题。
[0034]
本发明的其它优点、目标和特征将部分通过下面的说明体现,部分还将通过对本发明的研究和实践而为本领域的技术人员所理解。
附图说明
[0035]
图1、fce-kick detection示意图。
[0036]
图2、kpca实现样本分离的原理示意图。
[0037]
图3、代价敏感学习示意图。
[0038]
图4、gan网络结构。
[0039]
图5、四种算法分类性能对比。
[0040]
图6、最优代价与正类样本个数间的关系。
[0041]
图7、real ir随正类样本及不平衡比之间的关系。
具体实施方式
[0042]
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
[0043]
在实际钻井过程中,由于地层情况复杂、现场施工环境较差,工具测量时会产生一定的误差,增加了早期溢流监测的难度,基于单因素的早期溢流监测受误差噪声的影响极大。因此,通过对文献资料及大量现场资料的调研,本发明优选并总结出与溢流密切相关的特征参数及其表征规律如表1所示,基于多参数监测早期溢流,提高识别溢流的准确性。
[0044]
表1溢流预警特征参数及其表征规律
[0045][0046]
本发明中并未直接将每一时刻各个特征参数的数值作为输入,而是将特征参数下一时刻相对于上一时刻的累积变化量作为输入参数,时刻的长短可根据实际情况适当调整,再通过智能模型分析特征参数的变化量与早期溢流间的关系,对早期溢流进行智能监测。
[0047]
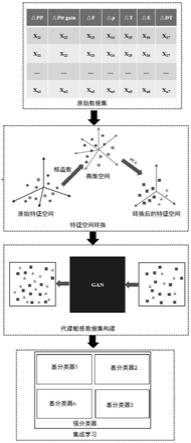
本发明以误分类代价最小为优化目标,使用数据前处理方法构建了基于代价敏感的早期溢流监测模型,将该模型命名为fce-kick detection(见图1)。由图1可知,模型主要由三个模块构成:1)特征转换模块(f:feature transformation),负责将输入数据集进行归一化处理及转换原始的特征空间;2)代价敏感数据集构建模块(c:cost-sensitive data construction),负责构建包含代价信息的训练数据集;3)集成学习模块(e:ensemble learning),用于集成多个弱分类器以得到强分类器。
[0048]
该模型的工作流程:首先,将原始数据集送入数据预处理模块,获得归一化及特征降维处理后的数据集。然后,将预处理后的数据集送入cdc模块中,正类样本将得到扩增,扩增后的正类样本与负类样本构成代价敏感的训练集。最后,在el模块中,我们集成了多个弱分类器组成强分类器,作为最终的分类器。模型的构建、训练及测试是基于python-keras深度学习库构建、训练和测试。keras是一个高级神经网络api,用python编写,能够在tensorflow,cntk或theano之上运行,能够实现快速实验。
[0049]
下面分别对三个模块进行说明:
[0050]
(1)特征转换模块
[0051]
特征转换旨在增强特征参数与溢流间的联系。在转换特征空间前,对数据集进行了归一化处理。数据归一化将预处理的数据限定在一定的范围内,从而消除奇异样本数据导致的不良影响。本发明使用了min-maxnormalization对原始数据进行线性变换,转换函数如下:
[0052][0053]
采用kpca(kernel principal componentanalysis)算法转换特征。pca是在保证样本数据信息损失最小的前提下,运用降维的思想将多个指标问题转换为新的指标问题,并且这些新的指标既互不相关,又能综合反映原指标所包含信息的一种分析方法。pca运算实际上是一种确定一个坐标系统的正交变换,在这个新的坐标系统下,变换数据点的方差沿新的坐标轴得到了最大化,这些坐标轴经常被称为是主成分。利用主成分分析可以较好地处理变量间的线性关系,但处理非线性关系时会导致各主成分的贡献率过于分散,不能找到能够有效代表原样本的综合变量,处理效果较差。kpca利用核化的思想,通过非线性映射φ,将低维输入空间每一个x=(x1,x2,
…
,x
p
)(xi∈rn,i=1,2,
…
,p)中不可分的数据映射到高维特征空间y,即:
[0054][0055]
在高维特征空间中进行数据处理,使输入空间中不可分的数据在高维特征空间中变得可分,再在这个更高的维度空间中利用特征的协方差矩阵判断变量间的方差一致性,寻找出变量之间的最佳的线性组合,来代替特征,从而达到降维的目的(图2)。
[0056]
多项式核函数非常适合于正交归一化后的数据,是一种常用的核函数,在处理二元分类问题上有很好的效果,其数学公式如下:
[0057]
k(x,y)=(ax
t
y c)dꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0058]
(2)代价敏感数据集构建模块
[0059]
代价敏感学习为不同的分类错误分配不同的代价,避免产生高代价的分类错误,以达到最小化分类代价的目标。代价敏感一般用代价矩阵(见表2)表示分类器错分时需要付出的代价,c0为正类样本,c1为负类样本,c(i,j)表示将i错分为j要付出的代价。
[0060]
表2混淆矩阵
[0061][0062]
通过代价矩阵获取代价信息后,根据代价嵌入过程的不同,可将代价敏感学习分为三类方法:数据前处理方法、直接的代价敏感学习方法与结果后处理方法,如图3所示。
[0063]
通过扩增数据集中正类样本的数量,改变数据集不平衡比,实现将代价信息嵌入到数据集中。在具体的实现过程中,选择gan(generative adversarial networks,gan)扩增正类样本。gan是goodfellow等人在2014年提出的一种新的生成式模型(goodfellow 2014),gan独特的对抗性思想使得它在众多生成器模型中脱颖而出。由于gan并不是单纯地对真实数据的复现,而是具备一定的数据内插和外插作用,能够有效的增加样本的多样性,这与我们希望生成的数据与真实数据存在一定差异的想法完美契合,非常适用于早期溢流监测扩增样本。gan由生成网络和判别网络组成,网络结构如图4所示。
[0064]
gan由生成器g(generate network)与判别器d(discriminant network)构成。gan
的目标函数定义为:
[0065][0066]
在每一轮的训练中,g随机从噪声分布pz(z)中采集m个向量作为输入,生成m个假数据g(zi)(i=1,2
…
m),其概率分布为pg。d接受g生成的m个假数据作为输入的同时,随机在真实数据中选取m个样本作为输入,真实数据的概率分布为p
data
。d通过pg与p
data
之间的差异判断输入来自真实数据或生成器,并输出d认定输入是真实分布的概率,并将输出反馈给g,用于指导g的训练。e
x~pdata(x)
[logd(x)]代表判别器对真实样本判断结果的期望,e
z~pz(z)
[log(1-d(g(z)))]代表判别器对虚假样本判断结果的期望。经过多轮对抗训练,理想情况下的d对真实样本判断结果d(x)应为1,logd(x)为0,即e
x~pdata(x)
[logd(x)]越大越好。对虚假样本判断结果d(g(z))应为0,1-d(g(z))为1,log(1-d(g(z)))为0,即e
z~pz(z)
[log(1-d(g(z)))]越大越好。最终d无法判别输入数据是来自真实数据x还是生成数据g(zi)(i=1,2
…
m),即d每次的输出概率值都为1/2,此时模型达到最优。
[0067]
(3)集成学习模块
[0068]
集成学习是组合多个弱分类模型以得到一个更好更全面的强分类器,集成学习潜在的思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来。
[0069]
本发明采用stacking方法训练一个模型用于组合其他各个基模型,在实际中我们选择了rf、adboost、gradientboost、et及svm五种基分类器。stacking方法首先根据原始训练集训练出若干个基分类器后,再将多个基分类器的预测结果作为新的训练集,来训练出一个新的分类器。stacking方法具体步骤如下:
[0070]
1)对model1,将训练集dc分为k份,对于每一份,用剩余数据集训练模型,然后预测出这一份的结果;
[0071]
2)重复上面步骤,直到每一份都预测出来,得到次级模型的训练集。得到k份测试集,平均后得到次级模型的测试集;
[0072]
3)对于剩余model重复以上步骤,得到m维数据;
[0073]
4)选定次级模型,作为最终的预测模型,我们使用了logistic regression。
[0074]
本发明的基于误分类代价的钻井早期溢流智能监测方法的应用案例如下:
[0075]
步骤1、数据集
[0076]
选取lz区块的实钻数据作为原始数据,以特征参数在30s左右的累积变化量,构建了多种规模的数据集,用以模拟区块开发的不同时期及测试模型的泛化能力。我们首先构建了测试数据集a用于验证模型,具体信息见表3。
[0077]
表3、数据集a(数据集不平衡比=9)
[0078]
[0079][0080]
数据集中样本数量共1000组,其中正类样本共100组,负类样本900组。样本不平衡率达到了9,属于典型的不平衡数据集。对于溢流而言,即使在区块开发的后期也难以获得大量的数据。
[0081]
步骤2、评价指标
[0082]
由于正类样本远少于负类样本,负类样本的分类性能更重要,此时准确率不能合理的衡量模型对不平衡数据的分类性能,为了更有意义的评估分类算法的性能,通常采用混淆矩阵的方法评估模型性能,混淆矩阵如表4所示。
[0083]
表4、混淆矩阵
[0084][0085]
模型预测正确的正样本数为tp,预测正确的负样本数为tn,预测为正的负样本数为fp,预测为负的正样本数为fn。这里选择混淆矩阵下的二级指标包括:accuracy、recall、precision、f-measure、roc曲线下面积(auc),以及模型分类错误产生的total cost作为评价准则衡量算法性能。
[0086]
f-measure是precision和recall加权调和平均,precision计算的是所有被检索到的tp fp中,tp占的比例,recall计算的是所有检索到的tp占所有tp fn的比例,评价指标公式:
[0087][0088][0089]
[0090][0091]
roc曲线下面积(auc)是衡量模型识别能力的重要指标,面积为0.5为随机分类,识别能力为0,面积越接近于1识别能力越强,面积等于1为完全识别。
[0092]
将分类正确的代价设置为0,将负类划分正类的代价设置为1,则模型误分类的总代价为:
[0093]
total cost=fp
·
1 fn
·
c(c1,c0)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0094]
步骤3、测试结果及对比分析
[0095]
这里设置了多种不同的代价以测试模型的性能。值得注意的是,当c(c0,c1)=c(c1,c0)时,模型退化为传统的分类模型。我们进行了多次测试以验证模型的性能,以下结果均为多次测试后的平均值。数据集a在被转换至不同维度下的分类性能测试结果见表5。
[0096]
表5、数据集a分类结果
[0097]
[0098][0099]
由表5可知,当c(c1,c0)=1,即模型退化为传统的分类模型时,虽然模型的分类准确率超过了0.95,但f-measure值极低,这表明模型对正类样本的分类准确率极低,即使是
在维度为6时,f-measure值最高,但也仅为0.79。由此可知,传统的分类模型,无法有效识别不平衡样本集中的正类样本。当误分类代价设置在2-5之间时,模型展现出极强的分类性能。模型对正类、负类数据均有较高的分类精度。在误分类代价设置为3、维度为6时,模型误分类产生的总代价仅为0.9,此时相对于传统的分类模型,模型对正类数据的识别准确率提升了48.9%。随着误分类代价进一步提高,此时模型产生了较高的误分类总代价,可以发现模型对正类样本的分类准确率极高,但对负类样本的分类准确率有所降低,由于对负类样本的错误分类较多而产生了较高的误分类总代价。究其原因在于,误分类代价设置过高时,为了避免产生更高的代价,模型倾向于将更多的样本划分为正类样本。基于此特点,我们认为在区块开发的前期或钻遇复杂地层时,可以适当提高误分类的代价,以保障模型对溢流的预测准确率,即使是在一定程度上牺牲对正常钻井的分类准确率也是值得的。从整个测试结果来看,我们的模型准确、可靠,能够应用于早期溢流监测中。
[0100]
发明人对比了在数据集a中,模型误分类产生的总代价与误分类代价、转换后的特征维度之间的关系。结果可知,当误分类代价设置在2-4之间,维度在4-6之间时,模型产生的误分类总代价最小。结合表5可知,转换后的特征维度介于4-6之间时,模型的分类性能最优。其原因在于,转换后的特征维度过小,转换特征后的数据集中包含的有用信息过少,此时训练出的模型出现了欠拟合的情况。转换后的特征维度过大,转换特征后的数据集中包含了过多的冗余信息,导致模型出现了过拟合的情况。因为本发明的原始溢流数据集中特征的维度已经确定,无法对比原始特征维度与转后的特征维度之间的关系,从而得出最优维度计算方法。
[0101]
发明人还对比了本发明的模型与其他方法的分类性能,包括过采样方法、欠采样方法与smote方法。过采样方法、欠采样方法与smote方法的测试结果见表6-表8。
[0102]
表6过采样方法测试结果
[0103]
[0104]
[0105]
[0106]
[0107][0108]
这几种算法各自训练出的最佳模型的分类性能对比如图5所示。由图可以看出,smote、过采样及欠采样三种模型对负类样本的分类准确率较高,但对正类样本的分类准确率极低,由此产生了较高的误分类总代价。fde模型(即本发明建立的模型)的分类性能明显优于其他三种模型。由此可以得出,通过简单的复制或者删除数据集中的样本及简单在数据集样本间进行插值增加样本数量的方法,均不能够解决早期溢流数据集正类样本量不足与不平衡的问题,训练出的模型无法应用于早期溢流监测中。而我们的模型能够有效解决数据集不平衡及正类样本量不足的问题。
[0109]
误分类代价属于先验信息,但在实际中,我们很难确定合适的代价。因此,我们以
模型性能最优为前提,对最优代价进行了分析。我们将正类样本数量设置在20-100之间,数据集的不平衡比设置在5-15之间,构建了多个数据集。将数据集转换后的特征维度设置为5,进行了多次实验。实验结果见表9。
[0110]
表9不同正类样本数量及数据集不平衡比下模型分类性能
[0111]
[0112]
[0113][0114]
由表9可知,不同不平衡比及正类样本数量下的模型分类性能相差较大。
[0115]
对比了最优代价随数据集不平衡比及正类样本数量变化的趋势,如图6所示。由图可知:1)最优代价随着不平衡比的增加而增加;2)最优代价随正类样本个数的变化差异较大,规律性不强;3)整体来看,最优代价保持在3-11之间。将扩增后的数据集的不平衡定义为real ir,对比了最优代价对应的real ir在不同正类样本量及不平衡比间的变化规律,如图7所示。
[0116]
由图7可以看出,当不平衡比为5时,最优的代价对应的real ir介于1-1.7之间;当不平衡比为7.5时,最优的代价对应的real ir介于1.25-1.9之间;当不平衡比为10时,最优的代价对应的real ir介于1.25-2之间;当不平衡比为12.5时,最优的代价对应的real ir介于1.4-2.1之间;当不平衡比为15时,最优的代价对应的real ir介于1.3-1.9之间。整体来看,最优代价对应的real ir介于1-2.5之间,由此,给出了模型最优代价计算公式:
[0117][0118]
式(9)中:c,最优代价;ir,数据集不平衡比;c,系数。
[0119]
综上所述,本发明提供了一种基于误分类代价的钻井早期溢流智能监测方法,克服了传统机器学习算法在溢流样本过少时分类精度低、泛化能力差的问题。并且使用lz区块的真实钻井数据对模型性能进行了测试,测试结果一致表明,模型拥有极强的分类性能。并且在与采样方法及smote方法的对比中,展现出极强的竞争力。详细对比了转换后的特征维度介于2-7之间时,模型的分类性能,经过多次测试得出:维度在4-6之间时,模型的性能最佳。尤其是在维度为6、误分类代价为3时,模型产生的误分类代价仅为0.9,对应的accuracy到达0.998,recall到达0.990,precision为0.986,f-measure为0.998,auc为0.997,模型展现出极强的分类性能。最后我们构建了多个正类样本量在20-100之间,数据集不平衡比在5-15之间的数据集。在验证了模型的泛化能力的同时,发现误分类代价对应的真实数据集不平衡比介于1-2.5之间,并由此推导出模型最优代价取值公式,为工程师提供参考。研究发现在代价过高时,模型对溢流样本的分类准确率极高,但在一定程度上,降低了对正常钻井样本的分类准确率。因此,在区块开发的前期或钻遇复杂地层时,可以基于此特点适当提高误分类代价,以保障钻井安全。
[0120]
以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制,虽然本发明已以较佳实施例揭露如上,然而并非用以限定本发明,任何熟悉本专业的技术人员,在不脱离本发明技术方案范围内,当可利用上述揭示的技术内容作出些许更动或修饰
为等同变化的等效实施例,但凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
