1.本发明涉及情感识别技术,尤其涉及一种基于视频时域动态注意力模型的微表情识别方法及装置。
背景技术:
2.微表情作为一种面部表情类型,与宏表情相比具有细微的、迅速的、自发的、抑制的和局部的特性。由于无法控制的微表情可以揭示一个人的真实感受,因此它可以广泛应用于临床医学、安全系统和审讯。对于微表情识别的研究,主要的问题是克服低密度和短持续时间的困难。然而,对于人的肉眼来说,基于静态图像的微表情识别是很困难的,因为微表情是瞬间发生的,很难被单一图像捕捉到。因此,微表情识别可以被视为一个需要超精度的视频分类问题。在视频分类任务中,微表情识别大致可以分为三个重要部分:时空特征提取、动态时间关系建模和时间信息有效融合。
3.与一般的表情、动作相比,微表情还具有显著的信息冗余问题,这使得更难去实施。除此之外,由于在实际生活中,某些表情并不容易被激励,长尾数据存在的类别不平衡的问题也普遍存在于微表情识别问题之中。之前的技术主要从提取时空特征入手,但随着深度学习网络结构的发展,越来越多的技术开始着力于使用深度学习的方法解决上述问题。但是,在建模中的过程中不仅需要考虑到“开始-峰值-结束”的微表情的时域动态规律,也需要提高识别微表情的准确率,只有这样,才能将微表情识别应用在日常生活中。
技术实现要素:
4.发明目的:本发明针对现有技术存在的问题,提供一种准确率更高的基于视频时域动态注意力模型的微表情识别方法及装置。
5.技术方案:本发明所述的基于视频时域动态注意力模型的微表情识别方法包括:
6.(1)获取微表情数据库,所述微表情数据中包括若干微表情视频和对应的微表情类别标签;
7.(2)构建微表情识别模型,所述微表情识别模型包括:
8.光流特征提取模块,用于将微表情视频等分为若干片段,在每个片段中随机挑选一帧图像与该片段的起始帧和尾帧一起计算光流图,并与随机翻转后的光流图融合,得到每一片段的光流融合特征;
9.深度特征提取模块,用于采用resnet18网络从每一片段的光流融合特征中提取深度特征,并将属于一个微表情视频的所有深度特征采用自注意力权重融合成一个视频级别深度特征;
10.加权深度特征提取模块,用于将视频级别深度特征与每个片段的深度特征再次拼接作为对应片段的新的深度特征,并将属于一个微表情视频的所有新的深度特征采用相关注意力权重融合成一个考虑到片段与视频之间关系的加权视频级别深度特征;
11.全连接层以及softmax层,用于根据加权视频级别深度特征识别出对应微表情视
频所属类别;
12.(3)将微表情数据库的每一微表情视频和对应标签作为一个样本,输入所述微表情识别模型,进行训练;
13.(4)将待识别的微表情视频输入训练好的微表情识别模型,输出即为识别的微表情类别。
14.进一步的,所述光流特征提取模块具体用于执行如下步骤:
15.a、将微表情视频等分成k个片段,得到{s1,s2,...sk}片段,针对每一个片段随机挑选一帧分别与起始帧、尾帧计算光流图,并将其转化成middlebury color编码的图片;
16.b、将提取到的光流图以0.5的随机概率随机水平翻转,之后将翻转后的光流图进行随机大小剪裁;
17.c、将步骤a和步骤b得到的图片做平均融合,作为对应片段的光流融合特征,其中第k个片段的光流融合特征表示为其中n表示视频样本个数,c代表通道个数,h和w分别表示长和宽。
18.进一步的,所述深度特征提取模块具体用于执行如下步骤:
19.a、将每一片段的光流融合特征送入resnet18网络,得到对应的深度特征,其中,第k个片段的深度特征表示为mk,k=1,...,k,k表示微表情视频划分的片段数量;
20.b、采用下式计算每一个片段的自注意力权重:
21.lk=σ(m
kat
),k=1,...,k
22.式中,表示第k个片段的自注意力权重,σ表示激活函数sigmoid,a表示与矩阵lk和mk关联的待训练参数;
23.c、根据自注意力权重采用下式将属于一个微表情视频的所有深度特征融合成一个视频级别深度特征v:
[0024][0025]
式中,
⊙
是一种具有广播机制的元素乘,n表示视频样本个数,d为深度特征mk的维度。
[0026]
进一步的,所述加权深度特征提取模块具体用于执行如下步骤:
[0027]
a、将视频级别深度特征与每个片段的深度特征加权后再次拼接,作为对应片段的新的深度特征:
[0028]m′k=c(lk⊙
mk,v),k=1,...,k
[0029]
式中,m
′k表示第k个片段的新的深度特征,c(
·
,
·
)表示连接函数,mk表示第k个片段拼接前的深度特征,lk表示第k个片段的自注意力权重,v表示视频级别深度特征,
⊙
是一种具有广播机制的元素乘,k表示微表情视频划分的片段数量;
[0030]
b、采用下式计算每一个新的深度特征对应的片段和对应的视频之间的相关注意力权重:
[0031]rk
=σ(c(lk⊙
mk,v)a
1t
),k=1,...,k
[0032]
式中,rk表示m
′k的相关注意力权重,σ表示激活函数sigmoid,a1表示与矩阵rk和c
(lk⊙
mk,v)关联的待训练参数;
[0033]
c、根据相关注意力权重采用下式将属于一个微表情视频的所有新的深度特征融合成一个加权视频级别深度特征o:
[0034][0035]
式中,
○
表示的达玛乘积运算符,n表示视频样本个数,d为深度特征mk的维度。
[0036]
进一步的,所述微表情识别模型训练时所采用的损失函数为:
[0037][0038]
其中,μ1和μ2是两个固定常量的超参数;
[0039][0040]
式中,m1是一个超参数表示两组的差异距离,是重要片段组的平均注意力权重,是冗余片段组的平均注意力权重,ih和ir分别为第h个重要片段、第r个冗余片段的时域注意力权重,通过以下方式得到:首先采用公式计算得到每个时域注意力权重ik,其中,lk(n)和rk(n)是分别是第n个样本的自注意力权重和相关注意力权重,
·
表示点乘运算,n表示样本数,之后将计算得到的时域注意力权重组合i=[i1,...,ik]划分为得分高的重要片段组ih=[i1,...,ih]和得分低的冗余片段组ir=[i1,...,ir],h r=k,k表示片段数;
[0041][0042]
式中,m2是一个固定的参数表示类别之间的边界距离,l表示标签类别的总数,β
′
=[β
′1,...,β
′
l
]
t
表示归一化类别注意力权重向量,β
′
*
表示其中的第*个元素,其通过以下方式得到:首先根据公式计算每个样本的注意力权重α,o为加权视频级别深度特征,a2是与矩阵o和α关联的待训练参数,之后根据下式计算每个类别的注意力权重β:β=w
l
α,是一种独热编码的标签矩阵,将所有类别的注意力权重β进行归一化后,按照降序排列后按序组成归一化类别注意力权重向量β
′
=[β
′1,...,β
′
l
]
t
;
[0043][0044]
式中,分别表示权重的预测输出中第l、y个元素,z
′
=α
⊙
z,
表示微表情识别模型的预测类别,
⊙
是一种具有广播机制的元素乘。
[0045]
本发明所述的基于视频时域动态注意力模型的微表情识别装置包括处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述方法。
[0046]
有益效果:本发明与现有技术相比,其显著优点是:本发明识别准确率更高。
附图说明
[0047]
图1是本发明提供的基于视频时域动态注意力模型的微表情识别方法的一个实施例的流程示意图;
[0048]
图2是本发明的微表情识别模型的结构图。
具体实施方式
[0049]
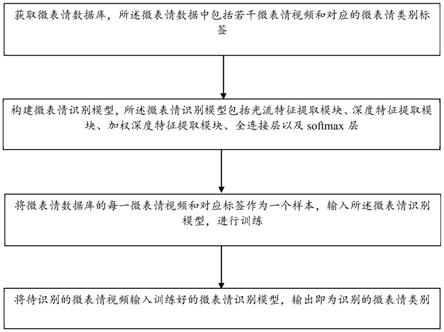
本实施例提供了一种基于视频时域动态注意力模型的微表情识别方法,如图1所示,包括:
[0050]
(1)获取微表情数据库,所述微表情数据中包括若干微表情视频和对应的微表情类别标签;
[0051]
(2)构建微表情识别模型,如图2所示,所述微表情识别模型包括:
[0052]
光流特征提取模块,用于将微表情视频等分为若干片段,在每个片段中随机挑选一帧图像与该片段的起始帧和尾帧一起计算光流图,并与随机翻转后的光流图融合,得到每一片段的光流融合特征;
[0053]
该模块具体用于执行如下步骤:a、将微表情视频等分成k个片段,得到{s1,s2,...sk}片段,针对每一个片段随机挑选一帧分别与起始帧、尾帧计算光流图,并将其转化成middlebury color编码的图片,用jpg格式的图片来保存;b、将提取到的光流图以0.5的随机概率随机水平翻转,之后将翻转后的光流图进行随机大小剪裁,产生112*112*3尺寸大小的图片;c、将步骤a和步骤b得到的图片做平均融合,作为对应片段的光流融合特征,其中第k个片段的光流融合特征表示为其中n表示视频样本个数,c代表通道个数,h和w分别表示长和宽。
[0054]
深度特征提取模块,用于采用resnet18网络从每一片段的光流融合特征中提取深度特征,并将属于一个微表情视频的所有深度特征采用自注意力权重融合成一个视频级别深度特征;
[0055]
该模块具体用于执行如下步骤:
[0056]
a、将每一片段的光流融合特征送入resnet18网络,得到对应的深度特征,其中,第k个片段的深度特征表示为mk,k=1,...,k,k表示微表情视频划分的片段数量;
[0057]
b、采用下式计算每一个片段的自注意力权重:
[0058]
lk=σ(m
kat
),k=1,...,k
[0059]
式中,表示第k个片段的自注意力权重,σ表示激活函数sigmoid,a表示与矩阵lk和mk关联的待训练参数,输入维度是256输出维度是1;
[0060]
c、根据自注意力权重采用下式将属于一个微表情视频的所有深度特征融合成一个视频级别深度特征v:
[0061][0062]
式中,
⊙
是一种具有广播机制的元素乘,n表示视频样本个数,d为深度特征mk的维度。
[0063]
加权深度特征提取模块,用于将视频级别深度特征与每个片段的深度特征再次拼接作为对应片段的新的深度特征,并将属于一个微表情视频的所有新的深度特征采用相关注意力权重融合成一个考虑到片段与视频之间关系的加权视频级别深度特征;
[0064]
该模块具体用于执行如下步骤:
[0065]
a、将视频级别深度特征与每个片段的深度特征加权后再次拼接,作为对应片段的新的深度特征:
[0066]m′k=c(lk⊙
mk,v),k=1,...,k
[0067]
式中,m
′k表示第k个片段的新的深度特征,c(
·
,
·
)表示连接函数,mk表示第k个片段拼接前的深度特征,lk表示第k个片段的自注意力权重,v表示视频级别深度特征,
⊙
是一种具有广播机制的元素乘,k表示微表情视频划分的片段数量;
[0068]
b、采用下式计算每一个新的深度特征对应的片段和对应的视频之间的相关注意力权重:
[0069]rk
=σ(c(lk⊙
mk,v)a
1t
),k=1,...,k
[0070]
式中,rk表示m
′k的相关注意力权重,σ表示激活函数sigmoid,a1表示与矩阵rk和c(lk⊙
mk,v)关联的待训练参数,输入维度是512输出维度是1;
[0071]
c、根据相关注意力权重采用下式将属于一个微表情视频的所有新的深度特征融合成一个加权视频级别深度特征o:
[0072][0073]
式中,
○
表示的达玛乘积运算符,n表示视频样本个数,d为深度特征mk的维度。
[0074]
全连接层以及softmax层,用于根据加权视频级别深度特征识别出对应微表情视频所属类别;全连接层(fully connected layers,fc)输出维度为微表情类别个数,输入为加权视频级别深度特征,全连接层及结果输出到softmax层,将概率最大的类别作为该微表情视频的识别类别结果。
[0075]
(3)将微表情数据库的每一微表情视频和对应标签作为一个样本,输入所述微表情识别模型,进行训练;训练时所采用的损失函数为:
[0076][0077]
其中,μ1和μ2是两个固定常量的超参数,分别控制两个子损失函数对联合损失函数的影响;
[0078]
排列片段注意力权重的损失函数:
[0079]
式中,m1是一个超参数表示两组的差异距离,是重要片段组的平均注意力权重,是冗余片段组的平均注意力权重,ih和ir分别为第h个重要片段、第r个冗余片段的时域注意力权重,通过以下方式得到:首先采用公式计算得到每个时域注意力权重ik,其中,lk(n)和rk(n)是分别是第n个样本的自注意力权重和相关注意力权重,
·
表示点乘运算,n表示样本数,之后将计算得到的时域注意力权重组合i=[i1,...,ik]划分为得分高的重要片段组ih=[i1,...,ih]和得分低的冗余片段组ir=[i1,...,ir],h r=k,k表示片段数;
[0080]
类别平衡的重分配权重的损失函数:
[0081][0082]
式中,m2是一个固定的参数表示类别之间的边界距离,l表示标签类别的总数,β
′
=[β
′1,...,β
′
l
]
t
表示归一化类别注意力权重向量,β
′
*
表示其中的第*个元素,其通过以下方式得到:首先根据公式计算每个样本的注意力权重α,o为加权视频级别深度特征,a2是与矩阵o和α关联的待训练参数,输入维度是512输出维度是1,之后根据下式计算每个类别的注意力权重β:β=w
l
α,是一种独热编码的标签矩阵,只有当该样本属于第1个类别时,该列向量在第1个元素为1其余都为0;将所有类别的注意力权重β进行归一化,归一化采用函数保证该范围为0~1及所有和为1,最后按照降序排列后按序组成归一化类别注意力权重向量β
′
=[β
′1,...,β
′
l
]
t
;
[0083]
类别引领的交叉熵损失函数:
[0084]
式中,分别表示权重的预测输出中第1、y个元素,z
′
=α
⊙
z,表示微表情识别模型的预测类别,
⊙
是一种具有广播机制的元素乘。
[0085]
(4)将待识别的微表情视频输入训练好的微表情识别模型,输出即为识别的微表情类别。
[0086]
本实施例还提供了一种基于视频时域动态注意力模型的微表情识别装置,包括处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述方法。
[0087]
为验证本发明的有效性,分别在smic-hs、samm和casme ii微表情数据库做了微表情识别的实验,验证结果如表1、表2和表3所示:
[0088]
表1 smic-hs结果
[0089]
方法类别数准确率f1-scoresparse mdmo370.51%0.7041kgsl366.46%0.6577sssn363.41%0.6329dsnn363.41%0.6462off-apexnet367.68%0.6709strcn-g373.20%0.6950dynamic376.10%0.7100micronet376.80%0.7440geme364.3l%0.6158本发明所提方法381.71%0.8166
[0090]
表2 samm结果
[0091]
方法类别数准确率f1-scorehigo-top541.18%0.3920sssn556.62%0.4513dsnn557.35%0.4644lgccon540.90%0.3400graph-tcn575.00%0.6985geme555.88%0.4538au-tcn574.26%0.7045本发明所提方法576.47%0.7524
[0092]
表3 casme ii结果
[0093]
方法类别数准确率f1-scoresparse mdmo566.95%0.6911kgsl565.81%0.6254sssn571.19%0.7151dsnn570.78%0.7297lgccon565.02%0.6400dynamic572.61%0.6700graph-tcn573.98%0.7246em-c3d gam569.76%n/ageme575.20%0.7354au-tcn574.27%0.7047本发明所提方法577.24%0.7689
[0094]
从表1、2、3可以看出,本发明方法识别准确率更高。
[0095]
以上所揭露的仅为本发明一种较佳实施例而已,不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
