基于改进粒子群算法优化设计dbn网络结构
技术领域
1.本发明涉及的是人工智能的深度学习算法领域,具体涉及一种基于改进粒子群算法优化设计dbn网络结构。
背景技术:
2.深度置信网络(dbn)是一种概率生成模型,网络结构由多个受限玻尔兹曼机(restricted boltzmann machines,rbm)堆叠而成,目前dbn广泛应用于语音识别、图像处理以及推荐系统等领域。深度置信网络在使用过程中不可避免遇到设置网络结构的问题,然而目前较少关于dbn网络结构设计的研究,也没有完善的规则去制定其结构。
3.粒子群算法(pso)是一种基于群体的智能优化算法,该算法具有群体智能、内在并行性、结构简单、收敛快速等优点。然而基本粒子群算法在迭代寻优时,经常会出现较早收敛现象,容易陷入局部最优值,因而需要改进粒子群算法。
4.在制定dbn网络结构时,当数据集确定之后,输入层特征维数和输出层节点数随之确定下来。然而dbn网络的复杂度主要取决于输入层特征维数、隐藏层神经元数目以及隐藏层层数。如果输入层特征太多造成特征冗余的局面,便会大大增加模型复杂度,倘若过分减少特征又而会导致输入数据包含信息过少,也不利于模型对于数据的学习。隐藏层的作用是对输入层特征信息的学习,隐藏层神经元数目设置过多,计算过于复杂,太小又无法学习到输入层不同数据之间的差异,导致最后预测效果很差。因此,提出基于改进粒子群算法优化设计dbn网络结构方法(non-linear particle swarm optimization-deep belief network,nlinpso-dbn)。该方法采用非线性权重递减策略提高了pso算法的收敛速度,通过连续性变量设计构造个体进行迭代训练,做到输入层特征和隐藏层神经元数目的优化选择。
技术实现要素:
5.针对现有技术上存在的不足,本发明目的是在于提供一种基于改进粒子群算法优化设计dbn网络结构,改进粒子群算法给dbn输入层筛选数据特征,改进粒子群算法对各隐藏层神经元数目进行优化设置。
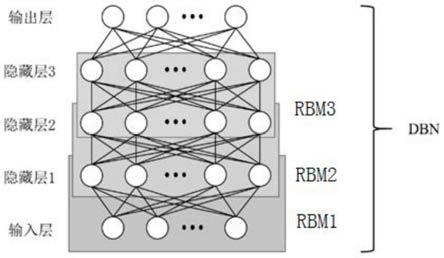
6.为了实现上述目的,本发明是通过如下的技术方案来实现:基于改进粒子群算法优化设计dbn网络结构,由3个rbm堆叠以及输出层组成,由于采用逐层预训练和对比散度算法可以快速完成连接权值的学习。
7.基于改进粒子群算法优化设计dbn网络结构方法,采用非线性权重递减策略提高pso算法的收敛速度,通过连续性变量设计构造个体进行迭代训练,做到输入层特征和隐藏层神经元数目的优化选择,具体包括以下步骤:
8.1、准备用于dbn网络训练的数据集,对数据集进行预处理,减少图片中噪声;
9.2、根据图片维度以及最终分类输出,确定dbn网络的初始结构,确定输入层特征维数和输出层节点数;
10.3、改进粒子群算法nlinpso群体中个体变量设计,个体变量维数设计分为两部分:一部分采用连续性编码设计,维度等于dbn网络结构的输入层特征维数,另一部分用于dbn网络结构各隐藏层神经元数目的设置,该部分维数为隐藏层的层数;
11.4、粒子群算法在迭代过程中区别与传统线性惯性权重因子,采用了非线性惯性权重因子算法设计,改善pos算法的收敛和寻优;
12.5、使用dbn模型中重构误差的方法,即输入数据与重构输入数据之间的差值,采用二阶范数,作为pso算法的适应度函数计算,逐步训练迭代,确定最优的dbn网络结构。
13.所述的步骤4中的非线性惯性权重因子算法设计,公式如下:
[0014][0015]
式(1)中ω_max和ω_min分别表示惯性权重因子的最大值和最小值,可人为设置。i表示第i次迭代,maxgen表示最大迭代次数。
[0016]
所述的步骤3中的个体变量设计的个体组成分别为输入层特征维数和各隐藏层神经元数目。个体变量设计方法如下:假设可见层特征维数为n,生成n维的随机向量xi=[x
i1
,x
i2
,
…
,x
ik
,
…
,x
in
](k《n),其中x
ik
服从[-1,1]的均匀分布,然后在dbn模型中求解适应度值时按照式(2)的规则选取特征,规则如下:
[0017][0018]
式(2)中y
ik
的取值1、0分别表示对第k维特征的选用和舍弃,对于隐藏层层数以及数目设计,由于隐藏层层数选择确定层数设计且为3层,于是各隐藏层神经元数目只需要随机生成一个实数迭代训练即可。
[0019]
综上,一个个体可以表示为pop(i)=[x
i1
,x
i2
,
…
,x
ik
,
…
,x
in
,b
i1
,b
i2
,b
i3
],其中pop(i)代表第i个个体,b
i1
,b
i2
,b
i3
分别表示为每一层隐藏层神经元数目。
[0020]
所述的步骤5中的适应度函数设计采用dbn模型中重构误差的方法,即输入数据与重构输入数据之间的差值,采用二阶范数,公式如下:
[0021][0022]
式(3)中s和n分别代表训练样本个数和可见层特征维数,m表示dbn中隐藏层的层数,代表在n维特征维数的原始数据中被选中的第j维的向量。代表被选中的第j维特征数据向量经过输入重构后的向量。很显然当适应度值e(k)越小时,则该个体转变后的模型参数在dbn模型使用中效果越好。
[0023]
本发明具有以下有益效果:
[0024]
1.改进粒子群算法,通过对传统线性惯性权重因子的非线性改造,非线性权重递减策略提高了pso算法的收敛速度,通过多次训练实验,结果表名非线性权重因子pso比传统线性pso在收敛速度和应用结果上更加有效。
[0025]
2.改进粒子群算法优化后的dbn网络结构在错误率和训练时间上与传统的dbn网络结构相比较,该方法在综合性能上有一定的提升,实现了改进粒子群算法优化设计dbn网
络结构的目的。
附图说明
[0026]
下面结合附图和具体实施方式来详细说明本发明;
[0027]
图1为本发明的3层隐藏层dbn网络结构示意图;
[0028]
图2为本发明的整体流程图;
[0029]
图3为本发明的算法核心设计流程图。
具体实施方式
[0030]
为使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体实施方式,进一步阐述本发明。
[0031]
参照图1-3,本具体实施方式采用以下技术方案:基于改进粒子群算法优化设计dbn网络结构,本质上是由3个rbm堆叠以及输出层组成,由于采用逐层预训练和对比散度算法可以快速完成连接权值的学习。因此,使用dbn解决实际问题时,重点在于dbn网络结构设计。
[0032]
nlinpso-dbn主要解决两个问题:一是改进粒子群算法给dbn输入层筛选数据特征,二是改进粒子群算法对各隐藏层神经元数目进行优化设置。
[0033]
nlinpso-dbn算法设计包括:
[0034]
1.权重非线性递减设计
[0035]
由于较大的惯性权重因子使得pso算法在迭代过程中容易避免局部最优,提高了全局搜索的能力,而较小的惯性权重因子适合对当前的小范围搜索区域进行精确地局部搜索,有利于算法最终的收敛。综合考虑pso算法早期容易收敛以及后期容易在最优解附近产生来回震荡的现象,准备将权重非线性变化,公式如下:
[0036][0037]
式(1)中ω_max和ω_min分别表示惯性权重因子的最大值和最小值,可人为设置。i表示第i次迭代,maxgen表示最大迭代次数。在整个算法设计过程中,根据目前改进粒子群算法模型进行应用于dbn网络结构设计还需要解决两个问题:个体变量和适应度函数设计。
[0038]
2.个体变量设计
[0039]
个体由两部分组成分别为输入层特征维数和各隐藏层神经元数目,输入层特征维数过多导致模型计算复杂,维数过少无法表示输入层数据包含的信息量,因此需要对输入层特征进行筛选。粒子群算法中粒子编码通常采用连续性变量,所以在个体变量设计时方法如下:
[0040]
假设可见层特征维数为n,生成n维的随机向量xi=[x
i1
,x
i2
,
…
,x
ik
,
…
,x
in
](k《n),其中x
ik
服从[-1,1]的均匀分布,然后在dbn模型中求解适应度值时按照式(2)的规则选取特征,规则如下:
[0041]
[0042]
式(2)中y
ik
的取值1、0分别表示对第k维特征的选用和舍弃,对于隐藏层层数以及数目设计,由于隐藏层层数选择确定层数设计且为3层,于是各隐藏层神经元数目只需要随机生成一个实数迭代训练即可。
[0043]
综上,一个个体可以表示为pop(i)=[x
i1
,x
i2
,
…
,x
ik
,
…
,x
in
,b
i1
,b
i2
,b
i3
],其中pop(i)代表第i个个体,b
i1
,b
i2
,b
i3
分别表示为每一层隐藏层神经元数目。
[0044]
3.适应度函数设计
[0045]
适应度函数设计采用dbn模型中重构误差的方法,即输入数据与重构输入数据之间的差值,采用二阶范数,公式如下:
[0046][0047]
式(3)中s和n分别代表训练样本个数和可见层特征维数,m表示dbn中隐藏层的层数,代表在n维特征维数的原始数据中被选中的第j维的向量。代表被选中的第j维特征数据向量经过输入重构后的向量。很显然当适应度值e(k)越小时,则该个体转变后的模型参数在dbn模型使用中效果越好。
[0048]
本具体实施方式基于传统线性权重粒子群算法存在局部最优和早期收敛的问题,提出非线性惯性权重因子递减方法,改进了粒子群算法。基于深度置信网络(dbn)存在设计网络结构的问题,提出采用改进粒子群算法优化设计dbn网络结构方法,其中重点在于个体变量设计以及适应度函数设计,最终实现了优化设计dbn网络结构的目的。
[0049]
综上,当在采用dbn网络训练识别图片或者语音时,对于人为设计的dbn网络结构可以通过上面介绍的方法进行优化设计。
[0050]
实施例1:用到手写体数字图片识别的整体流程:
[0051]
第一步,图像预处理,常见的图像预处理方法有去均值、归一化、pca等,通过对每一张图片进行预处理,一方面能够减少图片中噪声干扰后续模型训练的精度、准确度的影响,另一方面也能够让图像数据符合某种规则,降低后续的计算量,加速模型训练和收敛。对于手写体数据集中的每一张图片,可以通过归一化的方法完成对数据集的预处理。
[0052]
第二步,确定dbn模型初始网络结构,通常而言当给定数据集时,dbn网络的输入层特征维数和输出层特征维数便随之确定下来,本例中数据集中每一张图片的维度为28x28,展开为行向量为1x784,那么输入层特征维数就是一维向量的维数784,而输出层特征维数对应的是图片种类个数,本例图片为手写数字,所以种类为0到9一共10种。而对于中间各隐藏层,根据通用近似定理即两层及以上的神经网络能够逼近任意连续函数,因此可以根据实际情况设置层数,以及各隐藏层神经元数目,作为初始dbn网络结构模型用于后续模型结构优化。
[0053]
第三步,改进粒子群算法(nlinpso)个体变量设计,根据第二步初步确定的dbn网络结构结合改进粒子群算法设计个体,nlinpso算法中每一个个体都是一个一维向量,向量的组成分为两部分,第一部分用于dbn网络输入层特征维数的筛选,采用连续性编码设计,该部分维数为dbn输入层特征维数784,每一个数据服从[-1,1]的均匀分布,便于粒子群算法的计算迭代。第二部分用于dbn网络结构各隐藏层神经元数目的设置,该部分维数为隐藏
层的层数,每一个数据为隐藏层神经元的数目,两部分拼接完成nlinpso算法个体的设计。
[0054]
第四步,适应度函数设计,粒子群算法在迭代过程中,群体中所有的个体需要通过适应度函数学习知道自身的最优值来逐步寻找到解集空间存在的最优值,根据上面技术方案提到的适应度函数设计公式,在dbn网络实际训练过程中,粒子群中每个个体用于构造dbn网络结构进行训练从而计算得到个体的适应度值。
[0055]
第五步,粒子群算法参数设置,实际上要想使用粒子群算法还有很多参数需要设置,而该算法参数的设置可根据实际情况进行设置,本例是对手写体数字数据集进行识别,参数设置如下:学习因子c1=c2=1.494,因为个体由两部分构成,所以它们的速度和位置搜索空间都不同。可见层特征维数:速度vmax=0.2,vmin=-0.2,位置fpopmax=1,fpopmin=-1。隐藏层数目:速度lmax=5,lmin=-5,位置lpopmax=250,lpopmin=80。权重因子最大值和最小值为ωmax=0.9,ωmin=0.4,种群数目设为10,迭代200次停止。
[0056]
第六步,训练改进粒子群算法得到最优dbn网络结构,根据上面粒子群算法的个体和适应度函数设计,并设置算法迭代训练的参数,经过多次训练,模型逐渐收敛,最终得到最优的种群个体,将该个体的前半部分按照个体变量设计的公式转变为对于dbn网络结构的输入层特征维数,将个体的后半部分作为dbn网络各隐藏层神经元的数目,此时便得到了优化后的dbn网络结构模型,然后就可以使用该模型对手写体图片进行识别分类,最后为了后续调用方便,可以将优化的dbn模型元数据存入到hive中备用。
[0057]
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。