1.本发明涉及大数据智能分析技术领域,具体涉及一种基于深度神经网络的样本增量学习方法。
背景技术:
2.样本增量学习目前没有严格的定义,但其主要特征包含两点:(1)能够将已知类的新样本加入到已有的知识系统中。(2)能够使一个基本的知识系统逐步演化为更加复杂的系统。
3.对于样本增量学习,以往的工作主要采用各种非神经网络学习算法来实现,如支持向量机、决策树、贝叶斯网络等。随着深度神经网络的发展,利用深度神经网络来实现类似人类记忆的增量学习成为了一大热点,但目前的研究主要集中在类别增量学习上,而对样本增量学习的研究少之又少,在样本增量学习任务中的一大难点在于:模型需要在不从头训练的情况下不断学习已知类别的新数据,并在学习后使得模型对这组类别的识别率不断上升,且接近离线学习的识别性能。
技术实现要素:
4.本发明的目的在于克服现有技术的不足,提供一种基于深度神经网络的样本增量学习方法,包括以下步骤:
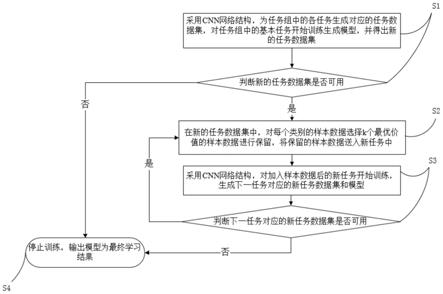
5.步骤1:采用cnn网络结构,为任务组中的各任务生成对应的任务数据集,对任务组中的基本任务开始训练生成模型,并得出新的任务数据集,判断新的任务数据集是否可用,若可用,则进入步骤2,若不可用,则进入步骤4;
6.步骤2:在新的任务数据集中,对每个类别的样本数据选择k个最优价值的样本数据进行保留,将保留的样本数据送入新任务中,进入步骤3;
7.步骤3:采用cnn网络结构,对加入样本数据后的新任务开始训练,生成下一任务对应的新任务数据集和模型,判断下一任务对应的新任务数据集是否可用,若可用,则返回步骤2,若不可用,则进入步骤4;
8.步骤4:停止训练,输出模型为最终学习结果。
9.优选的,所述步骤1中,任务组t={t1,t2,...,tn},任务组t中包含一批类别集为c的图像,每个类别包含大量样本,在开始训练前已获得的样本数据称为基本数据,基本任务为cnn网络结构对基本数据的训练,任务组中除基本任务外,其余任务为训练任务。
10.优选的,从当前任务开始学习到下一个任务开始学习的时间间隔称为样本增量学习的一个session,在第n个session中,模型只能访问当前任务tn的任务数据集dn。
11.优选的,所述cnn网络由一个特征提取器f(
·
)和一个全连接分类层c(
·
)组成,即p(xi)=c(f(xi)),损失函数采用交叉熵:
[0012][0013]
其中n为样本总数,m为类别数量,y
ic
为符号函数,当样本xi的标签等于c时,y
ic
等于1,反之为0;pc(xi)表示当前模型对样本xi属于类别集c的预测概率,p(xi)为当前模型对样本xi的预测概率。
[0014]
优选的,所述步骤2中,在新任务数据集中对每个类别的样本数据选择k个最优价值的样本数据进行保留时,还包括以下步骤:
[0015]
步骤21:依据新模型、新任务数据集,获取当前新模型的特征提取器,采用特征提取器提取出新任务数据集中所有样本数据的特征;
[0016]
步骤22:根据提取的多个样本数据特征,为每一类样本数据计算特征均值,并计算多个样本数据特征与特征均值的欧几里得距离;
[0017]
步骤23:保留欧几里得距离最小的样本数据特征所对应的k个样本数据。
[0018]
优选的,所述步骤21中,当任务t
j-1
训练完成后,得到当前任务的模型:
[0019]
p
j-1
(
·
)=c
j-1fj-1
(
·
)
[0020]
其特征提取器为f
j-1
(
·
),c
j-1
为当前任务的类别集。
[0021]
优选的,所述步骤22中,特征均值的计算公式为:
[0022][0023]
uc为特征均值,为类别集c的样本,nc为类别集c的样本数量,表示样本的特征,d
j-1
为类别集c的数据集。
[0024]
优选的,所述步骤23中,欧几里得距离的计算公式为:
[0025][0026]
||
·
||表示欧几里得距离。
[0027]
本发明的有益效果是:
[0028]
该方法在对新任务训练时,采用了对旧任务数据的知识蒸馏,这样做的目的时使得旧数据xk在新模型的预测结果pj(xk)尽可能的接近其在旧模型上的预测结果p
j-1
(xk),使模型在学习新数据的同时,保持对旧数据的识别能力,能够使模型保持对旧数据的预测结果,以缓解对旧知识的遗忘,防止模型偏向预测新数据。
附图说明
[0029]
图1显示为本发明的流程图;
[0030]
图2显示为本发明的学习框架;
[0031]
图3显示为本发明的任务学习过程好保留样本选择步骤;
[0032]
图4显示为本发明旧任务数据的知识蒸馏过程。
具体实施方式
[0033]
下面结合本发明的附图1~4,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施。
[0034]
在本发明的描述中,需要理解的是,术语“逆时针”、“顺时针”“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
[0035]
如图1、图2所示,一种基于深度神经网络的样本增量学习方法,包括以下步骤:
[0036]
步骤1:采用cnn网络结构,为任务组中的各任务生成对应的任务数据集,对任务组中的基本任务开始训练生成模型,并得出新的任务数据集,判断新的任务数据集是否可用,若可用,则进入步骤2,若不可用,则进入步骤4;
[0037]
步骤2:在新的任务数据集中,对每个类别的样本数据选择k个最优价值的样本数据进行保留,将保留的样本数据送入新任务中,进入步骤3;
[0038]
步骤3:采用cnn网络结构,对加入样本数据后的新任务开始训练,生成下一任务对应的新任务数据集和模型,判断下一任务对应的新任务数据集是否可用,若可用,则返回步骤2,若不可用,则进入步骤4;
[0039]
步骤4:停止训练,输出模型为最终学习结果。
[0040]
具体的,所述步骤1中,任务组t={t1,t2,...,tn},任务组t中包含一批类别集为c的图像,每个类别包含大量样本,在开始训练前已获得的样本数据称为基本数据,基本任务为cnn网络结构对基本数据的训练,任务组中除基本任务外,其余任务为训练任务。
[0041]
在样本增量学习的设置中,除了第一个任务的训练集d1,一般称为基本子任务训练集d
base
,除它有大量的训练样本外,其余每个任务数据集dn只包含较少样本,目的为通过不断学习已知类别的新样本数据,来不断增强模型对已知类别的识别表现,以达到接近离线学习的识别性能。基本任务训练结束后,当新任务数据可用时,利用新任务数据对当前模型进行微调更新,而不是再次从头训练。
[0042]
具体的,从当前任务开始学习到下一个任务开始学习的时间间隔称为样本增量学习的一个session,在第n个session中,模型只能访问当前任务tn的任务数据集dn。
[0043]
假设第n个任务tn的训练集是dn,则它在第n个session到达。cn是第tn的类别集,在样本增量学习中,不同任务的类之间是完全重叠的:即对于i≠j,ci=cj=c。
[0044]
具体的,所述cnn网络由一个特征提取器f(
·
)和一个全连接分类层c(
·
)组成,即p(xi)=c(f(xi)),损失函数采用交叉熵:
[0045][0046]
其中n为样本总数,m为类别数量,y
ic
为符号函数,当样本xi的标签等于c时,y
ic
等于1,反之为0;pc(xi)表示当前模型对样本xi属于类别集c的预测概率,p(xi)为当前模型对样本xi的预测概率。
[0047]
如图3所示,具体的,所述步骤2中,在新任务数据集中对每个类别的样本数据选择k个最优价值的样本数据进行保留时,还包括以下步骤:
[0048]
步骤21:依据新模型、新任务数据集,获取当前新模型的特征提取器,采用特征提取器提取出新任务数据集中所有样本数据的特征;
[0049]
步骤22:根据提取的多个样本数据特征,为每一类样本数据计算特征均值,并计算多个样本数据特征与特征均值的欧几里得距离;
[0050]
步骤23:保留欧几里得距离最小的样本数据特征所对应的k个样本数据。
[0051]
在基本任务学习完成后,且新的任务tn数据可用时,如果直接将其数据集dn用于训练更新当前模型,会使新模型的预测结果偏向于新数据的分布,从而损失对整体数据的预测精度。为了缓解这一现象,在每一个任务训练完成后,从当前数据集中为每类样本选择k个最有价值的样本进行保留,其中,k取任意值,用于构造旧任务数据集r。在训练下一个任务时,旧任务数据集r将与新任务的数据集共同参与训练,在保留旧任务知识的同时,防止模型偏向预测新数据。
[0052]
具体的,所述步骤21中,当任务t
j-1
训练完成后,得到当前任务的模型:
[0053]
p
j-1
(
·
)=c
j-1fj-1
(
·
)
[0054]
其特征提取器为f
j-1
(
·
),c
j-1
为当前任务的类别集。
[0055]
具体的,所述步骤22中,特征均值的计算公式为:
[0056][0057]
uc为特征均值,为类别集c的样本,nc为类别集c的样本数量,表示样本的特征,d
j-1
为类别集c的数据集。
[0058]
具体的,所述步骤23中,欧几里得距离的计算公式为:
[0059][0060]
||
·
||表示欧几里得距离。
[0061]
需要注意的时,旧任务数据集r中的样本是不断更新的,但其样本数量是固定的,即每类k个样本。当其参与新任务学习后,通过重新计算在当前模型下,每类训练样本与其特征中心距离最小的k个样本来重新构造旧任务数据集r。为了便于理解,对于在任务t
j-1
中构造的旧任务数据集,用rj表示,它将参与任务tj的训练。即对于任务{t1,t2,...,tn},其实际的训练集表示为:
[0062][0063]
其中,在学习已知类别的新样本时,由于出现的新样本随机,与已学习样本的分布可能存在差异,对于分布差异较大的样本,模型学习后可能会影响其分类器对该类别的识别性能,导致整体识别性能的下降。因此,进一步提出新样本的挑选过程,通过估计新样本的特征分布,从新样本中挑选对相应类别学习有益的样本,以保证能够提升对该类别的识别性能。
[0064]
具体过程为,对于已学习的旧样本,通过为其生成一个特征原型来代表其整体的特征分布。
[0065]
对于新数据的学习,在模型训练前,通过当前旧模型输出新数据的特征,并计算新数据特征与对应类别的特征原型之间的近似程度,对于近似程度较高的样本,认为其与已学习的样本分布较近,是对当前模型学习有用的样本,应当保留。而近似程度较低的样本,认为其与已学习的样本分布较远,是对当前模型学习有负面影响的样本,应当舍弃。对于任务tj中一个类别集c的新样本其在旧模型的特征输出为对应的类别特征原型为uc,则特征分布近似程度定义为:
[0066][0067]
其中n
dime
表示特征的维度,表示l1范数,该近似程度公式表示新样本特征输出与类别原型uc在特征每一个维度上的比值的平均值。为了便于计算,和uc在计算前会进行归一化,保证特征每一个维度值为正数。
[0068]
对于计算所得的分布近似度γ,通过比较其与设定的近似度阈值τ的大小来判断该新样本是否有用:
[0069]
|1-γ|≤τ
[0070]
新任务学习时,模型由于更新参数,会对旧任务学习的知识发生遗忘,具体来说,更新后的模型对旧数据的预测结果会发生改变。尽管我们保留了一部分旧任务的数据,但这部分保留数据数量较少,且并不完全来自所有旧任务。例如,当任务tj,...,t
j m
中存在多余k个样本的价值高于t1,...t
j-1
中的样本时,旧任务数据集中的保留样本将不包含任务t1,...t
j-1
中的数据。因此仍会发生对这部分任务知识的遗忘。
[0071]
为了解决这一问题,在对新任务训练时,采用了对旧任务数据的知识蒸馏。具体来说,如图4所示,当任务t
j-1
训练完成,并构造保留数据集rj后。新任务tj的数据集dj将与保留数据集rj共同训练并更新模型。为了使更新后的模型尽可能多的保持对旧数据的预测结果。在训练任务tj前,先利用上一个任务获得的模型p
j-1
(
·
)来获取rj中保留样本xk的预测结果p
j-1
(xk),这时获取的预测结果将作为保留样本xk在任务tj中的训练标签,用于计算蒸馏损失。这样做的目的时使得旧数据xk在新模型的预测结果pj(xk)尽可能的接近其在旧模型上的预测结果p
j-1
(xk),使模型在学习新数据的同时,保持对旧数据的识别能力。
[0072]
此时的损失函数包含两部分:对dj中新数据的交叉熵损失以及对rj中旧数据的蒸馏损失:
[0073][0074][0075]
[0076]
其中xi表示dj中的新样本,xk表示rj中的保留样本,和表示当前模型pj(
·
)对样本xi和xk属于类c的预测概率。表示旧模型p
j-1
(
·
)对保留样本xk属于类c的预测概率,将该结果作为保留样本xk在当前任务tj中的训练标签,能够使模型保持对旧数据的预测结果,以缓解对旧知识的遗忘。
[0077]
训练结束后,再次计算每一类的特征中心,并从当前的训练集中重新挑选离中心最近的k个样本保留用于更新保留样本数据集r
j 1
,用于参与下一个任务t
j 1
的训练。
[0078]
在具体实施过程中,对于cifar100和mini image net数据集,从训练集中为每一类分别选择300个样本作为基本任务数据集d1/d
base
,50个样本作为新任务数据集dn,共4组,即一共有5个学习过程(1个基本任务学习,4个新任务学习)。每个任务的训练集都是通过从原始训练数据集中随机抽取来构造的,测试集固定不变,测试样本为每类100个。
[0079]
使用resnet-18作为网络模型。每个任务训练时的batch size大小为128,初始学习率为0.1。在第30个epoch后(包括30),每10个epoch后将学习率手动降低10倍,并在第50个epoch完成后停止训练。
[0080]
miniimagenet:miniimagenet数据集是image net-1k数据集的子集。共100个类,每类包含500张训练图像和100张测试图像。图像为大小为84
×
84的rgb格式。
[0081]
cifar-100:cifar100数据集包含60,000张rgb图像,100个类,每个类有500个训练图像和100个测试图像。每幅图像的大小为32
×
32。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。